
關係型資料庫工作原理-事務管理(二)(22)
本文翻譯自Coding-Geek文章:《 How does a relational database work》。
緊接上一篇文章,本文翻譯瞭如下章節:
<
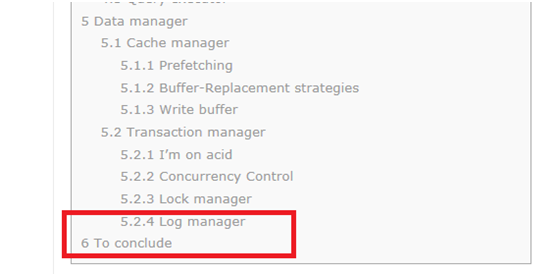
一、 Log manager(日誌管理)
通過前面的章節,我們已經知道,為了提升效能,資料庫會將資料快取在記憶體中。但是,如果在事務提交過程中,資料庫伺服器崩潰了。快取在記憶體的資料就會丟失,這破壞了資料庫的Durability特性。
也可以把所有資料都直接寫到儲存磁碟,萬一在寫的過程中伺服器崩潰了,就只有一部分資料寫到了磁碟。這也破壞了事務的Atomicity特性。
事務的完整性要求要麼所有操作都執行,要麼什麼也不做。
有兩種方式達到這樣的目的:
Shadow copies/pages(影像拷貝/影像頁面): 每個事務拷貝一份自己的資料庫(或者是資料庫的一部分),在這份拷貝上操作。出錯了,就刪除這份拷貝。成功後,使用檔案系統的功能 做一下檔案交換,替換掉舊的資料。
Transaction log (事務日誌):Transaction log是這樣一塊儲存區域–在事務將資料寫到磁碟之前先將資訊寫到Transaction log檔案。這樣,如果服務發生崩潰、事務被取消;資料庫清楚如果根據日誌刪除資料,或者繼續完成未完成的操作。
二、 WAL(Write Ahead logging 預寫日誌系統)
在大型資料庫上存在眾多事務,Shadow copies/pages 需要消耗大量的磁碟空間。這也是現代資料庫都使用 Transaction Log的原因。Transaction Log必須儲存在可靠的位置。我不打算深入介紹儲存技術,我假設使用的RAID盤是可靠的。
大多資料庫(Oracle、SQL Server、DB2、PostgreSQL、MySQL和SQLite)處理Transaction Log是用的WAL協議。本協議包含三條規則:
- 每一次資料庫的修改操作都產生一條日誌記錄。並且日誌資訊一定要在資料寫到磁碟之前先寫到事務日誌檔案中。
- 事務日誌必須按順序儲存。操作A先於操作B執行,那麼操作A的日誌必須先寫。
- 事務提交時,提交命令必須在事務結束之前寫到Transaction Log檔案中。
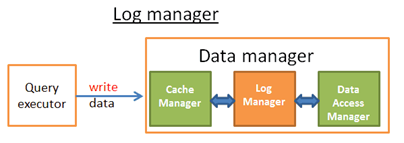
上面這些規則由Log Manager保證。一種簡單的理解:在Cache manager與Data Acccess Manager增加一層Log Manager,Log Manager將每一次操作(包含update/delete/create/commit/rollback)都先寫到Transaction Log,再將資料寫到磁碟。足夠簡單不?
錯!,我們已經看過的所有,與資料庫相關的東西都受到了“詛咒”– 資料庫效能(Database effect)。 更麻煩的問題是 如何找到一種寫Transaction Log的高效方式。如果寫Transaction log很慢,它將拖所有資料庫操作的後腿。
三、 ARIES (IBM資料恢復的原型演算法)
在1992年,IBM研究中心“發明”了增強版的WAL叫ARIES。現代資料庫都或多或少 用到了ARIES演算法。實現邏輯或許不同,但背後的原理都是ARIES。我之所以在“說明”上面加引號,是因為根據MIT思維、IBMS研究中心並沒有開發出一種更好的資料恢復軟體。停留在理論。
“我5歲的時候,ARIES演算法就已經發布”,我不在意這種少數苦逼研發人員的八卦。實際上我把這個作為一箇中場休息,在開始最後一段技術章節之前的中場休息。我已閱讀了大量關於ARIES的文件,我發現它很有趣。在這,我只給你們講一下ARIES的大概含義。如果你想了解ARIES的詳細的資訊,我建議讀一下相關的論文。
AREIS的意思是“Algorithms for Recovery and Isolation Exploiting Semantics”。
ARIES的目的旨在兩個方面:
- 提升寫Transaction Log的效能。
- 擁有快速、可靠的恢復能力。
有多種原因會導致資料庫事務回滾:
- 使用者取消了。
- 伺服器崩潰或者網路中斷。
- 事務操作違反了資料庫的約束條件(例如:某個欄位要求資料唯一,而事務插入了重複的資料)。
- 出現了死鎖。
有時(比如網路出現故障),資料庫可以恢復事務。它是如何做到的呢? 要回答這個問題,我們需要理解日誌中記錄了哪些資訊。
四、 The Logs
事務中的任何操作都會產生日誌,包括新增、刪除、修改。一條日誌由如下資訊構成:
1. LSN:Log Sequence Number, 日誌記錄的唯一編號。LSN按時間順序生成。這意味著,如果操作A在操作B之前執行,那麼A的LSN編碼將小於B。
2. TransID:事務ID。記錄當前操作所屬的事務。
3. PageID:分頁ID,記錄修改資料在磁碟上儲存的位置。分頁是資料在磁碟上儲存的最小單位,所以資料在磁碟上的儲存位置即指包含該資料的分頁在磁碟上的位置。
4. PreLSN:同一個事務中的上一條日誌。
5. UNDO:回滾操作。
例如,對於資料修改操作。UNDO將儲存修改操作的值或者狀態,在正式修改磁碟上的資料之前。回滾時執行反向操作回到前一個狀態。
6. REDO:重操作。
有兩種方式實現可實現REDO,儲存操作的值和狀態,或者操作自身。REDO時重執行操作。
7. …僅供參考:ARIES日誌還要另外兩個欄位:UndoNxtLSN 和 Type。
此外,儲存資料的磁碟分頁上還儲存了最後一次修改該分頁資料的LSN。
備註:根據我的瞭解,只有PostgreSQL不使用UNDO。它有一個垃圾回收執行緒,用於清除舊版本資料。這是PostgreSQL的data version的一種應用場景。
這裡給一個簡單示例,“UPDATE FROM PERSON SET AGE = 18;”修改生成的日誌記錄。
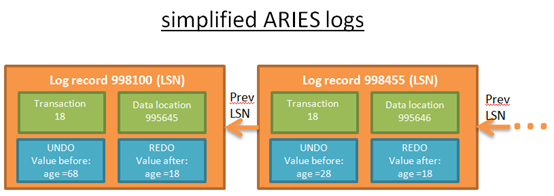
每一條日誌都有唯一的LSN。同一個事務中所有日誌構成連結串列結構,連結串列中日誌按時間先後順序排列。
五、 Log Buffer
為避免寫日誌成為效能瓶頸,Log Buffer派上用場。
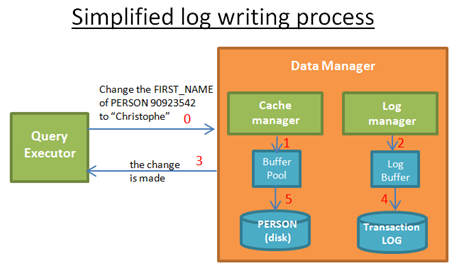
當query excutor執行一次資料庫修改操作時:
- Cache manager儲存修改後的資料到快取區。
- Log manager儲存相關的日誌資訊到快取區。
- 到這一步,Query Excutor任務修改操作已經完成。可以接收下一次操作請求。
- 然後,Log manager將日誌資訊寫到transaction log。決定什麼時候寫日誌有一個演算法。
- 然後, Cache manager將資料寫到磁碟。決定什麼時候寫資料到磁碟也有一個演算法。
當一個事務提交成功了,就意味為事務中的所有操作都已經完成了上面1~5步操作。寫事務日誌是非常快的,因為只需要把事務日誌資訊加到日誌檔案的末尾。反之,寫資料到磁碟上要複雜得多,寫資料的時候要考慮怎麼快速讀取(譯者注:作者的意思應該是說,為了提升讀取效能,資料庫都會有索引。寫資料將涉及到儲存索引B+樹的調整。時間很長,演算法很複雜。)
六、 STEAL and FORCE policies (竊取和強制策略)
為了提升效能,上面的第5步(將資料寫到磁碟)可能會被放在事務提交後再執行,因為即使萬一出現了什麼問題,也能通過事務日誌的REDO來恢復。這種方式被稱為NO-FORCE Policy。
資料庫也可以選擇 Force Policy(第5步必須在事務提交前完成),以降低資料庫恢復的負擔。
另一個問題是選擇採用一步一步往磁碟上寫資料的方式(STEAL Policy)還是等事務提交時,一次性將快取的資料寫到磁碟的方式(NO-STEAL Policy)。選擇哪種方式,取決於應用場景:快速的寫,但需要採用UNDO日誌緩慢的恢復,或者快速恢復。
不同的策略對資料恢復有哪些影響:
- STEAL/NO-FORCE需要UNDO和REDO:效能最好,也帶來更復雜的日誌設計和恢復處理(如ARIES)。大多數資料庫都採用這種方式。
- STEAL/ FORCE:僅需要 UNDO能力。
- NO-STEAL/NO-FORCE:僅需要REDO能力。
- NO-STEAL/FORCE:什麼也不需要,效能最差。需要大量記憶體。
七、 The recovery part
OK,我們已經構建出了完美的資料庫日誌,下來看應該如何使用它。
假如,一個實習生把資料庫搞掛了。你重啟了資料庫,然後資料庫恢復工作就開始了。
ARIES使資料庫從崩潰中恢復有三個步驟:
1. The Analysis pass (分析階段):恢復程式讀取所有的事務日誌,重建災難發生時現場環境。以決定哪些事務需要回滾,哪些資料需要寫到磁碟。
2. The Redo pass (重做階段):這個階段根據分析的日誌,執行REDO操作更新資料庫,使資料庫回到災難前的狀態。
在REDO階段,REDO日誌按時間順序先後執行(根據LSN)。針對每一條日誌,恢復程式將從磁碟包含資料的分頁中讀取LSN。
IF(磁碟分頁上的LSN) >= IF(事務日誌中LSN):這意味著資料在發生災難前已經寫到了磁碟上(並且,資料被後面(發生災難前)執行的操作覆蓋)。針對這條操作日誌什麼也不用做。
F(磁碟分頁上的LSN) < IF(事務日誌中LSN):說明磁碟上的資料被修改。將執行REDO操作,寫資料庫。哪怕後面事務又回滾了(這樣是為了使恢復程式簡單化,現代資料庫是不會這麼處理的)。
3. The Undo pass:這個階段將回滾在災難發生時未完成的事務。回滾操作從事務的最後一條日誌開始,按時間從後往前的方式執行Undo操作(通過日誌的PreLSN往前遍歷)。
在資料恢復過程中,事務日誌作為恢復程式執行任務的依據,以保證資料寫到磁碟順序與事務日誌記錄順序同步。應該有一種方案可以移除事務中未完成操作相關的日誌,但這很困難。相反,ARIES採用新增修正日誌的方式,以達到理論上刪除事務中未完成操作的目的。
當某個事務被取消了,取消的原因可能是使用者取消,Lock manager取消(防止死鎖)或者因為網路中斷的原因。出現這些情況不需要考慮通過日誌恢復。實際上,關於如何REDO和UNDO的資訊已經儲存在兩張記憶體表中:
事務表-transaction table(儲存當前正在執行的所有事務狀態)。
髒頁表-dirty page table(儲存哪一塊資料需要寫到磁碟)。
每來一個新的事務,這兩張表將被cache manager和transaction manager更新。由於這兩張表是儲存在記憶體中的,資料庫崩潰時資料就丟失了。
使用 transaction log做資料庫故障恢復, 在分析階段要做的事情就是重建這兩張表。為了加快分析階段處理,ARIES創造了檢查點(CheckPoint)的概念。其思路是,不時將transaction table和dirty page table寫到磁碟,並且將當時的最後一條LSN寫到磁碟;這樣,在分析階段就只有該LSN後面的日誌需要分析。
八、 To Conclude 最後一句話
在寫下這邊文章之前,我已經知道這個主題很大,寫深入 要花很多時間。實際證明,我還是過於樂觀了,我花了預期兩倍的時間。在這個過程中也學到很多東西。
如果你想更深入的瞭解資料庫,我建議你研讀一下論文“Architecture of a Database System”。這是一篇介紹資料庫很好的文章,非計算機專業人士也能看得懂。這篇論文幫助我規劃本文要寫的內容,這是一篇關於架構理念的文章,不像本文,本文主要描述資料結構和演算法。
如果你仔細閱讀了本文,你就瞭解了資料庫是多麼強大。由於文章很長,再梳理一下重點內容。
- B+樹索引概述
- 資料庫整體概述
- 資料表連線操作效能優化概述
- 快取池管理
- 事務管理
實際資料庫能力更加強大,例如:我還未介紹資料庫是如何解決這些更麻煩的問題的:
- 資料庫叢集和全域性事務
- 資料在執行過程中如何建立快照
- 高效資料壓縮
- 記憶體管理
因此,當你需要在充滿BUG的NO SQL和堅如磐石的關係型資料庫之前選擇時,慎重思考。不要誤解我的意思,一些NO SQL資料庫也很偉大。但是,他們還太嫩,而且只關注解決很少的一部分特定問題。
總之,當有人問你關係型資料庫是如何工作的時,你不必撒腿跑路,現在你能回答這個問題了。

或者,你也可以直接把這篇文件丟給他。