
特徵選擇(三)-K-L變換
上一講說到,各個特徵(各個分量)對分類來說,其重要性當然是不同的。捨去不重要的分量,這就是降維。
聚類變換認為:重要的分量就是能讓變換後類內距離小的分量。
類內距離小,意味著抱團抱得緊。
但是,抱團抱得緊,真的就一定容易分類麼?
如圖1所示,根據聚類變換的原則,我們要留下方差小的分量,把方差大(波動大)的分量丟掉,所以兩個橢圓都要向y軸投影,這樣悲劇了,兩個重疊在一起,根本分不開了。而另一種情況卻可以這麼做,把方差大的分量丟掉,於是向x軸投影,很順利就能分開了。因此,聚類變換並不是每次都能成功的。
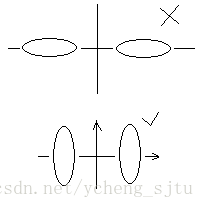
圖1
摧枯拉朽的K-L變換
K-L變換是理論上“最好”的變換:是均方誤差(MSE,MeanSquare Error)意義下的最佳變換,它在資料壓縮技術中佔有重要地位。
聚類變換還有一個問題是,必須一類一類地處理,把每類分別變換,讓它們各自抱團。
K-L變換要把所有的類別放在一起變換,希望通過這個一次性的變換,讓它們分的足夠開。
K-L變換認為:各類抱團緊不一定好區分。目標應該是怎麼樣讓類間距離大,或者讓不同類好區分。因此對應於2種K-L變換。
其一:最優描述的K-L變換(沿類間距離大的方向降維)
首先來看個二維二類的例子,如圖2所示。
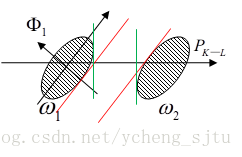
圖2
如果使用聚類變換,方向是方差最小的方向,因此降維向
方向投影,得到2類之間的距離即為2條紅線之間的距離,但是這並不是相隔最遠的投影方向。將橢圓投影到
方向,得到2類之間的距離為2條綠線之間的距離。這個方向就是用自相關矩陣的統計平均
設共有M個類別,各類出現的先驗概率為
以表示來自第i類的向量。則第i類叢集的自相關矩陣為:
混合分佈的自相關矩陣R是:
然後求出R的特徵向量和特徵值:
將特徵值降序排列(注意與聚類變換區別)
為了降到m維,取前m個特徵向量,構成變換矩陣A
以上便完成了最優描述的K-L變換。
為什麼K-L變換是均方誤差(MSE,MeanSquare Error)意義下的最佳變換?
其中表示n維向量y的第j個分量,
表示第個特徵分量。
引入的誤差
均方誤差為
從m+1開始的特徵值都是最小的幾個,所以均方誤差得到最小。
以上方法稱為最優描述的K-L變換,是沿類間距離大的方向降維,從而均方誤差最佳
本質上說,最優描述的K-L變換扔掉了最不顯著的特徵,然而,顯著的特徵其實並不一定對分類有幫助。我們的目標還是要找出對分類作用大的特徵,而不應該管這些特徵本身的強弱。這就誕生了第2種的K-L變換方法。
其二:最優區分的K-L變換(混合白化後抽取特徵)
針對上述問題,最優區分的K-L變換先把混合分佈白化,再來根據特徵值的分離程度進行排序。
最優區分的K-L變換步驟
首先還是混合分佈的自相關矩陣R
然後求出R的特徵向量和特徵值:
以上是主軸變換,實際上是座標旋轉,之前已經介紹過。
令變換矩陣
則有
這個作用是白化R矩陣,這一步是座標尺度變換,相當於把橢圓整形成圓,如圖3所示。
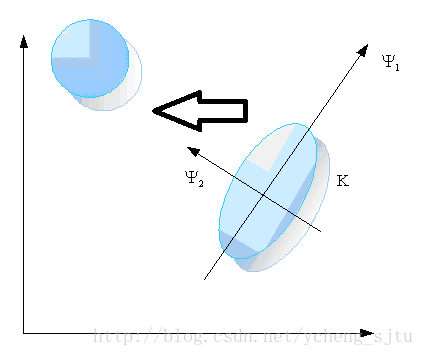
圖3
以二類混合分佈問題為例。
分別求出二類的特徵向量和特徵值,有
則二者的特徵向量完全相同,唯一的據別在於其特徵根,而且還負相關,即如果取降序排列時,則
以升序排列。
為了獲得最優區分,要使得兩者的特徵值足夠不同。因此,需要捨棄特徵值接近0.5的那些特徵,而保留使大的那些特徵,按這個原則選出了m個特徵向量記作
則總的最優區分的K-L變換就是:
歡迎參與討論並關注本部落格和微博以及知乎個人主頁,後續內容繼續更新哦~
轉載請您尊重作者的勞動,完整保留上述文字以及本文連結,謝謝您的支援!