
一本徹底搞懂MySQL索引優化EXPLAIN百科全書
1、MySQL邏輯架構
日常在CURD的過程中,都避免不了跟資料庫打交道,大多數業務都離不開資料庫表的設計和SQL的編寫,那如何讓你編寫的SQL語句效能更優呢?
先來整體看下MySQL邏輯架構圖:
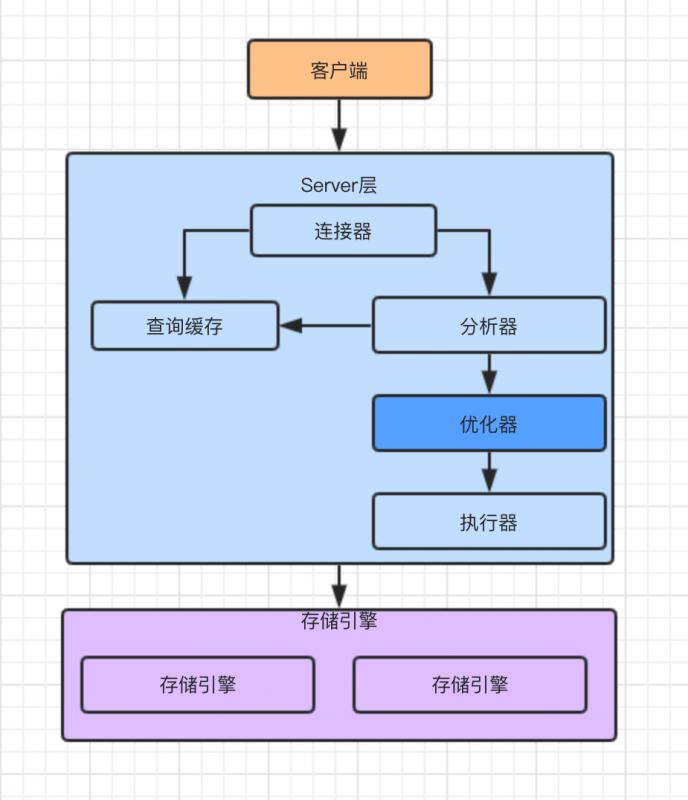
MySQL整體邏輯架構圖可以分為Server和儲存引擎層。
Server層:
Server層涵蓋了MySQL的大多數核心服務功能,以及所有的內建函式(如日期、時間、數學和加密函式等),以及儲存過程、觸發器、檢視等跨儲存引擎的實現也在這一層來實現。
- 聯結器:負責跟客戶端建立連線、獲取許可權、維持和管理連線。
- 分析器:SQL詞法分析,SQL語法分析
- 優化器:索引選擇,選擇一個執行效率高的,生成執行計劃
- 執行器:操作引擎,返回執行結果
- ...
- 查詢快取:執行SQL語句之前,先查快取,快取結果可能是以key-value對方式儲存的,key 是查詢的語句,value 是查詢的結果。
儲存引擎層:
負責資料的儲存和提取,是一種外掛式的架構方式。支援 InnoDB、MyISAM、Memory 等多個儲存引擎。MySQL 5.5.5版本開始預設儲存引擎是 InnoDB,也是目前常用的儲存引擎。
今天我們來看下詳細看下優化器裡的執行計劃如何分析,要分析一個 SQL 的執行效率,就要會看執行計劃,根據執行計劃優化 SQL,使其能達到高效查詢的目的。
一條查詢語句需要經過 MySQL 查詢優化器的各種基於成本和規則,優化後會生成一個所謂的執行計劃
那麼這個執行計劃主要展示具體執行查詢的方式,比如多表連線的順序是多少,表裡包含多個索引,每個表採用什麼訪問方法來具體執行查詢等。
而設計 MySQL 的大佬是非常貼心的,知道開發的朋友們都是親自寫 SQL 的,但是寫出 SQL 容易,想寫出效能高的 SQL 可不簡單。
所以,大佬提供了 Explain 語句來幫我們查詢某個查詢語句的具體執行計劃。
2、SQL 執行計劃解析
本文帶大家看懂 EXPLAIN 語句,必須要熟悉各項輸出是做什麼的,從而有針對性的提升SQL 查詢語句的效能。
列名 |
用途 |
|---|---|
| id | 每一個SELECT關鍵字查詢語句都對應一個唯一id |
| select_type | SELECT關鍵字對應的查詢型別 |
| table | 表名 |
| partitions | 匹配的分割槽資訊 |
| types | 單表的訪問方法 |
| possible_keys | 可能用到的索引 |
| key | 實際使用到的索引 |
| key_len | 實際使用到的索引長度 |
| ref | 當使用索引列等值查詢時,與索引列進行等值匹配的物件資訊 |
| rows | 預估需要讀取的記錄條數 |
| filtered | 某個表經過條件過濾後剩餘的記錄條數百分比 |
| Extra | 額外的一些資訊 |
為了方便解釋上面的執行計劃各項輸出的含義,下面建立三張資料庫表。
資料庫建立三張表:
DROP TABLE IF EXISTS user;
CREATE TABLE `user` (
`id` int(11) NOT NULL,
`name` varchar(45) DEFAULT NULL,
`update_time` datetime DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `idx_name` (`name`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
INSERT INTO user (`id`, `name`, `update_time`)
VALUES (1,'a','2017-12-22 15:27:18'), (2,'b','2017-12-22 15:27:18'), (3,'c','2017-12-22 15:27:18');
DROP TABLE IF EXISTS `group`;
CREATE TABLE `group` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(10) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `idx_name` (`name`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
INSERT INTO `group` (`id`, `name`) VALUES (1,'group1'),(2,'group2'),(3,'group3');
DROP TABLE IF EXISTS user_group;
CREATE TABLE `user_group` (
`id` int(11) NOT NULL,
`user_id` int(11) NOT NULL,
`group_id` int(11) NOT NULL,
`remark` varchar(255) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `idx_user_id` (`user_id`),
KEY `idx_group_id` (`group_id`),
KEY `idx_user_group_id` (`user_id`,`group_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
INSERT INTO user_group (`id`, `user_id`, `group_id`, `remark`)
VALUES (1,1,1,'bak1'), (2,2,2,'bak2'), (3,3,3,'bak3');EXPLAIN 執行計劃引數詳解:
下載了最新的 MySQL8.0+ 版本,直接執行 EXPLAIN ,對比了 MySQL 5.0+ 版本執行的 EXPLAIN EXTENDED 命令同樣都提供了一些查詢優化的資訊。除了執行計劃各項輸出引數外,額外還有 filtered 列,是一個百分比的值,rows * filtered/100 可以估算出將要和 EXPLAIN 中前一個表進行連線的行數 。
如下所示:

EXPLAIN 中的列
接下來我們將詳細說明下 EXPLAIN 執行結果每一列的資訊。
1、id 列
設計表時通常會設計 id,一般會作為主鍵,執行計劃的結果也不例外,也有 id 列,id 列編號是 SELECT 的序列號,並且 id 的順序是按 SELECT 出現的順序增長的。id列越大執行優先順序越高,id 相同則從上往下執行,id 為 NULL 最後執行。
MySQL將 SELECT 查詢分為簡單查詢 SIMPLE 和複雜查詢 PRIMARY。
複雜查詢包括:簡單子查詢、派生表( FROM 語句中的子查詢)、UNION 和 UNION ALL 查詢。
簡單查詢:

複雜查詢:
1)簡單子查詢
EXPLAIN SELECT (SELECT 1 from user LIMIT 1) from user;

2)FROM 子句中的子查詢
EXPLAIN SELECT * FROM (SELECT id, count(*) as c from group GROUP BY name) as derived

這個查詢執行時有個臨時表別名為 derived,外部 SELECT 查詢引用了這個臨時表
3)UNION 和 UNION ALL 查詢
EXPLAIN SELECT * FROM user UNION SELECT * FROM user;

UNION 結果總是放在一個匿名臨時表中,臨時表不在 SQL 中出現,臨時表名為 <union1, 2>,因此它的 id 是 NULL,表明這個臨時表是為了合併兩個查詢結果集而建立的。
跟 UNION 對比,UNION ALL 無需為最終結果而去重,僅是單純的將多個查詢結果集中的記錄合併成一個並返回給使用者,所以不會使用到臨時表,故沒有 id 為 NULL 記錄。如下所示:
EXPLAIN SELECT * FROM user UNION ALL SELECT * FROM user;

注意點:子查詢優化為連線查詢
查詢優化器可能對子查詢進行重寫,進而轉換為連線查詢,查詢計劃中的兩個id值是相同的,如下所示:
EXPLAIN SELECT * FROM user WHERE id IN (SELECT user_id FROM user_group);

2、select_type 列
MySQL中優化器中的概念:
物化:
子查詢語句中的子查詢結果集中的記錄儲存到臨時表的過程稱之為 物化(英文名:Materialize),簡單理解為儲存子查詢結果集的臨時表稱之為 物化表。
也正因為物化表的記錄都建立了索引(基於記憶體的物化表有雜湊索引,基於磁碟的有B+樹索引),因此通過 IN 語句判斷某個運算元在不在子查詢的結果集中變得很快,從而提升語句的效能。
半連線 semi-join:
也是跟 IN 語句子查詢有關。
通用語句:
SELECT ... FROM outer_tables
WHERE expr IN (SELECT ... FROM inner_tables ...) AND ...outer_tables 表對 inner_tables 半連線的意思:
對於outer_tables的某條記錄來說,我們僅關心在inner_tables表中是否存在匹配的記錄,而不用關心具體有多少條記錄與之匹配,最終結果只保留 outer_tables 表的記錄。
每一個 SELECT 關鍵字的查詢都定義了一個 select_type 屬性,知道這個查詢屬性就能知道在整個查詢語句中所扮演的角色。
1)SIMPLE:簡單查詢。查詢不包含子查詢 和 UNION。
2)PRIMARY:複雜查詢中最外層的SELECT,可參照上面的 UNION 查詢語句。
3)SUBQUERY:包含的子查詢語句無法轉換為 semi-join,並且為不相關子查詢,查詢優化器採用物化方案執行該子查詢,該子查詢的第一個 SELECT 就會 SUBQUERY。該查詢由於被物化,只需要執行一次。
4)DERIVED:對於採用物化形式執行的包含派生表的查詢,該派生表的對應的子查詢為 DERIVED。
查詢語句如下所示:
EXPLAIN SELECT * FROM (SELECT id, count(*) as c FROM user GROUP BY id) AS derived_u where c>1;
5)UNION:在 UNION 查詢語句中的第二個和緊隨其後的 SELECT。
6)UNION RESULT:MySQL選擇使用臨時表完成 UNION 查詢的去重工作。
當 select_type 為這個值時,經常可以看到table的值是 <unionN,M>,這說明匹配的 id 行 是這個集合的一部分。請看上面 UNION 查詢示例。
7)MATERIALIZED:當查詢優化器執行包含子查詢的語句時,選擇將子查詢物化之後與外層查詢進行連線查詢時,該子查詢型別為 MATERIALIZED。
8)DEPENDENT SUBQUERY:包含的子查詢語句無法轉換為 semi-join,並且為相關子查詢,則該子查詢的第一個 SELECT 就會 DEPENDENT SUBQUERY。該查詢可能會被執行多次。
8)DEPENDENT UNION:包含的子查詢語句中包含了 UNION 或者 UNION ALL 的大查詢,這些查詢都依賴外層查詢,這些子查詢語句型別為 DEPENDENT UNION。
EXPLAIN SELECT * FROM user WHERE id IN (SELECT user_id FROM user_group WHERE name = 'a' UNION SELECT id FROM user WHERE name = 'b');
上面這個子查詢語句中的 SELECT user_id FROM user_group WHERE name = 'a' 這個小查詢是第一個子查詢,所以它的 select_type 為 DEPENDENT SUBQUERY,而 SELECT id FROM user WHERE name = 'b' 這個查詢在 UNION 後面,所以它的 select_type 為 DEPENDENT UNION。
最常見的值包括:SIMPLE 、PRIMARY、DERIVED、UNION。
3、table 列
table 列表示 EXPLAIN 的單獨行的唯一識別符號。這個值可能是表名、表的別名或者一個未查詢產生臨時表的識別符號,如派生表、子查詢或集合。
當 FROM 子句中有子查詢時,如果優化器採用的物化方式,table 列是 <derivenN> 格式,表示當前查詢依賴 id=N 的查詢,於是先執行 id=N 的查詢。
當使用 UNION 查詢時,UNION RESULT 的 table 列的值為 <UNION1,2>,1和2表示參與 UNION 的 SELECT 的行 id。
4、type 列
這一列表示關聯型別或訪問型別,即MySQL決定如何查詢表中的行,查詢資料行記錄的大概範圍。
依次從最優到最差分別為:system > const > eq_ref > ref > range > index > ALL
一般來說,得保證查詢達到range級別,最好達到ref
NULL:mysql能夠在優化階段分解查詢語句,在執行階段用不著再訪問表或索引。例如:在索引列中選取最小值,可以單獨查詢索引來完成,不需要在執行時訪問表。
1)system,const:MySQL 能對查詢的某部分進行優化並將其轉化成一個常量。用於主鍵或唯一二級索引列與常數比較時,所以表最多有一個匹配行,讀取1次,速度比較快。system是 const 的特例,表裡只有一條記錄匹配時為 system。
EXPLAIN SELECT * FROM (SELECT * FROM user where id = 1) tmp;
2)eq_ref:在連線查詢時,如果被驅動表是通過主鍵或者唯一二級索引列等值匹配的方式進行訪問的,則對該被驅動表的訪問方法就是 eq_ref。這可能是在 const 之外最好的聯接型別了。
EXPLAIN SELECT * FROM user_group INNER JOIN user ON user_group.user_id = user.id;

3)ref:相比 eq_ref,不使用唯一索引,而是使用普通索引或者唯一性索引的部分字首,索引要和某個值相比較,可能會找到多個符合條件的行。
a. 簡單 SELECT 查詢,name 是普通索引(非唯一索引)。
EXPLAIN SELECT * FROM user where user.name = 'a';

b. 關聯表查詢,idx_user_group_id (user_id,group_id) 為聯合索引,這裡使用到了user_group聯合索引最左邊字首 user_id。
EXPLAIN SELECT user_id FROM user LEFT JOIN user_group ON user.id = user_group.user_id;

4)ref_or_null:對普通二級索引進行等值查詢,該索引列也可以為NULL值時。
EXPLAIN SELECT * FROM user where user.name = 'a' OR name IS NULL;

5)index_merge:MySQL使用索引合併的方式執行的。
EXPLAIN SELECT * FROM user WHERE user.name = 'a' OR user.id = 1;

6)range:使用索引獲取範圍區間的記錄,通常出現在 in, between ,> ,<, >= 等操作中。
EXPLAIN SELECT * FROM user WHERE user.id > 1;

7)index:掃描全表索引,這通常比ALL快一些。(index是從索引中讀取的,而 ALL 是從硬碟中讀取)
group 表裡的兩個欄位都有索引。
EXPLAIN SELECT * FROM group;

8)ALL:即全表掃描,MySQL 需要從頭到尾去查詢表中所需要的行。通常情況下這需要增加索引來進行優化了。
EXPLAIN SELECT * FROM user;

5、possible_keys 列
possible_keys 列表示查詢可能使用哪些索引來查詢。
EXPLAIN 執行計劃結果可能出現 possible_keys 列,而 key 顯示 NULL 的情況,這種情況是因為表中資料不多,MySQL 會認為索引對此查詢幫助不大,選擇了全表查詢。
如果 possible_keys 列為 NULL,則沒有相關的索引。在這種情況下,可以通過檢查 WHERE 子句去分析下,看看是否可以創造一個適當的索引來提高查詢效能,然後用 EXPLAIN 檢視效果。
另外注意:不是這一列的值越多越好,使用索引過多,查詢優化器計算時查詢成本高,所以如果可能的話,儘量刪除那些不用的索引。
6、key 列
key 列表示實際採用哪個索引來優化對該表的訪問。
如果沒有使用索引,則該列是 NULL。如果想強制 MySQL使用或忽視 possible_keys 列中的索引,在查詢中使用 force index、ignore index。
7、key_len 列
key_len 列表示當查詢優化器決定使用某一個索引查詢時,該索引記錄的最大長度。
key_len 列計算規則如下:
- 字串
char(n):n位元組長度
varchar(n):2位元組儲存字串長度,如果是utf-8,則長度 3n + 2
注意:該索引列可以儲存NULL值,則key_len比不可以儲存NULL值時多1個位元組。
比如:varchar(50),則實際佔用的key_len長度是 3 * 50 + 2 = 152,如果該列允許儲存NULL,則key_len長度是153。
- 數值型別
tinyint:1位元組
smallint:2位元組
int:4位元組
bigint:8位元組
- 時間型別
date:3位元組
timestamp:4位元組
datetime:8位元組
索引最大長度是768位元組,當字串過長時,MySQL 會做一個類似左字首索引的處理,將前半部分的字元提取出來做索引。
舉例1:
user_group表中的聯合索引 idx_user_group_id 由 user_id 和 group_id 兩個int 列組成,並且每個 int 是 4 位元組。
EXPLAIN SELECT * FROM user_group WHERE user_id = 2;

通過結果中的 key_len=4可推斷出查詢使用了第一個列:user_id 列來執行索引查詢。
舉例2:
再看 user 表 name 欄位是 varchar(45) 變長字串型別,key_len為138 等於 45 * 3 + 2 (變長位元組) + 1位元組(允許儲存NULL值)
EXPLAIN SELECT * FROM user WHERE name = 'a';

所以,以後再看到 key_len 欄位的值,不要在懵逼咯,固定套路~
8、ref 列
ref 列顯示了在 key 列記錄的索引中,表查詢值所用到的列或常量,常見的有:const(常量),欄位名(例:user.id)。
9、rows 列
rows 列是查詢優化器估計要讀取並檢測的行數,注意這個不是結果集裡的行數。
如果查詢優化器使用全表掃描查詢,rows 列代表預計的需要掃碼的行數;
如果查詢優化器使用索引執行查詢,rows 列代表預計掃描的索引記錄行數。
10、filtered 列
對於單表來說意義不大,主要用於連線查詢中。
前文中也已提到 filtered 列,是一個百分比的值,對於連線查詢來說,主要看驅動表的 filtered列的值 ,通過 rows * filtered/100 計算可以估算出被驅動表還需要執行的查詢次數。
EXPLAIN SELECT * FROM user INNER JOIN user_group ON user.id = user_group.user_id WHERE user.update_time = '2019-01-01';

可以看到驅動表user執行的rows列為3行,filtered列為 33.33,計算驅動表的扇出值為 3 * 33.33% 約等於1,說明還需要對被驅動表執行大約1次查詢。
11、Extra 列
Extra 列提供了一些額外資訊。這一列在 MySQL中提供的資訊有幾十個,這裡僅列舉一些常見的重要值如下:
1)Using index:查詢的列被索引覆蓋,並且 WHERE 篩選條件是索引的前導列,使用了索引效能高。一般是使用了覆蓋索引(查詢列都是索引列欄位)。對於 INNODB 儲存引擎來說,如果是輔助索引效能會有不少提高,並且也不需要回表查詢。
2)Using where Using index:查詢的列被索引覆蓋,並且 WHERE 篩選條件是索引列之一,但並不是索引的前導列,意味著無法直接通過索引查詢來查詢到符合條件的資料。
3)NULL:查詢的列未被索引覆蓋,並且 WHERE 篩選條件是索引的前導列,意味著用到了索引,但是部分欄位未被索引覆蓋,必須通過 回表 來查詢,不是純粹地用到了索引,也不是完全沒用到索引。
4)Using index condition:與Using where類似,查詢的列不完全被索引覆蓋,WHERE 條件中是一個前導列的範圍。
5)Using temporary:MySQL 中需要建立一張內部臨時表來處理查詢,一般出現這種情況就需要考慮進行優化了,首先是想到用索引來優化。
通常在許多執行包括DISTINCT、GROUP BY、ORDER BY等子句查詢過程中,如果不能有效利用索引來完成查詢,MySQL很有可能會尋求建立內部臨時表來執行查詢。
所以,執行計劃中出現了 Using temporary 並不是個好兆頭,因為建立與維護臨時表要付出很大的成本的,要考慮使用索引來優化改進。
6)Using filesort:MySQL 會對結果使用一個外部索引排序,而不是按索引次序從表裡讀取行。此時 MySQL 會根據聯接型別瀏覽所有符合條件的記錄,並儲存排序關鍵字和行指標,然後排序關鍵字並按順序檢索行資訊。這種情況下一般也是要考慮使用索引來優化的。
查詢中需要使用 filesort 的方式進行排序的記錄非常多,那麼這個過長是很耗時的,想辦法將使用 檔案排序 的執行方式改進為使用索引進行排序。
7)Index merges:通常顯示為Using sort_union(...) 說明準備用 Sort-Union 索引合併方式來查詢;顯示為 Using union(...),說明準備用Union索引合併方式查詢;顯示為Using intersect(...),說明準備使用Intersect索引合併方式查詢。
8)LooseScan:在 IN 子查詢轉為 semi-join 時,如果採用的是 LooseScan 執行策略,則會在Extra中提示。
9)FirstMatch(tbl_name):在 IN 子查詢轉為 semi-join 時,如果採用的是 FirstMatch 執行策略,則會在Extra中提示。
10)Using join buffer:強調了在獲取連線條件時沒有使用索引,並且需要連線緩衝區來儲存中間結果。出現該值,應該注意,根據查詢的具體情況可能需要新增索引來改進效能。
我們所提到的回表操作 ,其實是一種隨機IO,比較耗時,所以儘量避免上面提到的回表操作,當發現Extra提示為 Using filesort、Using temporary 時就需要格外注意了,考慮索引優化。
3、最佳姿勢索引實踐
新建 staff 表表演使用:
# 重建 `staff` 表
DROP TABLE `staff`;
CREATE TABLE `staff` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(24) NOT NULL DEFAULT '' COMMENT '姓名',
`s_name` VARCHAR(24) NOT NULL DEFAULT '' COMMENT '花名',
`s_no` INT(4) NOT NULL DEFAULT 0 COMMENT '工號',
`work_age` int(11) NOT NULL DEFAULT '0' COMMENT '工齡',
`position` varchar(20) NOT NULL DEFAULT '' COMMENT '職位',
`arrival_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '入職時間',
`remark` VARCHAR(500) DEFAULT NULL COMMENT '備註', # 允許 NULL
PRIMARY KEY (`id`), # 主鍵
UNIQUE KEY idx_s_name (s_name), # 唯一索引
KEY idx_s_no (s_no), # 普通索引
KEY `idx_name_age_position` (`name`,`work_age`,`position`) USING BTREE # 聯合索引
) ENGINE=InnoDB AUTO_INCREMENT=4 DEFAULT CHARSET=utf8 COMMENT='員工記錄表';
# 初始化 `staff` 表資料
INSERT INTO staff(name,s_name,s_no,work_age,position,arrival_time) VALUES('zhangsan','zs',10,2,'manager',NOW());
INSERT INTO staff(name,s_name,s_no,work_age,position,arrival_time) VALUES('lisi','ls',11,3,'dev',NOW());
INSERT INTO staff(name,s_name,s_no,work_age,position,arrival_time) VALUES('wangwu','ww',12,8,'dev',NOW());
INSERT INTO staff(name,s_name,s_no,work_age,position,arrival_time) VALUES('zhangliu','zl',110,5,'dev',NOW());
INSERT INTO staff(name,s_name,s_no,work_age,position,arrival_time) VALUES('xiaosun','xs',111,5,'dev',NOW());
INSERT INTO staff(name,s_name,s_no,work_age,position,arrival_time) VALUES('donggua','dg',200,3,'dev',NOW());
資料庫索引最佳實踐
1、全值匹配:
EXPLAIN SELECT * FROM staff WHERE name= 'zhangsan';

EXPLAIN SELECT * FROM staff WHERE name= 'zhangsan' AND work_age = 2;

EXPLAIN SELECT * FROM staff where name = 'zhangsan' AND work_age = 2 AND position = 'dev';

EXPLAIN SELECT * FROM staff where position = 'dev' AND name = 'zhangsan' AND work_age = 2;

最後一條,我們將 position 放到了 WHERE 條件後面,儘管沒有按照聯合索引的順序編寫條件,MySQL 優化器會自動優化,將 name 排到最前面去,所以還是會正確使用聯合索引的。
聯合索引建立後,你必須嚴格按照最左字首的原理進行使用,否則會無法使用到索引。儘量按照這個順序去寫,這樣避免 MySQL 優化器再次優化了。
2、最佳左字首法則:
如果索引了多列,要遵守最左字首法則。指的是查詢從索引的最左前列開始並且不跳過索引中的列。
以下 SQL 符合最左字首匹配法則:
EXPLAIN SELECT * FROM staff WHERE name = 'zhangsan' AND work_age = 3 AND position = 'manager';

EXPLAIN SELECT * FROM staff WHERE name = 'zhangsan' AND position = 'manager';

以下執行都是全表掃描,type 為 ALL,都不符合最左字首法則:
EXPLAIN SELECT * FROM staff WHERE work_age = 2 AND position ='dev';

EXPLAIN SELECT * FROM staff WHERE position = 'dev';

3、索引列上避免做計算操作
索引上儘量避免做函式計算等操作,會導致索引失效而轉向全表掃描。
WHERE 條件後面索引列使用函式:
EXPLAIN SELECT * FROM staff WHERE LEFT(name, 5) = 'zhang';
EXPLAIN SELECT * FROM staff WHERE LOWER(name) = 'zhangsan';

EXPLAIN SELECT * FROM staff WHERE staff.s_no * 2 > 3;

查詢的結果 type 列為 ALL,key 是空的,索引失效,全表掃描。
計算邏輯儘量放到業務層去處理,最大限度的命中索引,同時還能節省資料庫資源開銷。
4、儲存引擎無法使用索引中範圍條件右邊的列
EXPLAIN SELECT * FROM staff WHERE name= 'zhangsan' AND work_age > 2 AND position ='dev';

我們看到了執行結果中 type 為 range 級別,使用了範圍查詢,而 position 欄位並沒有用到索引(沒有使用到BTree的索引去查詢),只是從 name = 'zhangsan' AND work_age > 2 條件返回的結果集中,再過濾符合 position 欄位條件的資料。
5、儘量使用覆蓋索引
覆蓋索引:簡單理解,只訪問建了索引的列。減少使用 SELECT * 語句查詢列。
使用了覆蓋索引:
EXPLAIN SELECT name,work_age FROM staff WHERE name= 'zhangsan' AND work_age = 3;

使用了 SELECT * 查詢:
EXPLAIN SELECT * FROM staff WHERE name= 'zhangsan' AND work_age = 3;

我們重點看下使用了 覆蓋索引 方式查詢,會在結果中 Extra 列顯示 Using index ,這說明在查詢列包含了索引列,不需要再次回表查詢了。而如果使用 SELECT * 方式查詢,查詢列包含非索引的列,Extra 顯示為 NULL,所以還會進行回表查詢。
附一個曾經線上SQL的優化記錄:

artist 表有幾十萬條的資料量,第一條執行的SQL沒有索引直接查詢,查詢耗時 0.557 毫秒;第一次優化新建 founded 欄位作為普通索引,查詢耗時 0.0224 毫秒;第二次優化再次重建聯合索引 founded_name,優化後查詢耗時:0.0051 毫秒。因為使用了覆蓋索引查詢方式,基於此優化,SQL查詢效率提升非常明顯。
6、範圍條件查詢能夠命中索引
範圍條件主要包括 <、<=、>、>=、between 等。
若條件中範圍列有普通索引和主鍵索引同時存在, 優先使用主鍵索引:
EXPLAIN SELECT * FROM staff WHERE staff.s_no > 10 AND staff.id > 2;

範圍列可以用到索引,注意聯合索引必須符合最左字首法則,如果查詢條件中有兩個範圍列則無法全用到索引,優化器會去選擇:
EXPLAIN SELECT * FROM staff WHERE staff.name != 'zl' AND staff.s_no > 1;

若條件中範圍查詢和等值查詢同時存在,優先匹配等值查詢列的索引:
EXPLAIN SELECT * FROM staff WHERE staff.s_no > 10 AND staff.s_name = 'zl';

7、索引列不為 NULL,IS NOT NULL無法使用索引
索引列建議都使用 NOT NULL 約束 及預設值,單列索引不存 NULL 值,聯合索引不存全部為 NULL 的值,如果列允許為 NULL,查詢結果可能不符合預期。
staff 表中為 remark 欄位新建普通索引:
ALTER TABLE staff ADD INDEX idx_remark (remark);IS NULL 查詢命中索引:
EXPLAIN SELECT * FROM staff WHERE staff.remark IS NULL;

IS NOT NULL 查詢不會命中索引:
EXPLAIN SELECT * FROM staff WHERE staff.name IS NOT NULL;

8、模糊條件查詢以萬用字元開頭索引失效
like '%xx' 或 like '%xx%' 前導模糊查詢不能命中索引:
EXPLAIN SELECT * from staff where name like '%zhang%';

如何使用模擬查詢才能命中索引?
a)like 'xx%' 非前導模糊查詢可以命中索引:
EXPLAIN SELECT * FROM staff WHERE name LIKE 'zhang%';

b)使用覆蓋索引,查詢欄位必須要建立覆蓋索引欄位
EXPLAIN SELECT name,work_age FROM staff WHERE name LIKE '%zhang%';
聯合索引是 idx_name_work_age_position

9、字串型別不加單引號索引失效
字串的資料型別一定要將常量值使用單引號,這個在日常開發中要特別注意的,資料型別出現隱式轉換的時候不會命中索引。
不加單引號索引失效
EXPLAIN SELECT * FROM staff WHERE name = 1;

name=1 類似於在該欄位上做了一個函式運算,因此不會走索引的。
加單引號會命中索引:
EXPLAIN SELECT * FROM staff WHERE name = 'zhangsan';

10、OR 使用多數情況下索引會失效
EXPLAIN SELECT * FROM staff WHERE name='zhangsan' OR work_age = 2;

儘管 name 和 work_age 是聯合索引,但是 work_age 列上並沒有建索引,所以使用了 OR 不會走索引。
如果 OR 前後都是聯合索引帶頭大哥 name 欄位,那麼就會用到索引,如下所示:

因 OR 後面的條件列中沒有索引,會走全表掃描。存在全表掃描的情況下,就沒有必要多一次索引掃描增加IO訪問。
可使用覆蓋索引查詢:
EXPLAIN SELECT name,work_age FROM staff WHERE name='zhangsan' OR work_age = 2;

** OR 後面也使用索引列:**
EXPLAIN SELECT * FROM staff WHERE name='zhangsan' OR s_name='wangwu';

s_name 是唯一索引,name是聯合索引第一個欄位,兩者使用 OR 查詢結果 Extra 顯示 Using sort_union(idx_name_age_position,idx_s_name); Using where 解釋一下。
如果執行計劃 Extra 列出現了 Using sort_union(...) 的提示,說明準備使用 Sort-Union 索引合併的方式執行查詢。如果出現了 Using intersect(...) 的提示,說明準備使用 Intersect 索引合併方式執行查詢,如果出現了 Using union(...) 的提示 ,說明準備使用 Union 索引合併方式執行查詢。 括號中 ... 表示需要進行索引合併的索引名稱。
使用UNION優化改進:
EXPLAIN SELECT * FROM staff WHERE name='zhangsan' UNION SELECT * FROM staff WHERE s_name = 'zs';

使用 UNION 執行計劃中出現了第三條記錄,Extra 中出現 Using temporary,說明 MySQL因為不能有效利用索引,建立了內部臨時表來執行查詢。當你在使用 DISTINCT 、GROUP BY、UNION 等子句中的查詢過程中,都有可能會出現該擴充套件資訊。
使用UNION ALL進一步優化:
EXPLAIN SELECT * FROM staff WHERE name='zhangsan' UNION ALL SELECT * FROM staff WHERE s_name = 'zs';

執行結果中不再出現內部臨時表,具體用的時候結合實際需求來定是否使用。
11、負向查詢條件不能使用索引,可以優化為 IN 查詢
負向查詢條件包括:!=、<>、NOT IN、NOT EXISTS、NOT LIKE 等。
不會命中索引:
EXPLAIN SELECT * FROM staff WHERE s_no !=1 AND s_no != 2;
EXPLAIN SELECT * FROM staff WHERE s_no NOT IN (1,2);

使用IN優化,命中索引:
EXPLAIN SELECT * FROM staff WHERE s_no IN (11,12);

但是使用 IN 命中索引有個前提,是查詢條件欄位資料區分度要高,通常如:狀態、型別、性別之類的欄位。
** 12、排序對索引的影響**
ORDER BY是經常用的語句,排序也遵循最左字首列的原則。
查詢所有列未命中索引:
EXPLAIN SELECT * FROM staff ORDER BY name,work_age;

覆蓋索引查詢可命中索引:

覆蓋索引能夠利用聯合索引查詢,但是 ORDER BY 後的條件查詢不符合最左字首原則,執行結果 Extra 中出現了 Using filesort 的提示,一般看到這個就要想辦法優化了。
調整排序的兩個欄位順序之後,Extra 會提示為 Using index,使用了索引,避免了排序的資源開銷:
EXPLAIN SELECT name,work_age FROM staff ORDER BY name,work_age;

** 13、區域性索引的使用**
區域性索引,區別於最左列索引(順序取索引中靠左的列的查詢),它只取某列的一部分作為索引。
INNODB儲存引擎下,一般是字串型別,很長,全部作為索引大大增加儲存空間,索引也需要維護,對於長字串,又想作為索引列,可取的辦法就是取前一部分(區域性),代表一整列作為索引串。
如何確保這個字首能代表或大致代表這一列?MySQL中有個概念是 索引選擇性,是指索引中不重複的值的數目(也稱基數X)與整個表該列記錄總數(T)的比值。基數可以通過SHOW INDEX FROM 表名 檢視。
比如一個列表 [1,2,2,3,5,6],總數是 6,不重複值數目為 5,選擇性為 5/6,因此選擇性範圍是[X/T, 1],這個值越大,表示列中不重複值越多,越適合作為區域性索引,而唯一索引(UNIQUE KEY)的選擇性是1。
`SELECT COUNT(DISTINCT(CONCAT(LEFT(remark, N))/COUNT(*) FROM t; 測試出接近 1 的索引選擇性,其中N是索引的長度,窮舉法去找出N的值,然後再建索引。
建立 區域性索引 ,使用 remark 欄位舉個例子
EXPLAIN SELECT * FROM staff where remark LIKE 'xxx%';

對 remark 欄位重建區域性索引:
ALTER TABLE staff DROP INDEX idx_remark_part, ADD INDEX idx_remark_part(remark(5));再次執行查詢:
EXPLAIN SELECT * FROM staff where remark LIKE 'xxx%';

索引優化總結
上面列了大部分場景索引最佳實戰,除此之外,不宜建索引的幾點小總結:
1)更新非常頻繁欄位不宜建索引
因為欄位更新臺頻繁,會導致B+樹的頻繁的變更,重建索引。所以這個過程是十分消耗資料庫效能的。
2)區分度不大的欄位不宜建索引
比如類似性別這類的欄位,區分度不大,建立索引的意義不大。因為不能有效過濾資料,效能和全表掃描相當。另外注意一點,返回資料的比例在 30% 之外的,優化器不會選擇使用索引。
3)業務中有唯一特性的欄位,建議建成唯一索引
業務中如果有唯一特性的欄位,即使是多個欄位的組合,也儘量都建成唯一索引。儘管唯一索引會影響插入效率,但是對於查詢的速度提升是非常明顯的。此外,還能夠提供校驗機制,如果沒有唯一索引,高併發場景下,可能還會產生髒資料。
4)多表關聯時,要確保關聯欄位上必須有索引
5)建立索引時避免建立錯誤的認識
索引越多越好,認為一個查詢就需要建一個索引。
寧缺勿濫,認為索引會消耗空間、嚴重拖慢更新和新增速度。
抵制唯一索引,認為業務的唯一性一律需要在應用層通過“先查後插”方式解決。
過早優化,在不瞭解系統的情況下就開始優化。
6)最佳索引實踐口訣
如果你覺得上面哪些太囉嗦,有朋友已總結為一套優化口訣,優化SQL時也能提個醒吧。
全值匹配我最愛,最左字首要遵守;
帶頭大哥不能死,中間兄弟不能斷;
索引列上少計算,範圍之後全失效;
Like百分寫最右,覆蓋索引不寫星;
不等空值還有or,索引失效要少用;
VAR引號不可丟,SQL高階也不難!
7)EXPLAIN 執行計劃實踐總結
如果還是覺得 EXPLAIN 執行計劃列太多了,也記不住呀,那麼請重點關注以下幾列:
第1列:ID越大,執行的優先順序越高;ID相等,從上往下優先順序執行。
第2列:select_type 查詢語句的型別,SIMPLE簡單查詢,PRIMARY複雜查詢,DERIVED衍生查詢(from子查詢的臨時表),派生表。
第4列:請重點掌握,type型別,查詢效率優先順序:system->const->eq_ref->ref->range->index->ALL
ALL 是最差的,system 是最好的,效能最佳,阿里巴巴開發規約中要求最差也得到 range 級別,而不能有 index、ALL。
最後,對於後端工程師而言,盡力都能掌握 EXPLAIN 的使用,寫完SQL請習慣性的用它幫助你分析一下,做一個對SQL效能有追求的程式設計師,因為SQL也是程式設計師必備技能,將慢查詢問題拍死在專案上線前夕。
如果覺得本文有所收穫,歡迎轉發分享。
參考資料:
MySQL官網
https://www.cnblogs.com/songwenjie/p/9402295.html
https://www.cnblogs.com/phpdragon/p/8231533.html
歡迎關注我的公眾號,掃二維碼關注獲得更多精彩原創文章,與你一同成長~

相關推薦
一本徹底搞懂MySQL索引優化EXPLAIN百科全書
1、MySQL邏輯架構 日常在CURD的過程中,都避免不了跟資料庫打交道,大多數業務都離不開資料庫表的設計和SQL的編寫,那如何讓你編寫的SQL語句效能更優呢? 先來整體看下MySQL邏輯架構圖: MySQL整體邏輯架構圖可以分為Server和儲存引擎層。 Server層: Server層涵蓋了MySQL
徹底搞懂MySQL為什麼要使用B+樹索引
[toc] 搞懂這個問題之前,我們首先來看一下MySQL表的儲存結構,再分別對比二叉樹、多叉樹、B樹和B+樹的區別就都懂了。 # MySQL的儲存結構 ## 表儲存結構 和例項(instance),類是抽象的模板,比如學生這個抽象的事物,可以用一個Student類來表示。而例項是根據類創建出來的一個個具體的“物件”,每一個物件都
一文徹底搞懂python的垃圾回收機制
一 、什麼是記憶體管理和垃圾回收 Python GC主要使用引用計數(reference counting)來跟蹤和回收垃圾。在引用計數的基礎上,通過“標記-清除”(mark and sweep)解決容器物件可能產生的迴圈引用問題,通過“分代回收”(genera
一文徹底搞懂卷積神經網路的“感受野”,看不懂你來找我!
一、什麼是“感受野” 1.1 感受野的概念 “感受野”的概念來源於生物神經科學,比如當我們的“感受器”,比如我們的手受到刺激之後,會將刺激傳輸至中樞神經,但是並不是一個神經元就能夠接受整個面板的刺激,因為面板面積大,一個神經元可想而知肯定接受不完,而且我們同
一文徹底搞懂linux全域性環境變數生效順序
一、前言在登入linux系統並啟動一個bash shell時,預設情況下bash會在若干個檔案中查詢環境變數的設定。這些檔案可統稱為系統環境檔案。⭐️bash檢查環境變數檔案的情況取決於系統執行shell的方式 二、系統執行Shell的方式1、通過系統使用者登陸後預設執行的shell2、非登入互動式執行sh
一文徹底搞懂linux全局環境變量生效順序
錯誤 一個 支持 個人 檢查 技術分享 生效 water 正版 一、前言在登錄linux系統並啟動一個bash shell時,默認情況下bash會在若幹個文件中查找環境變量的設置。這些文件可統稱為系統環境文件。??bash檢查環境變量文件的情況取決於系統運行shell的方式
一文徹底搞懂股權投資中GP/LP關係! | 資本智庫
https://www.sohu.com/a/157617708_393543 國內股權投資市場是一個西學東漸的過程。三十餘年來,伴隨國內經濟體制改革的不斷深化、創新創業的全面開展,股權投資行業從無到有,從不毛沙漠變成燦然綠洲,雙創口號下,大勢依然強勁,經歷過功過成敗、喜怒反思,正昂首闊步邁向“
一文快速搞懂MySQL InnoDB事務ACID實現原理
test 用戶 bin 輔助索引 做的 text 訪問 通過 可重復 【51CTO.com原創稿件】說到數據庫事務,想到的就是要麽都做修改,要麽都不做,或者是 ACID 的概念。其實事務的本質就是鎖、並發和重做日誌的結合體。 這一篇主要講一下 InnoDB 中的事務到底是如
這一次徹底搞懂 Git Rebase
一、起因 上線構建的過程中掃了一眼程式碼變更,突然發現, commit 提交竟然多達 62 次。我們來看看都提交了什麼東西: 這裡我們先不說 git 提交規範,就單純這麼多次無用的 commit 就很讓人不舒服。可能
這一次 徹底搞懂Vue針對陣列和雙向繫結(MVVM)的處理方式
歡迎關注我的部落格:https://github.com/wangweianger/myblog Vue內部實現了一組觀察陣列的
一文徹底搞懂CAS實現原理 & 深入到CPU指令
本文導讀: 前言 如何保障執行緒安全 CAS原理剖析 CPU如何保證原子操作 解密CAS底層指令 小結 朋友,文章優先發布在公眾號上,如果你願意,可以掃右側二維碼支援一下下~,謝謝! 前言 日常編碼過程中,基本不會直接用到 CAS 操作,都是通過一些JDK 封裝好的併發工具類來使用的,在 java.
一文徹底讀懂MySQL事務的四大隔離級別
## 前言 之前分析一個死鎖問題,發現自己對資料庫隔離級別理解還不夠清楚,所以趁著這幾天假期,整理一下MySQL事務的四大隔離級別相關知識,希望對大家有幫助~  ## 一、索引是什麼 MySQL官方對索引的定義為:索引(Index)是幫助MySQL **高效** 獲取資料的資料結構,而MYSQL使用的資料結構是:*
一文徹底搞懂JS前端5大模組化規範及其區別
## 碼文不易,轉載請帶上本文連結,感謝~ https://www.cnblogs.com/echoyya/p/14577243.html [toc] 在開發以及面試中,總是會遇到有關模組化相關的問題,始終不是很明白,不得要領,例如以下問題,回答起來也是模稜兩可,希望通過這篇文章,能夠讓大家瞭解十之一二,
徹底搞懂狀態機(一段式、兩段式、三段式)
例項:FSM實現10010串的檢測 狀態轉移圖:初始狀態S0,a = 0,z = 0.如果檢測到1,跳轉到S1。 下一狀態S1,a = 1,z = 0.如果檢測到0,跳轉到S2。 &nb
mysql 索引優化的要點(系列一)
背景:sql 優化對資料來說是什麼非常重要,sql的索引優化更重中之重,有的人認為索引優化就是簡單加一個索引,其實這種想法是錯的,索引是涉及到很多知識點,並非大家想得這麼簡單,廢話不多說,馬上開車! 一,頭盤: SQL語句的五大要素:1,獲得結果集所需訪問的查詢條件2,定義結果集所需的查詢條件3,結果集的
徹底搞懂Scrapy的中介軟體(一)
中介軟體是Scrapy裡面的一個核心概念。使用中介軟體可以在爬蟲的請求發起之前或者請求返回之後對資料進行定製化修改,從而開發出適應不同情況的爬蟲。 “中介軟體”這個中文名字和前面章節講到的“中間人”只有一字之差。它們做的事情確實也非常相似。中介軟體和中間人都能在中途劫持資料,做一些修改再把資料傳遞出去。不同點
10年架構師圖解單鏈表,一篇圖文徹底搞懂
§單鏈表的定義 每一個節點都有一個向後的指標(引用)指向下一個節點,最後一個節點指向NULL表示結束,有一個Head(頭)指標指向第一個節點表示開始。如下圖: §單鏈表的特點 耗子戴眼鏡,鼠目寸光 我們只能拿到頭節點,(在不逐個遍歷的情況下),後面還有多