
王小草【機器學習】筆記--無監督演算法之聚類
標籤(空格分隔): 王小草機器學習筆記
1. 聚類的概述
存在大量未標註的資料集,即只有特徵,沒有標籤的資料。
根據這些特徵資料計算樣本點之間的相似性。
根據相似性將資料劃分到多個類別中。
使得,同一個類別內的資料相似度大,類別之間的資料相似度小。
2. 相似性的度量方法
2.1 歐式距離
歐氏距離指的是在任何維度的空間內,兩點之間的直線距離。距離越大,相似度越小,距離越小,相似度越大。公式如下:
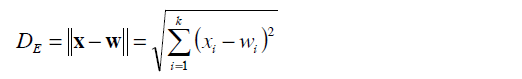
2.2 曼哈頓距離
曼哈頓距離(Manhattan DistanceCity)也叫街區距離(Block Distance)。兩點之間的距離是直角三角形的兩條邊長和。

國外一般是分一個一個街區的,要想從街區的一角走到另一角,不能直接穿過,必須沿著街區兩邊的道路走。
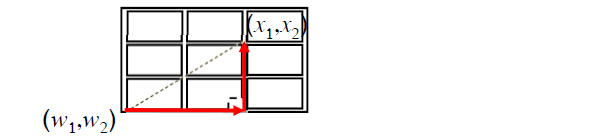
所以上圖中兩點的曼哈頓距離是:
|x1-w1|+|x2-w2|
2.3 漢明距離Hamming Distance
假設有兩組資料分別是兩個使用者在淘寶上買過的東西,如下圖,假設1-17是17件商品,如果買了就在該使用者下標記為1,沒買的標記為0.根據這兩組資料比較AB兩個使用者在購物行為上的相似性。
漢明距離的做法是,如果AB都沒有買或都買了,表示他們行為一致,距離為0,相似度高;如果他們的行為不同,那麼在該商品種類下距離為1,最後將17件商品對應的距離相加(也就是把1相加),求和的結果就是漢明距離

2.4 皮而遜相關係數
Pearson相關係數是用來衡量兩個資料集合是否在一條線上面。
Pearsion相關係數的範圍是[-1,1],如果完全正相關則為1,完全負相關則為-1,完全不先關則為0.

pearsion相關係數在迴歸中應用普遍,比如在建立迴歸模型之前,需要先計算各個自變數與應變數之間的相關度,如果相關度小,則應該講該自變數從模型中去掉。另外,也有必要計算自變數之間的兩兩相關性,如果自變數之間存在相關性大的變數,那麼非常有必要將其中一個剔除或者使用主成分分析PCA進行特徵降維,因為線性迴歸的假設之一是自變數都是互相獨立的,如果有自變數先關則會導致共線性,影響模型的質量與預測的準確度。
2.5 餘弦相似度
通過計算兩個向量的夾角餘弦值來評估他們的相似度。因為我們認為夾角如果越大則相距越遠,夾角小則距離近,餘弦值越接近1。
計算餘弦角的公式:

假設向量a、b的座標分別為(x1,y1)、(x2,y2)則餘弦相似度為:
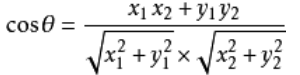
設向量 A = (A1,A2,…,An),B = (B1,B2,…,Bn) 。推廣到多維:
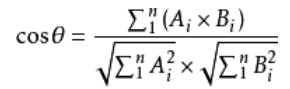
皮爾遜先關係數與預先相似度的關係:
相關係數即將x,y座標向量各自平移到原點後的夾角餘弦。
這即解釋了為何文件間求距離使用夾角餘弦,因為這一物理量表徵了文件去均值化後的隨機向量間的相關係數。
文件的去均值就是將計算文件的tf-idf值。
然後再將tf-idf來做餘弦相似性。
2.6 傑卡德相似係數
Jaccard similarity coefficient
兩個集合A和B交集元素的個數在A、B並集中所佔的比例,稱為這兩個集合的傑卡德係數,用符號 J(A,B) 表示。傑卡德相似係數是衡量兩個集合相似度的一種指標。
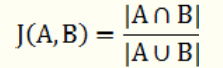
假設樣本A和樣本B是兩個n維向量,而且所有維度的取值都是0或1。例如,A(0,1,1,0)和B(1,0,1,1)。我們將樣本看成一個集合,1表示集合包含該元素,0表示集合不包含該元素。
p:樣本A與B都是1的維度的個數
q:樣本A是1而B是0的維度的個數
r:樣本A是0而B是1的維度的個數
s:樣本A與B都是0的維度的個數
那麼樣本A與B的傑卡德相似係數可以表示為:
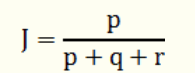
此處分母之所以不加s的原因在於:
對於傑卡德相似係數或傑卡德距離來說,它處理的都是非對稱二元變數。非對稱的意思是指狀態的兩個輸出不是同等重要的,例如,疾病檢查的陽性和陰性結果。
按照慣例,我們將比較重要的輸出結果,通常也是出現機率較小的結果編碼為1(例如HIV陽性),而將另一種結果編碼為0(例如HIV陰性)。給定兩個非對稱二元變數,兩個都取1的情況(正匹配)認為比兩個都取0的情況(負匹配)更有意義。負匹配的數量s認為是不重要的,因此在計算時忽略。
傑卡德相似度演算法沒有考慮向量中潛在數值的大小,而是簡單的處理為0和1,不過,做了這樣的處理之後,傑卡德方法的計算效率肯定是比較高的,畢竟只需要做集合操作。
2.7 相對熵
相對熵也叫K-L距離,計算公式如下:
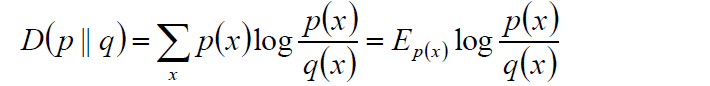
2.8 Hellinger距離
計算過程如下:
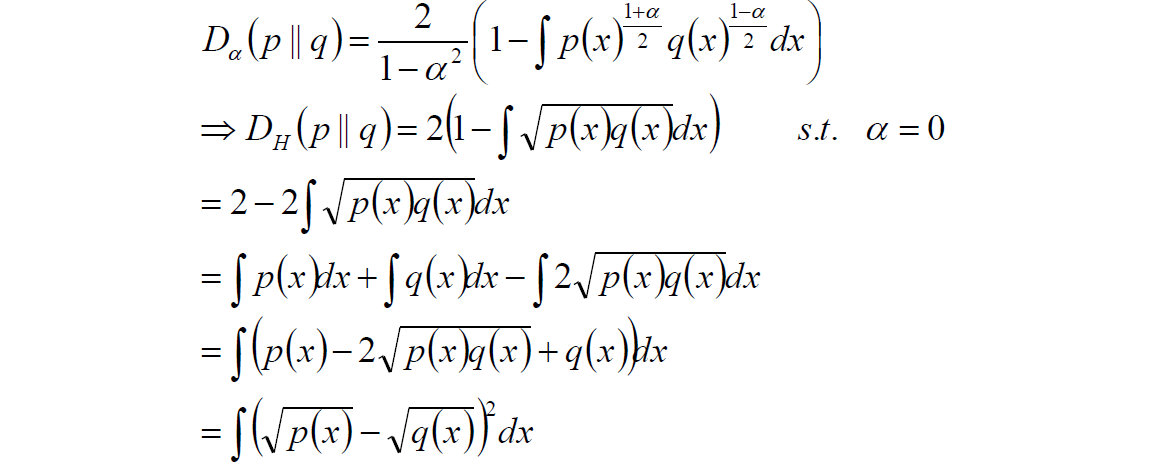
該距離滿足三角不等式,是對稱,非負距離
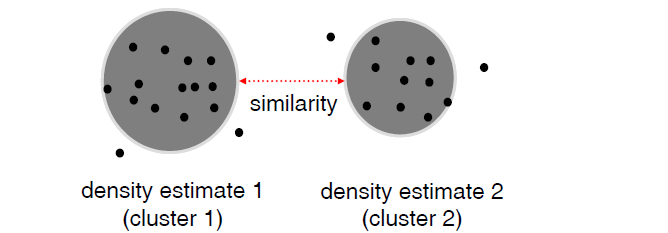
2.9 基於密度的相似性
Density-based methods define similarity as the distance
between derived density “bubbles” (hyper-spheres).
3. K-means聚類的過程與步驟
給定一個有N個物件的資料集,構造資料的K各簇。k<=n。滿足下列條件:
1.每個簇至少包含一個物件
2.每個物件屬於且僅屬於一個簇
3.將滿足上述條件的K個簇稱作一個合理的劃分。
基本思想:
對於給定的類別數目k,首先給出初始的劃分,通過迭代改變樣本和簇的隸屬關係,使得每一次改進之後的劃分方案都較前一次好。
3.1 k-means演算法基本步驟
The three-step k-means methodology is given
1.確定輸入樣本
假定輸入樣本為S=x1, x2, x3,…,xm
2.選擇初始的k個類別中心,μ1, μ2, μ3,…,μk
3.對每個樣本xi,都與各個類別中心求相似性,然後將它標記為與它相似度最高的那個類別中心所在的類別。即:

4.在新的類別中選出一個新的類別中心(該類中所有樣本的均值)
5.不斷重複3,4煉骨,直到類別中心的變化小於某個閥值或者滿足終止條件為止。完成聚類過程。
如下圖,就是聚類的整個過程:
3.2 對K-means的思考
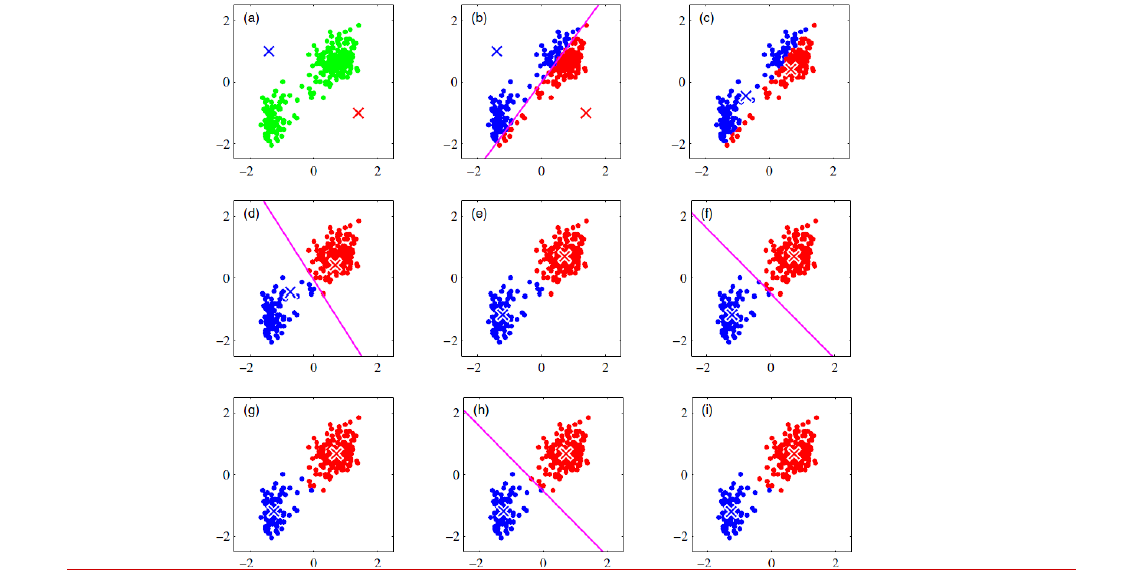
如何選擇初始均值?
初始均值可以隨機選擇。但是萬一選擇不好,也可能影響之後的所有結果。
比如下圖,要對左圖分成4個類,非常明顯的4個分佈點。但是如果初始的均值選成了右圖那樣,最後聚類的結果完全不是我們想要的結果
所以初始均值是敏感的。
那麼如何選擇初始均值呢?
假設k=4
首先隨機選擇一個點作為第一個初始中心。
然後求其他所有樣本點到這個中心的距離,用距離作為概率的權重,再隨機得在樣本中去選擇第二中心點。
接著對剩下的樣本再對現有的2箇中心點求距離取出最短距離,以這個距離作為概率的權重,再隨機選擇第三個中心點。
同理,選出第4箇中心點。
於是,4個初始的中心點都選好了。可以繼續去做正常的聚類了。
這個過程我們叫K+means++
中心一定要用均值選嗎?
比如說1,2,3,4,100的均值是22,但很顯然22來當聚類中心有點牽強,因為它離大多數的點都比較遠,100可能是一個噪聲。所以選擇 中位數3更為妥當。
這種聚類方法叫做k-Mediods聚類(k-中值距離)
在實際應用中具體問題具體分析。
關於終止條件的指標可以是?
迭代次數/簇中心變化率/最小平方誤差MSE
關於如何選擇k?
• Subject-matter knowledge (There
are most likely five groups.)
• Convenience (It is convenient to
market to three to four groups.)
• Constraints (You have six products
and need six segments.)
• Arbitrarily (Always pick 20.)
• Based on the data (Ward’s method)
3.3 K-means的公式解釋
記K個簇中心為μ1,μ2,μ3…,μk,
每個簇數目為N1,N2,..Nk
使用平方誤差作為目標函式:

對每個簇中,求每個樣本到中心的距離的平方求和,然後將每個簇的誤差相加。
該函式是關於μ1,μ2,μ3…,μk的凸函式,其駐點為:

所以是對目標函式的梯度下降。
如果對所有樣本求梯度下降就是BGD
隨機得對若干個樣本做梯度下降就是隨機下降法SGD.
將以上兩者結合就是Mini-batch K-means演算法。
根據上述目標函式,另外一個更深入的重點
其實對每一個簇,有一個前提假設:所有樣本服從高斯分佈。
如果將目標函式中的(xi-μi)^2換成絕對值|xi-μi|,那就是上面提到過的k-Mediods聚類
3.4K-means聚類方法的總結
優點
1.解決聚類問題的一種經典演算法,簡單,快速
2.對處理大資料集,該演算法保持可伸縮性和高效率
3.當簇近似為高斯分佈,它的效果是較好的
缺點:
1.在簇的平均值可被定義的情況下才能使用,可能不適用於某些應用
2.必須事先給出k,而且對初值敏感,對於不同的初始值,可能會導致不同的結果。
3.不適用於發現非凸形狀的簇或者大小差別很大的簇
4.對噪聲和孤立點資料敏感
k-means聚類演算法可作為其他聚類演算法的基礎演算法,如譜聚類。
4.其他聚類演算法
4.1 Canopy演算法
雖然Canopy演算法可以劃歸為聚類演算法,但更多的可以使用它做空間索引,其時空複雜度都很出色,演算法描述如下:
對於給定樣本x1,x2…,xm;給定先驗值r1,r2(r1< r2)
x1,x2…,xm形成一個列表L;同時構造一個空列表C。
隨機選擇L中的樣本c,計算了Lz中樣本xj與c的距離dj
若dj
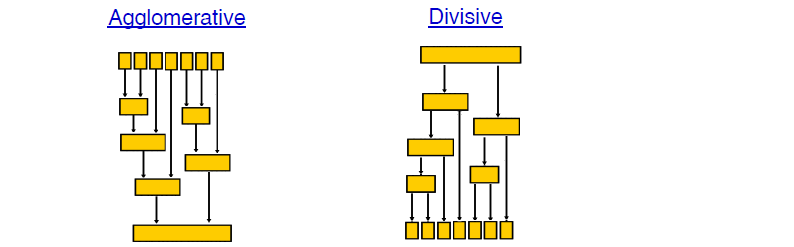
4.2 層次聚類方法
層次聚類方法對給定的資料集進行層次分解,直到某種條件滿足為止。具體可以分為兩類:
凝聚的層次聚類AGNES
一種自底向上的策略,首先將每個物件作為一個簇,然後合併這些原子簇為越來越大的簇,直到某個終結條件被滿足。
分裂的層次聚類DIANA
採用自頂向下的策略,它首先將所有物件置於一個簇中,然後逐漸細分為越來越小的簇,直到到達了某個終結條件。
4.3 密度聚類法
密度聚類的指導思想是,只要樣本點的密度大於某閥值,則將該樣本新增到最近的簇中。
基於距離的聚類只能發現“類圓形”的聚類(即高斯分佈的假設),而密度聚類可以發現任意形狀,並且對噪聲資料不敏感。
但是計算密度單元的計算複雜度大,需要建立空間索引來降低計算量。
這裡主要介紹兩種密度聚類方法:DBSCAN和密度最大值法
4.3.1DBSCAN演算法
全稱:Densiti-Based Spatial Clustering of Applications with Noise
DBSCAN的若干概念:
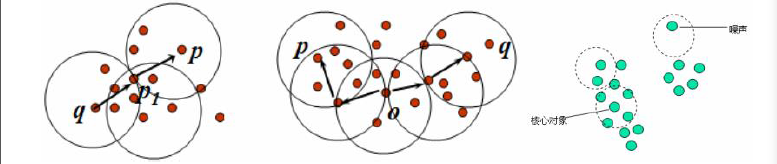
物件的ε-鄰域:給定物件在半徑ε內的區域。
核心物件:對於給定的數目m,如果一個物件的ε-鄰域至少包含m個物件,則稱該物件為核心物件。
直接密度可達:給定一個物件集合D,如果p是在q的ε鄰域內,而q是一個核心物件,我們說物件p從物件q出發是直接密度可達的。
密度可達:如果p直接密度可達p1,p1直接密度可達q,則說q是從物件p關於ε和m的密度可達。
密度相連:如果物件o與p,o與q都是密度可達,則說p和q室密度相連。
簇:一個基於密度的簇是最大的密度相連物件的集合。
噪聲:不包含在任何簇中的物件稱為噪聲。
DBSCAN演算法流程:
1.如果一個點p的ε-鄰域包含多於m個物件,則建立一個p作為核心物件的新簇;
2.尋找併合並核心物件直接密度可達的物件;
3.沒有新點可以更新簇時,演算法結束
由上述演算法可知:
每個簇至少包含一個核心物件;
非核心物件可以是簇的一部分,構成了簇的邊緣。
包含過少物件的簇被認為是噪聲
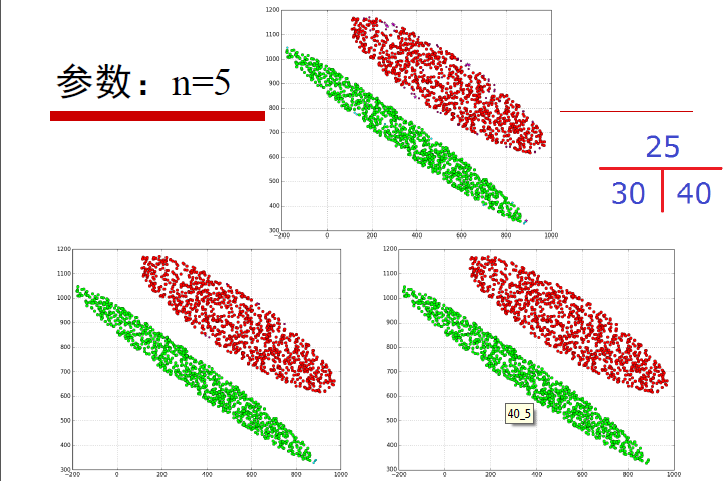
例子:
以下分別是m為5,ε=25,30,40的時候的聚類
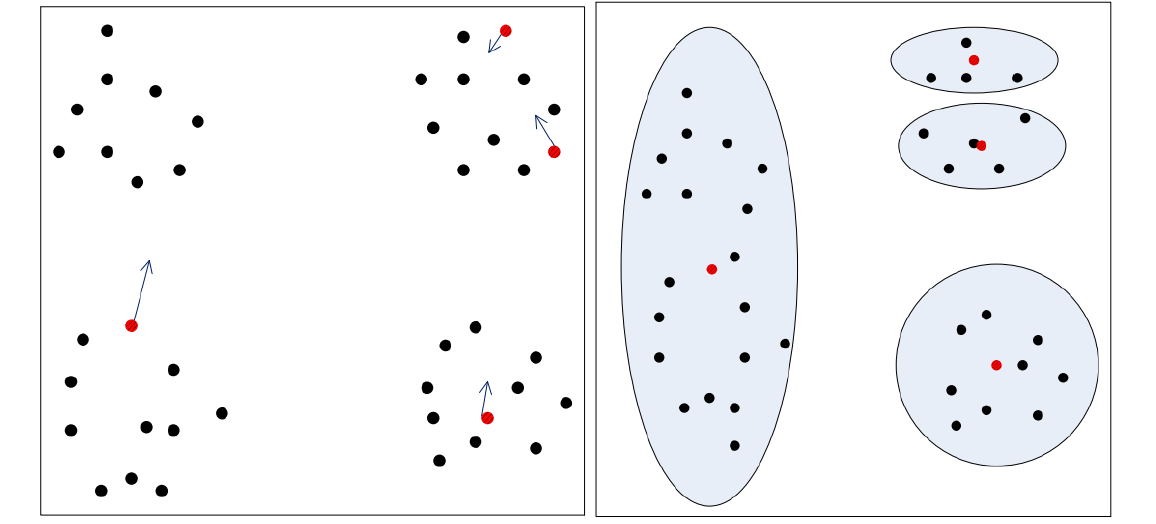
4.3.2密度最大值聚類
密度最大值聚類是一種簡潔優美的聚類演算法,可以識別各種形狀的類簇,並且引數很容易確定。
給定一個r值,對每個樣本點xi,求出其以r為半徑的圓內包含了多少個樣本點,樣本點的個數記為ρi,表示以xi的密度。於是我們可以求出ρ1,ρ2…ρm。
再對每個樣本點,比如現在以x1為例。找出一堆離它距離比較近的點,比如x2,x4,x6,x7.
這4個點分別有自己的密度ρ2=6,ρ4=8,ρ6=4,ρ7=7.
假設ρ1=5,分別把ρ1與以上四個ρ值作比較,留下密度比自己大的樣本點,所以剩下的是ρ2=6,ρ4=8,ρ7=7。
然後再求出x1分別到以上三個點的距離,分別是d2,d4,d7,選出距離最小的那個值,比如是d4,這個最小的距離我們記做δ1,即高區域性密度點距離。
現在我們為x1求出了兩個值:(ρ1,δ1)。
以此類推,所有的樣本點xi都可以求出(ρi,δi)
想想,如果一個點的ρ和δ都很大,那麼說明這個點的密度很大,並且密度比它大且離它最近的那個樣本點距離它也比較遠。也就說它們兩可以自成一個類,彼此密度都很大,且距離也比較遠。
如果一個點的ρ很小δ卻很大,則說明它的密度很小,且離其他的大密度點也比較遠,說明它是一個噪聲!
簇中心的識別:那些有著比較大的區域性密度ρi和很大的高密度距離的點被認為是簇的中心。
確定簇中心之後,其他點按照距離已知中心簇的中心最近進行分類。
(也可以按照密度可達方法進行分類)
舉個例子:
左圖是所有樣本點在二維空間的分佈,右圖是以ρ為橫座標,以δ為縱座標繪製的決策圖。可以看到,1和10兩個點的ρδ都比較大,作為簇中心、而26.27.28三個點的δ也比較大,但是ρ比較小,所以是噪聲。

5.譜聚類
5.1 譜聚類的過程
(據說譜聚類是使用起來比較簡單但是解釋起來比較困難的。。。)
假設我們有m個樣本(a1,a2,…,am),每個樣本的特徵維度是n維。
現在將每個樣本(ai,aj)根據特徵兩兩求相似性wij。於是就有了m*m維的相似性矩陣W。
因為(ai,aj)的相似性 = (aj,ai)的相似性,所以這個相似性矩陣W是一個對稱矩陣。
相似性矩陣W的的每一行都是ai與a1,a2,..am的相似性,將每行的值求和,每個樣本點ai都會得到一個值di.
將di(d1,d2,…,dn)放在n*n矩陣的對角線上,形成了一個n*n的對角矩陣D。
好了現在我們有兩個矩陣:對角矩陣D,與對稱矩陣W
定義一個L矩陣:L=D-W
這個L的來頭非常大,它就是拉普拉斯矩陣。
對這個L矩陣提取特徵值與特徵向量。
特徵值:λ1,λ2,…,λm
特徵向量:u1,u2,…,um
可以證明L是一個半正定矩陣,所以最小特徵值肯定是0.(為什麼是半正定,為什麼半正定就有特徵值0呢?這個不放在這裡細講先)
將所有特徵值由小到大排列,取出最小的前k個特徵值。將這些特徵值對應的特徵矩陣組合在一起。
因為一個特徵矩陣ui是m*1維度。所有k個特徵矩陣組合在一起就形成了m*k維度的大矩陣U。
U的行數是m,對應的是m個樣本,列數為k,對應的是k個指標。
這k個指標可以看成是k個特徵。
於是我們有了針對m個樣本的k維特徵的這樣一組資料。直接將這組資料用於做k-means聚類即可。(其實就是將原來的特徵用轉換後的新的特徵代替了)。
以上就是譜聚類的具體過程。
對了還要說一下相似度的計算,也就是W矩陣是咋滴來的。
有這樣幾個方法,一般都是用高斯相似性:
距離越大,相似度越小
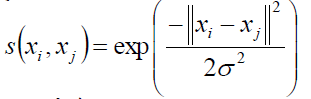
關於高斯相似性的東東在“王小草【機器學習】筆記–支援向量機”一文的核函式處有解釋。
6.聚類的衡量指標
6.1 在有標記的樣本資料下
6.1.1 準確性Cluster Accuracy(CA)
CA計算 聚類正確的百分比;CA越大證明聚類效果越好.
其計算公式為:
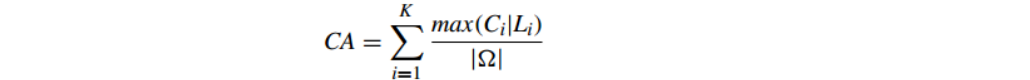
CA也叫purity。
purity方法的優勢是方便計算,值在0~1之間,完全錯誤的聚類方法值為0,完全正確的方法值為1。同時,purity方法的缺點也很明顯它無法對退化的聚類方法給出正確的評價,設想如果聚類演算法把每篇文件單獨聚成一類,那麼演算法認為所有文件都被正確分類,那麼purity值為1!而這顯然不是想要的結果。
6.1.2 RI
RI的公式表示為:
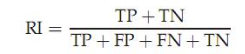
其中TP是指應該被聚在一類的兩個樣本被正確分類了,TN是隻不應該被聚在一類的兩個文件被正確分開了,FP是不應該放在一類的文件被錯誤的放在了一類,FN只不應該分開的文件被錯誤的分開了。
6.1.3 F-meature
這是基於上述RI方法衍生出的一個方法,

6.1.4 均一性Homogeneity
均一性是指一個簇只能包含一個類別的樣本,即只對一個簇中的樣本做考慮,至於這個類別是否還被歸到了其他的簇中,它不管。
均一性可以通過以下公式求得:
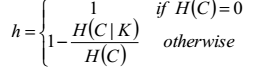
假設我們是已經知道這批聚類資料的真實類別的,聚類之後,在同一個簇中的類別,如果只有一個,那麼這個簇的經驗為0jj,均一性為1, 如果有大於1個類別,那麼計算該類別下的簇的條件經驗熵,如果條件經驗熵越大,則均一性就越小。
均一性在0-1之間。
6.1.5 完整性Completeness
完整性是指同類別樣本被歸類到相同的簇中,至於這個簇中還有沒有其他類別的樣本,它不管。
完整性的計算公式如下:
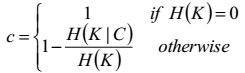
假設我們是已經知道這批聚類資料的真實類別的,聚類之後,如果同一個類的樣本的確被全部分在了同一個簇中,那麼這個類的經驗熵就是0,完整性就是1,;反之,如果同一類的樣本被分到了不同的簇中,H(K|C)的條件經驗熵就會增大,從而完整性就降低了。
完整性在0-1之間。
6.1.6 V-meature
單一地考慮均一性與完整性兩個指標都是片面的。
通過以下公式我們將均一性與完整性的加權平均:
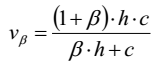
其實V-measure與F-measure是一樣的,前者用的是經驗熵,後者用的是頻率。
6.1.7 ARI
Adjusted Rand index(調整蘭德指數)(ARI)
假設資料集S共有N個元素,我們對N個元素去做聚類。
用不同的聚類方法得到兩個不同的聚類結果:
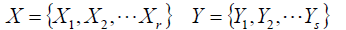
Xi,Yi分別為各自的簇。
(當然,如果事先知道樣本的標籤就更好,其中一個結果就是真實的結果,另一個是聚類得到的結果)
ai,bi分別為對應簇中的元素個數:
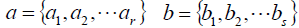
nij表示Xi和Yi兩個簇中相同的元素的個數:
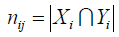
將以上關係表示成如下表格:
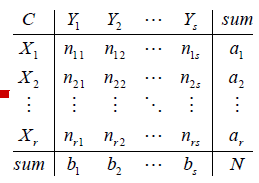
那麼我們最終要求的ARI指數的計算公式為:

ARI取值範圍為[−1,1],值越大意味著聚類結果與真實情況越吻合。從廣義的角度來講,ARI衡量的是兩個資料分佈的吻合程度。
其實ARI是由AR轉變優化而來的,可將以上公式簡寫為:
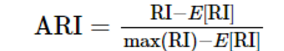
6.1.8 AMI
AMI使用與ARI相同的幾號,但是用的是資訊熵。
互資訊為:
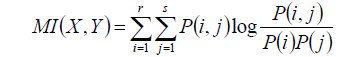
正則化的互資訊為
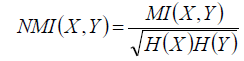
X服從超幾何分佈,則互資訊的期望是:

借鑑ARI,則AMI為:
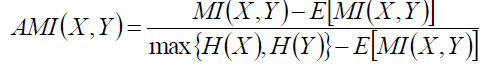
6.2 在沒有標記樣本的情況下
6.2.1 Compactness(緊密性)(CP)
公式如下:
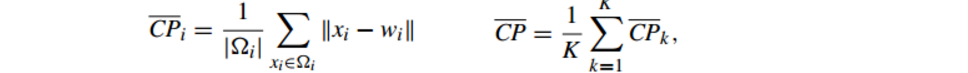
CP計算 每一個類 各點到聚類中心的平均距離
CP越低意味著類內聚類距離越近
缺點:沒有考慮類間效果
6.2.2 Separation(間隔性)(SP)
公式如下:
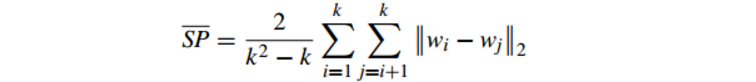
SP計算 各聚類中心兩兩之間平均距離
SP越高意味類間聚類距離越遠
缺點:沒有考慮類內效果
6.2.3 Davies-Bouldin Index(戴維森堡丁指數)(分類適確性指標)(DB)(DBI)
公式如下:
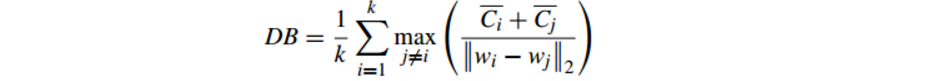
DB計算 任意兩類別的類內距離平均距離(CP)之和除以兩聚類中心距離 求最大值
DB越小意味著類內距離越小 同時類間距離越大
缺點:因使用歐式距離 所以對於環狀分佈 聚類評測很差
6.2.4 Dunn Validity Index (鄧恩指數)(DVI)
公式如下:
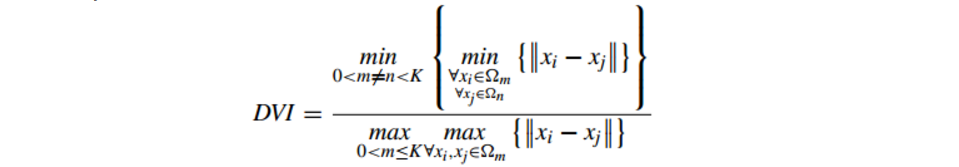
DVI計算 任意兩個簇元素的最短距離(類間)除以任意簇中的最大距離(類內)
DVI越大意味著類間距離越大 同時類內距離越小
缺點:對離散點的聚類測評很高、對環狀分佈測評效果差
6.2.5 輪廓係數Silhouette
與以上評價指標不同,輪廓係數是不需要標記樣本的。因為聚類本身是無監督的,要尋找有標記的樣本比較困難。
樣本i到同簇其他樣本的平均距離為ai;
樣本i到最近的其他簇的所有樣本的平均距離為bi;
於是輪廓係數的計算公式為:
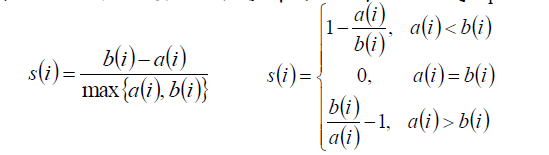
所有樣本輪廓係數的平均值稱為聚類結果的輪廓係數。
輪廓係數越接近於1則聚類效果越好!