
Spark之SparkStreaming案例-Window Operations
阿新 • • 發佈:2019-02-19
Window Operations
Spark Streaming還提供了視窗計算,允許您在資料的滑動視窗上應用轉換。 下圖說明了這個滑動視窗。
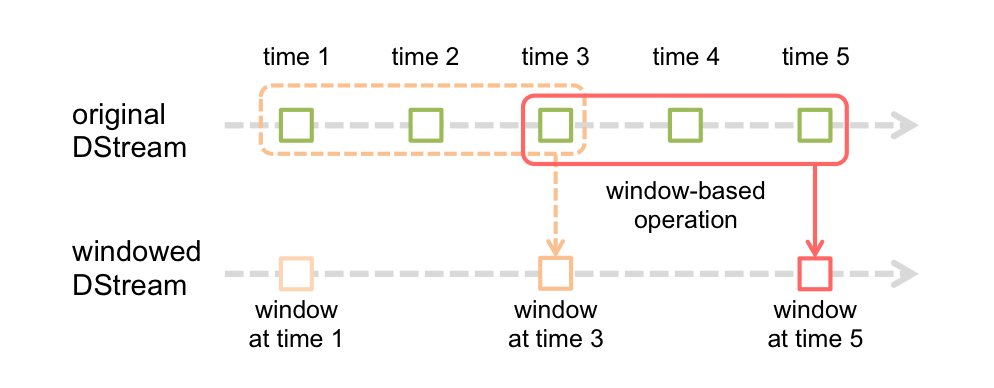
如圖所示,每當視窗滑過源DStream時,落在視窗內的源RDD被組合並進行操作以產生視窗DStream的RDD。在這種具體情況下,操作應用於最近3個時間單位的資料,並以2個時間單位滑動。這表明任何視窗操作都需要指定兩個引數。
視窗長度 - 視窗的持續時間(圖中的3)。
滑動間隔 - 執行視窗操作的間隔(圖中的2)。
這兩個引數必須是源DStream的批間隔的倍數(圖中的1)。
我們以一個例子來說明視窗操作。為了擴充套件以前的wordcount示例, 每隔10秒,統計前30秒的單詞數。為此,我們必須在最近30秒的資料中對(word,1)對的對DStream應用reduceByKey操作。這是使用reduceByKeyAndWindow操作完成的。
// Reduce function adding two integers, defined separately for clarity
Function2<Integer, Integer, Integer> reduceFunc = new Function2<Integer, Integer, Integer>() {
@Override public Integer call(Integer i1, Integer i2) {
return i1 + i2;
}
};
##reduceByKey 改為了reduceByKeyAndWindow
// Reduce 二、wordcount案例
2.1、分詞,mapToPair()沒有改變
2.2、統計單詞資料由reduceByKey變為了reduceByKeyAndWindow
內部邏輯,還是對相同word進行累加
@Override
public Integer call(Integer v1, Integer v2) throws Exception {
return v1+v2;
}
新增兩個引數
Durations.seconds(60), Durations.seconds(10)2.3、排序, 獲取
已經每隔10秒把之前60秒收集到的單詞統計計數(Durations.seconds(5), 所以共有12個RDD),執行transform操作因為一個視窗60秒資料會變成一個RDD
// 然後對這一個RDD根據每個搜尋詞出現頻率進行排序然後獲取排名前3熱點搜尋詞,這裡不用transform用transformToPair返回就是鍵值對
package com.chb.spark.streaming;
import java.util.List;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.function.Function;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import org.apache.spark.streaming.Durations;
import org.apache.spark.streaming.api.java.JavaDStream;
import org.apache.spark.streaming.api.java.JavaPairDStream;
import org.apache.spark.streaming.api.java.JavaReceiverInputDStream;
import org.apache.spark.streaming.api.java.JavaStreamingContext;
import scala.Tuple2;
public class WindowBasedTopWord {
public static void main(String[] args) {
SparkConf conf = new SparkConf().setAppName("wordcount").setMaster("local[2]");
JavaStreamingContext jssc = new JavaStreamingContext(conf,Durations.seconds(5));
// 這裡日誌簡化, yasaka hello, lily world,這裡日誌簡化主要是學習怎麼使用Spark Streaming的
JavaReceiverInputDStream<String> searchLog = jssc.socketTextStream("spark001", 9999);
// 將搜尋日誌轉換成只有一個搜尋詞即可
JavaDStream<String> searchWordDStream = searchLog.map(new Function<String,String>(){
private static final long serialVersionUID = 1L;
@Override
public String call(String searchLog) throws Exception {
return searchLog.split(" ")[1];
}
});
// 將搜尋詞對映為(searchWord, 1)的Tuple格式
JavaPairDStream<String, Integer> searchWordPairDStream = searchWordDStream.mapToPair(new PairFunction<String,String,Integer>(){
private static final long serialVersionUID = 1L;
@Override
public Tuple2<String, Integer> call(String word) throws Exception {
return new Tuple2<String,Integer>(word,1);
}
}) ;
JavaPairDStream<String, Integer> searchWordCountsDStream =
searchWordPairDStream.reduceByKeyAndWindow(new Function2<Integer,Integer,Integer>(){
private static final long serialVersionUID = 1L;
@Override
public Integer call(Integer v1, Integer v2) throws Exception {
return v1+v2;
}
}, Durations.seconds(60), Durations.seconds(10));
// 到這裡就已經每隔10秒把之前60秒收集到的單詞統計計數(Durations.seconds(5),每隔batch的時間間隔為5s, 所以共有12個RDD),執行transform操作因為一個視窗60秒資料會變成一個RDD
// 然後對這一個RDD根據每個搜尋詞出現頻率進行排序然後獲取排名前3熱點搜尋詞,這裡不用transform用transformToPair返回就是鍵值對
JavaPairDStream<String,Integer> finalDStream = searchWordCountsDStream.transformToPair(
new Function<JavaPairRDD<String,Integer>,JavaPairRDD<String, Integer>>(){
private static final long serialVersionUID = 1L;
@Override
public JavaPairRDD<String, Integer> call(
JavaPairRDD<String, Integer> searchWordCountsRDD) throws Exception {
// 反轉
JavaPairRDD<Integer,String> countSearchWordsRDD = searchWordCountsRDD
.mapToPair(new PairFunction<Tuple2<String,Integer>,Integer,String>(){
private static final long serialVersionUID = 1L;
@Override
public Tuple2<Integer, String> call(
Tuple2<String, Integer> tuple) throws Exception {
return new Tuple2<Integer,String>(tuple._2,tuple._1);
}
});
//排序
JavaPairRDD<Integer,String> sortedCountSearchWordsRDD = countSearchWordsRDD.
sortByKey(false);
//再次反轉
JavaPairRDD<String,Integer> sortedSearchWordsRDD = sortedCountSearchWordsRDD
.mapToPair(new PairFunction<Tuple2<Integer,String>,String,Integer>(){
private static final long serialVersionUID = 1L;
@Override
public Tuple2<String,Integer> call(
Tuple2<Integer,String> tuple) throws Exception {
return new Tuple2<String,Integer>(tuple._2,tuple._1);
}
});
//獲取前三個word
List<Tuple2<String,Integer>> topSearchWordCounts = sortedSearchWordsRDD.take(3);
//列印
for(Tuple2<String,Integer> wordcount : topSearchWordCounts){
System.out.println(wordcount._1 + " " + wordcount._2);
}
return searchWordCountsRDD;
}
} );
// 這個無關緊要,只是為了觸發job的執行,所以必須有action操作
finalDStream.print();
jssc.start();
jssc.awaitTermination();
jssc.close();
}
}