
oracle中的索引----重要
通俗的來講,索引在表中的作用,相當於書的目錄對書的作用。
—-前言
一、索引的優點
- 索引是與表相關的一個可選結構
一個表中可以存在索引,也可以不存在索引,不做硬性要求。 - 用以提高 SQL 語句執行的效能
快速定位我們需要查詢的表的內容(物理位置),提高sql語句的執行效能。 - 減少磁碟I/O
取資料從磁碟上取到資料緩衝區中,再交給使用者。磁碟IO非常不利於表的查詢速度(效率的提高)。 - 使用 CREATE INDEX 語句建立索引
- 在邏輯上和物理上都獨立於表的資料
索引與表完全獨立,表裡的內容是我們真正感興趣的內容,而索引則是做了一些編制 ,索引和資料可以存放在不同的表空間下面,可以存放在不同的磁碟下面。
Oracle 自動維護索引
當對一個建立索引的表的資料進行增刪改的操作時,oracle會自動維護索引,使得其仍然能夠更好的工作。
二、索引的型別與結構
1、索引型別
從總的概念上來說,索引分為B樹索引(也叫平衡樹索引,即就是什麼都不寫,最常用)和點陣圖索引(多用於資料倉庫)。這兩種索引在邏輯結構(儲存)上完全不同。
B樹索引
其中B樹索引 又可以具體分為:
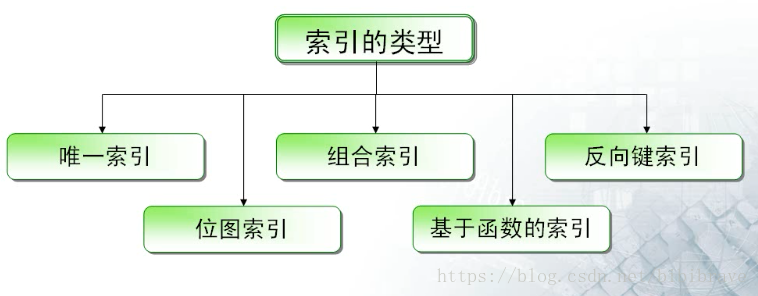
(1)唯一索引:
唯一索引確保在定義索引的列中沒有重複值
Oracle 自動在表的主鍵列上建立唯一索引
使用CREATE UNIQUE INDEX語句建立唯一索引
- 語法:create unique index index_name on table_name (column_name);
具體列值: 索引相關列上的值必須唯一,但可以不限制NULL值。
(2)組合索引:
組合索引是在表的多個列上建立的索引
索引中列的順序是任意的
如果 SQL 語句的 WHERE 子句中引用了組合索引的所有列或大多數列,則可以提高檢索速度
- 語法:create index index_name on table_name (column_name1,column_name2);
具體列值:該表中的元組由兩列共同確定一行,例如班級號 學號 唯一確定一個學生。
(3)反向鍵索引:
反向鍵索引反轉索引列鍵值的每個位元組,為了實現索引的均勻分配,避免b樹不平衡
通常建立在值是連續增長的列上,使資料均勻地分佈在整個索引上
建立索引時使用REVERSE關鍵字
- 語法:create index index_name on table_name (column_name) reverse;
具體列值: 適用於某列值前面相同,後幾位不同的情況,例如
sno: 1001 1002 1003 1004 1005 1006 1007
索引轉化:1001 2001 3001 4001 5001 6001 7001
(4)點陣圖索引:
點陣圖索引適合建立在低基數列上
點陣圖索引不直接儲存ROWID,而是儲存位元組位到ROWID的對映
節省空間佔用
如果索引列被經常更新的話,不適合建立點陣圖索引
總體來說,點陣圖索引適合於資料倉庫中,不適合OLTP中
- 語法:create bitmap index index_name on table_name (column_name);
具體列值: 不適用於經常更新的列,適用於條目多但取值類別少的列,例如性別列。
(5)基於函式的索引:
基於一個或多個列上的函式或表示式建立的索引
表示式中不能出現聚合函式
不能在LOB型別的列上建立
建立時必須具有 QUERY REWRITE 許可權
- 語法:create index index_name on table_name (函式(column_name));
具體列值: 不能在LOB型別的列上建立,使用者在該列上對該函式有經常性的要求。
- 例如:使用者不知道儲存時候姓名是大寫還是小寫,使用
select * from student where upper(sname)=’TOM’;
- 例如:使用者不知道儲存時候姓名是大寫還是小寫,使用
2、索引結構
索引的結構是一個倒立的樹狀結構,其中每個節點的左子樹比他的右子樹小,索引最終指向表裡面的資料與表裡面的資料對應。

如上圖,前三行是索引的內部構造,第三行與最後一行,這是索引指向表裡資料的一個指向。索引是建立在列上的。最後一行是索引建立在表中某列上的值。
- 根節點塊 :如果索引列的值>0時,指向B1這個分支節點塊,如果索引列的值>500時,指向B2這個分支節點塊,如果索引列的值>1000時,指向B3這個分支節點塊。
- 分支節點塊:對於B1來說,再進行細分 如果索引列的值>0且<200時,指向L1這個分支節點塊,如果索引列的值>200且<400時,指向L2這個分支節點塊,如果索引列的值>400且<500時,指向L3這個分支節點塊。
- 葉子節點塊: 對於L1來說,如果資料行的值為0,那就放在R1這個資料行中,如果資料行的值為29,那就放在R2這個資料行中,如果資料行的值為190,那就放在R3這個資料行中,等。
三、索引的建立。
1— 建立一張表:
create table student(sno number ,
sname varchar2(10),sage int,
male char(3)); --一個漢字佔三個字元
insert into student values(1,'TOM',21,'男');
insert into student values(2,'kite',22,'男');
insert into student values(3,'john',23,'女');2— 建立該表上的索引:
create index ind1 from student(sno); 3– 查詢索引相關資訊:
-- 索引的全部資訊 select * from user_indexes;
--查詢索引涉及到的列 select * from user_ind_columns u where u.index_name='IND1’;
四、索引的變動,查詢索引碎片
由於我們在對錶的使用過程中,必然引發增刪查改等操作,當表中的資料不存在,但其索引仍然存在,極大的影響了查詢速度,降低了索引的利用率。
我們可以通過 檢視index_stats表中的pct_used列的值,如果pct_used的值過低,說明在索引中存在碎片,可以重建索引,來提高pct_used的值,減少索引中的碎片。
對索引碎片的查詢,在該語句前後都要使用分析索引語句,已使得索引利用率發生改變。
分析:
alter index index_name validate structure;
查詢碎片:
select name,pct_used from index_stats where name='index_name';
當表中資料發生變化時,我們可以通過兩種方式來對索引進行更新,一是通過刪除該索引,再建立新的索引來提高索引的利用率。二是通過重建索引來提高索引利用率。
①刪除索引 : drop index index_name (同時也證明表和索引之間相互獨立)
create index index_name on 表名(列名) tablespace tname;
②重建索引: alter index index_name rebuild REBUILD [ONLINE] [NOLOGGING] [COMPUTE STATISTICS];
其中:
- ONLINE使得在重建索引過程中,使用者可用對原來
的索引進行修改,也就是其他的使用者同時可以對錶進行增刪改操作; - NOLOGGING表示在重建過程中產生最少的重做條目redo Entry,加快重建的速度;
- COMPUTE STATISTICS表示在重建過程中就生成了oracle優化器所需的統計資訊,避免了索引重建之後再進行analyze或dbms_stats來收集統計資訊。
五、索引分割槽:
可以將索引儲存在不同的分割槽中
與分割槽有關的索引有三種類型:
- 區域性分割槽索引 - 在分割槽表上建立的索引,在每個表分割槽上建立獨立的索引,索引的分割槽範圍與表一致 (按照表分割槽對索引進行分割槽)
create index ind1 on stu(sno) local ;- 全域性分割槽索引 - 在分割槽表或非分割槽表上建立的索引,索引單獨指定分割槽的範圍,與表的分割槽範圍或是否分割槽無關
*create index ind1 on stu(sno) global ;
partition by range(列名)
(partition 索引分割槽名1 values less than(條件1),
partition 索引分割槽名2 values less than(條件2),
partition 索引分割槽名3 values less than(條件3),
); - 全域性非分割槽索引 - 在分割槽表上建立的全域性普通索引,索引沒有被分割槽
create index ind1 on stu(sno) global ;