
【機器學習】筆記之聚類Cluster—— 層次聚類 Hierarchical clustering
什麼是層次聚類Hierarchical clustering?
平面聚類是高效且概念上簡單的,但它有許多缺點。 演算法返回平坦的非結構化簇集合,需要預先指定的簇數目作為輸入並且這個數目是不確定的。 分層聚類(或分層聚類)輸出層次結構,這種結構比平面聚類返回的非結構化聚類集更具資訊性。 分層聚類不需要我們預先指定聚類的數量,並且在IR(Information Retrieval)中使用的大多數分層演算法是確定性的。 分層聚類的這些優點以降低效率為代價。 與K-means和EM的線性複雜度相比,最常見的層次聚類演算法具有至少二次的文件數量的複雜性。
平面和層次聚類在資訊檢索中的應用差異很小。 特別是,分層聚類適用於
我們首先介紹了凝聚層次聚類(第17.1節),並在第17.2-17.4節介紹了四種不同的凝聚演算法,它們採用的不同的相似性量度:single-link, complete-link, group-average, and centroid similarity。 然後,我們將在第17.5節討論層次聚類的最優性條件。 第17.6節介紹了自上而下(divisive)的層次聚類。 第17.7節著眼於自動標記聚類,這是人類與聚類輸出互動時必須解決的問題。 我們在第17.8節討論實現問題。 第17.9節提供了進一步閱讀的指示,包括對軟分層聚類的引用,我們在本書中沒有涉及。
凝聚分層聚類(Hierarchical agglomerative clustering):
分層聚類演算法可以是自上而下的,也可以是自下而上的。 自下而上演算法在開始時將每個文件視為單個簇,然後連續地合併(或聚合)簇對,直到所有簇已合併到包含所有文件的單個簇中。 因此,自下而上的層次聚類稱為凝聚分層聚類或HAC。在介紹HAC中使用的特定相似性度量之前,我們首先介紹一種以圖形方式描述層次聚類的方法,討論HAC的一些關鍵屬性,並提出一種計算HAC的簡單演算法。
HAC聚類通常視覺化為樹狀圖(Dendrogram),如圖1所示。 每個合併由水平線表示。 水平線的y座標是合併的兩個聚類的相似度(cosine similarity: 1為完全相似,0為完全不一樣),其中文件被視為單個聚類。 我們將這種相似性稱為合併簇的組合相似性(combination similarity)
![\includegraphics[width=15cm]{rprojectsingle.eps}](https://nlp.stanford.edu/IR-book/html/htmledition/img1544.png)
通過從底層向上移動到頂層節點,樹形圖允許我們重建已經合併的簇。 例如,我們看到名為War hero Colin Powell的兩個檔案首先在Figure 1中合併,並且在最後一次合併中加入了Ag trade組成了一個包含其他29個檔案組成的簇。 HAC的一個基本假設是合併操作是單調的。 單調意味著如果是HAC的連續合併的組合相似性,則
成立。分層聚類不需要預先指定數量的聚類。 但是,在某些應用程式中,我們需要像平面聚類一樣對不相交的簇進行分割槽。 在這些情況下,需要在某個時刻削減層次結構。 可以使用許多標準來確定切割點:
- 削減預先指定的相似度。 例如,如果我們想要最小組合相似度為0.4的聚類,我們將樹形圖切割為0.4。 在圖1中,以
切割圖表產生了24個聚類(僅將具有高相似性的文件組合在一起),並將其切割為
,產生12個聚類(一個大型財經新聞聚類和11個較小聚類)。
- 如果兩個連續的組合相似性之間的差距最大,那麼就在此處切割樹。 如此大的差距可以說是“自然的”聚類。 再新增一個簇會顯著降低聚類的質量,因此需要在發生這種急劇下降之前進行切割。 This strategy is analogous to looking for the knee in the
 -means graph in Figure 16.8 (page 16.8 ).
-means graph in Figure 16.8 (page 16.8 ). - 應用公式:
其中指的是導致
個簇的層次結構的削減,RSS是剩餘的平方和(residual sum of squares),
是每個額外簇的懲罰。 可以使用另一種失真度量來代替RSS。
-
與平面聚類一樣,我們也可以預先指定聚類的數量並選擇產生聚類的切割點。
一個簡單的HAC演算法如Figure 2所示。 我們首先計算相似度矩陣
。然後該演算法執行
步(e.g.10個樣本需要N-1=9次來最終將所有樣本cluster到一起)來合併當前最相似的簇。 在每次迭代中,合併兩個最相似的簇(比如
和
),將這個簇與其他簇從新計算相似度並更新到相似度矩陣
中
的行和列。這樣做的目的是利用
來表示新合併好的簇。然後將
deactivated,這樣做在以後的迭代中,
便用來代表包含
的簇,而
將不再被考慮(
已經被聚類)。合併形成的簇以列表的形式儲存在
中。
表示哪些群集仍然可以合併(如前文所說的
,若
沒有被聚類則
否則
)。 函式
計算簇
與簇
和
合併的相似性。 對於某些HAC演算法,
只是和
的函式,例如,這兩者中的single-link的值。

相似性度量:Single-link and complete-link clustering:
Single-link clustering: 在single-link clustering中,兩個聚類的相似性是其最相似成員的相似性。 Single-link合併標準是本地的。 也就是說,我們只關注兩個簇彼此最接近的區域, 其他更遠的簇的整體結構不予考慮。參考Figure 2(a)。
Complete-link clustering: 在Complete-link中,兩個聚類的相似性是它們最不相似的成員的相似性。 這相當於選擇合併具有最小直徑的簇對。 Complete-link合併標準是非本地的; 簇的整個結構可以影響合併決策。 這導致Complete-link傾向於在長的,散亂的簇上選擇具有小直徑的緊密簇,但也導致對異常值的敏感性。 遠離中心的單個文件可以顯著增加候選合併叢集的直徑,並完全改變最終的叢集。參考Figure 2(b)。

Figure 17.2描繪了八個文件的Single-link and Complete-link clustering。 前四個步驟,每個步驟產生一個由兩個文件組成的簇,兩種方法的結果是相同的。 然後Single-link clustering連線上面的兩對,之後是下面的兩對,因為在聚類相似性的最大相似性定義上,這兩個聚類最接近。 Complete-link clustering連線左兩對(然後是右兩對),因為根據聚類相似性的最小相似性定義,它們是最接近的對。
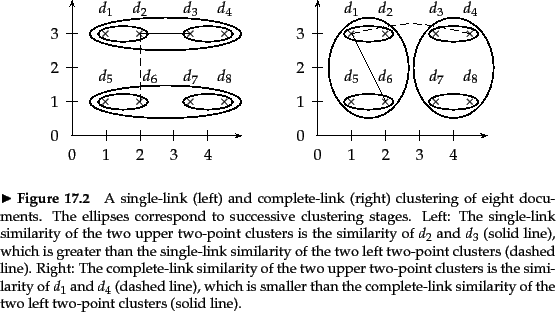
Figure 1是一組文件的Single-link cluster的示例,Figure 3是同一組檔案的Complete-link cluster。當切割Figure 3中的最後一個合併時,我們獲得兩個相似大小的簇。 Figure 1中的樹狀圖沒有這樣的切割可以為我們提供同樣平衡的聚類。
![\includegraphics[width=13.5cm]{rprojectcomplete.eps}](https://nlp.stanford.edu/IR-book/html/htmledition/img1562.png)
Single-link and Complete-link clustering都具有圖形理論解釋。將定義為合併步驟
中的兩個簇的組合相似度,將
定義為已經根據相似度大於
的相似度合併好的樹(我的理解:將
定義為截止到第
步所合併形成的樹圖)。 在完成了
次聚類以後,通過Single-link clustering形成的樹包含了很多connected components,而通過Complete-link形成的樹則包含了很多cliques。
Connected components:A maximal set of connected points such that there is a path connecting each pair.
Clique: A clique is a set of points that are completely linked with each other.
到這為止,我們要清楚:Single-link clustering在每一次聚類時,只要當前即將要合併的兩個簇中保證有一個樣本樣本對的相似度最大即可。而在Complete-link clustering中,即將要合併的兩個簇必須要保證所有樣本對的相似度都很小(根據兩個簇最不相似的樣本對相似最大,那麼這兩個簇中任意的兩個樣本對的相似度必都大於最不相似樣本對相似度)。就好比是一個朋友圈,這個圈子裡只要有一個人喜歡你,就把你加進來——Single-link cluster;所有人都喜歡你才能把你加進來——Complete-link clustering。
鏈式效應在Figure 1中也很明顯。 Single-link clustering的最後十一個合併(超過行的那些)新增單個文件或文件對,可看作是鏈式效應。 Figure 3中的Complete-link clustering避免了這個問題。 當我們在最後一次合併時剪下樹形圖時,文件被分成兩組大小相等的大小。 通常,我們更想得到一個平均的叢集而不是鏈式的叢集。
但是,Complete-link clustering會遇到不同的問題。 它過分關注異常值,這些點不適合叢集的全域性結構。 在Figure 4的示例中,四個文件由於左邊緣的異常值
而被拆分。 在此示例中,Complete-link clustering未找到最直觀的群集結構。