
ES(elasticsearch)搜尋引擎安裝和使用
大資料時代,搜尋無處不在。搜尋技術是全棧工程師必備技術之一,如今是開源時代,數不盡的資源供我們利用,如果要自己寫一套搜尋引擎無疑是浪費繩命。本節主要介紹搜尋引擎開源專案elasticSearch的安裝和使用
為什麼需要搜尋引擎
首先想一下:在一篇文章裡找一個關鍵詞怎麼找?字串匹配是最佳答案。
然後再想一下:找到100篇文章裡包含某個關鍵詞的文章列表怎麼找?依然是關鍵詞匹配
再繼續想:找到100000000000(一千億)篇文章裡包含某個關鍵詞的文章怎麼找?如果用關鍵詞匹配,以現在的電腦處理速度,從遠古時代到人類滅絕這麼長時間都處理不完,這時候搜尋引擎要發揮作用了
搜尋引擎技術有多麼高深?
搜尋引擎這種技術實際上從古代就有了。想象一個國家儲存各類編撰資料的部門,有幾個屋子的書,如果想找到某一本書的時候會怎麼找呢?對了,有分類目錄,先確定要找的書籍是哪個類別的,然後從目錄裡面找到想要找的書籍位於屋子的什麼位置,然後再去拿。搜尋引擎其實就是做了生成目錄(也就是索引)的事情。那麼如今的搜尋引擎是怎麼生成索引的呢?
要把網際網路上的資料生成索引,攏共分三步:第一步,把資料編號;第二步,把每篇資料內容切成詞;第三步,把詞和資料編號的對應關係處理成“詞=》編號列表”的形式
這時候你就可以迅速的找到一千億篇文章裡包含某個關鍵詞的文章了,告訴我關鍵詞是什麼,我直接就從索引裡找到了這個詞對應的文章編號列表了,搞定!把需要數萬年才能做完的工作用了不到一秒鐘就搞定了,這就是搜尋引擎的魅力!
當然,上面說的搜尋引擎技術很簡單,但百度數萬工程師也不都是白吃飯的,如果想做好一個搜尋引擎產品需要解決的問題就有很多了:收集網頁時要考慮全、快、穩、新、優的問題,建索引時要考慮質量、效率、賦權、週期、時效性、資源消耗等問題,搜尋的時候要考慮query分析、排序、篩選、展示、效能、廣告、推薦、個性化、統計等問題,整體上要考慮地域性、容災、國際化、當地法律、反作弊、垂直需求、移動網際網路等諸多問題,所以百度大廈徹夜通明也是可以理解的。
開源搜尋引擎
既然搜尋引擎技術這麼複雜,那麼我們何必自尋煩惱了,開源社群為我們提供了很多資源,世界很美好。
說到開源搜尋引擎一定要用的開源專案就是lucene,它不是搜尋引擎產品,而是一個類庫,而且是至今開源搜尋引擎的最好的類庫沒有之一,因為只有它一個。lucene是用Java語言開發,基本上涵蓋了搜尋引擎中索引和檢索兩個核心部分的全部功能,而且抽象的非常好,我後面會單獨寫數篇文章專門講lucene的使用。最後強調一遍,它是一個類庫,不是搜尋引擎,你可以比較容易的基於lucene寫一個搜尋引擎。
然後要說的一個開源專案是solr,這是一個完整的搜尋引擎產品,當然它底層一定是基於lucene的,毫無疑問,因為lucene是最好且唯一的搜尋引擎類庫。solr使用方法請看我的另一篇文章《
最後要說的就是elasticSearch,這個開源專案也可以說是一個產品級別的開源專案,當然它底層一定是基於lucene的,毫無疑問,因為lucene是最好且唯一的搜尋引擎類庫,我承認我是唐僧。它是一種提供了RESTful api的服務,RESTful就是直接通過HTTP協議收發請求和響應,介面比較清晰簡單,是一種架構規則。話不多說,下面我就說下安裝方法和簡單使用方法,這樣更容易理解,之後我會單獨講解怎麼讓你的網站利用elasticSearch實現搜尋功能
Elasticsearch(簡稱ES)是一個基於Apache Lucene(TM)的開源搜尋引擎,無論在開源還是專有領域,Lucene可以被認為是迄今為止最先進、效能最好的、功能最全的搜尋引擎庫。
Elasticsearch簡介
Elasticsearch是什麼
Elasticsearch是一個基於Apache Lucene(TM)的開源搜尋引擎,無論在開源還是專有領域,Lucene可以被認為是迄今為止最先進、效能最好的、功能最全的搜尋引擎庫。
但是,Lucene只是一個庫。想要發揮其強大的作用,你需使用Java並要將其整合到你的應用中。Lucene非常複雜,你需要深入的瞭解檢索相關知識來理解它是如何工作的。
Elasticsearch也是使用Java編寫並使用Lucene來建立索引並實現搜尋功能,但是它的目的是通過簡單連貫的RESTful API讓全文搜尋變得簡單並隱藏Lucene的複雜性。
不過,Elasticsearch不僅僅是Lucene和全文搜尋引擎,它還提供:
- 分散式的實時檔案儲存,每個欄位都被索引並可被搜尋
- 實時分析的分散式搜尋引擎
- 可以擴充套件到上百臺伺服器,處理PB級結構化或非結構化資料
而且,所有的這些功能被整合到一臺伺服器,你的應用可以通過簡單的RESTful API、各種語言的客戶端甚至命令列與之互動。上手Elasticsearch非常簡單,它提供了許多合理的預設值,並對初學者隱藏了複雜的搜尋引擎理論。它開箱即用(安裝即可使用),只需很少的學習既可在生產環境中使用。Elasticsearch在Apache 2 license下許可使用,可以免費下載、使用和修改。
隨著知識的積累,你可以根據不同的問題領域定製Elasticsearch的高階特性,這一切都是可配置的,並且配置非常靈活。
Elasticsearch中涉及到的重要概念
Elasticsearch有幾個核心概念。從一開始理解這些概念會對整個學習過程有莫大的幫助。
(1) 接近實時(NRT)
Elasticsearch是一個接近實時的搜尋平臺。這意味著,從索引一個文件直到這個文件能夠被搜尋到有一個輕微的延遲(通常是1秒)。
(2) 叢集(cluster)
一個叢集就是由一個或多個節點組織在一起,它們共同持有你整個的資料,並一起提供索引和搜尋功能。一個叢集由一個唯一的名字標識,這個名字預設就是“elasticsearch”。這個名字是重要的,因為一個節點只能通過指定某個叢集的名字,來加入這個叢集。在產品環境中顯式地設定這個名字是一個好習慣,但是使用預設值來進行測試/開發也是不錯的。
(3) 節點(node)
一個節點是你叢集中的一個伺服器,作為叢集的一部分,它儲存你的資料,參與叢集的索引和搜尋功能。和叢集類似,一個節點也是由一個名字來標識的,預設情況下,這個名字是一個隨機的漫威漫畫角色的名字,這個名字會在啟動的時候賦予節點。這個名字對於管理工作來說挺重要的,因為在這個管理過程中,你會去確定網路中的哪些伺服器對應於Elasticsearch叢集中的哪些節點。
一個節點可以通過配置叢集名稱的方式來加入一個指定的叢集。預設情況下,每個節點都會被安排加入到一個叫做“elasticsearch”的叢集中,這意味著,如果你在你的網路中啟動了若干個節點,並假定它們能夠相互發現彼此,它們將會自動地形成並加入到一個叫做“elasticsearch”的叢集中。
在一個叢集裡,只要你想,可以擁有任意多個節點。而且,如果當前你的網路中沒有執行任何Elasticsearch節點,這時啟動一個節點,會預設建立並加入一個叫做“elasticsearch”的叢集。
(4) 索引(index)
一個索引就是一個擁有幾分相似特徵的文件的集合。比如說,你可以有一個客戶資料的索引,另一個產品目錄的索引,還有一個訂單資料的索引。一個索引由一個名字來標識(必須全部是小寫字母的),並且當我們要對對應於這個索引中的文件進行索引、搜尋、更新和刪除的時候,都要使用到這個名字。索引類似於關係型資料庫中Database的概念。在一個叢集中,如果你想,可以定義任意多的索引。
(5) 型別(type)
在一個索引中,你可以定義一種或多種型別。一個型別是你的索引的一個邏輯上的分類/分割槽,其語義完全由你來定。通常,會為具有一組共同欄位的文件定義一個型別。比如說,我們假設你運營一個部落格平臺並且將你所有的資料儲存到一個索引中。在這個索引中,你可以為使用者資料定義一個型別,為部落格資料定義另一個型別,當然,也可以為評論資料定義另一個型別。型別類似於關係型資料庫中Table的概念。
(6)文件(document)
一個文件是一個可被索引的基礎資訊單元。比如,你可以擁有某一個客戶的文件,某一個產品的一個文件,當然,也可以擁有某個訂單的一個文件。文件以JSON(JavaScript Object
Notation)格式來表示,而JSON是一個到處存在的網際網路資料互動格式。
在一個index/type裡面,只要你想,你可以儲存任意多的文件。注意,儘管一個文件,物理上存在於一個索引之中,文件必須被索引/賦予一個索引的type。文件類似於關係型資料庫中Record的概念。實際上一個文件除了使用者定義的資料外,還包括_index、_type和_id欄位。
(7) 分片和複製(shards & replicas)
一個索引可以儲存超出單個結點硬體限制的大量資料。比如,一個具有10億文件的索引佔據1TB的磁碟空間,而任一節點都沒有這樣大的磁碟空間;或者單個節點處理搜尋請求,響應太慢。
為了解決這個問題,Elasticsearch提供了將索引劃分成多份的能力,這些份就叫做分片。當你建立一個索引的時候,你可以指定你想要的分片的數量。每個分片本身也是一個功能完善並且獨立的“索引”,這個“索引”可以被放置到叢集中的任何節點上。
分片之所以重要,主要有兩方面的原因:
- 允許你水平分割/擴充套件你的內容容量
- 允許你在分片(潛在地,位於多個節點上)之上進行分散式的、並行的操作,進而提高效能/吞吐量
至於一個分片怎樣分佈,它的文件怎樣聚合回搜尋請求,是完全由Elasticsearch管理的,對於作為使用者的你來說,這些都是透明的。
在一個網路/雲的環境裡,失敗隨時都可能發生,在某個分片/節點不知怎麼的就處於離線狀態,或者由於任何原因消失了。這種情況下,有一個故障轉移機制是非常有用並且是強烈推薦的。為此目的,Elasticsearch允許你建立分片的一份或多份拷貝,這些拷貝叫做複製分片,或者直接叫複製。複製之所以重要,主要有兩方面的原因:
- 在分片/節點失敗的情況下,提供了高可用性。因為這個原因,注意到複製分片從不與原/主要(original/primary)分片置於同一節點上是非常重要的。
- 擴充套件你的搜尋量/吞吐量,因為搜尋可以在所有的複製上並行執行
總之,每個索引可以被分成多個分片。一個索引也可以被複制0次(意思是沒有複製)或多次。一旦複製了,每個索引就有了主分片(作為複製源的原來的分片)和複製分片(主分片的拷貝)之別。分片和複製的數量可以在索引建立的時候指定。在索引建立之後,你可以在任何時候動態地改變複製數量,但是不能改變分片的數量。
預設情況下,Elasticsearch中的每個索引被分片5個主分片和1個複製,這意味著,如果你的叢集中至少有兩個節點,你的索引將會有5個主分片和另外5個複製分片(1個完全拷貝),這樣的話每個索引總共就有10個分片。一個索引的多個分片可以存放在叢集中的一臺主機上,也可以存放在多臺主機上,這取決於你的叢集機器數量。主分片和複製分片的具體位置是由ES內在的策略所決定的。
elasticSearch安裝
從github下載1.7版tag並編譯(選擇1.7版是因為當前我們的網站的symfony2版本還不支援2.x版本,但請放心的用,1.7版是經過無數人驗證過的最穩定版本)
wget https://codeload.github.com/elastic/elasticsearch/tar.gz/v1.7.5解壓後進入目錄執行
mvn package -DskipTests這會花費你很長一段時間,你可以去喝喝茶了
編譯完成後會在target/releases中生成編譯好的壓縮包(類似於elasticsearch-1.7.5.zip這樣的檔案),把這個壓縮包解壓放到任意目錄就安裝好了
安裝ik外掛
ik是一箇中文切詞外掛,elasticSearch自帶的中文切詞很不專業,ik對中文切詞支援的比較好。
在https://github.com/medcl/elasticsearch-analysis-ik上找到我們elasticSearch對應的版本,1.7.5對應的ik版本是1.4.1,所以下載https://github.com/medcl/elasticsearch-analysis-ik/releases/tag/v1.4.1
解壓出的目錄是:
elasticsearch-analysis-ik-1.4.1
進入目錄後執行
mvn clean package編譯完後依然是在target/releases生成了類似於elasticsearch-analysis-ik-*.zip的壓縮包,把裡面的內容解壓到elasticsearch安裝目錄的plugins/ik下
再把elasticsearch-analysis-ik-1.4.1/config/ik目錄整體拷貝到elasticsearch安裝目錄的config下
修改elasticsearch安裝目錄下的config/elasticsearch.yml,新增:
index:
analysis:
analyzer:
ik:
alias: [ik_analyzer]
type: org.elasticsearch.index.analysis.IkAnalyzerProvider
ik_max_word:
type: ik
use_smart: false
ik_smart:
type: ik
use_smart: true這樣ik就安裝好了
啟動並試用
直接進入elasticsearch安裝目錄,執行
./bin/elasticsearch -d後臺啟動完成
elasticSearch是通過HTTP協議收發資料的,所以我們用curl命令來給它發命令,elasticSearch預設監聽9200埠
寫入一篇文章:
curl -XPUT 'http://localhost:9200/myappname/myblog/1?pretty' -d '
{
"title": "我的標題",
"content": "我的內容"
}'會收到返回資訊:
{
"_index" : "myappname",
"_type" : "myblog",
"_id" : "1",
"_version" : 1,
"created" : true
}這說明我們成功把一篇文章發給了elasticSearch,它底層會利用lucene自動幫我們建好搜尋用的索引
再寫一篇文章:
curl -XPUT 'http://localhost:9200/myappname/myblog/2?pretty' -d '
{
"title": "這是第二篇標題",
"content": "這是第二篇內容"
}'會收到返回資訊:
{
"_index" : "myappname",
"_type" : "myblog",
"_id" : "2",
"_version" : 1,
"created" : true
}這時我們找到elasticsearch安裝目錄的data目錄下會生成這樣的目錄和檔案:
ls data/nodes/0/indices/myappname/
0 1 2 3 4 _state不同環境會稍有不同,但是都會生成myappname目錄就對了
檢視所有文章:
curl -XGET 'http://localhost:9200/myappname/myblog/_search?pretty=true' -d '
{
"query" : {
"match_all" : {}
}
}'這時會把我們剛才新增的兩篇文章都列出來
搜尋關鍵詞“我的”:
curl -XGET 'http://localhost:9200/myappname/myblog/_search?pretty=true' -d '
{
"query":{
"query_string":{"query":"我的"}
}
}'會返回:
{
"took" : 2,
"timed_out" : false,
"_shards" : {
"total" : 5,
"successful" : 5,
"failed" : 0
},
"hits" : {
"total" : 1,
"max_score" : 0.191783,
"hits" : [ {
"_index" : "myappname",
"_type" : "myblog",
"_id" : "1",
"_score" : 0.191783,
"_source":
{
"title": "我的標題",
"content": "我的內容"
}
} ]
}
}搜尋關鍵詞“第二篇”:
curl -XGET 'http://localhost:9200/myappname/myblog/_search?pretty=true' -d '
{
"query":{
"query_string":{"query":"第二篇"}
}
}'會返回:
{
"took" : 2,
"timed_out" : false,
"_shards" : {
"total" : 5,
"successful" : 5,
"failed" : 0
},
"hits" : {
"total" : 1,
"max_score" : 0.1879082,
"hits" : [ {
"_index" : "myappname",
"_type" : "myblog",
"_id" : "2",
"_score" : 0.1879082,
"_source":
{
"title": "這是第二篇標題",
"content": "這是第二篇內容"
}
} ]
}
}如果想檢查ik的切詞效果,可以執行:
curl 'http://localhost:9200/myappname/_analyze?analyzer=ik_max_word&pretty=true' -d'
{
"text":"中華人民共和國國歌"
}'通過返回結果可以看出,ik_max_word切詞把中華人民共和國國歌切成了“中華人民共和國”、“中華人民”、“中華”、“華人”、“人民共和國”、“人民”、“共和國”、“共和”、“國”、“國歌”
也就是說我們搜尋這些詞中的任意一個都能把這句話搜到,如果不安裝ik外掛的話,那隻會切成:“中”、“華”、“人”、“民”、“共”、“和”、“國”、“國”、“歌”,不夠智慧,搜尋也不好進行了
講解一下
上面幾條命令都是json形式,elasticSearch就是這麼人性化,沒治了。
這裡面的myappname是你自己可以改成自己應用的名字,這在elasticSearch資料儲存中是完全隔離的,而myblog是我們在同一個app中想要維護的不同的資料,就是你的不同資料,比如文章、使用者、評論,他們最好都分開,這樣搜尋的時候也不會混
pretty引數就是讓返回的json有換行和縮排,容易閱讀,除錯時可以加上,開發到程式裡就可以去掉了
analyzer就是切詞器,我們指定的ik_max_word在前面配置檔案裡遇到過,表示最大程度切詞,各種切,360度切
返回結果裡的hits就是“命中”,total是命中了幾條,took是花了幾毫秒,_score就是相關性程度,可以用來做排序的依據
elasticSearch有什麼用
上面都是json的介面,那麼我們怎麼用呢?其實你想怎麼用就怎麼用,煎著吃、炒著吃、燉著吃都行。比如我們的部落格網站,當你建立一篇部落格的時候可以傳送“新增”的json命令,然後你開發一個搜尋頁面,當你輸入關鍵詞點搜尋的時候,可以傳送查詢的命令,這樣返回的結果就是你的搜尋結果,只不過需要你自己潤色一下,讓展現更美觀。感覺複雜嗎?下一節告訴你怎麼用symfony2的擴充套件來實現部落格網站的搜尋功能
————————————————————————————————————————————————————
簡介
開始學es,我習慣邊學邊記,總結出現的問題和解決方法。本文是在兩臺Linux虛擬機器下,安裝了三個節點。本次搭建es同時實踐了兩種模式——單機模式和分散式模式。條件允許的話,可以在多臺機器上配置es節點,如果你機器效能有限,那麼可以在一臺虛擬機器上完成多節點的配置。
如圖,是本次3個節點的分佈。
| 虛擬機器主機名 | IP | es節點 |
|---|---|---|
| master | 192.168.137.100 | node1、node3 |
| slave | 192.168.137.101 | node2 |
一、下載及配置
1.幾個基本名詞
index: es裡的index相當於一個資料庫。
type: 相當於資料庫裡的一個表。
id: 唯一,相當於主鍵。
node:節點是es例項,一臺機器可以執行多個例項,但是同一臺機器上的例項在配置檔案中要確保http和tcp埠不同(下面有講)。
cluster:代表一個叢集,叢集中有多個節點,其中有一個會被選為主節點,這個主節點是可以通過選舉產生的,主從節點是對於叢集內部來說的。
shards:代表索引分片,es可以把一個完整的索引分成多個分片,這樣的好處是可以把一個大的索引拆分成多個,分佈到不同的節點上,構成分散式搜尋。分片的數量只能在索引建立前指定,並且索引建立後不能更改。
replicas:代表索引副本,es可以設定多個索引的副本,副本的作用一是提高系統的容錯性,當個某個節點某個分片損壞或丟失時可以從副本中恢復。二是提高es的查詢效率,es會自動對搜尋請求進行負載均衡。
2.下載
下載後,放到你的目錄下並解壓. 因為我們要配置包含三個節點的叢集,可以先將其重新命名為elasticsearch-node1。比如我的是 /home/zkpk/elasticsearch-node1。
3.修改配置檔案
(1) 初步修改
開啟/home/zkpk/elasticsearch-node1/config目錄下的elasticsearch.yml 檔案 ,修改以下屬性值並取消該行的註釋:
cluster.name: elasticsearch
#這是叢集名字,我們 起名為 elasticsearch。es啟動後會將具有相同叢集名字的節點放到一個叢集下。
node.name: "es-node1"
#節點名字。
covery.zen.minimum_master_nodes: 2
#指定叢集中的節點中有幾個有master資格的節點。對於大叢集可以寫3個以上。
discovery.zen.ping.timeout: 40s
#預設是3s,這是設定叢集中自動發現其它節點時ping連線超時時間,為避免因為網路差而導致啟動報錯,我設成了40s。
discovery.zen.ping.multicast.enabled: false
#設定是否開啟多播發現節點,預設是true。
network.bind_host: 192.168.137.100
#設定繫結的ip地址,這是我的master虛擬機器的IP。
network.publish_host: 192.168.137.100
#設定其它節點和該節點互動的ip地址。
network.host: 192.168.137.100
#同時設定bind_host和publish_host上面兩個引數。
discovery.zen.ping.unicast.hosts: ["192.168.137.100", "192.168.137.101","192.168.137.100:9301"]
#discovery.zen.ping.unicast.hosts:["節點1的 ip","節點2 的ip","節點3的ip"]
指明叢集中其它可能為master的節點ip,以防es啟動後發現不了叢集中的其他節點。第一對引號裡是node1,預設埠是9300。第二個是 node2 ,在另外一臺機器上。第三個引號裡是node3,因為它和node1在一臺機器上,所以指定了9301埠。- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
(2) 進一步修改
拷貝 elasticsearch-node1 整個資料夾,兩份,一份elasticsearch-node2,一份elasticsearch-node3.
將elasticsearch-node2 資料夾copy到另外一臺IP為192.168.137.101的機器上。而在 192.168.137.100 機器上有 node1和node3.
對於node3: node3和node1在一臺機器上,node1的配置檔案裡埠預設分別是9300和9200,所以要改一下node3配置檔案裡的埠,elasticsearch.yml 檔案修改如下:
node.name: "es-node3"
transport.tcp.port: 9301
http.port: 9201- 1
- 2
- 3
- 1
- 2
- 3
對於node2: 對 elasticsearch.yml 修改如下
node.name: "es-node2"
network.bind_host: 192.168.137.101
network.publish_host: 192.168.137.101
network.host: 192.168.137.101- 1
- 2
- 3
- 4
- 1
- 2
- 3
- 4
注意:
1.對於單機多節點的es叢集,一定要注意修改 transport.tcp.port 和http.port 的預設值保證節點間不衝突。
2. 出現找不到同一叢集中的其他節點的情況,檢查下 discovery.zen.ping.unicast.hosts 是否已設定。
二、執行 & 關閉 elasticsearch
1.執行elasticsearch :
編輯 /home/zkpk/elasticsearch-1.7.3/bin/elasticsearch.in.sh, 設定 ES_MIN_MEM和ES_MAX_MEM,確保二者數值一致,或者可以在啟動es時指定,
[zkpk@master ~]$ cd ~/elasticsearch-node1/bin
[zkpk@master bin]$ ./elasticsearch -Xms512m -Xmx512m- 1
- 2
- 1
- 2
若想讓es後臺執行,則
[zkpk@master bin]$ ./elasticsearch -d -Xms512m -Xmx512m- 1
- 1
2.關閉elasticsearch:
前臺執行:可以通過”CTRL+C”組合鍵來停止執行
後臺執行,可以通過”kill -9 程序號”停止.也可以通過REST API介面:
curl -XPOST http://主機IP:9200/_cluster/nodes/_shutdown- 1
- 1
來關閉整個叢集,通過:
curl -XPOST http://主機IP:9200/_cluster/nodes/節點標示符(如es-node1)/_shutdown- 1
- 1
來關閉單個節點.
三、外掛及其安裝
BigDesk Plugin : 對叢集中es狀態進行監控。
Elasticsearch Head Plugin: 對ES進行各種操作,如查詢、刪除、瀏覽索引等。
1.安裝head外掛
進入到節點elasticsearch-node1/bin路徑,並安裝外掛。
[zkpk@master bin]$ ./plugin -install mobz/elasticsearch-head- 1
- 1
2. 安裝bigdesk
[zkpk@master bin]$ ./plugin -install lukas-vlcek/bigdesk
讓我們看下es頁面吧~~
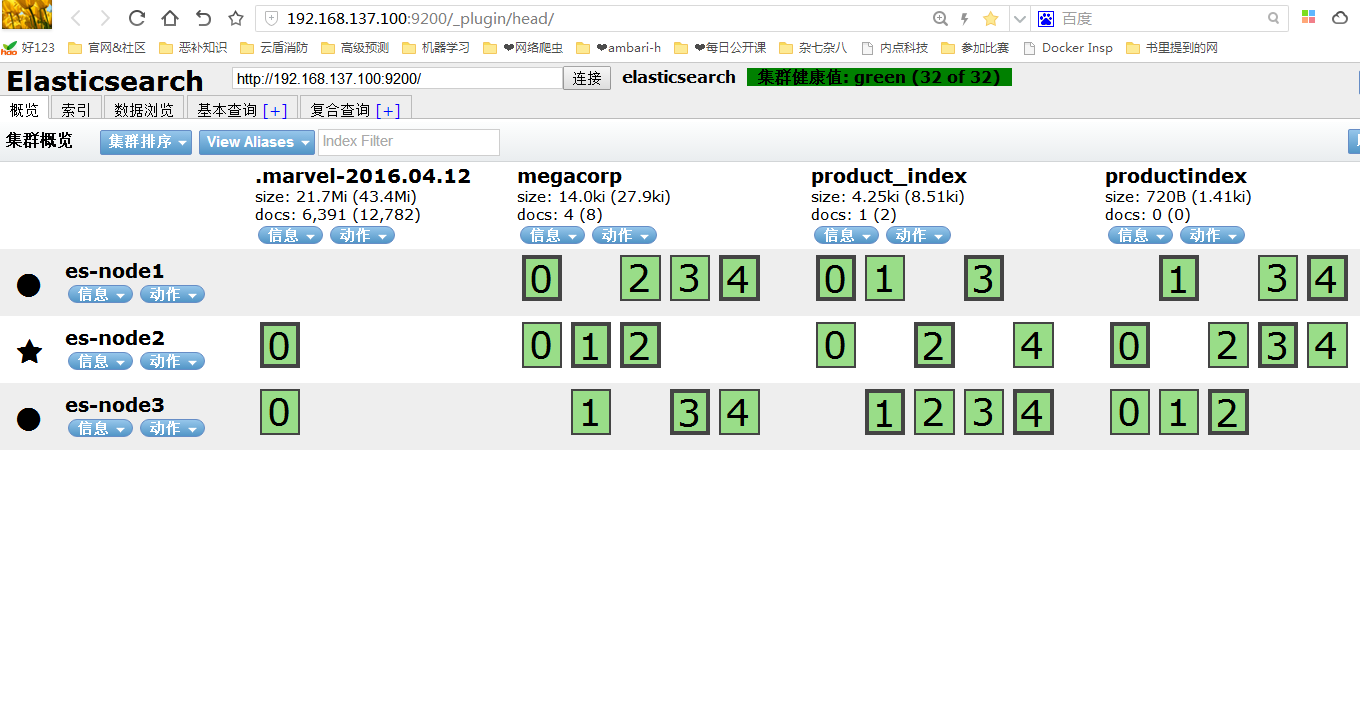
每個小方塊就是索引分片,可以看到每個索引被分成幾個分片,每個分片還有它的備份分片,然後儲存在三個節點上。粗框的是主分片,細框的是備份分片。
四、新增索引
現在我們來新增一個索引記錄吧~
1.可以在命令視窗通過命令來新增
curl -XPUT 'http://主機IP:9200/dept/employee/32' -d '{ "empname": "emp32"}'- 1
- 1
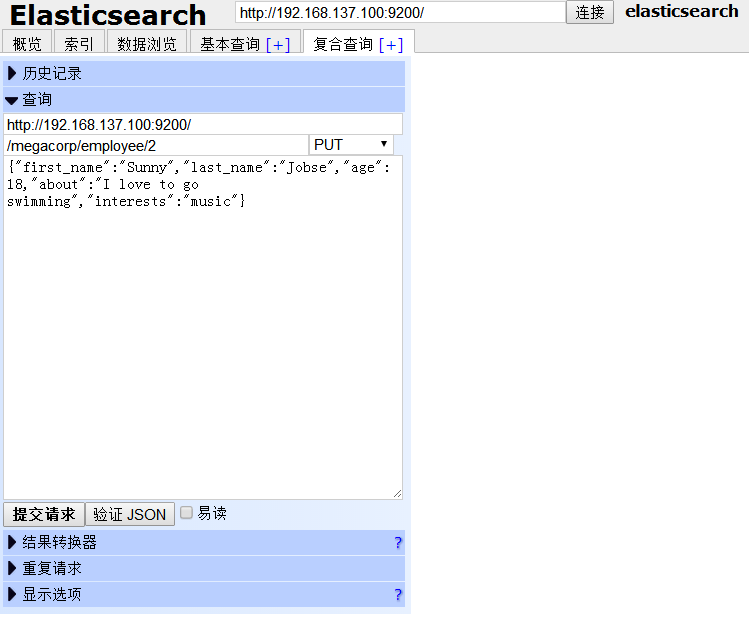
2.我們可以在頁面上通過JSON新增
(1)點選 複合查詢[+] ,我們可以在 megacorp 索引 (相當於資料庫名)的 employee 型別(相當於表名)下新增一個id為2的人的資訊。
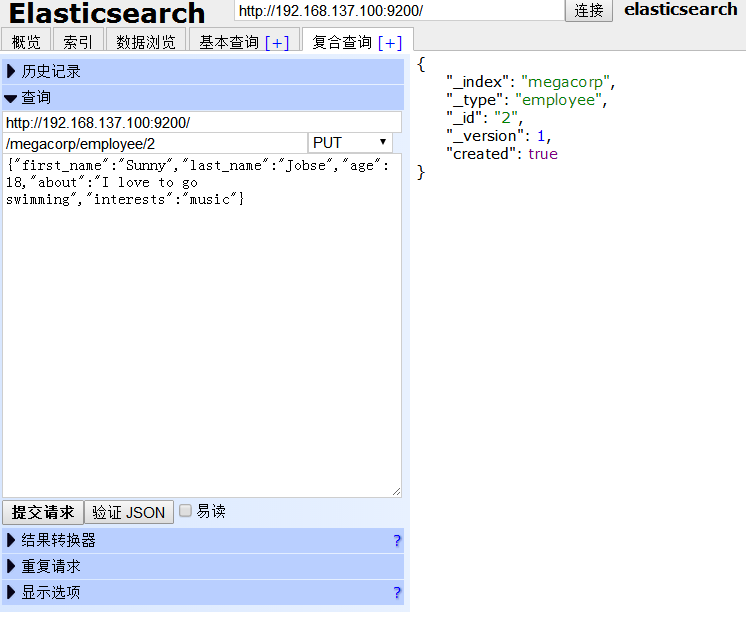
點選下方的 提交請求 按鈕,頁面右方有回饋資訊,“created”代表是否為新建。新增成功。
相關推薦
ES(elasticsearch)搜尋引擎安裝和使用
大資料時代,搜尋無處不在。搜尋技術是全棧工程師必備技術之一,如今是開源時代,數不盡的資源供我們利用,如果要自己寫一套搜尋引擎無疑是浪費繩命。本節主要介紹搜尋引擎開源專案elasticSearch的安裝和使用 為什麼需要搜尋引擎 首先想一下:在一篇文章裡找一個關鍵詞
二十四、ES(elasticsearch)搜尋引擎安裝和使用
大資料時代,搜尋無處不在。搜尋技術是全棧工程師必備技術之一,如今是開源時代,數不盡的資源供我們利用,如果要自己寫一套搜尋引擎無疑是浪費繩命。本節主要介紹搜尋引擎開源專案elasticSearch的安裝和使用 為什麼需要搜尋引擎 首先想一下:在一篇文章裡找一個關鍵
ES(elasticsearch)搜尋引擎使用(一)
版權宣告:本文為博主原創文章,未經博主允許不得轉載。轉載請務必加上原作者:銘毅天下,原文地址:blog.csdn.net/laoyang360 https://blog.csdn.net/wojiushiwo987/article/details/52244917 API連結:
elasticsearch搜尋引擎安裝部署
實驗環境:redhat6.5 server1 172.25.35.1 redhat6.5 server1 172.25.35.2redhat6.5 server1 172.25.35.3準備安裝包;[[email protected] elk]# lsbigdesk-master.zip jemal
linux下 elasticsearch的安裝和配置(一)
1. 安裝地址 https://www.elastic.co/products/elasticsearch 2. 使用 xshell 將壓縮包上傳到linux上,解壓elasticsearch-5.6.1.tar.gz到/home目錄下。 切記不要放在root目錄下 3
elasticsearch的安裝和啟動(親測可行)
此處我使用的是elasticsearch的最新版本elasticsearch-5.3.0,官網對這個版本的安裝的唯一要求就是使用jdk的1.8版本(此時最高版本) elasticsearch5.3的rpm官網下載 如果官網下載很慢可以使用下面的下載路徑進行下
Elasticsearch-Head安裝和使用 Elasticsearch-Head 外掛連線不上叢集
5、CORS解釋wiki上的解釋是 Cross-origin resource sharing (CORS) is a mechanism that allows restricted resources ,即跨域訪問。 這個欄位預設為false,在Elasticsearch安裝叢集之外的一臺機上用Sens
實時搜尋引擎Elasticsearch(1)——基礎概念、安裝和執行
Elasticsearch(簡稱ES)是一個基於Apache Lucene(TM)的開源搜尋引擎,無論在開源還是專有領域,Lucene可以被認為是迄今為止最先進、效能最好的、功能最全的搜尋引擎庫。 Elasticsearch簡介 Elasticsearch是什麼 Ela
ElasticSearch入門 - 安裝es服務端和Kibana客戶端
ElasticSearch是什麼?? 和Lucene一樣,都是用來做全文檢索(建立索引和搜尋索引).只是lucene是全文檢索工具包,而ES是全文搜尋伺服器 為什麼要用全文檢索? --> 以基於索引的搜尋代替資料庫模糊查詢,增強查詢效率
ElasticSearch搜尋引擎(一:es安裝及增刪改)
ElasticSearch下載地址:https://www.elastic.co/cn/downloads/elasticsearch es是一個使用java編寫的開源專案,所以需要jdk環境支援(且jdk版本須在1.8以上),安裝方式簡單粗暴,通過上方地址下載完壓縮包後直接解壓,進入bin目錄
Zeppelin 學習筆記之 Zeppelin安裝和elasticsearch整合
XML exp ado 8.0 elk mage search tor 選擇 Zeppelin安裝: Apache Zeppelin提供了web版的類似ipython的notebook,用於做數據分析和可視化。背後可以接入不同的數據處理引擎,包括spark, hive,
【ElasticSearch篇】--ElasticSearch從初識到安裝和應用
sequence ria wan shard 主機 single when please lock 一、前述 ElasticSearch是一個基於Lucene的搜索服務器。它提供了一個分布式多用戶能力的全文搜索引擎,基於RESTful web接口,在企業中全文搜索時,特別常
elasticsearch系列一:elasticsearch(ES簡介、安裝&配置、集成Ikanalyzer)
ins 表示 吞吐量 search 工作 use art tcp傳輸 .net 一、ES簡介 1. ES是什麽? Elasticsearch 是一個開源的搜索引擎,建立在全文搜索引擎庫 Apache Lucene 基礎之上 用 Java 編寫的,它的內部使用 Lucene
ElasticSearch 學習記錄之 分散式文件儲存往ES中存資料和取資料的原理
分散式文件儲存 ES分散式特性 遮蔽了分散式系統的複雜性 叢集內的原理 垂直擴容和水平擴容 真正的擴容能力是來自於水平擴容–為叢集新增更多的節點,並且將負載壓力和穩定性分散到這些節點中 ES叢集特點 一個叢集擁有相同
Elasticsearch學習(三)在windows上安裝和啟動Elasticseach
步驟 1、安裝JDK,至少1.8.0_73以上版本,java -version 2、下載和解壓縮Elasticsearch安裝包,目錄結構 3、啟動Elasticsearch:bin\elasticsearch.bat,es本身特點之一就是開箱即用,如果是中小型應用,資料量少,操作不
第一章 python分散式爬蟲打造搜尋引擎環境搭建 第一節 CentOS7環境下pycharm的安裝和使用
時下最流行的大資料想必大家都很耳熟了,作為程式設計師,我們需要不時的夯實一下自己的知識!在接下來的一個月內,我會在此記錄下自己學習的點點滴滴,一來方便自己日後檢視,二來給初學者提供點學習思路!堅持就是勝利,你比別人差的只是每天的點滴積累!想要開始
Elasticsearch安裝和相關外掛的安裝
Elasticsearch官網:https://www.elastic.co/cn/products/elasticsearch Elasticsearch下載:在這裡選擇適合自己的sha 安裝(elasticsearch無需安裝,解壓即用) 雙擊
搜尋框架搭建1:elasticsearch安裝和視覺化工具kibana、分詞外掛jieba安裝
elasticsearch安裝和視覺化工具kibana、分詞外掛jieba安裝 1 Windosw環境 1.1 java環境安裝 1.2 elasticsearch安裝 1.3 視覺化介面kibana安裝 1.
1、ElasticSearch的安裝配置和使用
一、安裝 按照個人習慣我習慣把自己的軟體都安裝到opt下 解壓 tar -zxvf elasticsearch-6.3.2.tar.gz 重新命名 mv elasticsearch-6.3.2.tar.gz esearch
在windows上安裝和啟動Elasticsearch+kibana
首先需要安裝JDK 至少需要1.8.0_73以上版本,參考這篇文章https://blog.csdn.net/u012934325/article/details/73441617/ 下載和解壓縮Elasticsearch安裝包並執行elasticsearch.