
總結:Hive效能優化上的一些總結
Hive效能優化上的一些總結
注意,本文百分之九十來源於此文:Hive效能優化,很感謝作者的細心整理,其中有些部分我做了補充和追加,要是有什麼寫的不對的地方,請留言賜教,謝謝
前言
今天電話面試突然被涉及到hive上有沒有做過什麼優化,當時剛睡醒,迷迷糊糊的沒把以前實習的中遇到的一些問題闡述清楚,這裡順便轉載一篇並來做一下總結
介紹
首先,我們來看看Hadoop的計算框架特性,在此特性下會衍生哪些問題?
- 資料量大不是問題,資料傾斜是個問題。
- jobs數比較多的作業執行效率相對比較低,比如即使有幾百行的表,如果多次關聯多次彙總,產生十幾個jobs,耗時很長。原因是map reduce作業初始化的時間是比較長的。
- sum,count,max,min等UDAF,不怕資料傾斜問題,hadoop在map端的彙總合併優化,使資料傾斜不成問題。
count(distinct ),在資料量大的情況下,效率較低,如果是多count(distinct )效率更低,因為count(distinct)是按group by 欄位分組,按distinct欄位排序,一般這種分佈方式是很傾斜的。舉個例子:比如男uv,女uv,像淘寶一天30億的pv,如果按性別分組,分配2個reduce,每個reduce處理15億資料。
面對這些問題,我們能有哪些有效的優化手段呢?下面列出一些在工作有效可行的優化手段:
好的模型設計事半功倍。
- 解決資料傾斜問題。
- 減少job數。
- 設定合理的map reduce的task數,能有效提升效能。(比如,10w+級別的計算,用160個reduce,那是相當的浪費,1個足夠)。
- 瞭解資料分佈,自己動手解決資料傾斜問題是個不錯的選擇。set hive.groupby.skewindata=true;這是通用的演算法優化,但演算法優化有時不能適應特定業務背景,開發人員瞭解業務,瞭解資料,可以通過業務邏輯精確有效的解決資料傾斜問題。
- 資料量較大的情況下,慎用count(distinct),count(distinct)容易產生傾斜問題。
- 對小檔案進行合併,是行至有效的提高排程效率的方法,假如所有的作業設定合理的檔案數,對雲梯的整體排程效率也會產生積極的正向影響。
優化時把握整體,單個作業最優不如整體最優。
而接下來,我們心中應該會有一些疑問,影響效能的根源是什麼?
效能低下的根源
hive效能優化時,把HiveQL當做M/R程式來讀,即從M/R的執行角度來考慮優化效能,從更底層思考如何優化運算效能,而不僅僅侷限於邏輯程式碼的替換層面。
RAC(Real Application Cluster)真正應用叢集就像一輛機動靈活的小貨車,響應快;Hadoop就像吞吐量巨大的輪船,啟動開銷大,如果每次只做小數量的輸入輸出,利用率將會很低。所以用好Hadoop的首要任務是增大每次任務所搭載的資料量。
Hadoop的核心能力是parition和sort,因而這也是優化的根本。
觀察Hadoop處理資料的過程,有幾個顯著的特徵:
- 資料的大規模並不是負載重點,造成執行壓力過大是因為執行資料的傾斜。
- jobs數比較多的作業執行效率相對比較低,比如即使有幾百行的表,如果多次關聯對此彙總,產生幾十個jobs,將會需要30分鐘以上的時間且大部分時間被用於作業分配,初始化和資料輸出。M/R作業初始化的時間是比較耗時間資源的一個部分。
- 在使用SUM,COUNT,MAX,MIN等UDAF函式時,不怕資料傾斜問題,Hadoop在Map端的彙總合併優化過,使資料傾斜不成問題。
- COUNT(DISTINCT)在資料量大的情況下,效率較低,如果多COUNT(DISTINCT)效率更低,因為COUNT(DISTINCT)是按GROUP BY欄位分組,按DISTINCT欄位排序,一般這種分散式方式是很傾斜的;比如:男UV,女UV,淘寶一天30億的PV,如果按性別分組,分配2個reduce,每個reduce處理15億資料。
資料傾斜是導致效率大幅降低的主要原因,可以採用多一次 Map/Reduce 的方法, 避免傾斜。
最後得出的結論是:避實就虛,用 job 數的增加,輸入量的增加,佔用更多儲存空間,充分利用空閒 CPU 等各種方法,分解資料傾斜造成的負擔。
優化效能
配置角度優化
map階段優化
Map階段的優化,主要是確定合適的map數。那麼首先要了解map數的計算公式,另外要說明的是,這個優化只是針對Hive 0.9版本。
num_map_tasks = max[${mapred.min.split.size},min(${dfs.block.size},${mapred.max.split.size})]- mapred.min.split.size: 指的是資料的最小分割單元大小;min的預設值是1B
- mapred.max.split.size: 指的是資料的最大分割單元大小;max的預設值是256MB
- dfs.block.size: 指的是HDFS設定的資料塊大小。個已經指定好的值,而且這個引數預設情況下hive是識別不到的
通過調整max可以起到調整map數的作用,減小max可以增加map數,增大max可以減少map數。需要提醒的是,直接調整mapred.map.tasks這個引數是沒有效果的。
reduce階段優化
這裡說的reduce階段,是指前面流程圖中的reduce phase(實際的reduce計算)而非圖中整個reduce task。Reduce階段優化的主要工作也是選擇合適的reduce task數量, 與map優化不同的是,reduce優化時,可以直接設定mapred.reduce.tasks引數從而直接指定reduce的個數
num_reduce_tasks = min[${hive.exec.reducers.max},(${input.size}/${hive.exec.reducers.bytes.per.reducer})]hive.exec.reducers.max:此引數從Hive 0.2.0開始引入。在Hive 0.14.0版本之前預設值是999;而從Hive 0.14.0開始,預設值變成了1009,這個引數的含義是最多啟動的Reduce個數
hive.exec.reducers.bytes.per.reducer:此引數從Hive 0.2.0開始引入。在Hive 0.14.0版本之前預設值是1G(1,000,000,000);而從Hive 0.14.0開始,預設值變成了256M(256,000,000),可以參見HIVE-7158和HIVE-7917。這個引數的含義是每個Reduce處理的位元組數。比如輸入檔案的大小是1GB,那麼會啟動4個Reduce來處理資料。
也就是說,根據輸入的資料量大小來決定Reduce的個數,預設Hive.exec.Reducers.bytes.per.Reducer為1G,而且Reduce個數不能超過一個上限引數值,這個引數的預設取值為999。所以我們可以調整Hive.exec.Reducers.bytes.per.Reducer來設定Reduce個數。
需要注意的是:
- Reduce的個數對整個作業的執行效能有很大影響。如果Reduce設定的過大,那麼將會產生很多小檔案,對NameNode會產生一定的影響,而且整個作業的執行時間未必會減少;如果Reduce設定的過小,那麼單個Reduce處理的資料將會加大,很可能會引起OOM異常。
- 如果設定了
mapred.reduce.tasks/mapreduce.job.reduces引數,那麼Hive會直接使用它的值作為Reduce的個數; - 如果
mapred.reduce.tasks/mapreduce.job.reduces的值沒有設定(也就是-1),那麼Hive會根據輸入檔案的大小估算出Reduce的個數。根據輸入檔案估算Reduce的個數可能未必很準確,因為Reduce的輸入是Map的輸出,而Map的輸出可能會比輸入要小,所以最準確的數根據Map的輸出估算Reduce的個數。
列裁剪
Hive 在讀資料的時候,可以只讀取查詢中所需要用到的列,而忽略其它列。 例如,若有以下查詢:
SELECT a,b FROM q WHERE e<10;在實施此項查詢中,Q 表有 5 列(a,b,c,d,e),Hive 只讀取查詢邏輯中真實需要 的 3 列 a、b、e,而忽略列 c,d;這樣做節省了讀取開銷,中間表儲存開銷和資料整合開銷。
裁剪所對應的引數項為:hive.optimize.cp=true(預設值為真)
補充:在我實習的操作過程中,也有用到這個道理,也就是多次join的時候,考慮到只需要的指標,而不是為了省事使用select * 作為子查詢
分割槽裁剪
可以在查詢的過程中減少不必要的分割槽。 例如,若有以下查詢:
SELECT
*
FROM
(
SELECTT
a1,
COUNT(1)
FROM T
GROUP BY a1
)subq # 建議貼邊寫,這樣容易檢查是否是中文括號!
WHERE subq.prtn=100; #(多餘分割槽)
SELECT
*
FROM
T1
JOIN
(
SELECT
*
FROM T2
)subq
ON (T1.a1=subq.a2)
WHERE subq.prtn=100;查詢語句若將“subq.prtn=100”條件放入子查詢中更為高效,可以減少讀入的分割槽 數目。 Hive 自動執行這種裁剪優化。
分割槽引數為:hive.optimize.pruner=true(預設值為真)
補充:實際叢集操作過程中,加分割槽是重中之重,不加分割槽的後果非常可能把整個佇列資源佔滿,而導致io讀寫異常,無法登陸伺服器及hive!切記切記分割槽操作和limit操作
JOIN操作
在編寫帶有 join 操作的程式碼語句時,應該將條目少的表/子查詢放在 Join 操作符的左邊。 因為在 Reduce 階段,位於 Join 操作符左邊的表的內容會被載入進記憶體,載入條目較少的表 可以有效減少 OOM(out of memory)即記憶體溢位。所以對於同一個 key 來說,對應的 value 值小的放前,大的放後,這便是“小表放前”原則。 若一條語句中有多個 Join,依據 Join 的條件相同與否,有不同的處理方法。
JOIN原則
在使用寫有 Join 操作的查詢語句時有一條原則:應該將條目少的表/子查詢放在 Join 操作符的左邊。原因是在 Join 操作的 Reduce 階段,位於 Join 操作符左邊的表的內容會被載入進記憶體,將條目少的表放在左邊,可以有效減少發生 OOM 錯誤的機率。對於一條語句中有多個 Join 的情況,如果 Join 的條件相同,一句話就是小表在左邊比如查詢:
INSERT OVERWRITE TABLE pv_users
SELECT
pv.pageid,
u.age
FROM page_view p
JOIN user u ON (pv.userid = u.userid)
JOIN newuser x ON (u.userid = x.userid); - 如果 Join 的 key 相同,不管有多少個表,都會則會合併為一個 Map-Reduce
- 一個 Map-Reduce 任務,而不是 ‘n’ 個
- 在做 OUTER JOIN 的時候也是一樣
如果 Join 的條件不相同,比如:
INSERT OVERWRITE TABLE pv_users
SELECT
pv.pageid,
u.age
FROM page_view p
JOIN user u ON (pv.userid = u.userid)
JOIN newuser x on (u.age = x.age); Map-Reduce 的任務數目和 Join 操作的數目是對應的,上述查詢和以下查詢是等價的:
INSERT OVERWRITE TABLE tmptable
SELECT
*
FROM page_view p
JOIN
user u
ON (pv.userid = u.userid);
INSERT OVERWRITE TABLE pv_users
SELECT
x.pageid,
x.age
FROM tmptable x
JOIN
newuser y
ON (x.age = y.age); MAP JOIN操作
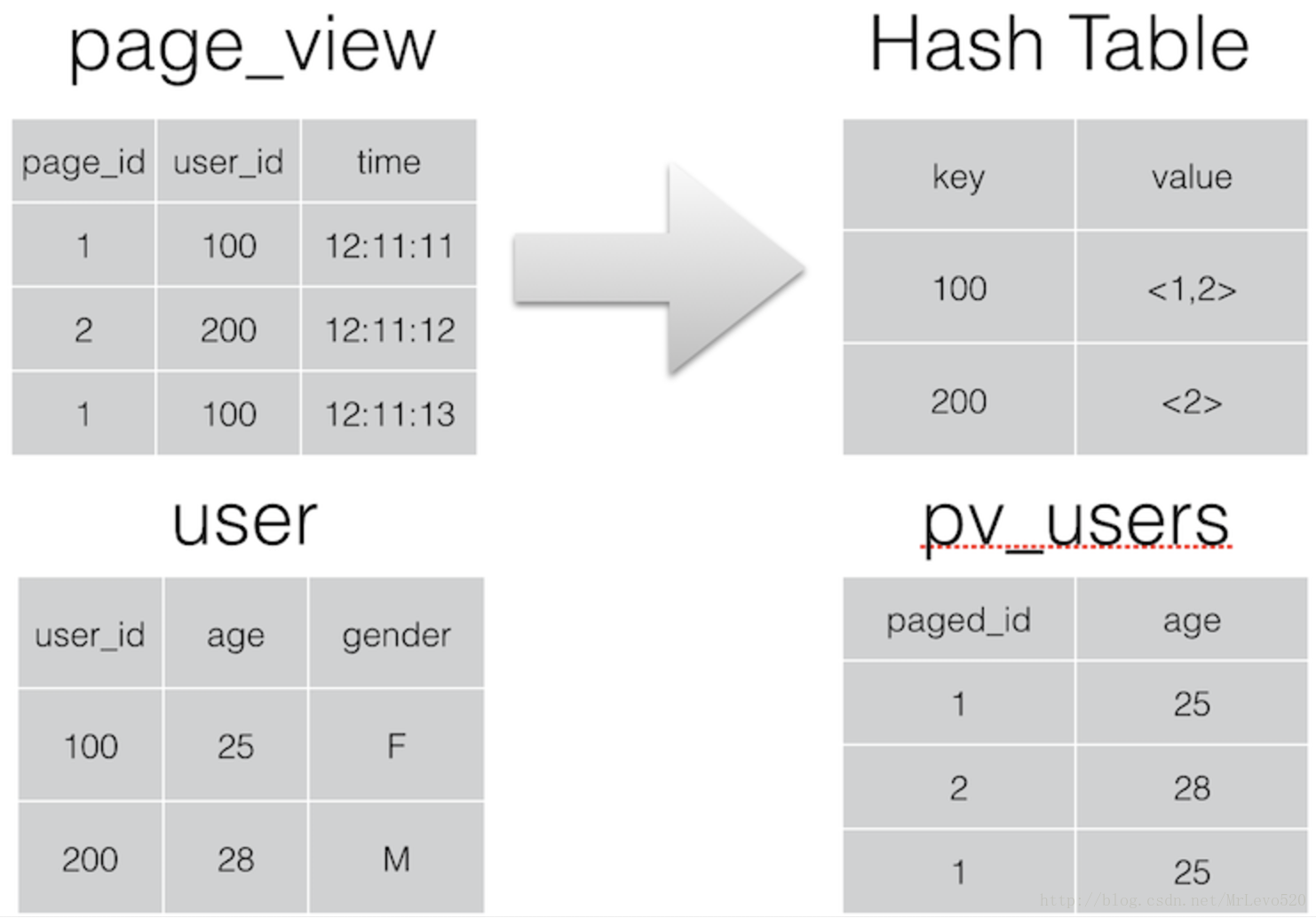
如果你有一張表非常非常小,而另一張關聯的表非常非常大的時候,你可以使用mapjoin此Join 操作在 Map 階段完成,不再需要Reduce,也就不需要經過Shuffle過程,從而能在一定程度上節省資源提高JOIN效率前提條件是需要的資料在 Map 的過程中可以訪問到。比如查詢:
INSERT OVERWRITE TABLE pv_users
SELECT /*+ MAPJOIN(pv) */ pv.pageid, u.age
FROM page_view pv
JOIN user u ON (pv.userid = u.userid); 可以在 Map 階段完成 Join,如圖所示:
相關的引數為:
- hive.join.emit.interval = 1000
- hive.mapjoin.size.key = 10000
- hive.mapjoin.cache.numrows = 10000
參考於Hive MapJoin:值得注意的是,Hive版本0.11之後,Hive預設啟動該優化,也就是不在需要顯示的使用MAPJOIN標記,其會在必要的時候觸發該優化操作將普通JOIN轉換成MapJoin
兩個屬性來設定該優化的觸發時機
hive.auto.convert.join預設值為true,自動開戶MAPJOIN優化
hive.mapjoin.smalltable.filesize預設值為2500000(25M),通過配置該屬性來確定使用該優化的表的大小,如果表的大小小於此值就會被載入進記憶體中
GROUP BY操作
進行GROUP BY操作時需要注意一下幾點:
Map端部分聚合
事實上並不是所有的聚合操作都需要在reduce部分進行,很多聚合操作都可以先在Map端進行部分聚合,然後reduce端得出最終結果。
這裡需要修改的引數為:
hive.map.aggr=true(用於設定是否在 map 端進行聚合,預設值為真) hive.groupby.mapaggr.checkinterval=100000(用於設定 map 端進行聚合操作的條目數)
有資料傾斜時進行負載均衡
此處需要設定 hive.groupby.skewindata,當選項設定為 true 是,生成的查詢計劃有兩個MapReduce 任務。
- 在第一個 MapReduce 中,map 的輸出結果集合會隨機分佈到 reduce 中, 每個reduce 做部分聚合操作,並輸出結果。這樣處理的結果是,相同的 Group By Key 有可能分發到不同的 reduce 中,從而達到負載均衡的目的;
- 第二個 MapReduce 任務再根據預處 理的資料結果按照 Group By Key 分佈到 reduce 中(這個過程可以保證相同的 Group By Key 分佈到同一個 reduce 中),最後完成最終的聚合操作。
合併小檔案
我們知道檔案數目小,容易在檔案儲存端造成瓶頸,給 HDFS 帶來壓力,影響處理效率。對此,可以通過合併Map和Reduce的結果檔案來消除這樣的影響。
用於設定合併屬性的引數有:
- 是否合併Map輸出檔案:
hive.merge.mapfiles=true(預設值為真) - 是否合併Reduce 端輸出檔案:
hive.merge.mapredfiles=false(預設值為假) - 合併檔案的大小:
hive.merge.size.per.task=256*1000*1000(預設值為 256000000)
補充:實際叢集操作過程中,join時候的小表在前的原則是比較先接觸到的,這點在查閱一些資料和問過同事之後覺得是最快優化join操作的,而mapjoin則幾乎沒有用到,可能接觸到的小表量級也是比較大的,而且公司的hive貌似是0.12的了,應該是自動優化的把
程式角度優化
熟練使用SQL提高查詢
熟練地使用 SQL,能寫出高效率的查詢語句。
場景:有一張 user 表,為賣家每天收到表,user_id,ds(日期)為 key,屬性有主營類目,指標有交易金額,交易筆數。每天要取前10天的總收入,總筆數,和最近一天的主營類目。
常用方法
# 第一步:利用分析函式,取每個 user_id 最近一天的主營類目,存入臨時表 t1。
CREATE TABLE t1 AS
SELECT
user_id,
substr(MAX(CONCAT(ds,cat),9) AS main_cat)
FROM users
WHERE ds=20120329 // 20120329 為日期列的值,實際程式碼中可以用函式表示出當天日期 GROUP BY user_id;
# 第二步:彙總 10 天的總交易金額,交易筆數,存入臨時表 t2
CREATE TABLE t2 AS
SELECT
user_id,
sum(qty) AS qty,SUM(amt) AS amt
FROM users
WHERE ds BETWEEN 20120301 AND 20120329
GROUP BY user_id
# 第三步:關聯 t1,t2,得到最終的結果。
SELECT
t1.user_id,
t1.main_cat,
t2.qty,t2.amt
FROM t1
JOIN t2 ON t1.user_id=t2.user_id優化方法
SELECT
user_id,
substr(MAX(CONCAT(ds,cat)),9) AS main_cat,
SUM(qty),
SUM(amt)
FROM users
WHERE ds BETWEEN 20120301 AND 20120329
GROUP BY user_id在工作中我們總結出:方案 2 的開銷等於方案 1 的第二步的開銷,效能提升,由原有的 25 分鐘完成,縮短為 10 分鐘以內完成。節省了兩個臨時表的讀寫是一個關鍵原因,這種方式也適用於 Oracle 中的資料查詢工作。 SQL 具有普適性,很多 SQL 通用的優化方案在 Hadoop 分散式計算方式中也可以達到效果。
補充:實際叢集操作過程中,第一種普通操作是要被同事嘲笑的,一般寫join的複合類的操作,我們儘量將把它寫在同一段程式碼中,所以可能會出現一段hive有七八個join,只有當需要產出中間表或者業務邏輯有點混亂的時候,我們才儲存中間表然後再重新寫下,一般而言,我們抽取資料的時候使用核心表去left join其他表,這樣就保證了核心表中的欄位都會在,即使匹配不到也會存在Null而不是資料的丟失,這對於我們之後計算指標來說是比較重要的
無效ID在關聯時的資料傾斜問題
問題:日誌中常會出現資訊丟失,比如每日約為 20 億的全網日誌,其中的 user_id 為主 鍵,在日誌收集過程中會丟失,出現主鍵為 null 的情況,如果取其中的 user_id 和 bmw_users 關聯,就會碰到資料傾斜的問題。原因是 Hive 中,主鍵為 null 值的項會被當做相同的 Key 而分配進同一個計算 Map。
- 解決方法 1:user_id 為空的不參與關聯,子查詢過濾 null
SELECT
*
FROM log a
JOIN
bmw_users b
ON a.user_id IS NOT NULL AND a.user_id=b.user_id
UNION All
SELECT
*
FROM log a
WHERE a.user_id IS NULL- 解決方法 2 如下所示:函式過濾 null
SELECT
*
FROM log a
LEFT OUTER JOIN
bmw_users b
ON
CASE WHEN a.user_id IS NULL THEN CONCAT('dp_hive',RAND()) ELSE a.user_id END =b.user_id; // 這句話寫的好騷氣啊,還有這種操作,我沒有試過調優結果:原先由於資料傾斜導致執行時長超過 1 小時,解決方法 1 執行每日平均時長 25 分鐘,解決方法 2 執行的每日平均時長在 20 分鐘左右。優化效果很明顯。
我們在工作中總結出:解決方法2比解決方法1效果更好,不但IO少了,而且作業數也少了。解決方法1中log讀取兩次,job 數為2。解決方法2中 job 數是1。這個優化適合無效 id(比如-99、 ‘’,null 等)產生的傾斜問題。把空值的 key 變成一個字串加上隨機數,就能把傾斜的 資料分到不同的Reduce上,從而解決資料傾斜問題。因為空值不參與關聯,即使分到不同 的 Reduce 上,也不會影響最終的結果。附上 Hadoop 通用關聯的實現方法是:關聯通過二次排序實現的,關聯的列為 partion key,關聯的列和表的 tag 組成排序的 group key,根據 pariton key分配Reduce。同一Reduce內根據group key排序。
不同資料型別關聯產生的傾斜問題
問題:不同資料型別 id 的關聯會產生資料傾斜問題。
一張表 s8 的日誌,每個商品一條記錄,要和商品表關聯。但關聯卻碰到傾斜的問題。 s8 的日誌中有 32 為字串商品 id,也有數值商品 id,日誌中型別是 string 的,但商品中的 數值 id 是 bigint 的。猜想問題的原因是把 s8 的商品 id 轉成數值 id 做 hash 來分配 Reduce, 所以字串 id 的 s8 日誌,都到一個 Reduce 上了,解決的方法驗證了這個猜測。
- 解決方法:把資料型別轉換成字串型別
SELECT
*
FROM s8_log a
LEFT OUTER JOIN
r_auction_auctions b
ON a.auction_id=CASE(b.auction_id AS STRING) 調優結果顯示:資料表處理由 1 小時 30 分鐘經程式碼調整後可以在 20 分鐘內完成。
補充:話說hive不是自帶隱式轉換麼,需要將bigint型別強制轉換成string型別?
利用Hive對UNION ALL優化的特性
問題:比如推廣效果表要和商品表關聯,效果表中的 auction_id 列既有 32 為字串商 品 id,也有數字 id,和商品表關聯得到商品的資訊。
- 解決方法:union all
SELECT
*
FROM effect a
JOIN
(
SELECT
auction_id AS auction_id
FROM auctions
UNION All
SELECT
auction_string_id AS auction_id
FROM auctions
)b
ON a.auction_id=b.auction_id 多表 union all 會優化成一個 job。比分別過濾數字 id,字串 id 然後分別和商品表關聯效能要好。
這樣寫的好處:1 個 MapReduce 作業,商品表只讀一次,推廣效果表只讀取一次。把 這個 SQL 換成 Map/Reduce 程式碼的話,Map 的時候,把 a 表的記錄打上標籤 a,商品表記錄 每讀取一條,打上標籤 b,變成兩個
解決Hive對UNION ALL優化的短板
Hive 對 union all 的優化的特性:對 union all 優化只侷限於非巢狀查詢。
消滅子查詢內的 group by
- 示例 1:子查詢內有 group by
SELECT
*
FROM
(
SELECT
*
FROM t1
GROUP BY c1,c2,c3
UNION ALL
SELECT
*
FROM t2
GROUP BY c1,c2,c3
)t3
GROUP BY c1,c2,c3 從業務邏輯上說,子查詢內的 GROUP BY 怎麼都看顯得多餘(功能上的多餘,除非有 COUNT(DISTINCT)),如果不是因為 Hive Bug 或者效能上的考量(曾經出現如果不執行子查詢 GROUP BY,資料得不到正確的結果的 Hive Bug)。所以這個 Hive 按經驗轉換成如下所示:
SELECT
*
FROM
(
SELECT
*
FROM t1
UNION ALL
SELECT
*
FROM t2
)t3
GROUP BY c1,c2,c3 調優結果:經過測試,並未出現 union all 的 Hive Bug,資料是一致的。MapReduce 的 作業數由 3 減少到 1。
t1 相當於一個目錄,t2 相當於一個目錄,對 Map/Reduce 程式來說,t1,t2 可以作為 Map/Reduce 作業的 mutli inputs。這可以通過一個 Map/Reduce 來解決這個問題。Hadoop 的 計算框架,不怕資料多,就怕作業數多。
但如果換成是其他計算平臺如 Oracle,那就不一定了,因為把大的輸入拆成兩個輸入, 分別排序彙總後 merge(假如兩個子排序是並行的話),是有可能效能更優的(比如希爾排 序比氣泡排序的效能更優)。
消滅子查詢內的 COUNT(DISTINCT),MAX,MIN。
SELECT
*
FROM
(
SELECT
*
FROM t1
UNION ALL
SELECT
c1,
c2,
c3,
COUNT(DISTINCT c4)
FROM t2
GROUP BY c1,c2,c3
)t3
GROUP BY c1,c2,c3; 由於子查詢裡頭有 COUNT(DISTINCT)操作,直接去 GROUP BY 將達不到業務目標。這時採用臨時表消滅 COUNT(DISTINCT)作業不但能解決傾斜問題,還能有效減少 jobs。
INSERT t4 SELECT c1,c2,c3,c4 FROM t2 GROUP BY c1,c2,c3;
SELECT
c1,
c2,
c3,
SUM(income),
SUM(uv)
FROM
(
SELECT
c1,
c2,
c3,
income,
0 AS uv
FROM t1
UNION ALL
SELECT
c1,
c2,
c3,
0 AS income,
1 AS uv
FROM t2
)t3
GROUP BY c1,c2,c3;job 數是 2,減少一半,而且兩次 Map/Reduce 比 COUNT(DISTINCT)效率更高。
調優結果:千萬級別的類目表,member 表,與 10 億級得商品表關聯。原先 1963s 的任務經過調整,1152s 即完成。
消滅子查詢內的 JOIN
SELECT
*
FROM
(
SELECT
*
FROM t1
UNION ALL
SELECT
*
FROM t4
UNION ALL
SELECT
*
FROM t2
JOIN t3
ON t2.id=t3.id
)x
GROUP BY c1,c2; 上面程式碼執行會有 5 個 jobs。加入先 JOIN 生存臨時表的話 t5,然後 UNION ALL,會變成 2 個 jobs。
INSERT OVERWRITE TABLE t5
SELECT * FROM t2 JOIN t3 ON t2.id=t3.id;
SELECT * FROM (t1 UNION ALL t4 UNION ALL t5); 調優結果顯示:針對千萬級別的廣告位表,由原先 5 個 Job 共 15 分鐘,分解為 2 個 job 一個 8-10 分鐘,一個3分鐘。
補充:第二個消滅子查詢內的 JOIN,我覺得意義不是很大,第一需要建立臨時表,這個內表還需要定時清理,第二沒有從原理上進行優化,只是把步驟分開了而已,所以意義並非那麼大,如果說從減少job的意義上來說,的確有提升,但是如果是業務程式碼塊,感覺分開寫意義不是很大,這是我個人的理解
GROUP BY替代COUNT(DISTINCT)達到優化效果
計算 uv 的時候,經常會用到 COUNT(DISTINCT),但在資料比較傾斜的時候 COUNT(DISTINCT) 會比較慢。這時可以嘗試用 GROUP BY 改寫程式碼計算 uv。
- 原有程式碼
ALTER TABLE s_dw_tanx_adzone_uv ADD PARTITION (ds=20120329)
SELECT
20120329 AS thedate,
adzoneid,
COUNT(DISTINCT acookie) AS uv
FROM s_ods_log_tanx_pv t
WHERE t.ds=20120329
GROUP BY adzoneid關於COUNT(DISTINCT)的資料傾斜問題不能一概而論,要依情況而定,下面是我測試的一組資料:
測試資料:169857條
#統計每日IP
CREATE TABLE ip_2014_12_29 AS
SELECT
COUNT(DISTINCT ip) AS IP
FROM logdfs
WHERE logdate='2014_12_29';
耗時:24.805 seconds
#統計每日IP(改造)
CREATE TABLE ip_2014_12_29 AS
SELECT
COUNT(1) AS IP
FROM
(
SELECT
DISTINCT ip
from logdfs
WHERE logdate='2014_12_29'
)tmp;
耗時:46.833 seconds測試結果表名:明顯改造後的語句比之前耗時,這是因為改造後的語句有2個SELECT,多了一個job,這樣在資料量小的時候,資料不會存在傾斜問題。
補充:相當於多做子查詢操作,那肯定是變慢的
優化總結
優化時,把hive sql當做mapreduce程式來讀,會有意想不到的驚喜。理解hadoop的核心能力,是hive優化的根本。這是這一年來,專案組所有成員寶貴的經驗總結。
長期觀察hadoop處理資料的過程,有幾個顯著的特徵:
- 不怕資料多,就怕資料傾斜。
- 對jobs數比較多的作業執行效率相對比較低,比如即使有幾百行的表,如果多次關聯多次彙總,產生十幾個jobs,沒半小時是跑不完的。map reduce作業初始化的時間是比較長的。
- 對sum,count來說,不存在資料傾斜問題。
- 對count(distinct ),效率較低,資料量一多,準出問題,如果是多count(distinct )效率更低。
優化可以從幾個方面著手:
- 好的模型設計事半功倍。
- 解決資料傾斜問題。
- 減少job數。
- 設定合理的map reduce的task數,能有效提升效能。(比如,10w+級別的計算,用160個reduce,那是相當的浪費,1個足夠)。
- 自己動手寫sql解決資料傾斜問題是個不錯的選擇。set hive.groupby.skewindata=true;這是通用的演算法優化,但演算法優化總是漠視業務,習慣性提供通用的解決方法。 Etl開發人員更瞭解業務,更瞭解資料,所以通過業務邏輯解決傾斜的方法往往更精確,更有效。
- 對count(distinct)採取漠視的方法,尤其資料大的時候很容易產生傾斜問題,不抱僥倖心理。自己動手,豐衣足食。
- 對小檔案進行合併,是行至有效的提高排程效率的方法,假如我們的作業設定合理的檔案數,對雲梯的整體排程效率也會產生積極的影響。
優化時把握整體,單個作業最優不如整體最優。
更新
這是一個積累的過程,所以以後必然會有更新
- 2017.07.29 第一次更新
- 2017.08.04 第二次更新