
傳說時間複雜度為0(n)的排序
前面已經介紹了幾種排序演算法,像插入排序(直接插入排序,折半插入排序,希爾排序)、交換排序(氣泡排序,快速排序)、選擇排序(簡單選擇排序,堆排序)、2-路歸併排序(見我的另一篇文章:各種內部排序演算法的實現)等,這些排序演算法都有一個共同的特點,就是基於比較。本文將介紹三種非比較的排序演算法:計數排序,基數排序,桶排序。它們將突破比較排序的Ω(nlgn)下界,以線性時間執行。
一、比較排序演算法的時間下界
所謂的比較排序是指通過比較來決定元素間的相對次序。
“定理:對於含n個元素的一個輸入序列,任何比較排序演算法在最壞情況下,都需要做Ω(nlgn)次比較。”
也就是說,比較排序演算法的執行速度不會快於nlgn,這就是基於比較的排序演算法的時間下界
通過決策樹(Decision-Tree)可以證明這個定理,關於決策樹的定義以及證明過程在這裡就不贅述了。你可以自己去查詢資料,推薦觀看《MIT公開課:線性時間排序》。
根據上面的定理,我們知道任何比較排序演算法的執行時間不會快於nlgn。那麼我們是否可以突破這個限制呢?當然可以,接下來我們將介紹三種線性時間的排序演算法,它們都不是通過比較來排序的,因此,下界Ω(nlgn)對它們不適用。
二、計數排序(Counting Sort)
計數排序的基本思想就是對每一個輸入元素x,確定小於x的元素的個數,這樣就可以把x直接放在它在最終輸出陣列的位置上,例如:

演算法的步驟大致如下:
-
找出待排序的陣列中最大和最小的元素
-
統計陣列中每個值為i的元素出現的次數,存入陣列C的第i項
-
對所有的計數累加(從C中的第一個元素開始,每一項和前一項相加)
-
反向填充目標陣列:將每個元素i放在新陣列的第C(i)項,每放一個元素就將C(i)減去1
- /*************************************************************************
- > File Name: CountingSort.cpp
- > Author: SongLee
- > E-mail: [email protected]
-
> Created Time: 2014年06月11日 星期三 00時08分55秒
- > Personal Blog: http://songlee24.github.io
- ************************************************************************/
- #include<iostream>
- usingnamespace std;
- /*
- *計數排序:A和B為待排和目標陣列,k為陣列中最大值,len為陣列長度
- */
- void CountingSort(int A[], int B[], int k, int len)
- {
- int C[k+1];
- for(int i=0; i<k+1; ++i)
- C[i] = 0;
- for(int i=0; i<len; ++i)
- C[A[i]] += 1;
- for(int i=1; i<k+1; ++i)
- C[i] = C[i] + C[i-1];
- for(int i=len-1; i>=0; --i)
- {
- B[C[A[i]]-1] = A[i];
- C[A[i]] -= 1;
- }
- }
- /* 輸出陣列 */
- void print(int arr[], int len)
- {
- for(int i=0; i<len; ++i)
- cout << arr[i] << " ";
- cout << endl;
- }
- /* 測試 */
- int main()
- {
- int origin[8] = {4,5,3,0,2,1,15,6};
- int result[8];
- print(origin, 8);
- CountingSort(origin, result, 15, 8);
- print(result, 8);
- return 0;
- }
可能你會發現,計數排序似乎饒了點彎子,比如當我們剛剛統計出C,C[i]可以表示A中值為i的元素的個數,此時我們直接順序地掃描C,就可以求出排序後的結果。的確是這樣,不過這種方法不再是計數排序,而是桶排序,確切地說,是桶排序的一種特殊情況。
三、桶排序(Bucket Sort)
桶排序(Bucket Sort)的思想是將陣列分到有限數量的桶子裡。每個桶子再個別排序(有可能再使用別的排序演算法)。當要被排序的陣列內的數值是均勻分配的時候,桶排序可以以線性時間執行。桶排序過程動畫演示:Bucket Sort,桶排序原理圖如下:
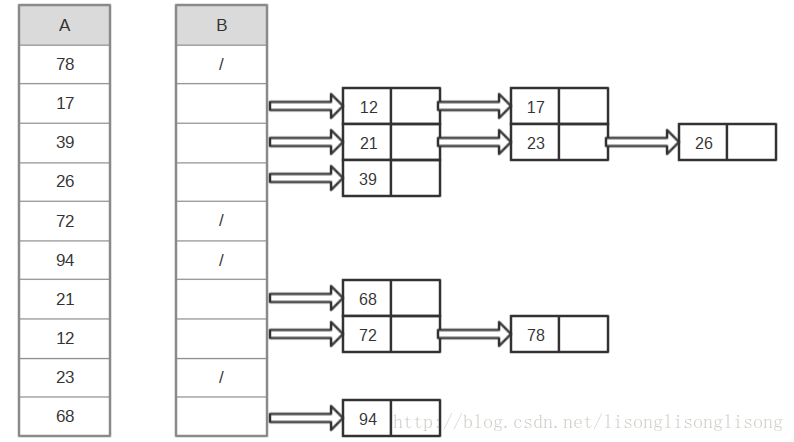
C++程式碼:
- /*************************************************************************
- > File Name: BucketSort.cpp
- > Author: SongLee
- > E-mail: [email protected]
- > Created Time: 2014年06月11日 星期三 09時17分32秒
- > Personal Blog: http://songlee24.github.io
- ************************************************************************/
- #include<iostream>
- usingnamespace std;
- /* 節點 */
- struct node
- {
- int value;
- node* next;
- };
- /* 桶排序 */
- void BucketSort(int A[], int max, int len)
- {
- node bucket[len];
- int count=0;
- for(int i=0; i<len; ++i)
- {
- bucket[i].value = 0;
- bucket[i].next = NULL;
- }
- for(int i=0; i<len; ++i)
- {
- node *ist = new node();
- ist->value = A[i];
- ist->next = NULL;
- int idx = A[i]*len/(max+1); // 計算索引
- if(bucket[idx].next == NULL)
- {
- bucket[idx].next = ist;
- }
- else/* 按大小順序插入連結串列相應位置 */
- {
- node *p = &bucket[idx];
- node *q = p->next;
- while(q!=NULL && q->value <= A[i])
- {
- p = q;
- q = p->next;
- }
- ist->next = q;
- p->next = ist;
- }
- }
- for(int i=0; i<len; ++i)
- {
- node *p = bucket[i].next;
- if(p == NULL)
- continue;
- while(p!= NULL)
- {
- A[count++] = p->value;
- p = p->next;
- }
- }
- }
- /* 輸出陣列 */
- void print(int A[], int len)
- {
- for(int i=0; i<len; ++i)
- cout << A[i] << " ";
- cout << endl;
- }
- /* 測試 */
- int main()
- {
- int row[11] = {24,37,44,12,89,93,77,61,58,3,100};
- print(row, 11);
- BucketSort(row, 235, 11);
- print(row, 11);
- return 0;
- }
四、基數排序(Radix Sort)
基數排序(Radix Sort)是一種非比較型排序演算法,它將整數按位數切割成不同的數字,然後按每個位分別進行排序。基數排序的方式可以採用MSD(Most significant digital)或LSD(Least significant digital),MSD是從最高有效位開始排序,而LSD是從最低有效位開始排序。
當然我們可以採用MSD方式排序,按最高有效位進行排序,將最高有效位相同的放到一堆,然後再按下一個有效位對每個堆中的數遞迴地排序,最後再將結果合併起來。但是,這樣會產生很多中間堆。所以,通常基數排序採用的是LSD方式。
LSD基數排序實現的基本思路是將所有待比較數值(正整數)統一為同樣的數位長度,數位較短的數前面補零。然後,從最低位開始,依次進行一次排序。這樣從最低位排序一直到最高位排序完成以後, 數列就變成一個有序序列。需要注意的是,對每一個數位進行排序的演算法必須是穩定的,否則就會取消前一次排序的結果。通常我們使用計數排序或者桶排序作為基數排序的輔助演算法。基數排序過程動畫演示:Radix
Sort
C++實現(使用計數排序):
- /*************************************************************************
- > File Name: RadixSort.cpp
- > Author: SongLee
- > E-mail: [email protected]
- > Created Time: 2014年06月22日 星期日 12時04分37秒
- > Personal Blog: http://songlee24.github.io
- ************************************************************************/
- #include<iostream>
- usingnamespace std;
- // 找出整數num第n位的數字
- int findIt(int num, int n)
- {
- int power = 1;
- for (int i = 0; i < n; i++)
- {
- power *= 10;
- }
-
相關推薦
傳說時間複雜度為0(n)的排序
前面已經介紹了幾種排序演算法,像插入排序(直接插入排序,折半插入排序,希爾排序)、交換排序(氣泡排序,快速排序)、選擇排序(簡單選擇排序,堆排序)、2-路歸併排序(見我的另一篇文章:各種內部排序演算法的實現)等,這些排序演算法都有一個共同的特點,就是基於比較。本文將介紹三種非比較的排序演算法:計數排序
對公司幾萬名員工按年齡排序(時間複雜度為O(N))
【0】 目錄 【1】題目 【2】分析 【3】測試程式碼 【4】測試結果 【1】題目: 面試官: 請實現一個排序演算法,要求時間複雜度為O(N) 應聘者:請問對什麼數字進行排序,共有多少數字? 面試官:我們想對公司所有員工按年齡排序,我們公司共有幾
實現排序演算法,時間複雜度為O(n)
我們常用的排序氣泡排序 O(n^2); 快速排序O(nlogn);堆排序O(nlogn);選擇排序O(n^2); 我們常用的排序都不符合時間複雜度的要求; 經常聽說一個說法 用空間代替時間 現在要排序的陣列為陣列 a;例如a數組裡面有 1,1,2,2,3,3,2,2,5
時間複雜度為O(N*logN)的常用排序演算法總結與Java實現
時間複雜度為O(N*logN)的常用排序演算法主要有四個——快速排序、歸併排序、堆排序、希爾排序1.快速排序·基本思想 隨機的在待排序陣列arr中選取一個元素作為標記記為arr[index](有時也直接選擇起始位置),然後在arr中從後至前以下標j尋找比arr[inde
面試題7-2:時間複雜度為O(n)的排序
問題:請實現一個排序演算法,要求排序一個公司幾萬名員工的年齡,要求時間複雜度為O(n)。 思路:要排序的序列元素數量比較大,不適合用傳統的排序方法,但問題的要求是排序員工的年齡,也就是說,每個元素都在一個很小的範圍之內(1-100)。 又要求時間複雜度為O(n),但沒有要求
將陣列排序,陣列中所有的負整數出現在正整數前面(時間複雜度為 O(n), 空間複雜度為 O(1)).
<pre name="code" class="plain">#include <stdio.h> #define N 10 void swap (int *a, int i,
有1,2,....一直到n的無序陣列,求排序演算法,要求時間複雜度為O(n),空間複雜度O(1)
http://blog.csdn.net/dazhong159/article/details/7921527 1、有1,2,....一直到n的無序陣列,求排序演算法,並且要求時間複雜度為O(n),空間複雜度O(1),使用交換,而且一次只能交換兩個數。 #include &
在一個含有空格字元的字串中加入XXX,演算法時間複雜度為O(N)
import java.util.Scanner; /** * */ /** * @author jueying: * @version 建立時間:2018-10-18 下午10:54:54 * 類說明 */ /** * @author jueying
【2019新浪&微博筆試題目】判斷連結串列是否為迴文結構,空間負責度為O(1),時間複雜度為O(n)
原題描述 判斷一個連結串列是否為迴文結構,要求額外空間複雜度為O(1),時間複雜度為O(n) 解題思路 一、雙向連結串列 如果連結串列是雙向連結串列,那簡直不要太完美。直接從連結串列兩端向中間遍歷即可判定 可惜,這個題目肯定不會說的是這種情況,
雜談——如何合併兩個有序連結串列(時間複雜度為O(n))
假設本帥博主有連結串列arr1: int[] arr1 = {1,3,6,8,23,34,56,77,90}; 連結串列arr2: int[] arr2 = {-90,34,55,79,87,98,123,234,567}; 我要如何才能夠合併這兩個有序連結串列,使得合併後的連結串列
計數排序--時間複雜度為線性的排序演算法
我們知道基於比較的排序演算法的最好的情況的時間複雜度是O(nlgn),然而存在一種神奇的排序演算法,不是基於比較的,而是空間換時間,使得時間複雜度能夠達到線性O(n+k),這種演算法就是本文將
【C++實現】第k大元素 時間複雜度為O(n),空間複雜度為O(1)
解題思路: 二基準快速排序,在排序時判斷每次找到的標記點下標 p 與 n-k 的大小,若小於n-k,則只需在p的右側繼續遞迴,若大於 p 則只需在p 的左側遞迴,直至 p 與 n-k 相等 vs可執行程式碼 #include<ctime> #includ
求最大連續子序列的和,時間複雜度為 O(n)
練習題目 給定陣列 [ a0, a1, a2, …, an ] ,找出其最大連續子序列和,要求時間複雜度為 O(n),陣列包含負數。 例如:輸入 [ -2,11,-4,13,-5,-2] ,輸出 20(即 11 到 13)。 解答 關於這個問題有很多種解法,這裡介紹一種時間複雜度僅為 O(n)
把一個含有N個元素的陣列迴圈右移K位, 要求時間複雜度為O(N)
分析與解法 這個解法其實在《啊哈!演算法》有講到。 假設原陣列序列為abcd1234,要求變換成的陣列序列為1234abcd,即迴圈右移了4位,比較之後,不難看出,其中有兩段的順序是不變的:1234和abcd,可把兩段看成兩個整體。右移K位的過程就是把陣列的兩部分交換一下。
長度為n的順序表L,編寫一個時間複雜度為O(n),空間複雜度為O(1)的演算法,該演算法刪除線性表中所有值為X的元素
解法:用K記錄順序表L中不等於X的元素個數,邊掃描L邊統計K,並將不等於X的元素向前放置K位置上,最後修改L長度 void del_x_1(SqList &L,Elemtype x){ int k=0; for(i=0;i<L.length;i++) {
Manacher演算法:求解最長迴文字串,時間複雜度為O(N)
迴文串定義:“迴文串”是一個正讀和反讀都一樣的字串,比如“level”或者“noon”等等就是迴文串。迴文子串,顧名思義,即字串中滿足迴文性質的子串。 經常有一些題目圍繞回文子串進行討論,比如POJ3974最長迴文,求最長迴文子串的長度。樸素演算法是依次以每一個字元為中心
刪除線性表中所有值為x的元素,要求時間複雜度為O(n),空間複雜度為O(1)
思路:統計不等於x的個數,用k記錄不等於x的元素的個數。邊統計邊把當前元素放在第k個位置上,最後修改表的長度 public static void del(List<Integer> l
分治法 求 逆序對數 的個數 時間複雜度為O(n*logn)
思路: 分治法 歸併排序的過程中,有一步是從左右兩個陣列中,每次都取出小的那個元素放到tmp[]陣列中 右邊的陣列其實就是原陣列中位於右側的元素。當不取左側的元素而取右側的元素時,說明左側剩下的元素均
尋找陣列中第k小的數:平均情況下時間複雜度為O(n)的快速選擇演算法
又叫線性選擇演算法,這是一種平均情況下時間複雜度為O(n)的快速選擇演算法,用到的是快速排序中的第一步,將第一個數作為中樞,使大於它的所有數放到它右邊,小於它的所有數放到它左邊。之後比較該中樞的最後位
演算法設計:將一個數組分為奇數、偶數左右兩個部分,要求時間複雜度為O(n)
已知陣列A[n]中的元素為整型,設計演算法將其調整為左右兩部分,左邊所有元素為奇數,右邊所有元素為偶數,並要求演算法的時間複雜度為O(n)。 程式碼實現部分: #include &l