
KAFKA原始碼閱讀——FetchRequestPurgatory, ProducerRequestPurgatory
RequestPurgatory
purgatory,煉獄的意思。第一次看RequestPurgatory類的程式碼時,一頭霧水,不明白是幹什麼的。要理解這個,需要先理解kafka處理FetchRequest和ProduceRequest的思路:
1. 請求到達,先判斷該請求執行完成的條件是否滿足(例如ProduceRequest,需要判斷是否有足夠多的Follower都已經同步了指定的offset),如果滿足,則直接返回響應,否則請求就由Purgatory來處理了。
2. 對於進入到Purgatory中的請求,根據請求的key(TopicAndPartition)放入不同的Wather中。當相應的TopicAndPartition有可能影響hw或者leo的操作時,Watchers.collectSatisfiedRequests
3. 除此之外,每個請求都有timeout,Purgatory會定時檢查是否有請求超時,如果超時則從Purgatory中移除,並呼叫
expire函式; 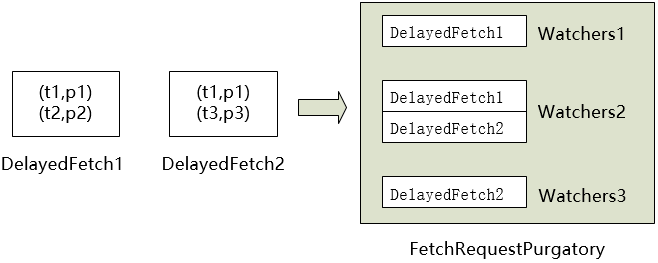
所以,RequestPurgatory可以理解為一個包含以TopicAndPartition為主鍵的Map,如果相應的TopicAndPartition有動作,則觸發檢查,同時,還有定時檢查,清理超時項。
/**
* Watcher中的檢查函式,一個TopicAndPartition對應一個Watcher,每個
* Watcher包含一個requests佇列。這個函式就是遍歷requests佇列,檢查是否
* 有request被satisfied
* @return RequestPurgatory是個抽象類,FetchRequestPurgatory和 ProducerRequestPurgatory分別採用不同的方式實現了checkSatisfied和expire函式。checkSatisfied返回boolean,用於判斷一個請求返回所需的條件是否已經滿足;expire則是在請求超時時被呼叫。
ProducerRequestPurgatory
ProducerRequestPurgatory用於處理生產請求,收到ProducerRequest時,請求就有可能放入到ProducerRequestPurgatory中。將請求放入watcher中之前,會先呼叫checkSatisfied判斷請求返回所需的條件是否已經滿足,如果滿足了則直接返回;否則加入到watcher中,並在後面不斷查詢;
ProducerRequestPurgatory.checkSatisfied(delayedProduce)直接呼叫了delayedProduce.isSatisfied函式,該函式會對ProducerRequest中的每個Partition的狀態進行檢查,呼叫partition.checkEnoughReplicasReachOffset,有如下幾個步驟:
1. 對於除去leader外的,leo > requiredOffset的replica數進行統計,設為變數numAcks;
2. 如果requiredAcks < 0,當 hw >= requiredOffset時即滿足條件;
3. 如果requiredAcks >0,當numAcks>=requiredAcks時滿足條件;
如果請求超時,ProducerRequestPurgatory.expire被呼叫,最終呼叫DelayedProduce.respond函式。該函式程式碼如下:
def respond(offsetManager: OffsetManager): RequestOrResponse = {
val responseStatus = partitionStatus.mapValues(status => status.responseStatus)
val errorCode = responseStatus.find { case (_, status) =>
status.error != ErrorMapping.NoError
}.map(_._2.error).getOrElse(ErrorMapping.NoError)
//如果該請求是offsetCommit請求,在message寫入沒有異常時,將新的offset更新到cache中
if (errorCode == ErrorMapping.NoError) {
offsetCommitRequestOpt.foreach(ocr => offsetManager.putOffsets(ocr.groupId, ocr.requestInfo) )
}
//1.如果是offsetCommitRequest,則轉換errorCode,並返回響應;
//2.如果是ProduceRequest,則根據partitionStatus返回Response;
val response = offsetCommitRequestOpt.map(_.responseFor(errorCode, offsetManager.config.maxMetadataSize))
.getOrElse(ProducerResponse(produce.correlationId, responseStatus))
response
}DelayedProduce的repond函式有點難懂,這裡不僅包含了返回ProduceRequest的操作,還包含返回OffsetCommitReuqest的邏輯。在OffsetCommitRequest請求成功執行到每個replica後,需要將offset更新到OffsetCache中。
FetchRequestPurgatory
同樣,FetchRequestPurgatory.checkSatisfied由delayedFetch.isSatisfied實現,滿足delayFetch有四種情況:
1. 當前broker不再是該partition的leader;
2. 錯誤的topicAndPartition,當前replica不存在該partition;
3. fetch的offset不在log的最新的segment上;
4. 累計的位元組數達到了最低要求————這個才是滿足Fetch的正常方式;
對於FetchRequest中的每一個 parition->fetchOffset, 累計的位元組數 accumulatedSize += endOffset.positionDiff(fetchOffset);即每一個partition的leo-fetchOffset是該partition累計的位元組數,如果所有partition累計的位元組數之和accumulatedSize>fetch.minBytes,則Fetch請求被滿足。
當FetchRequest超時DelayedFetch.respond被呼叫:
def respond(replicaManager: ReplicaManager): FetchResponse = {
//從log中讀取messageSet
val topicData = replicaManager.readMessageSets(fetch)
FetchResponse(fetch.correlationId, topicData.mapValues(_.data))
}即從log中讀取FetchRequest指定offset開始的MessageSet,幷包裝成FetchResponse返回。