
顯卡里的cuda真正做到並行運算的機制和執行緒個數,主要關於SM、warp等概念。
硬體基本架構
實際上在nVidia的GPU裡,最基本的處理單元是所謂的SP(Streaming Processor),而一顆nVidia的GPU裡,會有非常多的SP可以同時做計算;而數個SP會在附加一些其他單元,一起組成一個SM(Streaming Multiprocessor)。幾個SM則會在組成所謂的TPC(Texture Processing Clusters)。 在G80/G92的架構下,總共會有128個SP,以8個SP為一組,組成16個SM,再以兩個SM為一個TPC,共分成8個TPC來運作。而在新一代的GT200裡,SP則是增加到240個,還是以8個SP組成一個SM,但是改成以3個SM組成一個TPC,共10組TPC。下面則是提供了兩種不同表示方式的示意圖。(可參考《
NVIDIA G92終極狀態!!》、《NVIDIA D10U繪圖核心》)
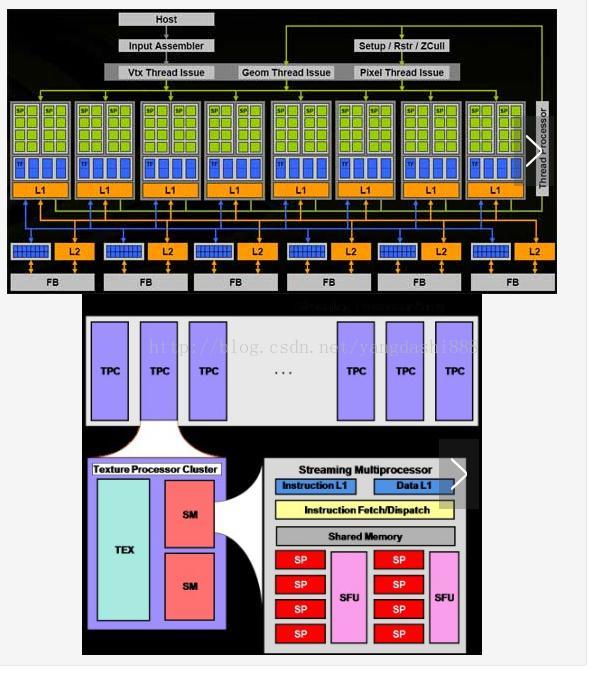
對應到CUDA
而在CUDA 中,應該是沒有TPC 的那一層架構,而是隻要根據GPU 的SM、SP 的數量和資源來調整就可以了。
如果把CUDA 的Grid – Block – Thread 架構對應到實際的硬體上的話,會類似對應成GPU – Streaming Multiprocessor ??– Streaming Processor;一整個Grid 會直接丟給GPU 來執行,而Block 大致就是對應到SM, thread 則大致對應到SP。當然,這個講法並不是很精確,只是一個簡單的比喻而已。
SM 中的Warp 和Block
CUDA的device實際在執行的時候,會以Block為單位,把一個個的block分配給SM進行運算;而block中的thread,又會以「warp」為單位,把thread來做分組計算。目前CUDA的warp大小都是32,也就是32個thread會被群組成一個warp來一起執行;同一個warp裡的thread,會以不同的資料,執行同樣的指令。此外,在Compute Capability 1.2的硬體中,還加入了warp vote的功能,可以快速的進行warp內的簡單統計。
基本上warp 分組的動作是由SM 自動進行的,會以連續的方式來做分組。比如說如果有一個block 裡有128 個thread 的話,就會被分成四組warp,第0-31 個thread 會是warp 1、32-63 是warp 2、64-95 是warp 3、96-127 是warp 4。
而如果block 裡面的thread 數量不是32 的倍數,那他會把剩下的thread 獨立成一個warp;比如說thread 數目是66 的話,就會有三個warp:0-31、32-63、64-65 。由於最後一個warp 裡只剩下兩個thread,所以其實在計算時,就相當於浪費了30 個thread 的計算能力;這點是在設定block 中thread 數量一定要注意的事!
一個SM 一次只會執行一個block 裡的一個warp,但是SM 不見得會一次就把這個warp 的所有指令都執行完;當遇到正在執行的warp 需要等待的時候(例如存取global memory 就會要等好一段時間),就切換到別的warp 來繼續做運算,藉此避免為了等待而浪費時間。所以理論上效率最好的狀況,就是在SM 中有夠多的warp 可以切換,讓在執行的時候,不會有「所有warp 都要等待」的情形發生;因為當所有的warp 都要等待時,就會變成SM 無事可做的狀況了~
下圖就是一個warp 排程的例子。一開始是先執行thread block 1 的warp1,而當他執行到第六行指令的時候,因為需要等待,所以就會先切到thread block 的warp2 來執行;一直等到存取結束,且剛好有一個warp 結束時,才繼續執行TB1 warp1 的第七行指令。
實際上,warp 也是CUDA 中,每一個SM 執行的最小單位;如果GPU 有16 組SM 的話,也就代表他真正在執行的thread 數目會是32*16 個。不過由於CUDA 是要透過warp 的切換來隱藏thread 的延遲、等待,來達到大量平行化的目的,所以會用所謂的active thread 這個名詞來代表一個SM 裡同時可以處理的thread 數目。
而在block 的方面,一個SM 可以同時處理多個thread block,當其中有block 的所有thread 都處理完後,他就會再去找其他還沒處理的block 來處理。假設有16 個SM、64 個block、每個SM 可以同時處理三個block 的話,那一開始執行時,device 就會同時處理48 個block;而剩下的16 個block 則會等SM 有處理完block 後,再進到SM 中處理,直到所有block 都處理結束。

建議的數值?
在Compute Capability 1.0/1.1中,每個SM最多可以同時管理768個thread(768 active threads)或8個block(8 active blocks);而每一個warp的大小,則是32個thread,也就是一個SM最多可以有768 / 32 = 24個warp(24 active warps)。到了Compute Capability 1.2的話,則是active warp則是變為32,所以active thread也增加到1024。
在這裡,先以Compute Capability 1.0/1.1 的數字來做計算。根據上面的資料,如果一個block 裡有128 個thread 的話,那一個SM 可以容納6 個block;如果一個block 有256 個thread 的話,那SM 就只能容納3 個block。不過如果一個block 只有64 個thread 的話,SM 可以容納的block 不會是12 個,而是他本身的數量限制的8 個。
因此在Compute Capability 1.0/1.1的硬體上,決定block大小的時候,最好讓裡面的thread數目是warp數量(32)的倍數(可以的話,是64的倍數會更好);而在一個SM裡,最好也要同時存在複數個block。如果再希望能滿足最多24個warp的情形下,block裡的thread數目似乎會是96(一個SM中有8個block)、128(一個SM中有6個block)、192(一個SM中有4個block)、256(一個SM中有3個block)這些數字了~
而官方的建議則是一個block裡至少要有64個thread,192或256個也是通常比較合適的數字(請參考Programming Guide) 。但是是否這些數字就是最合適的呢?其實也不盡然。因為實際上,一個SM 可以允許的block 數量,還要另外考慮到他所用到SM 的資源:shared memory、registers 等。在G80 中,每個SM 有16KB 的shared memory 和8192 個register。而在同一個SM 裡的block 和thread,則要共用這些資源;如果資源不夠多個block 使用的話,那CUDA 就會減少Block 的量,來讓資源夠用。在這種情形下,也會因此讓SM 的thread 數量變少,而不到最多的768 個。
比如說如果一個thread 要用到16 個register 的話(在kernel 中宣告的變數),那一個SM 的8192 個register 實際上只能讓512 個thread 來使用;而如果一個thread 要用32 個register,那一個SM 就只能有256 個thread 了~而shared memory 由於是thread block 共用的,因此變成是要看一個block 要用多少的shread memory、一個SM 的16KB 能分給多少個block 了。
所以雖然說當一個SM裡的thread越多時,越能隱藏latency,但是也會讓每個thread能使用的資源更少。因此,這點也就是在最佳化時要做取捨的了。