
Java之學習筆記(17)---------------變數和許可權
首先先總結一下變數的具體內容
Java變數的宣告在 Java 程式設計中,每個宣告的變數都必須分配一個型別。宣告一個變數時,應該先宣告變數的型別,隨後再宣告變數的名字。下面演示了變數的宣告方式。
double salary;
int age;
Boolean op;
其中第一項稱為變數型別,第二項稱為變數名。分號是必須的,這是 Java 語句的結束符號。
同一型別的不同變數,可以宣告在一行,也可以宣告在不同行,如果要宣告在同一行中,不同的變數之間用逗號分隔,例如下面的例子。
int studentNumber,people;
宣告變數的同時可以為變數賦值,也可以宣告以後再賦值。
int a=1; //宣告時賦值
int a; a=1; //聲明後賦值
注意:在程式執行過程中,空間內的值是變化的,這個記憶體空間就稱為變數。為了操作方便,給這個空間取了個名字,稱為變數名,記憶體空間內的值就是變數值。所以,申請了記憶體空間,變數不一定有值,要想變數有值,就必須要放入值。
例如:“int x”; 定義了變數但沒有賦值,即申請了記憶體空間,但沒有放入值;int x=5; 不但申請了記憶體空間而且還放入了值,值為 5。
注意:沒有賦值的變數,系統將按下列預設值進行初始化。
| 資料型別 | 初始值 |
|---|---|
| byte | 0 |
| short | 0 |
| int | 0 |
| long | 0L |
| char | '\u0000' |
| float | 0.0f |
| double | 0 |
| boolean | false |
| 所有引用型別 | null(不引用任何物件) |
二.變數的作用域(全域性變數|區域性變數)
根據作用域(作用範圍)來分,一般將變數分為全域性變數和區域性變數。從字面上理解很簡單,全域性變數就是在程式範圍之內都有效的變數,而區域性變數就是在程式中的一部分內是有效的。
在Java中,全域性變數就是在類的整個範圍之內,都有效的變數。而區域性變數就是在類中某個方法函式內或某個子類內,有效的變數,下面將從實際程式程式碼中慢慢的體會。
1.全域性變數示例
public class var{ ///a 是全域性變數
int a=10;
public static void main(String[] args){
var v=new var();
v.print();
}
void print(){
System.out.println("全域性變數 a="+a);
}
}
執行結果:
全域性變數 a=10
從以上例子可以看出,變數“a”的值在整個類中都有效。
2.區域性變數示例
public class Math1{ ///c 是區域性變數
public static void main(String[] args){
Math1 v=new Math1();
System.out.println("這個是區域性變數 c="+c);
}
void print(){
int c=20;
}
}
以上程式碼在編譯時,會出現錯誤,就是找不到變數“c”。這說明變數“c”只在方法“print()”中起作用,在方法外就無法再呼叫。
從上述程式碼中可以看出,如果一個變數在類中定義,那麼這個變數就是全域性變數;而在類中的方法、函式中定義的變數就是區域性變數。
三.全域性變數與區域性變數的宣告
public class var{
byte x; short y; int z; long a; float b;
double c; char d; boolean e;
public static void main(String[] args){
var m=new var();
System.out.println(" 列印資料 x="+m.x);
System.out.println(" 列印資料 y="+m.y);
System.out.println(" 列印資料 z="+m.z);
System.out.println(" 列印資料 a="+m.a);
System.out.println(" 列印資料 b="+m.b);
System.out.println(" 列印資料 c="+m.c);
System.out.println(" 列印資料 d="+m.d);
System.out.println(" 列印資料 e="+m.e);
}
}
執行結果:
列印資料 x=0
列印資料 y=0
列印資料 z=0
列印資料 a=0
列印資料 b=0.0
列印資料 c=0.0
列印資料 d=
列印資料 e=false
從以上例子可以看出,作為全域性變數,無需初始化,系統自動給變數賦值。除了字元型資料被賦值為空,布林型資料被賦值為 false,其他一律賦值為 0。下面再看一段程式程式碼段。
public class var1{
void printnumber(){
byte x; short y; int z; long a;
float b; double c; char d; boolean e;
}
public static void main(String[] args){
var1 m=new var1();
System.out.println(" 列印資料 x="+m.x);
System.out.println(" 列印資料 y="+m.y);
System.out.println(" 列印資料 z="+m.z);
System.out.println(" 列印資料 a="+m.a);
System.out.println(" 列印資料 b="+m.b);
System.out.println(" 列印資料 c="+m.c);
System.out.println(" 列印資料 d="+m.d);
System.out.println(" 列印資料 e="+m.e);
}
)
這個程式段編譯時就會報錯,原因是所有區域性變數都沒有初始化。從以上兩段程式程式碼得出一個結果:全域性變數可以不用進行初始化賦值工作,而區域性變數必須要進行初始化賦值工作。
java的記憶體分配問題
在任何程式語言中,無論是基本型別還是引用型別,不論其作用域如何,都必須為其分配一定的記憶體空間,Java 語言也不例外,Java 的資料型別可以分為兩種:基本型別(變數持有資料本身的值)和引用型別(是某個物件的引用,而並非是物件本身);基本型別包括:boolean、float、double、int、long、short、byte以及char;在Java程式語言中除基本型別以外其餘都是引用型別如:類型別、陣列型別等。
在計算機記憶體中主要來自四個地方:heap segment(堆區)、stack segment(棧區)、codesegment(程式碼區)、data segment(資料區);不同的地方存放不同資料:其中堆區主要存放Java程式執行時建立的所有引用型別都放在其中;棧區主要存放Java程式執行時所需的區域性變數、方法的引數、物件的引用以及中間運算結果等資料;程式碼區主要存放Java的程式碼;資料區主要存放靜態變數及全域性變數;以下結合例項來探討其具體機制。
| class Student { private String name; private int age; public Student(String name, int age) { this.name = name; this.age = age; } } public class Test { static int i = 10; public static void main(String[] args) { Student s1 = new Student(“feng”, 21); } } |
當該程式執行起來後,其計算機記憶體分佈大致如下:
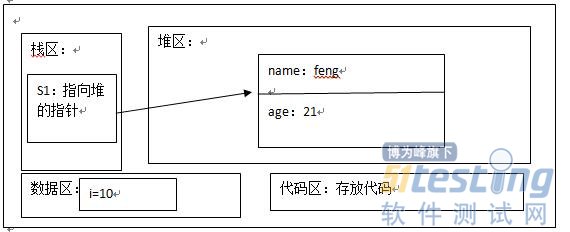
物件在內部表示Java虛擬機器規範並沒有規定其在堆中是如何表示的。物件的內部的表示會直接影響到堆區的設計以及垃圾收集器(GC)的設計。
Java在堆中的表示方法具體有兩種:
把堆分成兩個部分:一個控制代碼池,一個物件池;表示如下圖所示:
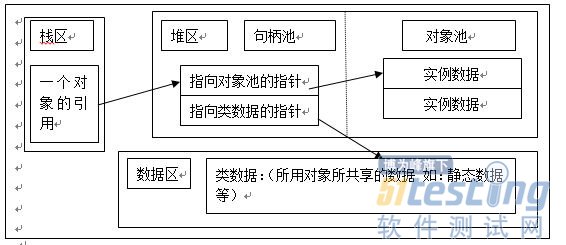
用物件指標直接指向一組資料,而該資料包括物件例項資料以及指向方法區中的資料的指標,具體如下圖所示:
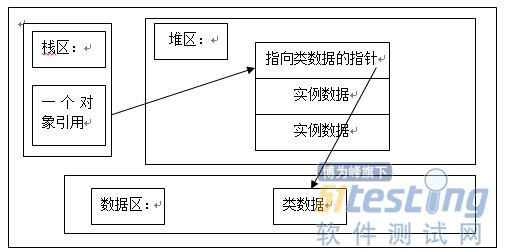
小結:通過對物件記憶體分配的分析,來使讀者對Java的底層有一個比較理性的認識,從而進一步掌握Java的基礎知識。在深入瞭解了Java記憶體的分配以後,才能為以後編寫高質量的程式打下堅實的基礎,而且可以借鑑該思想來分析其它面嚮物件語言的記憶體分配問題。
在網上又找了一些關於記憶體分配的資料與大家分享一下!寫的很詳細!
堆疊
靜態儲存區域
一個由C/C++編譯的程式佔用的記憶體分為以下幾個部分
1、棧區(stack)— 由編譯器自動分配釋放 ,存放函式的引數值,區域性變數的值等。其操作方式類似於資料結構中的棧。
2、堆區(heap)— 由程式設計師分配釋放, 若程式設計師不釋放,程式結束時可能由OS回收。注意它與資料結構中的堆是兩回事,分配方式倒是類似於連結串列。
3、全域性區(靜態區)(static)— 全域性變數和靜態變數的儲存是放在一塊的,初始化的全域性變數和靜態變數在一塊區域,未初始化的全域性變數和未初始化的靜態變數在相鄰的另一塊區域。程式結束後由系統釋放。
4、文字常量區 — 常量字串就是放在這裡的,程式結束後由系統釋放 。
5、程式程式碼區 — 存放函式體的二進位制程式碼。
Java中儲存地址:
暫存器register 這是速度最快的地方 資料位於和其他所有方式都不同的一個地方 處理器的內部 不過 暫存器的數量十分有限 所以暫存器是根據需要由編譯器分配我們對此沒有直接的控制權 也不可能在自己的程式裡找到暫存器存在的任何跡象。
JVM的暫存器用來存放當前系統狀態。然而,基於移植性要求,JVM擁有的暫存器數目不能過多。否則,對於任何本身的暫存器個數小於JVM的移植目標機,要用常規儲存來模擬高速暫存器,是比較困難的。同時JVM是基於棧(Stack)的,這也使得它擁有的暫存器較少。
JVM的暫存器包括下面四個:
(1)PC程式計數暫存器
(2)optop運算元棧棧頂地址暫存器。
(3)frame當前執行環境地址暫存器。
(4)vars區域性變數首地址暫存器。
這些暫存器長度均為32位。其中PC用來記錄程式執行步驟,其餘optop,frame,vars都存放JVM棧中對應地址,用來快速獲取當前執行所需的資訊。
堆疊stack 堆疊位於常規 RAM 隨機訪問儲存器 內 但可通過它的 堆疊指標 獲得處理器的直接支援 堆疊指標若向下移 會建立新的記憶體 若向上移則會釋放那些記憶體這是一種特別快 特別有效的資料儲存方式 僅次於暫存器 建立程式時 Java編譯器必須準確地知道堆疊內儲存的所有資料的長度 以及 存在時間 這是由於它必須生成相應的程式碼 以便向上和向下移動指標 這一限制無疑影響了程式的靈活性 所以儘管有些 Java資料要儲存在堆疊裡 特別是物件引用 但 Java 物件並不放到其中
在函式中定義的一些基本型別的變數和物件的引用變數都在函式的堆疊 中分配 。
當在一段程式碼塊定義一個變數時,Java就在棧中為這個變數分配記憶體空間,當超過變數的作用域後,Java會自動釋放掉為該變數所分配的記憶體空間,該記憶體空間可以立即被另作他用。 所以儘量使用基本型別的變數.
堆(或 記憶體堆 heap) 一種常規用途的記憶體池 也在 RAM 內 所有 Java 物件都儲存在裡面 和堆疊不同 記憶體堆 或 堆 Heap 最吸引人的地方在於編譯器不必知道要從堆裡分配多少儲存空間 也不必知道儲存的資料要在堆裡呆多長的時間 因此用堆儲存資料時會得到更大的靈活性 要建立一個物件時 只需用 new 命令編制相關的程式碼即可執行這些程式碼時 就會在堆裡自動進行資料的儲存 不過 為了獲得這種靈活性我們也必然需要付出一定的代價 假如在記憶體堆裡分配儲存空間 和分配規格儲存空間相比 前者要花掉更長的時間 和 C++不同 Java 事實上是不允許在堆疊裡建立物件的 這樣說 只是為了進行理論上的一種比較
堆記憶體用來存放由 new建立的物件和陣列。 由Java虛擬機器的自動垃圾回收器來管理。
在堆中產生了一個數組或物件後,還可以在棧中定義一個特殊的變數,讓棧中這個變數的取值等於陣列或物件在堆記憶體中的首地址,棧中的這個變數就成了陣列或物件的引用變數。
引用變數就相當於是為陣列或物件起的一個名稱,以後就可以在程式中使用棧中的引用變數來訪問堆中的陣列或物件
靜態儲存static storage 靜態 Static 是指 位於固定位置 儘管仍在 RAM 里程序執行期間 靜態儲存的資料將隨時等候呼叫 可用 static 關鍵字指出一個物件的特定元素是靜態的 但 Java 物件本身永遠都不會不會置入靜態儲存空間
常數儲存constant storage 常數值通常直接置於程式程式碼內部 這樣做是安全的 因為它們永遠都不會改變有的常數需要嚴格地保護 所以可考慮將它們置入只讀儲存器 ROM
非 RAM 儲存 若資料完全獨立於一個程式之外 那麼即使程式不運行了 它們仍可存在 並處在程式的控制範圍之外 其中兩個最主要的例子便是 流式物件 和 永續性物件 對於流式物件 物件會變成位元組流通常會發給另一臺機器 而對於永續性物件我們可把它們儲存在磁碟或磁帶中 即使程式中止執行 它們仍可保持自己的狀態不變之所以要設計這些型別的資料儲存 最主要的一個考慮便是把物件變成可在其他媒體上存在的形式 以後一旦需要 還可重新變回一個普通的 存在於 RAM 裡的物件 目前 Java 只提供了有限的 永續性物件 支援 在未來的 Java 版本中 有望提供對 永續性 更完善的支援。
棧與堆都是Java用來在Ram中存放資料的地方。與C++不同,Java自動管理棧和堆,程式設計師不能直接地設定棧或堆。
Java的堆或者說記憶體堆是一個執行時資料區,類的(物件從中分配空間。這些物件通過new、newarray、anewarray和multianewarray等指令建立,它們不需要程式程式碼來顯式的釋放。堆是由垃圾回收來負責的,堆的優勢是可以動態地分配記憶體大小,生存期也不必事先告訴編譯器,因為它是在執行時動態分配記憶體的,Java的垃圾收集器會自動收走這些不再使用的資料。但缺點是,由於要在執行時動態分配記憶體,存取速度較慢。
堆疊的優勢是,存取速度比堆要快,僅次於暫存器,棧資料可以共享。但缺點是,存在棧中的資料大小與生存期必須是確定的,缺乏靈活性。棧中主要存放一些基本型別的變數(,int, short, long, byte, float, double, boolean, char)和物件控制代碼。
棧有一個很重要的特殊性,就是存在棧中的資料可以共享 。 假設我們同時定義:
int a = 3;
int b = 3;
編譯器先處理int a = 3;首先它會在棧中建立一個變數為a的引用,然後查詢棧中是否有3這個值,如果沒找到,就將3存放進來,然後將a指向3。接著處理int b = 3;在建立完b的引用變數後,因為在棧中已經有3這個值,便將b直接指向3。這樣,就出現了a與b同時均指向3的情況。這時,如果再令a=4;那麼編譯器會重新搜尋棧中是否有4值,如果沒有,則將4存放進來,並令a指向4;如果已經有了,則直接將a指向這個地址。因此a值的改變不會影響到b的值。要注意這種資料的共享與兩個物件的引用同時指向一個物件的這種共享是不同的,因為這種情況a的修改並不會影響到b, 它是由編譯器完成的,它有利於節省空間。而一個物件引用變數修改了這個物件的內部狀態,會影響到另一個物件引用變數。
String是一 個特殊的包裝類資料。可以用:
String str = new String("abc");
String str = "abc";
兩種的形式來建立,第一種是用new()來新 建物件的,它會在存放於堆中。每呼叫一次就會建立一個新的物件。
-> String str = new String("abc");自己補充:應該說有會產生兩個物件,一個為new String("abc")的實體物件放到記憶體堆中, 一個為堆疊物件str 也就是類例項物件的引用物件。
而第二種(String str = "abc";)是先在棧中建立一個對String類的物件引用變數str,然後查詢棧中有沒有存放"abc",如果沒有,則將"abc"存放進棧,並令str指向”abc”,如果已經有”abc” 則直接令str指向“abc”。
比較類裡面的數值是否相等時,用equals()方法;當 測試兩個包裝類的引用是否指向同一個物件時,用==, 下面用例子說明上面的理論。
String str1 = "abc";
String str2 = "abc";
System.out.println(str1==str2); //true
可以看出str1和 str2是指向同一個物件的。
String str1 =new String ("abc");
String str2 =new String ("abc");
System.out.println(str1==str2); // false
用new的方式是生成不同的物件。每一次生成一個 。
因此用第二種方式(String str = "abc";)建立多個”abc”字串,在記憶體中其實只存在一個物件而已. 這種寫法有利與節省記憶體空間. 同時它可以在一定程度上提高程式的執行速度,因為JVM會自動根據棧中資料的實際情況來決定是否有必要建立新物件。而對於String str = new String("abc");的程式碼,則一概在堆中建立新物件,而不管其字串值是否相等,是否有必要建立新物件,從而加重了程式的負擔。
另一方面, 要注意: 我們在使用諸如String str = "abc";的格式定義類時,總是想當然地認為,建立了String類的物件str。擔心陷阱!物件可能並沒有被建立!而可能只是指向一個先前已經建立的物件。只有通過new()方法才能保證每次都建立一個新的對象。由於String類的immutable性質,當String變數需要經常變換其值時,應該考慮使用StringBuffer類,以提高程式效率。
總結完畢!
封裝和隱藏
理解封裝
封裝(Encapsulation)是面向物件三大特徵之一(封裝、繼承、多型),它指的是將物件的狀態資訊隱藏在內部,不允許外部程式直接訪問物件內部資訊,而是通過該類所提供的方法來實現對內部資訊的操作和訪問。 對一個類或物件實現良好的封裝,可以實現以下目的:µ隱藏類的實現細節。µ讓使用者只能通過事先預定的方法訪問資料,從而可以在該方法里加入控制邏輯,限制對屬性不合理訪問。µ可進行資料檢查,從而有利於保證物件資訊的完整性。µ便於修改,提高程式碼的可維護性。為了實現良好的封裝,需要從兩個方面考慮:µ將物件的屬性和實現細節隱藏起來,不允許外部直接訪問。µ把方法暴露出來,讓方法來操作或訪問這些屬性。注意:對於類而言,可以使用public和預設訪問控制符修飾,使用public修飾的類可以被所有類使用,不使用任何訪問控制符修飾的類只能被同一個包中的所有類訪問。定義Person類,實現良好的封裝。public class Person{private String name;private int age; public void setName(String name) {//要求使用者名稱必須在2~6位之間if (name.length() > 6 || name.length() < 2){System.out.println("您設定的人名不符合要求");}else{this.name = name;}}public String getName(){ return this.name;}public void setAge(int age){//要求使用者年齡必須在0~100之間if (age > 100 || age < 0){System.out.println("您設定的年齡不合法");}else{this.age = age;}}public int getAge(){ return this.age;}}注意:屬性的getter方法和setter方法有重要的意義,命名應遵循的原則:將原屬性名的首字母大寫,並在前面分別增加set和get動詞,就變成setter和getter方法名 。訪問控制符的使用總結:µ類中絕大部分屬性應該使用private修飾,除了一些static修飾的、類似全域性變數的屬性,才考慮使用public修飾。µ有些方法只是用於輔助實現該類的其他方法,這些方法被稱為工具方法,也應用private修飾。µ如果某個類主要用作其他類的父類,該類裡包含的大部分方法可能僅希望被其子類重寫,而不想被外界直接呼叫,則應該使用protected修飾這些方法。µ希望暴露出來給其他類自由呼叫的方法使用public修飾。µ頂級類通常都希望被其他類自由使用,所以大部分頂級類都使用public修飾。¯package和importµ包:Java中,包(package)是一組相關的類和介面的集合。Java編譯器將包與檔案系統的目錄一一對應起來。µµ 優點:ü避免大量類的重名衝突,擴大名字空間。ü包體現了封裝機制。µ包的建立:如果希望把一個類放在指定的包結構下,應該在Java源程式的第一個非註釋行放如下格式的程式碼:package packageName[.packageName[…]];µ例4.18 包的建立。package hbsi;public class HelloWorld{public static void main(String[] args) {System.out.println("Hello World!");}}注意:ü包名是有效地識別符號即可,但從可讀性規範角度來看,包名應該全部由小寫字母組成。ü為了避免不同公司之間類名的重複,Sun建議使用單位Internet域名倒寫來作為包名,üpackage語句必須作為原始檔的第一句非註釋性語句,一個原始檔只能指定一個包,該原始檔中可以定義多個類,則這些類將全部位於該包下。ü如果沒有顯示指定package語句,則處於無名包下。實際企業開發中,通常不會把類定義在無名包下。µ包中類的使用 如果要使用包中的類,可以有兩種方法:ü引用包中的類(使用類的全限定名稱)myPackage.mySubPackage.Book bookObj=new myPackage.mySubPackage.Book();üimport語句引入包中的類
格式:import 包名.類名;
或 import 包名.*; //“*”號表示所有類
例如: import myPackage.mySubPackage.*;
Book bookObj=new Book();注意:在引入具有層次結構的包時,“*”號僅僅表示該包中的所有類,如果該包中還有子包,那麼子包中的類時不被包括的。
µ比較兩種方法的優缺點:ü適用包名作字首的方法使程式清晰,很容易就看出所使用的類位於哪個包中;而引入包的方法要知道某個類所在的包比較困難.ü使用引入包的方法會帶來名字衝突的問題,而使用包名作字首不會存在這樣的問題.ü使用包名作字首書寫程式時比較麻煩.µ靜態匯入
JDK1.5以後更是增加了一種靜態匯入的語法,它用於匯入指定類的某個靜態屬性值或全部靜態屬性值。ü匯入指定類單個靜態屬性
import static 父包.子包…類名.靜態屬性名;
例:import static java.lang.System.out;ü匯入指定類全部靜態屬性
import static 父包.子包…類名.*;
例:import static java.lang.Math.*;隱藏的實現 在面向物件的設計中,最關鍵的問題就是”將會變與不會變的東西分離開來”。
有時為了不讓客戶程式設計師修改他們不該修改的東西,有時為了讓自己修改程式碼之後不會讓客戶程式出現問題,就必須設定一些控制訪問符,來限定各自的訪問範圍。
Java中的範圍控制符有4個,分別是private、package(預設的範圍)、protected、public,
許可權範圍由小到大。
方法及屬性的訪問控制
Private的訪問範圍是只有在本類中才可以訪問
Package的訪問範圍是在本package中的所有類都可以訪問
Protected的訪問範圍是該類的子類,及和它在同一package中的類可以訪問
Public在任何地方都可以訪問
類的訪問控制
類的訪問許可權只能是package(預設)和public的
為了控制不讓別人隨便訪問這個類,可以通過將這個類的建構函式設為private,這樣就只有你就沒有人可以建立這個物件啦。
你可以用一個static(靜態)方法建立物件。
例項:
public class Sample {
private Sample (){
System.out.println("create a Sample ");
}
public static Sample get Sample (){
return new Sample ();
}
}
或者可以先定義建立一個private的static的物件,再通過一個public的static方法返回這個物件的引用,這樣做到話可以實現 singleton(單例)模式,只會建立一個物件。
例項:
public class Sample {
private static Sample s1 = new Sample ();
public static Sample getSample(){
return s1;
}}隱藏與覆蓋的區別
關於隱藏和覆蓋的區別,要提到RTTI(run-time type identification)(執行期型別檢查),也就是執行期的多型,當一個父類引用指向子類物件的時候,請看下面我編寫的一段程式碼:
程式碼如下:
public class RunTime {
public static void main(String[] args) {
Animal a = new Cat();
System.out.println(a.A);
System.out.println(a.b);
a.voice();
a.method();
}
}
class Dog extends Animal {
public int b = 3;
public static int A = 3;
public static void method(){
System.out.println("狗");
}
public void voice() {
System.out.println("狗叫");
}
}
class Cat extends Animal {
public int b = 4;
public static int A = 4;
public static void method(){
System.out.println("貓");
}
public void voice() {
System.out.println("貓叫");
}
}
class Animal {
public int b = 0;
public static int A = 0;
public static void method(){
System.out.println("動物");
}
public void voice() {
System.out.println("動物叫");
}
}
輸出結果是:
0
0
貓叫
動物
您可以看到,當父類Animal的引用a指向子類Dog時,RTTI在執行期會自動確定該引用的真是型別,當子類 覆蓋 了父類的方法時,則直接呼叫子類的方法,打印出“貓叫”;然而非靜態的方法在子類中重寫的話就是被覆蓋,而靜態的方法被子類重寫的話就是隱藏,另外,靜態變數和成員變數也是被隱藏,而RTTI是隻針對覆蓋,不針對影藏,所以,靜態變數 A 和 非靜態變數 b 以及靜態方法method() 均不通過RTTI,是哪個類的引用就呼叫誰的靜態方法,成員變數,而這裡是父類Animal的引用,所以直接呼叫父類Animal中的方法以及成員變數。所以靜態方法 method(), 靜態變數 A 和成員變數 b 列印結果全是父類中的。只用被覆蓋的非靜態方法voice()才打印子類的。
良心的公眾號,更多精品文章,不要忘記關注哈
《Android和Java技術棧》
