
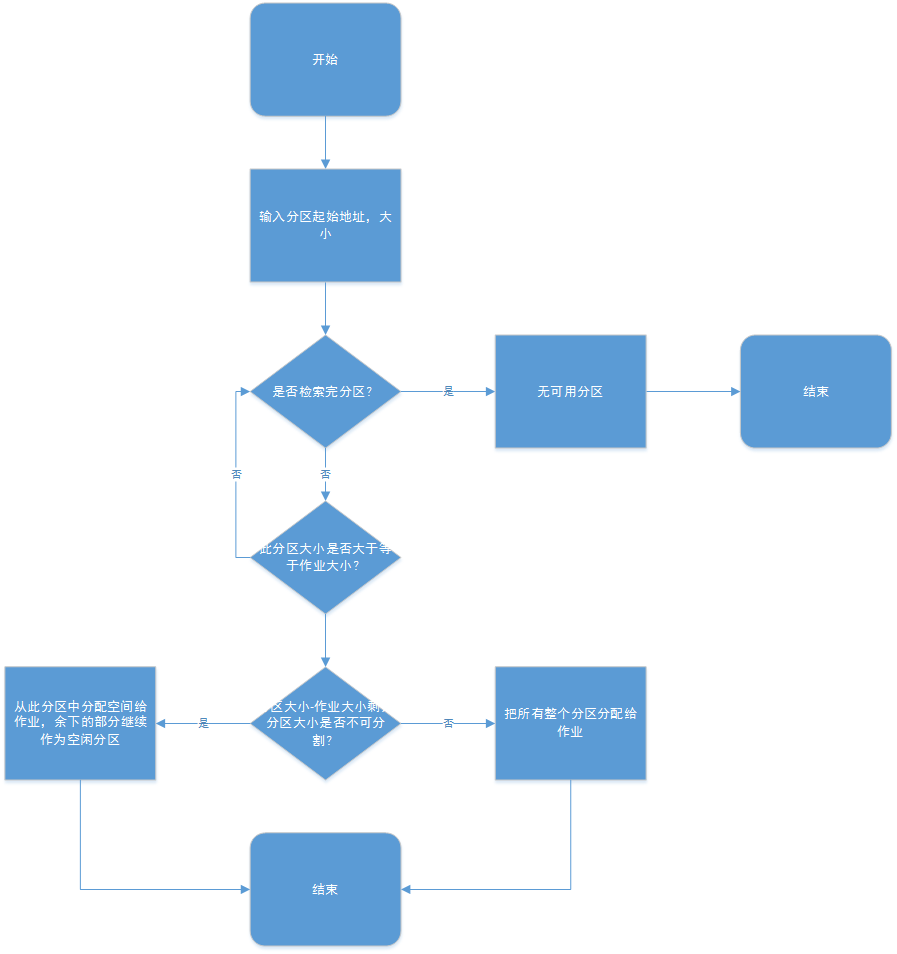
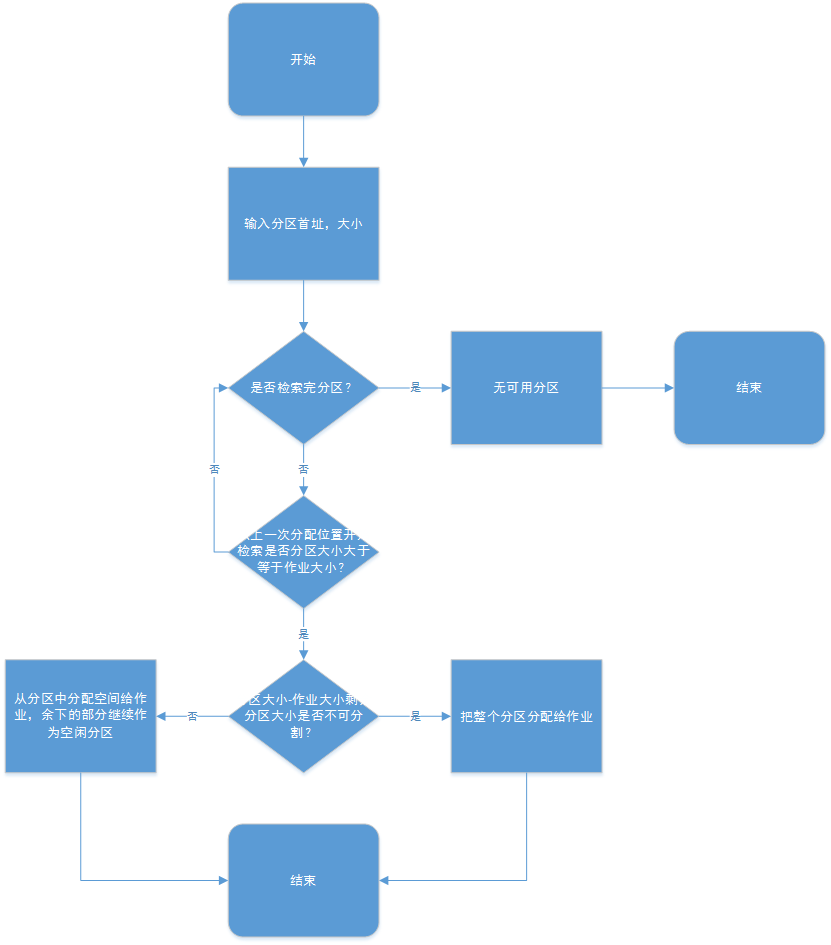
首次適應演算法(FF)和迴圈首次適應演算法(NF)
FF和NF演算法都是基於順序搜尋的動態分割槽分配演算法,在記憶體中檢索一塊分割槽分配給作業。如果空間大小合適則分配,如果找不到空間則等待。
FF演算法按地址遞增從頭掃描空閒分割槽,如果找到空閒分割槽大小>=作業大小則分配。如果掃描完空閒分割槽表都沒有找到分割槽,則分配失敗。
NF演算法和FF演算法類似,但是NF演算法每次分配都會記錄下位置,下次分配的時候從記錄的位置開始,迴圈掃描一遍空閒分割槽。
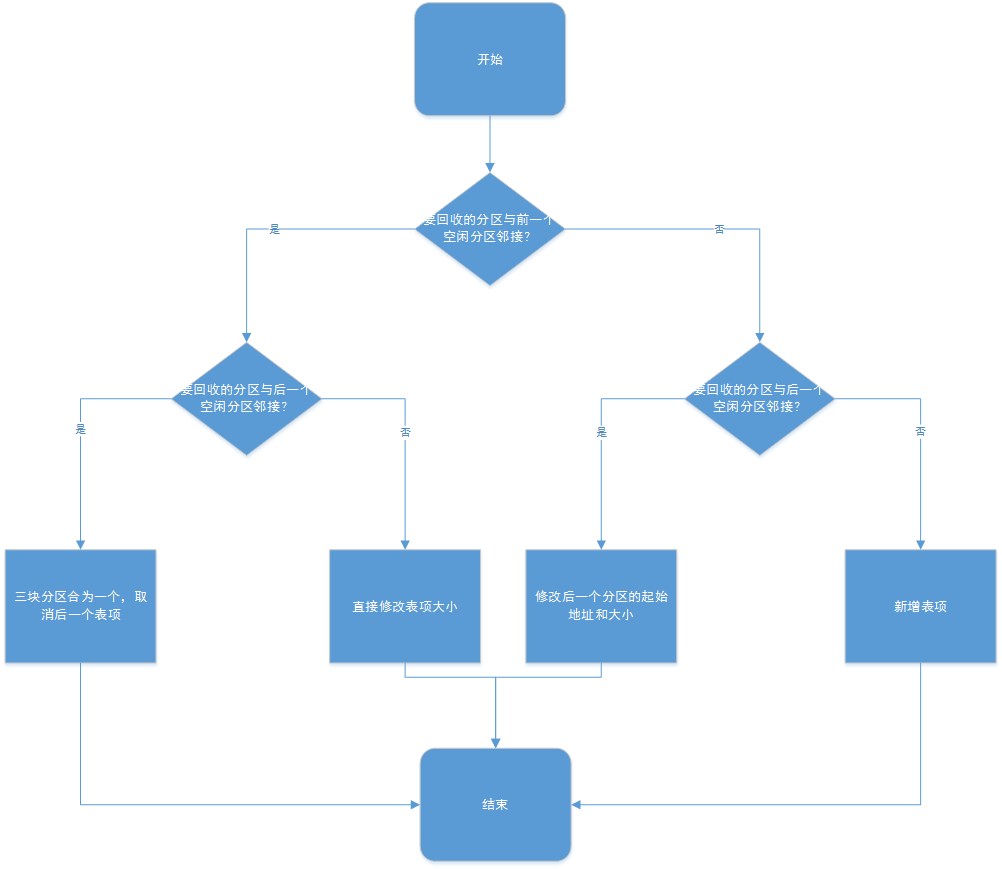
注:回收分割槽的演算法寫的和書上不太一樣,書上是分配過後把分割槽從空閒分割槽鏈中移除,我是直接分配然後狀態為設定為false,所以可能不太一樣。
- //公共模組,負責定義結構體,初始化,顯示結果,回收
- //BlockJob.h
- #ifndef BLOCKJOB_H_
- #define BLOCKJOB_H_
- #include <vector>
- constint MINSIZE = 10; //最小不可分割分割槽大小
- //空閒分割槽
- typedefstruct block
- {
- int start; //開始地址
- int size; //大小
- bool state; //分割槽狀態 true:空閒 false:佔用
- }block;
- //作業
- typedefstruct job
- {
- int size; //作業大小
- int start; //分配的分割槽首址
- int BlockSize; //分配空閒分割槽的大小(可能大於作業大小)
- };
- //初始化空閒分割槽與作業
- void init(std::vector<block> &BlockList, std::vector<job> &JobList);
- //顯示結果
- void show(std::vector<block> &BlockList, std::vector<job> &JobList);
- //回收分割槽
- void recycle(std::vector<block> &BlockList, std::vector<job> &JobList);
- #endif
- //BlockJob.cpp
- #include "BlockJob.h"
- #include <iostream>
- #include <iomanip>
- //初始化空閒分割槽與作業
- void init(std::vector<block> &BlockList, std::vector<job> &JobList)
- {
- std::cout << "輸入空閒分割槽數: ";
- int num;
- std::cin >> num;
- std::cout << "輸入空閒分割槽的起始地址與大小: \n";
- block temp;
- for (int i = 0; i < num; ++i)
- {
- std::cin >> temp.start >> temp.size;
- temp.state = true;
- BlockList.push_back(temp);
- }
- std::cout << "輸入作業數: ";
- std::cin >> num;
- std::cout << "輸入作業的大小: \n";
- job tempj;
- for (int i = 0; i < num; ++i)
- {
- std::cin >> tempj.size;
- tempj.BlockSize = 0;
- tempj.start = 0;
- JobList.push_back(tempj);
- }
- }
- //顯示結果
- void show(std::vector<block> &BlockList, std::vector<job> &JobList)
- {
- using std::setw;
- std::cout.setf(std::ios_base::left);
- std::cout << "空閒分割槽表: \n";
- std::cout << setw(10) << "分割槽號" << setw(10) << "分割槽大小" << setw(10) << "分割槽始址" << setw(10) << "狀態" << std::endl;
- int num = 0;
- for (std::vector<block>::iterator it = BlockList.begin(); it != BlockList.end(); ++it, ++num)
- std::cout << setw(10) << num << setw(10) << (*it).size << setw(10) << (*it).start << setw(10) << (((*it).state == true) ? "空閒" : "佔用") << std::endl;
- std::cout << "作業資訊: \n";
- std::cout << setw(10) << "作業號" << setw(10) << "作業大小" << setw(10) << "分割槽大小" << setw(10) << "分割槽始址" << std::endl;
- num = 0;
- for (std::vector<job>::iterator it = JobList.begin(); it != JobList.end(); ++it, ++num)
- std::cout << setw(10) << num << setw(10) << (*it).size << setw(10) << (*it).BlockSize << setw(10) << (*it).start << std::endl;
- }
- //回收分割槽
- void recycle(std::vector<block> &BlockList, std::vector<job> &JobList)
- {
- std::cout << "輸入回收分割槽的首址: ";
- int start;
- std::cin >> start;
- for (std::vector<block>::iterator it = BlockList.begin(); it != BlockList.end(); ++it)
- {
- //找到要回收的分割槽
- if (start == (*it).start)
- {
- //與前一個分割槽鄰接
- if (it != BlockList.begin() && (*(it - 1)).start + (*(it - 1)).size == (*it).start)
- {
- //與後一個分割槽鄰接
- if (it != BlockList.end() - 1 && (*it).start + (*it).size == (*(it + 1)).start)
- {
- //將前一塊分割槽,要回收的分割槽,後一塊分割槽合併
- (*(it - 1)).size += (*it).size + (*(it + 1)).size;
- (*(it - 1)).state = true;
- BlockList.erase(it);
- BlockList.erase(it);
- }
- else//不與後一個分割槽鄰接
- {
- //將此分割槽與前一個分割槽合併
- (*(it - 1)).size += (*it).size;
- (*(it - 1)).state = true;
- BlockList.erase(it);
- }
- }
- elseif(it != BlockList.end()-1 && (*it).start +(*it).size == (*(it+1)).start) //不與前一個分割槽鄰接,與後一個分割槽鄰接
- {
- //將此分割槽與後一個分割槽合併
- (*it).size += (*(it + 1)).size;
- (*it).state = true;
- BlockList.erase(it + 1);
- }
- else//都不鄰接
- {
- (*it).state = true;
- }
- break;
- }
- }
- for (std::vector<job>::iterator it = JobList.begin(); it != JobList.end(); ++it)
- {
-
相關推薦
首次適應演算法(FF)和迴圈首次適應演算法(NF)
FF和NF演算法都是基於順序搜尋的動態分割槽分配演算法,在記憶體中檢索一塊分割槽分配給作業。如果空間大小合適則分配,如果找不到空間則等待。FF演算法按地址遞增從頭掃描空閒分割槽,如果找到空閒分割槽大小>=作業大小則分配。如果掃描完空閒分割槽表都沒有找到分割槽,則分配失敗。NF演算法和FF演算法類似,但是
HMAC-SHA1簽名演算法(JAVA和PHP) base64簽名演算法(PHP)
HMAC 根據RFC 2316(Report of the IAB,April 1998),HMAC(雜湊訊息身份驗證碼: Hashed Message Authentication Code)以及IPSec被認為是Interact安全的關鍵性核心協議。它不是雜湊函式,而是採用了將MD5或S
反彙編演算法介紹和應用——線性掃描演算法分析
做過逆向的朋友應該會很熟悉IDA和Windbg這類的軟體。IDA的強項在於靜態反彙編,Windbg的強項在於動態除錯。往往將這兩款軟體結合使用會達到事半功倍的效果。可能經常玩這個的朋友會發現IDA反彙
最小生成樹(prime演算法、kruskal演算法) 和 最短路徑演算法(floyd、dijkstra)
簡介: 帶權圖分為有向和無向,無向圖的最短路徑又叫做最小生成樹,有prime演算法和kruskal演算法;有向圖的最短路徑演算法有dijkstra演算法和floyd演算法。 生成樹
HMAC-SHA1簽名演算法(JAVA和PHP) base64簽名演算法(PHP)
HMAC 根據RFC 2316(Report of the IAB,April 1998),HMAC(雜湊訊息身份驗證碼: Hashed Message Authentication Code)以及IPSec被認為是Interact安全的關鍵性核心協議。它不是雜湊函式,而是
斯坦福演算法設計和分析_3. 分治演算法
本文預計閱讀時間4分鐘,在讀的過程中你需要帶著以下問題: 分治演算法的基本步驟 逆序對計數是如何使用分治演算法來解決問題的 為什麼MergeSort排序法可以自然的算出逆序對數目 分值策略一般步驟 把輸入劃分成更小的子問題。 遞迴的治理子問題。 把子問題
斯坦福演算法分析和設計_2. 排序演算法MergeSort
Motivate MergeSort是個相對古老的演算法了,為什麼現在我們還要討論這麼古老的東西呢?有幾個原因: 它雖然年齡很大了,但是在實踐中一直被沿用,仍然是很多程式庫中的標準演算法之一。 實現它的本質是分治思想,是一個理解分治演算法思想的好例子,好起點。 本文會使用
迴圈首次適應演算法、首次適應演算法、最佳適應演算法_C語言版
#include <stdio.h> #define getpch(type) (type*)mallloc(sizeof(type)) strct LNode { int size; int start; int end; struct LNode *
動態分割槽分配-迴圈首次適應演算法+最佳適應演算法
(文章待更新) (1)採用空閒區表,並增加已分配區表{未分配區說明表、已分配區說明表(分割槽號、起始地址、長度、狀態)}。分配演算法採用最佳適應演算法(記憶體空閒區按照尺寸大小從小到大的排列)和迴圈首次適應演算法,實現記憶體的分配與回收。 #include<iostr
2017年總結的前端文章——border屬性的多方位應用和實現自適應三角形
content ott 現在 修改 缺點 顏色 b- 固定 瀏覽器 border屬性是在實際的應用中使用頻率比較高的一個屬性,除了作為邊框使用,利用border屬性的一些特征以及表現方式,可以在實現一些比較常見的效果(如等高布局,上下固定內容滾動布局和繪制CSS圖標等),利
記一次產品需求:圖片等比縮放和CSS自適應布局16:9
是我 width 圖片展示 網上 IT tom 就會 很好 尺寸 前言 前陣子,產品跑過來問我現有的模板中沒有圖片模板,需要添加一個圖片模板;然而,他要求圖片在展示區最好能夠實現隨著窗口的變化而自動按圖片比例等比縮放,並且居中展示圖片。我當時想著,拋開技術實現層面,圖
利用padding-top/padding-bottom百分比,進行占位和高度自適應
自身 .com gty tps 有一個 想要 很大的 after pic 在css裏面,padding-top,padding-bottom,margin-top,margin-bottom取值為百分比的時候,參照的是父元素的寬度。 比如:父元素寬度是100px, 子元素p
vue中解決佈局和表格自適應的問題
表格自適應 我們可能在使用vue框架開發中遇到需要解決元件元素自適應的問題,如何解決呢?可以使用第三方JS庫“element-resize-detector”,並定義監聽元素變化事件的回撥函式,通過該函式動態計算元素高度,然後寫入到Vue元件的樣式中。從而實現佈局上的自適應。另外,表格的
網頁自適應pc端和移動端
手機的螢幕比較小,寬度通常在600畫素以下;PC的螢幕寬度,一般都在1000畫素以上(目前主流寬度是1366×768),有的還達到了2000畫素。同樣的內容,要在大小迥異的螢幕上,都呈現出滿意的效果,並不是一件容易的事。 於是,網頁設計師不得不面對一個難題:如何才能在不同
opencv學習筆記四十九:基於距離變換和區域性自適應閾值的物件計數
案例背景:統計下圖中玉米粒的個數 方案思路:先灰度化,再二值化(基於THRESH_TRIANGLE,圖中直方圖有明顯的雙峰值),腐蝕去掉一些小雜點,距離變換,再自適應區域性閾值,膨脹連成連通域,尋找輪廓進行計數。 距離變換於1966年被學者首次提出,目前已被廣泛應
Project-3:基於堆和迴圈桶實現 djikstra 演算法
Project-3:基於堆和迴圈桶實現 djikstra 演算法 實驗原理 堆: 堆是一種經過排序的完全二叉樹,其中任一非終端節點的資料值均不大於(或不小於)其左子節點和右子節點的值。最大堆和最小堆是二叉堆的兩種形式。最大堆:根結點的鍵值是所有堆結點鍵值
全域性固定閾值化和區域性自適應閾值化
在影象處理應用中二值化操作是一個很常用的處理方式,較為常用的影象二值化方法有:1)全域性固定閾值;2)區域性自適應閾值;3)OTSU等。 全域性固定閾值化:對整幅影象都是用一個統一的閾值來進行二值化; 區域性自適應閾值化:根據畫素的鄰域塊的畫素值分佈來確定該畫素位置上的二
【記者暗訪爆料】Plustoken,首次公開技術團隊和團隊創始人!
時光荏苒,光陰似箭,2018年以極其快的速度向我們走來,向我們走去,層出不窮的各類專案,花樣百出的玩法手段,在謊言者,投資者的光怪陸離中,我們能否剝離層層表面,一探事情的真相。 區塊鏈專案有一個悖論,你永遠無法證明一個專案不會跑路,即使上了交易所,開了金山銀山的
react native 螢幕自適應 區分iOS和iPhoneX
import { Dimensions, PixelRatio, Platform } from 'react-native'; export const deviceWidth = Dimensions.get('window').width; export con
css的高階和寬度自適應問題
1.寬度自適應 現在網頁佈局基本都是要適配各個螢幕,所以佈局時候的自適應也就非常重要,這個東西說難不難,說簡單也不簡單,主要是一個積累的過程,當你寫得多了,也就掌握了。 我先從三列式佈局講吧,三列式佈局什麼呢,說白了就是兩邊固定,中間自適應,三列式佈局經典的