
【目標檢測】Faster RCNN演算法詳解
Ren, Shaoqing, et al. “Faster R-CNN: Towards real-time object detection with region proposal networks.” Advances in Neural Information Processing Systems. 2015.
本文是繼RCNN[1],fast RCNN[2]之後,目標檢測界的領軍人物Ross Girshick團隊在2015年的又一力作。簡單網路目標檢測速度達到17fps,在PASCAL VOC上準確率為59.9%;複雜網路達到5fps,準確率78.8%。
思想
從RCNN到fast RCNN,再到本文的faster RCNN,目標檢測的四個基本步驟(候選區域生成,特徵提取,分類,位置精修)終於被統一到一個深度網路框架之內
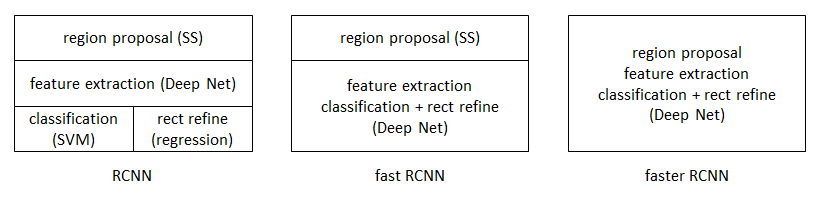
faster RCNN可以簡單地看做“區域生成網路+fast RCNN“的系統,用區域生成網路代替fast RCNN中的Selective Search方法。本篇論文著重解決了這個系統中的三個問題:
1. 如何設計區域生成網路
2. 如何訓練區域生成網路
3. 如何讓區域生成網路和fast RCNN網路共享特徵提取網路
區域生成網路:結構
基本設想是:在提取好的特徵圖上,對所有可能的候選框進行判別。由於後續還有位置精修步驟,所以候選框實際比較稀疏。
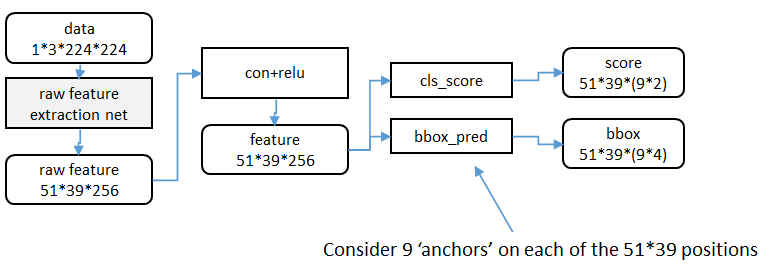
特徵提取
原始特徵提取(上圖灰色方框)包含若干層conv+relu,直接套用ImageNet上常見的分類網路即可。本文試驗了兩種網路:5層的ZF[
額外新增一個conv+relu層,輸出51*39*256維特徵(feature)。
候選區域(anchor)
特徵可以看做一個尺度51*39的256通道影象,對於該影象的每一個位置,考慮9個可能的候選視窗:三種面積{128 2 ,256 2 ,512 2 }× 三種比例{1:1,1:2,2:1} 。這些候選視窗稱為anchors。下圖示出51*39個anchor中心,以及9種anchor示例。

在整個faster RCNN演算法中,有三種尺度。
原圖尺度:原始輸入的大小。不受任何限制,不影響效能。
歸一化尺度:輸入特徵提取網路的大小,在測試時設定,原始碼中opts.test_scale=600。anchor在這個尺度上設定。這個引數和anchor的相對大小決定了想要檢測的目標範圍。
網路輸入尺度:輸入特徵檢測網路的大小,在訓練時設定,原始碼中為224*224。
視窗分類和位置精修
分類層(cls_score)輸出每一個位置上,9個anchor屬於前景和背景的概率;視窗迴歸層(bbox_pred)輸出每一個位置上,9個anchor對應視窗應該平移縮放的引數。
對於每一個位置來說,分類層從256維特徵中輸出屬於前景和背景的概率;視窗迴歸層從256維特徵中輸出4個平移縮放參數。
就區域性來說,這兩層是全連線網路;就全域性來說,由於網路在所有位置(共51*39個)的引數相同,所以實際用尺寸為1×1的卷積網路實現。
需要注意的是:並沒有顯式地提取任何候選視窗,完全使用網路自身完成判斷和修正。
區域生成網路:訓練
樣本
考察訓練集中的每張影象:
a. 對每個標定的真值候選區域,與其重疊比例最大的anchor記為前景樣本
b. 對a)剩餘的anchor,如果其與某個標定重疊比例大於0.7,記為前景樣本;如果其與任意一個標定的重疊比例都小於0.3,記為背景樣本
c. 對a),b)剩餘的anchor,棄去不用。
d. 跨越影象邊界的anchor棄去不用
代價函式
同時最小化兩種代價:
a. 分類誤差
b. 前景樣本的視窗位置偏差
具體參看fast RCNN中的“分類與位置調整”段落。
超引數
原始特徵提取網路使用ImageNet的分類樣本初始化,其餘新增層隨機初始化。
每個mini-batch包含從一張影象中提取的256個anchor,前景背景樣本1:1.
前60K迭代,學習率0.001,後20K迭代,學習率0.0001。
momentum設定為0.9,weight decay設定為0.0005。[5]
共享特徵
區域生成網路(RPN)和fast RCNN都需要一個原始特徵提取網路(下圖灰色方框)。這個網路使用ImageNet的分類庫得到初始引數W 0 ,但要如何精調引數,使其同時滿足兩方的需求呢?本文講解了三種方法。
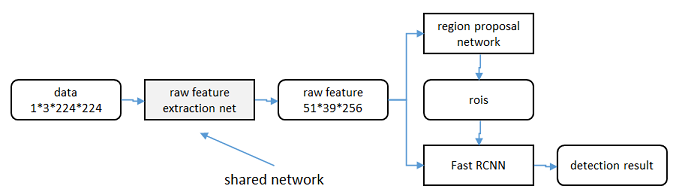
輪流訓練
a. 從W 0 開始,訓練RPN。用RPN提取訓練集上的候選區域
b. 從W 0 開始,用候選區域訓練Fast
RCNN,引數記為W 1
c. 從W 1 開始,訓練RPN…
具體操作時,僅執行兩次迭代,並在訓練時凍結了部分層。論文中的實驗使用此方法。
如Ross Girshick在ICCV 15年的講座Training R-CNNs of various velocities中所述,採用此方法沒有什麼根本原因,主要是因為”實現問題,以及截稿日期“。
近似聯合訓練
直接在上圖結構上訓練。在backward計算梯度時,把提取的ROI區域當做固定值看待;在backward更新引數時,來自RPN和來自Fast RCNN的增量合併輸入原始特徵提取層。
此方法和前方法效果類似,但能將訓練時間減少20%-25%。公佈的python程式碼中包含此方法。
聯合訓練
直接在上圖結構上訓練。但在backward計算梯度時,要考慮ROI區域的變化的影響。推導超出本文範疇,請參看15年NIP論文[6]。
實驗
除了開篇提到的基本效能外,還有一些值得注意的結論
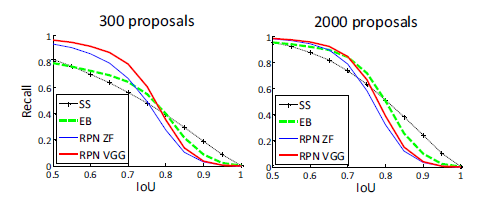
-
與Selective Search方法(黑)相比,當每張圖生成的候選區域從2000減少到300時,本文RPN方法(紅藍)的召回率下降不大。說明RPN方法的目的性更明確。
-
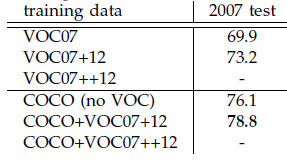
使用更大的Microsoft COCO庫[7]訓練,直接在PASCAL VOC上測試,準確率提升6%。說明faster RCNN遷移性良好,沒有over fitting。
- Girshick, Ross, et al. “Rich feature hierarchies for accurate object detection and semantic segmentation.” Proceedings of the IEEE conference on computer vision and pattern recognition. 2014. ↩
- Girshick, Ross. “Fast r-cnn.” Proceedings of the IEEE International Conference on Computer Vision. 2015. ↩
- M. D. Zeiler and R. Fergus, “Visualizing and understanding convolutional neural networks,” in European Conference on Computer Vision (ECCV), 2014. ↩
- K. Simonyan and A. Zisserman, “Very deep convolutional networks for large-scale image recognition,” in International Conference on Learning Representations (ICLR), 2015. ↩
- learning rate-控制增量和梯度之間的關係;momentum-保持前次迭代的增量;weight decay-每次迭代縮小引數,相當於正則化。 ↩
- Jaderberg et al. “Spatial Transformer Networks”
NIPS 2015 ↩