
【深度學習:目標檢測】 RCNN學習筆記(11):R-FCN: Object Detection via Region-based Fully Convolutional Networks
轉自:http://blog.csdn.NET/shadow_guo/article/details/51767036
作者代季峰 1,14年畢業的清華博士到微軟亞洲研究院的視覺計算組,CVPR 16 兩篇一作的會議主持人同時公佈了原始碼~ 2
1. 簡介
物體檢測的深度網路按感興趣區域 (RoI) 池化層分為兩大主流:共享計算的全卷積子網路 (每個子網路與 RoI 無關) 和 不共享計算的作用於各自 RoI 的子網路。工程分類結構 (如 Alexnet 和 VGG Nets) 造成這樣的分流。而工程上的影象分類結構被設計為兩個子網路——1個字尾1個空間池化層的卷積子網路和多個全連線層。因此,影象分類網路中最後的空間池化層自然變成了物體檢測網路中的 RoI 池化層。
近年來,諸如殘差網路和 GoogLeNets 等先進的影象分類網路為全卷積網路。類似地,自然會想到用在物體檢測中用全卷積網路 (隱藏層不包含作用於 RoI 的子網路)。然而,物體檢測工作中的經驗表明,這樣天真的解決方案的檢測效果遠差於該網路的分類效果。 為彌補尷尬,更快 R-CNN 檢測器不自然地在兩卷積層間插入RoI 池化層,這樣更深的作用於各 RoI 的子網路雖精度更高,但各個 RoI 計算不共享所以速度慢。
尷尬在於:物體分類要求平移不變性越大越好 (影象中物體的移動不用區分),而物體檢測要求有平移變化。所以,ImageNet 分類領先的結果證明儘可能有平移不變性的全卷積結構更受親睞。另一方面,物體檢測任務需要一些平移變化的定位表示。比如,物體的平移應該使網路產生響應,這些響應對描述候選框覆蓋真實物體的好壞是有意義的。我們假設影象分類網路的卷積層越深,則該網路對平移越不敏感。
我曾看到的尷尬包括:
a) Kaggle 中的白鯨身份識別。剛開始很多人嘗試從影象到座標的直接回歸,到後面有幾位心善的大哥分享了自己手動標定後白鯨的影象座標,後來顯著的進展大多是因為把白鯨的位置檢測和身份識別問題簡化為白鯨的身份識別問題。
b) Caffe 用於物體檢測時的均值收斂問題。
為消除尷尬,在網路的卷積層間插入 RoI 池化層。這種具體到區域的操作在不同區域間跑時不再有平移不變性。然而,該設計因引入相當數目的按區域操作層 (region-wise layers) 而犧牲了訓練和測試效率。
本文,我們為物體檢測推出了基於區域的全卷積網路 (R-FCN),採用全卷積網路結構作為 FCN,為給 FCN 引入平移變化,用專門的卷積層構建位置敏感分數地圖 (position-sensitive score maps)。每個空間敏感地圖編碼感興趣區域的相對空間位置資訊。 在FCN上面增加1個位置敏感 RoI 池化層來監管這些分數地圖。
2. 方法
(1) 簡介
效仿 R-CNN,採用流行的物體檢測策略,包括區域建議和區域分類兩步。不依賴區域建議的方法確實存在 (SSD 和 Yolo 弟兄),基於區域的系統在不同 benchmarks 上依然精度領先。用更快 R-CNN 中的區域建議網路 (RPN) 提取候選區域,該 RPN 為全卷積網路。效仿更快 R-CNN,共享 RPN 和 R-FCN 的特徵。
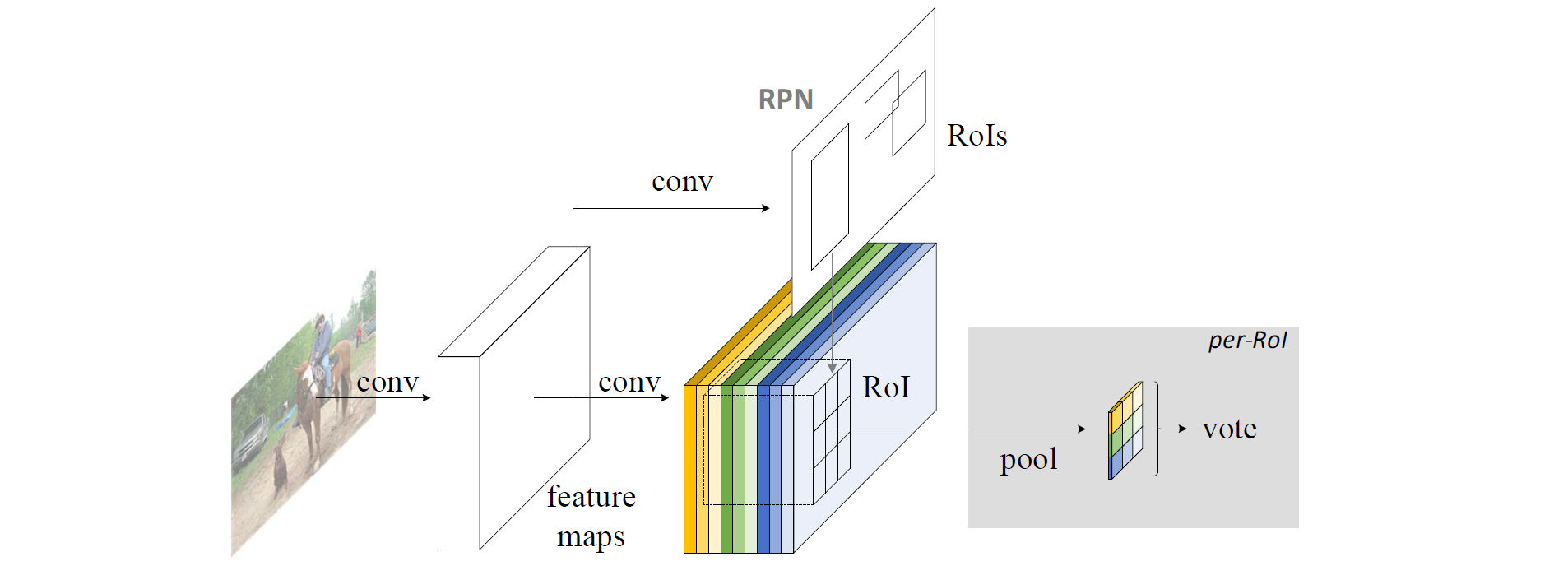
RPN 給出感興趣區域,R-FCN 對該感興趣區域分類。R-FCN 在與 RPN 共享的卷積層後多加1個卷積層。所以,R-FCN 與 RPN 一樣,輸入為整幅影象。但 R-FCN 最後1個卷積層的輸出從整幅影象的卷積響應影象中分割出感興趣區域的卷積響應影象。
R-FCN 最後1個卷積層在整幅影象上為每類生成
R-FCN 最後用位置敏感 RoI 池化層,給每個 RoI 1個分數。選擇性池化圖解:看上圖的橙色響應影象 (
選擇性池化是跨通道的,投票部分的池化為所有通道的池化。而一般池化都在通道內。
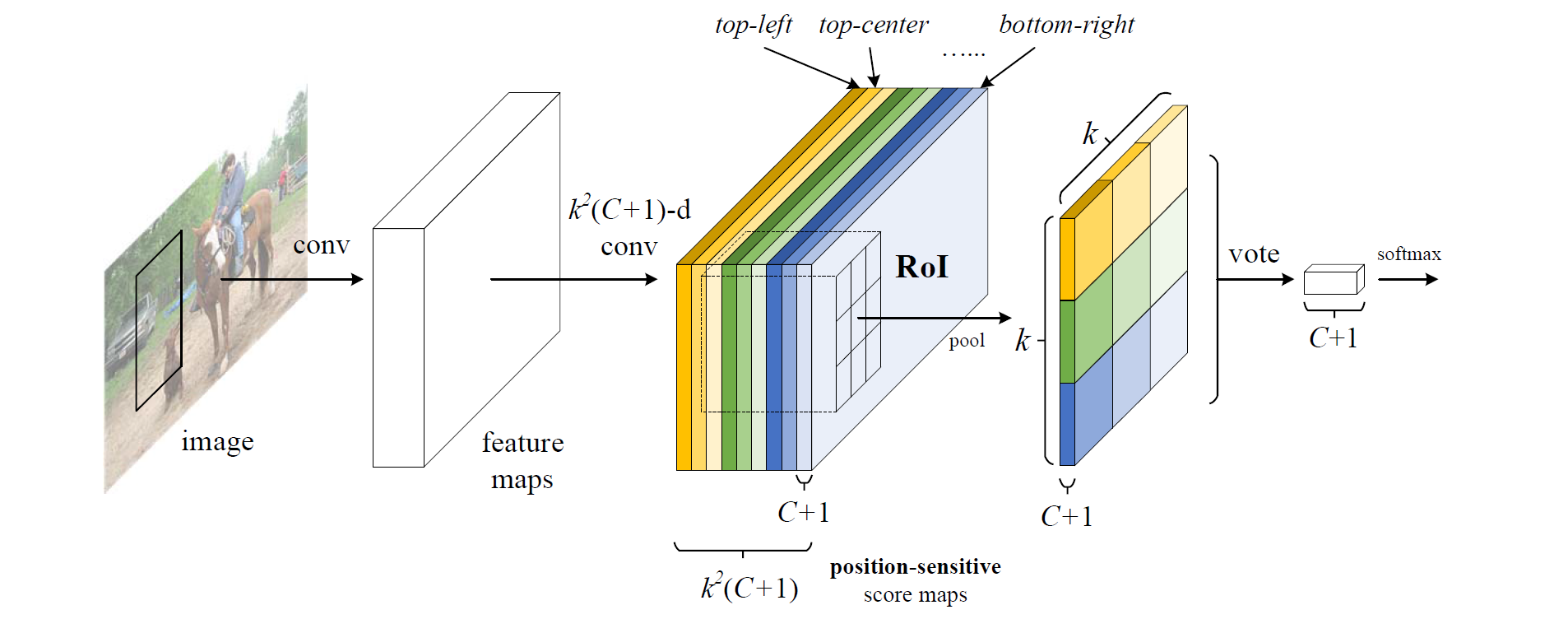
R-FCN 最後1個卷積層的輸出為什麼會具有相對空間位置這樣的物理意義 (top-left,top-center,…,bottom-right)?
原文為“With end-to-end training, this RoI layer shepherds the last convolutional layer to learn specialized position-sensitive score maps.”。所以,假設端到端訓練後每層真有相對位置的意義,那麼投票前的輸入一定位置敏感。投票後面的內容用作分類。
端到端訓練先自行腦補:
假設已知原影象與真實物體的邊界框中心座標和寬高,把1個物體的邊界框中心座標分成
(2) 基礎結構
ResNet-101 網路有100個卷積層,1個全域性平均池化層和1個1000類的全連線層。僅用ImageNet預訓練的該網路的卷積層計算特徵圖。
(3) 位置敏感分數圖
對 R-FCN 的卷積響應影象按 RPN 的結果分割出來感興趣區域,對單通道的感興趣區域分成
其實不是這樣的~ 因為 RoI 覆蓋的所有面積的橙色方片都是左上位置的響應。
“To explicitly encode position information into each RoI, we divide each RoI rectangle into

對1個大小為