
QQ群資訊爬取
阿新 • • 發佈:2019-02-19
需要安裝谷歌瀏覽器,下載chrome.exe放到python的安裝路徑下
#coding=utf-8
from lxml import etree
import time
from selenium import webdriver
class qqGroupSpider():
'''
Q群爬蟲類
'''
def __init__(self, driver,qq,passwd,qqgroup,writefile):
'''
初始化根據使用者資訊登入到Q群管理介面
:param driver:
:param qq:
:param passwd:
:param qqgroup:
:param writefile:
''' 執行如下:
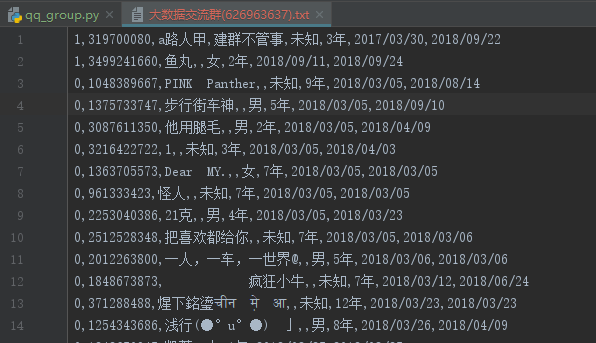
爬取出的資料儲存成文字檔案,格式:是否群管理,暱稱,群名片,QQ號,性別,q齡,入群時間,等級,最後發言
我的郵箱:[email protected]
我的GitHub賬號:https://github.com/LoyalWilliams
我建了一個大資料的學習交流群
QQ:2541692705
Q群:882855741
微信公眾號:程式國度
