
MySQL之SQL分析三部曲實際案例
阿新 • • 發佈:2019-02-20
------------------------------------------------------------正文------------------------------------------------------------
由於是生產環境下進行的,截圖和SQL都隱去了一些資訊
背景:有使用者在抱怨生產系統上,某一個Web的頁面太慢,忍無可忍
問題分析過程:略
問題聚焦:最終確定是某一個SQL語句太慢,查詢時間用了4s(慢查詢日誌給出的資訊)
SQL分析三部曲之一:explain,結果如下圖

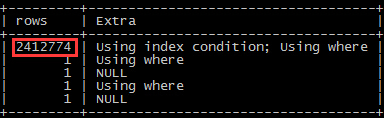
可以很明顯的看到主要問題出在tom表上,使用了索引還有這麼高的rows,從常規考慮來說,這個SQL使用了錯誤的索引
那麼檢視一下這個表上的索引,發現tom表上是存在聯合索引的,顯然,手動指定索引就可以了。
以解決問題為目的,就到上面就可以了,不過為了弄清楚優化器沒有選擇使用這個聯合索引,反而用了效率更低的其他的索引的原因,還需要看具體的優化器判斷過程
SQL分析三部曲之二:profile,拖慢SQL的主要問題在於掃描了不必要的資料,因此不必用profile來尋找時間消耗的主要目標
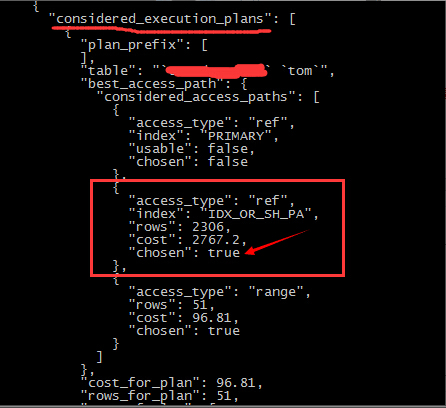
SQL分析三部曲之三:optimizer_trace,操作過程略,部分結果如圖
從下圖可以看到,在判斷where條件時,優化器選擇了這個聯合索引,同時計算出了rows和cost
接著往下看優化器的邏輯,在最後,由於SQL語句中有limit m,n的存在,優化器重新計算了使用這個索引的cost

接下來就是喜聞樂見的索引更換
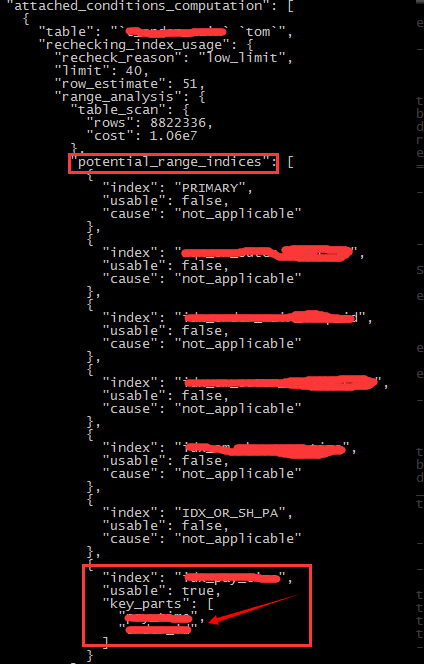
選擇另外一個索引是因為primary key和ptime的索引能夠組成二級索引,而且ptime也出現在了where的條件當中,所以最終的結果,就變成了最前面explain的extra裡面出現的Using index condition
在實際的測試和驗證過程中,刪掉limit語句以後,優化器就能正確的選擇最優的索引,也證明了limit m,n這個語句是導致優化器做出了錯誤判斷的罪魁禍首~
優化器計算的cost出現了問題?MySQL的優化器一直以來背了無數黑鍋(口碑爛
最後附上正確的執行計劃截圖
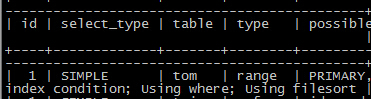

rows已經降到了11~
PS:Using index condition,這是在在5.6之後新加入的特性,index condition pushdown,百度可以搜到很多介紹的文章,這裡就略過了
由於是生產環境下進行的,截圖和SQL都隱去了一些資訊
背景:有使用者在抱怨生產系統上,某一個Web的頁面太慢,忍無可忍
問題分析過程:略
問題聚焦:最終確定是某一個SQL語句太慢,查詢時間用了4s(慢查詢日誌給出的資訊)
罪魁禍首的SQL語句:
select col1,col2......colN from tom inner join toa on tom.id = toa.id left join tov on tom.id = tov.id inner join toi on tom.id = toi.id left join fo on tom.stype = 2 and fo.id = tom.id WHERE ( tom.ostatus = 1 and tom.sid in ( 1 , 2 , 3) and tom.ptime >= '2333-01-01 09:41:58.056' and tom.ptime <= '2333-02-01 09:41:58.056' and tom.otype != 2 and toi.iid = '233333333333333' and tom.stype in ( 1 , 2 ) ) order by tom.ptime desc limit 20,20
SQL分析三部曲之一:explain,結果如下圖
可以很明顯的看到主要問題出在tom表上,使用了索引還有這麼高的rows,從常規考慮來說,這個SQL使用了錯誤的索引
那麼檢視一下這個表上的索引,發現tom表上是存在聯合索引的,顯然,手動指定索引就可以了。
以解決問題為目的,就到上面就可以了,不過為了弄清楚優化器沒有選擇使用這個聯合索引,反而用了效率更低的其他的索引的原因,還需要看具體的優化器判斷過程
SQL分析三部曲之二:profile,拖慢SQL的主要問題在於掃描了不必要的資料,因此不必用profile來尋找時間消耗的主要目標
SQL分析三部曲之三:optimizer_trace,操作過程略,部分結果如圖
從下圖可以看到,在判斷where條件時,優化器選擇了這個聯合索引,同時計算出了rows和cost
接著往下看優化器的邏輯,在最後,由於SQL語句中有limit m,n的存在,優化器重新計算了使用這個索引的cost
接下來就是喜聞樂見的索引更換
選擇另外一個索引是因為primary key和ptime的索引能夠組成二級索引,而且ptime也出現在了where的條件當中,所以最終的結果,就變成了最前面explain的extra裡面出現的Using index condition
在實際的測試和驗證過程中,刪掉limit語句以後,優化器就能正確的選擇最優的索引,也證明了limit m,n這個語句是導致優化器做出了錯誤判斷的罪魁禍首~
優化器計算的cost出現了問題?MySQL的優化器一直以來背了無數黑鍋(口碑爛
最後附上正確的執行計劃截圖
rows已經降到了11~
PS:Using index condition,這是在在5.6之後新加入的特性,index condition pushdown,百度可以搜到很多介紹的文章,這裡就略過了