
Spark Streaming on Kafka解析和安裝實戰
本博文內容主要包括以下幾點:
1、Kafka解析;
2、Kafka的安裝和實戰。
一、Kafka的概念、架構和用例場景:
1、Kafka的概念:
Apache Kafka是分散式釋出-訂閱訊息系統。
它提供了類似於JMS的特性,但是在設計實現上完全不同,此外它並不是JMS規範的實現。Kafka是一種快速、可擴充套件的、設計內在就是分散式的,分割槽的和可複製的提交日誌服務。
kafka對訊息儲存時根據Topic(及傳送訊息內容)進行歸類,傳送訊息者成為Producer,訊息接受者成為Consumer,此外kafka叢集有多個kafka例項組成,每個例項(server)成為broker。
Kafka就是這樣的通訊元件,將不同物件元件粘合起來的紐帶,且是解耦合方式傳遞資料。
2,為何使用訊息系統:
(1)解耦
在專案啟動之初來預測將來專案會碰到什麼需求,是極其困難的。訊息系統在處理過程中間插入了一個隱含的、基於資料的介面層,兩邊的處理過程都要實現這一介面。這允許你獨立的擴充套件或修改兩邊的處理過程,只要確保它們遵守同樣的介面約束。
(2)冗餘
有些情況下,處理資料的過程會失敗。除非資料被持久化,否則將造成丟失。訊息佇列把資料進行持久化直到它們已經被完全處理,通過這一方式規避了資料丟失風險。許多訊息佇列所採用的”插入-獲取-刪除”正規化中,在把一個訊息從佇列中刪除之前,需要你的處理系統明確的指出該訊息已經被處理完畢,從而確保你的資料被安全的儲存直到你使用完畢。
(3)擴充套件性
因為訊息佇列解耦了你的處理過程,所以增大訊息入隊和處理的頻率是很容易的,只要另外增加處理過程即可。不需要改變程式碼、不需要調節引數。擴充套件就像調大電力按鈕一樣簡單。
(4)靈活性 & 峰值處理能力
在訪問量劇增的情況下,應用仍然需要繼續發揮作用,但是這樣的突發流量並不常見;如果為以能處理這類峰值訪問為標準來投入資源隨時待命無疑是巨大的浪費。使用訊息佇列能夠使關鍵元件頂住突發的訪問壓力,而不會因為突發的超負荷的請求而完全崩潰。
(5)可恢復性
系統的一部分元件失效時,不會影響到整個系統。訊息佇列降低了程序間的耦合度,所以即使一個處理訊息的程序掛掉,加入佇列中的訊息仍然可以在系統恢復後被處理。
(6)順序保證
在大多使用場景下,資料處理的順序都很重要。大部分訊息佇列本來就是排序的,並且能保證資料會按照特定的順序來處理。Kafka保證一個Partition內的訊息的有序性。
(7)緩衝
在任何重要的系統中,都會有需要不同的處理時間的元素。例如,載入一張圖片比應用過濾器花費更少的時間。訊息佇列通過一個緩衝層來幫助任務最高效率的執行———寫入佇列的處理會盡可能的快速。該緩衝有助於控制和優化資料流經過系統的速度。
(8)非同步通訊
很多時候,使用者不想也不需要立即處理訊息。訊息佇列提供了非同步處理機制,允許使用者把一個訊息放入佇列,但並不立即處理它。想向佇列中放入多少訊息就放多少,然後在需要的時候再去處理它們。
Apache Kafka與傳統訊息系統相比,有以下不同的特點:
(1)分散式系統,易於向外擴充套件;
(2)線上低延遲,同時為釋出和訂閱提供高吞吐量;
(3)將訊息儲存到磁碟,因此可以處理1天甚至1周前內容
3、Kafka的架構:

Kafka既然具備訊息系統的基本功能,那麼就必然會有組成訊息系統的元件:Topic,Producer和Consumer。Kafka還有其特殊的Kafka Cluster元件。
Topic主題:
代表一種資料的類別或型別,工作、娛樂、生活有不同的Topic,生產者需要說明把說明資料分別放在那些Topic中,裡面就是一個個小物件,並將資料資料推到Kafka,消費者獲取資料是pull的過程。一組相同型別的訊息資料流。這些訊息在Kafka會被分割槽存放,並且有多個副本,以防資料丟失。每個分割槽的訊息是順序寫入的,並且不可改寫。
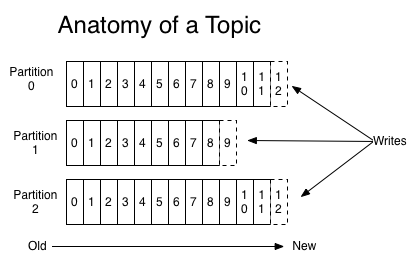
Producer(生產者):把資料推到Kafka系統的任何物件。
- Kafka Cluster(Kafka叢集):把推到Kafka系統的訊息儲存起來的一組伺服器,也叫Broker。因為Kafka叢集用到了Zookeeper作為底層支援框架,所以由一個選出的伺服器作為Leader來處理所有訊息的讀和寫的請求,其他伺服器作為Follower接受Leader的廣播同步備份資料,以備災難恢復時用。
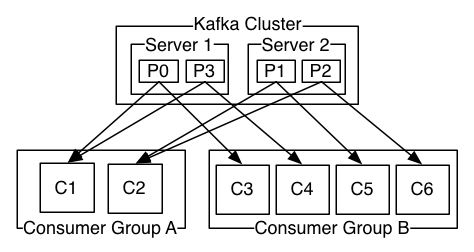
Consumer(消費者):從Kafka系統訂閱訊息的任何物件。
消費者可以有多個,並且某些消費者還可以組成Consumer Group。多個Consumer Group之間組成訊息廣播的關係,所以各個Group可以拉相同的訊息資料。在Consumer Group內部,各消費者之間對Consumer Group拉出來的訊息資料是佇列先進先出的關係,某個訊息資料只能給該Group的一個消費者使用。
資料傳輸基於kernel(核心)級別的(傳輸速度接近0拷貝-ZeroCopy)、沒有使用者空間的參與。Linux本身是軟體,軟體啟動時第一個啟動程序叫init,在init程序啟動後會進入使用者空間;例如:在分散式系統中,機器A上的應用程式需要讀取機器B上的Java服務資料,由於Java程式對應的JVM是使用者空間級別而且資料在磁碟上,A上應用程式讀取資料時會首先進入機器B上的核心空間再進入機器B的使用者空間,讀取使用者空間的資料後,資料再經過B機器上的核心空間分發到網路中,機器A網絡卡接收到傳輸過來的資料後再將資料寫入A機器的核心空間,從而最終將資料傳輸給A的使用者空間進行處理。如下圖:

外部系統從Java程式中讀取資料,傳輸給核心空間並依賴網絡卡將資料寫入到網路中,從而把資料傳輸出去。其實Java本身是核心的一層外衣,Java Socket程式設計,操作的各種資料都是在JVM的使用者空間中進行的。而Kafka操作資料是放在核心空間的,通常核心空間處理資料的速度比使用者空間快上萬倍,所以通過kafka可以實現高速讀、寫資料
二:Kafka的安裝:
1、最詳細的Zookeeper安裝和配置
Kafka叢集模式需要提前安裝好Zookeeper。
- 提示:Kafka單例模式不需要安裝額外的Zookeeper,可以使用內建的Zookeeper。
- Kafka叢集模式需要至少3臺伺服器。本課實戰用到的伺服器Hostname:master,slave1,slave2。
- 本博文中用到的Zookeeper版本是Zookeeper-3.4.6。
進入http://www.apache.org/dyn/closer.cgi/zookeeper/,你可以選擇其他映象網址去下載,用官網推薦的映象:http://mirror.bit.edu.cn/apache/zookeeper/提示:下載官網裡的的zookeeper-3.4.6.tar.gz 安裝檔案。
1) 安裝Zookeeper
提示:下面的步驟發生在master伺服器。
以ubuntu14.04舉例,把下載好的檔案放到root/Downloads目錄,用下面的命令解壓:
cd Downloads
tar -zxvf zookeeper-3.4.6.tar.gz
解壓後在Downloads目錄會多出一個zookeeper-3.4.6的新目錄,用下面的命令把它剪下到指定目錄即安裝好Zookeeper了:
cd Downloads
mv zookeeper-3.4.6 /usr/local/spark
之後在/usr/local/spark目錄會多出一個zookeeper-3.4.6的新目錄。下面我們講如何配置安裝好的Zookeeper。
2) 配置Zookeeper
提示:下面的步驟發生在master伺服器。
配置.bashrc
- 開啟檔案:vi ~/.bashrc
- 在PATH配置行前新增:
export ZOOKEEPER_HOME=/usr/local/spark/zookeeper-3.4.6
- 最後修改PATH:
export PATH=/usr/local/eclipse:${JAVA_HOME}/bin:${ZOOKEEPER_HOME}/bin:${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin:${SPARK_HOME}/bin:${SPARK_HOME}/sbin:${SCALA_HOME}/bin:${HIVE_HOME}/bin:${FLUME_HOME}/bin:$PATH- 使配置的環境變數立即生效:source ~/.bashrc
3)建立data目錄
- cd $ZOOKEEPER_HOME
- mkdir data
4)建立並開啟zoo.cfg檔案
- cd $ZOOKEEPER_HOME/conf
cp zoo_sample.cfg zoo.cfg
vi zoo.cfg
5)配置zoo.cfg,在zoo.cfg的文件中輸入下面的內容:
# The number of milliseconds of each tick
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
#dataDir=/tmp/zookeeper
# the port at which the clients will connect
#clientPort=2181
# the maximum number of client connections.
# increase this if you need to handle more clients
#maxClientCnxns=60
#
# Be sure to read the maintenance section of the
# administrator guide before turning on autopurge.
#http://zookeeper.apache.org/doc/current/zookeeperAdmin.htmlsc_maintenance
#
# The number of snapshots to retain in dataDir
#autopurge.snapRetainCount=3
# Purge task interval in hours
# Set to "0" to disable auto purge feature
#autopurge.purgeInterval=1
# 配置Zookeeper的日誌和伺服器身份證號等資料存放的目錄。
# 千萬不要用預設的/tmp/zookeeper目錄,因為/tmp目錄的資料容易被意外刪除。
dataDir=../data
# Zookeeper與客戶端連線的埠
clientPort=2181
# 在檔案最後新增3行配置每個伺服器的2個重要埠:Leader埠和選舉埠
# server.A=B:C:D:其中 A 是一個數字,表示這個是第幾號伺服器;
# B 是這個伺服器的hostname或ip地址;
# C 表示的是這個伺服器與叢集中的 Leader 伺服器交換資訊的埠;
# D 表示的是萬一叢集中的 Leader 伺服器掛了,需要一個埠來重新進行選舉,
# 選出一個新的 Leader,而這個埠就是用來執行選舉時伺服器相互通訊的埠。
# 如果是偽叢集的配置方式,由於 B 都是一樣,所以不同的 Zookeeper 例項通訊
# 埠號不能一樣,所以要給它們分配不同的埠號。
server.1=master:2888:3888
server.2=slave1:2888:3888
server.3=slave2:2888:38886)建立並開啟myid檔案
- cd $ZOOKEEPER_HOME/data
- touch myid
- vi myid
配置myid
按照zoo.cfg的配置,myid的內容就是1。
7) 同步master的安裝和配置到slave1和slave2
- 在master伺服器上執行下面的命令
cd /root
scp ./.bashrc root@slave1:/root
scp ./.bashrc root@slave2:/root
cd /usr/local/spark
scp -r ./zookeeper-3.4.6 root@slave1:/usr/local/spark
scp -r ./zookeeper-3.4.6 root@slave2:/usr/local/spark
- 在slave1伺服器上執行下面的命令
vi $ZOOKEEPER_HOME/data/myid
按照zoo.cfg的配置,myid的內容就是2。
- 在slave2伺服器上執行下面的命令
vi $ZOOKEEPER_HOME/data/myid
按照zoo.cfg的配置,myid的內容就是3。
8) 啟動Zookeeper服務
- 在master伺服器上執行下面的命令
zkServer.sh start
- 在slave1伺服器上執行下面的命令
source /root/.bashrc
zkServer.sh start
在slave1伺服器上執行下面的命令
source /root/.bashrc
zkServer.sh start
- 在slave2伺服器上執行下面的命令
source /root/.bashrc
zkServer.sh start
5) 驗證Zookeeper是否安裝和啟動成功
- 在master伺服器上執行(1)命令jps:

(2)zkServer.sh status命令:

- 在slave1伺服器上執行命令:jps和zkServer.sh status
source /root/.bashrc

在slave2伺服器上執行命令:jps和zkServer.sh status ……
至此,代表Zookeeper已經安裝和配置成功。
2,Kafka的安裝配置
本博文中用到的Kafka版本是Kafka-2.10-0.9.0.1。
1) 安裝Kafka
提示:下面的步驟發生在master伺服器。
以ubuntu14.04舉例,把下載好的檔案放到/root目錄,用下面的命令解壓:
cd /root
tar -zxvf kafka_2.10-0.9.0.1.tgz
解壓後在/root目錄會多出一個kafka_2.10-0.9.0.1的新目錄,用下面的命令把它剪下到指定目錄即安裝好Kafka了:
cd /root
mv kafka_2.10-0.9.0.1 /usr/local
之後在/usr/local目錄會多出一個kafka_2.10-0.9.0.1的新目錄。下面我們講如何配置安裝好的Kafka。
2) 配置Kafka
提示:下面的步驟發生在master伺服器。
(1)配置.bashrc
- 開啟檔案:vim ~/.bashrc
- 在PATH配置行前新增:
export KAFKA_HOME=/usr/local/kafka_2.10-0.9.0.1- 最後修改PATH:
export PATH=/usr/local/eclipse:${JAVA_HOME}/bin:${KAFKA_HOME}/bin:${ZOOKEEPER_HOME}/bin:${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin:${SPARK_HOME}/bin:${SPARK_HOME}/sbin:${SCALA_HOME}/bin:${HIVE_HOME}/bin:${FLUME_HOME}/bin:$PATH
使配置的環境變數立即生效:source ~/.bashrc
(2)配置server.properties:
cd $KAFKA_HOME/config
vi server.properties
配置server.properties,初步修改為下方這樣,後期將會進行跟複雜的修改,已達到效能最優情況:
broker.id=0
port=9092
zookeeper.connect=master:2181,slave1:2181,slave2:21813) 同步master的安裝和配置到slave1和slave2
- 在master伺服器上執行下面的命令
cd /root
scp ./.bashrc root@slave1:/root
scp ./.bashrc root@slave2:/root
cd /usr/local
scp -r ./kafka_2.10-0.9.0.1 root@slave1:/usr/local
scp -r ./kafka_2.10-0.9.0.1 root@slave2:/usr/local
- 在slave1伺服器上執行下面的命令
vi $KAFKA_HOME/config/server.properties
修改broker.id=1。
- 在slave2伺服器上執行下面的命令
vi $KAFKA_HOME/config/server.properties
修改broker.id=2。
4) 啟動Kafka服務
- 在master伺服器上執行下面的命令
cd $KAFKA_HOME/bin
kafka-server-start.sh ../config/server.properties &
- 在slave1伺服器上執行下面的命令
source /root/.bashrc
cd $KAFKA_HOME/bin
kafka-server-start.sh ../config/server.properties &
- 在slave2伺服器上執行下面的命令
source /root/.bashrc
cd $KAFKA_HOME/bin
kafka-server-start.sh ../config/server.properties &
5) 驗證Kafka是否安裝和啟動成功
- 在任意伺服器上執行命令建立Topic“HelloKafka”:
kafka-topics.sh –create –zookeeper master:2181,slave1:2181,slave2:2181 –replication-factor 3 –partitions 1 –topic HelloKafka
- 在任意伺服器上執行命令為建立的Topic“HelloKafka”生產一些訊息:
kafka-console-producer.sh –broker-list master:9092,slave1:9092,slave2:9092 –topic HelloKafka
輸入下面的訊息內容:
- 在任意伺服器上執行命令從指定的Topic“HelloKafka”上消費(拉取)訊息:
kafka-console-consumer.sh –zookeeper master:2181,slave1:2181,slave2:2181 –from-beginning –topic HelloKafka
過一會兒,你會看到列印的訊息內容:
- 在任意伺服器上執行命令檢視所有的Topic名字:
kafka-topics.sh –list –zookeeper master:2181,slave1:2181,slave2:2181
- 在任意伺服器上執行命令檢視指定Topic的概況:
kafka-topics.sh –describe –zookeepermaster:2181,slave1:2181,slave2:2181 –topic HelloKafka
至此,代表Kafka已經安裝和配置成功。
博文內容源自DT大資料夢工廠Spark課程。相關課程內容視訊可以參考:
百度網盤連結:http://pan.baidu.com/s/1slvODe1(如果連結失效或需要後續的更多資源,請聯絡QQ460507491或者微訊號:DT1219477246 獲取上述資料)。