
權重衰減(weight decay)與學習率衰減(learning rate decay)
文章來自Microstrong的知乎專欄,僅做搬運。原文鏈接
1. 權重衰減(weight decay)
L2正則化的目的就是為了讓權重衰減到更小的值,在一定程度上減少模型過擬合的問題,所以權重衰減也叫L2正則化。
1.1 L2正則化與權重衰減系數
L2正則化就是在代價函數後面再加上一個正則化項:
其中 代表原始的代價函數,後面那一項就是L2正則化項,它是這樣來的:所有參數w的平方的和,除以訓練集的樣本大小n。λ就是正則項系數,權衡正則項與
項的比重。另外還有一個系數
,
經常會看到,主要是為了後面求導的結果方便,後面那一項求導會產生一個2,與
相乘剛好湊整為1。系數
就是權重衰減系數。
1.2 為什麽可以對權重進行衰減
我們對加入L2正則化後的代價函數進行推導,先求導:
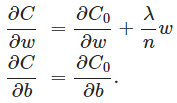
可以發現L2正則化項對b的更新沒有影響,但是對於w的更新有影響:
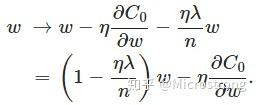
在不使用L2正則化時,求導結果中w前系數為1,現在w前面系數為 ,因為η、λ、n都是正的,所以
小於1,它的效果是減小w,這也就是權重衰減(weight decay)的由來。當然考慮到後面的導數項,w最終的值可能增大也可能減小。
另外,需要提一下,對於基於mini-batch的隨機梯度下降,w和b更新的公式跟上面給出的有點不同:
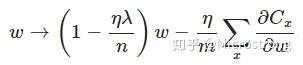
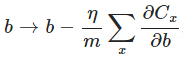
對比上面w的更新公式,可以發現後面那一項變了,變成所有導數加和,乘以η再除以m,m是一個mini-batch中樣本的個數。
1.3 權重衰減(L2正則化)的作用
作用:權重衰減(L2正則化)可以避免模型過擬合問題。
思考:L2正則化項有讓w變小的效果,但是為什麽w變小可以防止過擬合呢?
原理:(1)從模型的復雜度上解釋:更小的權值w,從某種意義上說,表示網絡的復雜度更低,對數據的擬合更好(這個法則也叫做奧卡姆剃刀),而在實際應用中,也驗證了這一點,L2正則化的效果往往好於未經正則化的效果。(2)從數學方面的解釋:過擬合的時候,擬合函數的系數往往非常大,為什麽?如下圖所示,過擬合,就是擬合函數需要顧忌每一個點,最終形成的擬合函數波動很大。在某些很小的區間裏,函數值的變化很劇烈。這就意味著函數在某些小區間裏的導數值(絕對值)非常大,由於自變量值可大可小,所以只有系數足夠大,才能保證導數值很大。而正則化是通過約束參數的範數使其不要太大,所以可以在一定程度上減少過擬合情況。
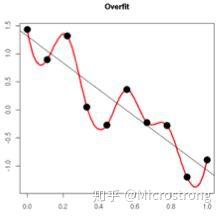
內容來自:正則化方法:L1和L2 regularization、數據集擴增、dropout
2. 學習率衰減(learning rate decay)
在訓練模型的時候,通常會遇到這種情況:我們平衡模型的訓練速度和損失(loss)後選擇了相對合適的學習率(learning rate),但是訓練集的損失下降到一定的程度後就不在下降了,比如training loss一直在0.7和0.9之間來回震蕩,不能進一步下降。如下圖所示:
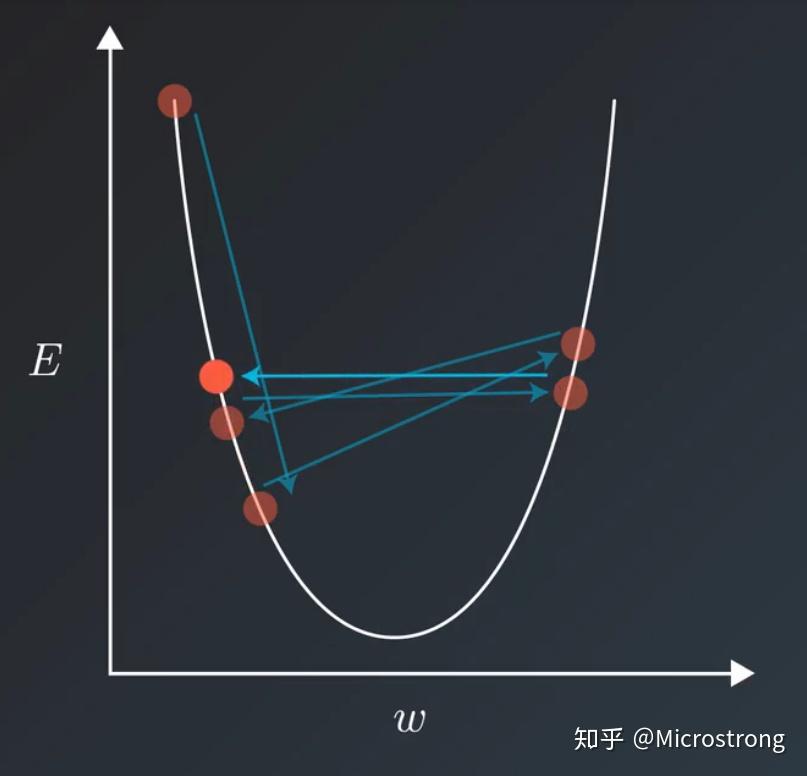
遇到這種情況通常可以通過適當降低學習率(learning rate)來實現。但是,降低學習率又會延長訓練所需的時間。
學習率衰減(learning rate decay)就是一種可以平衡這兩者之間矛盾的解決方案。學習率衰減的基本思想是:學習率隨著訓練的進行逐漸衰減。
學習率衰減基本有兩種實現方法:
- 線性衰減。例如:每過5個epochs學習率減半。
- 指數衰減。例如:隨著叠代輪數的增加學習率自動發生衰減,每過5個epochs將學習率乘以0.9998。具體算法如下:
decayed_learning_rate=learning_rate*decay_rate^(global_step/decay_steps)
其中decayed_learning_rate為每一輪優化時使用的學習率,learning_rate為事先設定的初始學習率,decay_rate為衰減系數,decay_steps為衰減速度。
Reference:
(1)學習率衰減部分內容和圖片來自: 學習率衰減(learning rate decay)
(2)神經網絡學習率(learning rate)的衰減
權重衰減(weight decay)與學習率衰減(learning rate decay)