
(轉)Python爬蟲--通用框架
轉自https://blog.csdn.net/m0_37903789/article/details/74935906
前言:
相信不少寫過Python爬蟲的小夥伴,都應該有和筆者一樣的經歷吧只要確定了要爬取的目標,就開始瘋狂的寫代碼,寫腳本經過一番努力後,爬取到目標數據;但是回過頭來,卻發現自己所代碼復用性小,一旦網頁發生了更改,我們也不得不隨之更改自己的代碼,而卻自己的程序過於腳本化,函數化,沒有采用OPP的思維方式;沒有系統的框架或結構。
指導老師看了筆者的爬蟲作品後,便給出了以下三點建議:
(1)爬蟲爬取的數據根據需要存數據庫或直接寫入.csv文件;
(2)爬蟲程序包括控制程序、URL調度器、頁面加載器、頁面分析器、數據處理器等,盡量用OOP的思想,寫成類,便於擴充,而不要直接全寫成腳本;
由於筆者知識和能力有限,剛聽到這些建議時,很難明白他的意思,而筆者還偏執的認為既然已經成功的爬取到目標數據,也就沒什麽要做的啦,已經OK啦直到昨天看了這個http://www.imooc.com/learn/563關於Python爬蟲的課程後,才徹底的理解了老師教的課程裏系統的講解了爬蟲應有的框架和結構,使筆者收益匪淺,故在此總結,反思,希望對大家有幫助。
這裏先為它,打個小廣告吧~筆者個人認為,不管你是資深的Python爬蟲專家,還是才接觸爬蟲的新手,都應該來看一看,為你以後的Python爬蟲工作添磚加瓦,廣告語“慕課網—程序員的夢工廠”。
基於百度百科詞條,通用爬蟲源碼:https://github.com/NO1117/baike_spider
Python交流群:942913325 歡迎大家一起交流學習
總結:
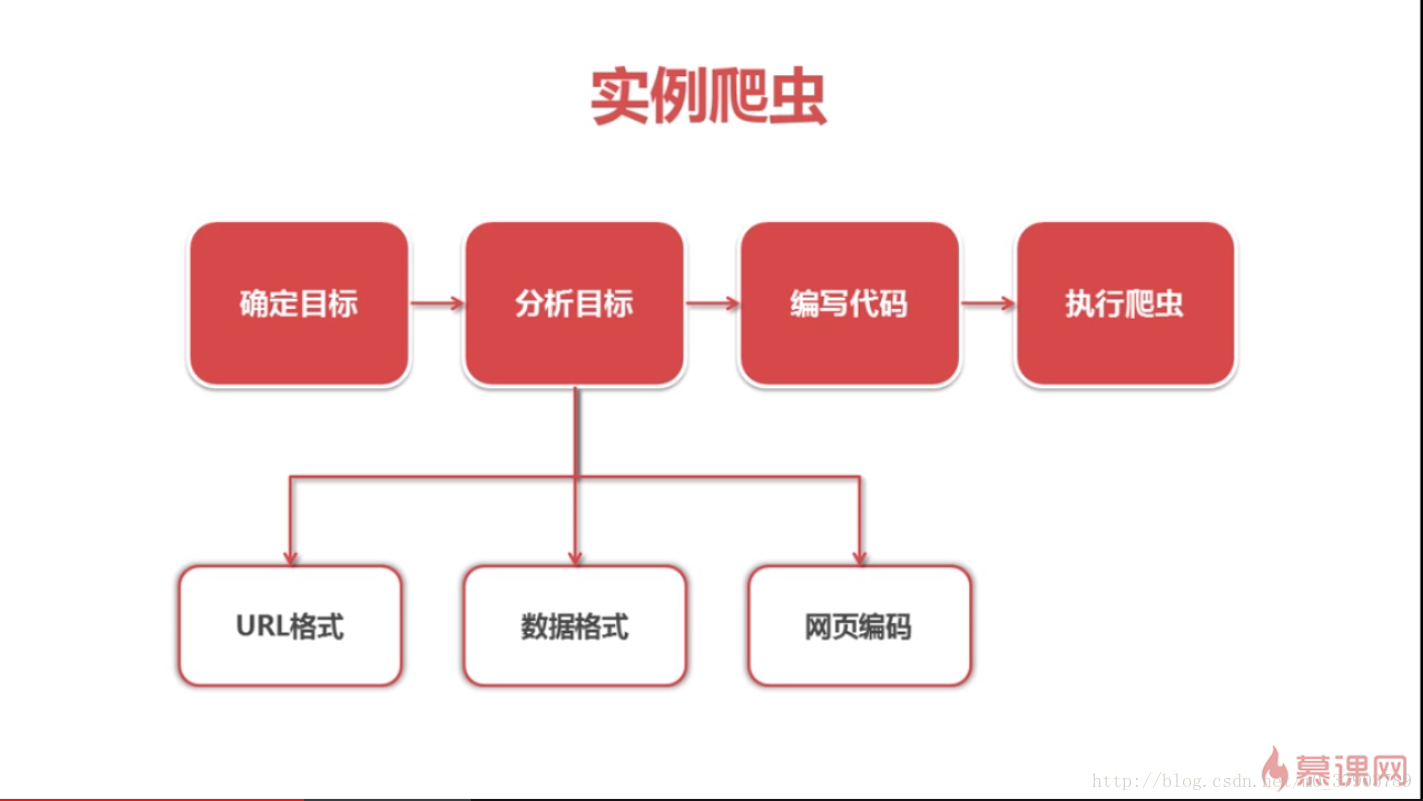
1.爬蟲思路
如上圖所示,一般在開始爬蟲時,都會經歷這樣的思考過程,其中最為主要和關鍵的分析目標,只有經過準確的分析和前期的充分準備,才能順順利利的爬取到目標數據。
2.爬蟲任務:

3.爬蟲的框架及運行流程圖
接下來,就一起學習一下Python爬蟲的框架吧~
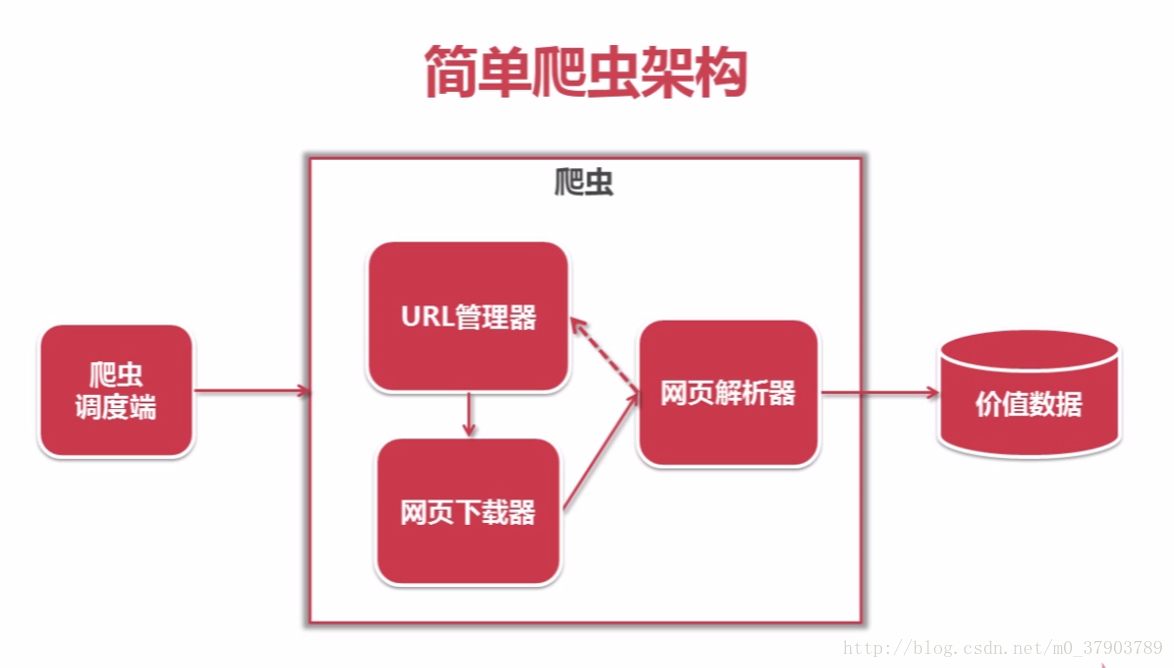
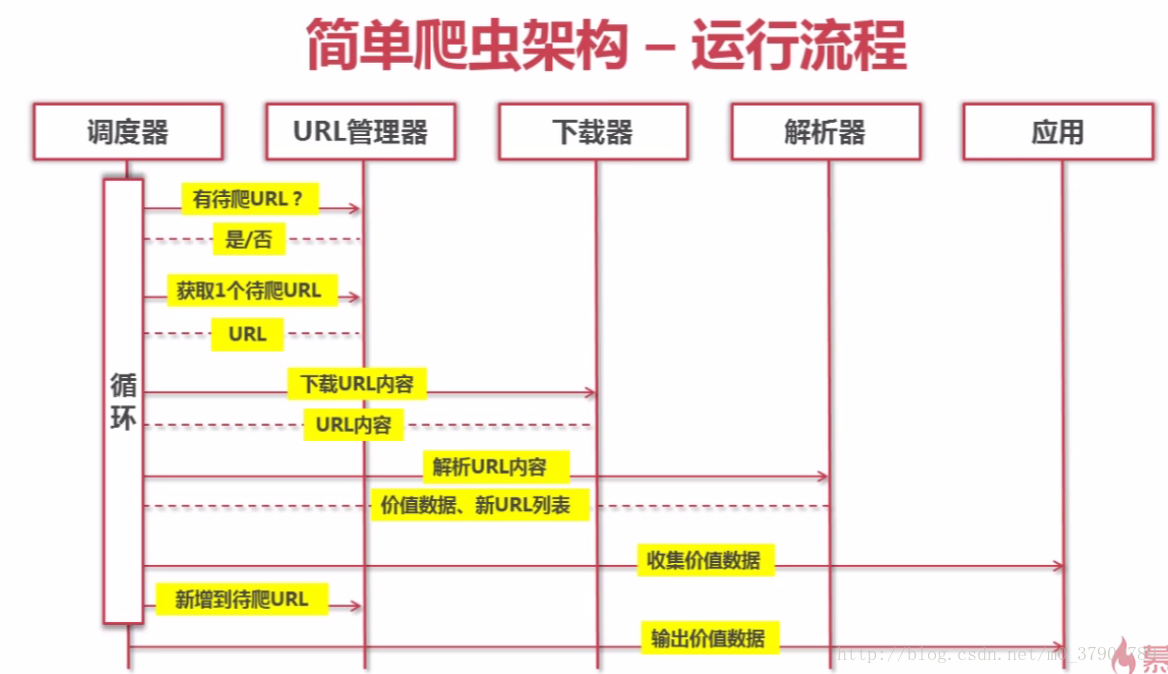
爬蟲的大致運行過程如下:
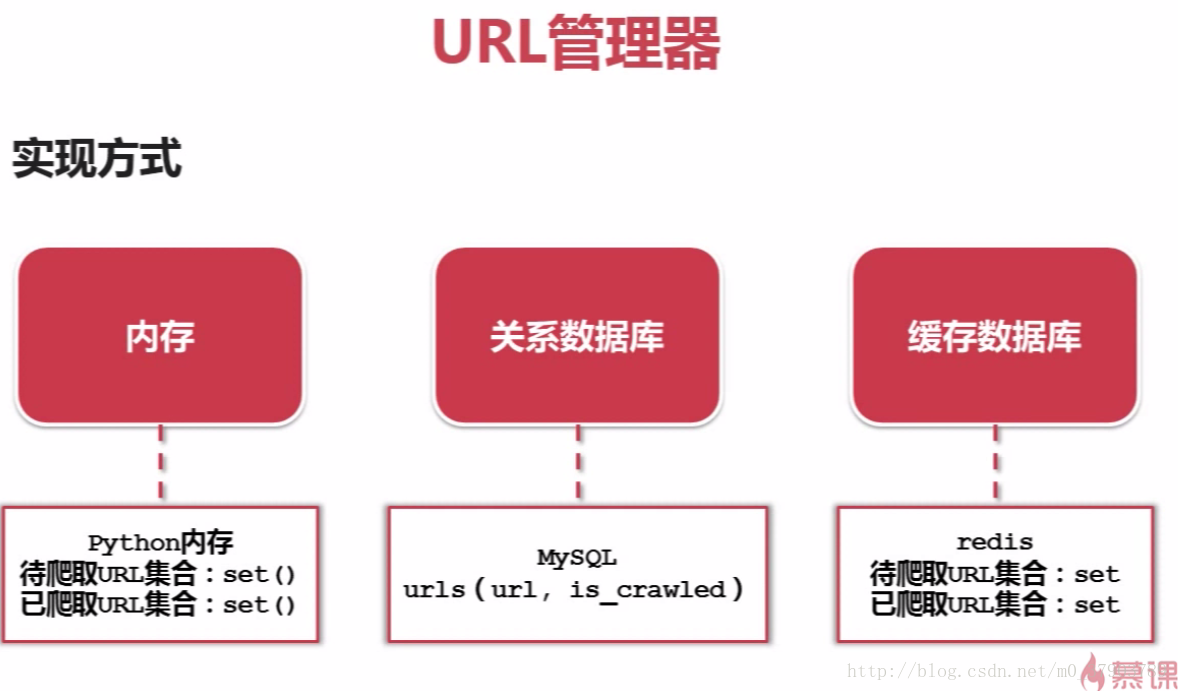
4.URL管理器
所謂的URL管理器,主要是由兩個集合構成(待抓取URL集合和已抓取URL集合),其目的是為了防止重復抓取,循環抓取;
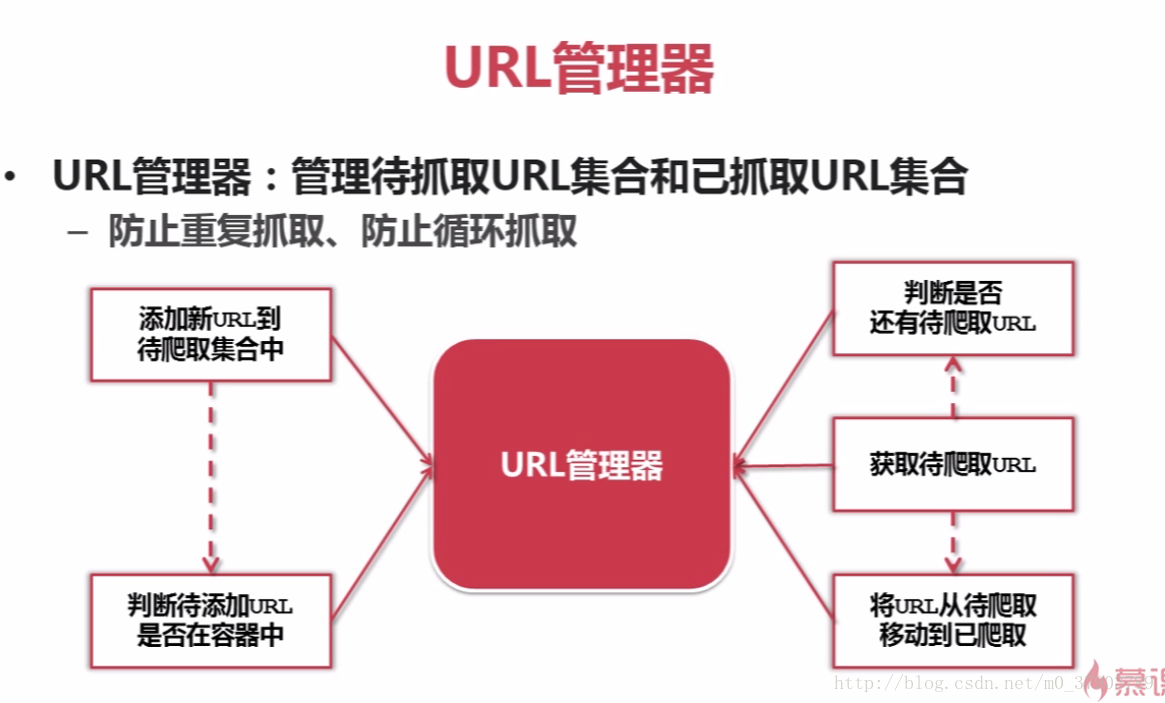
URL管理器的實現方式,分三種:a,Python內存(即集合);b,數據庫(如MySQL,MongoDB等);c,緩存數據庫
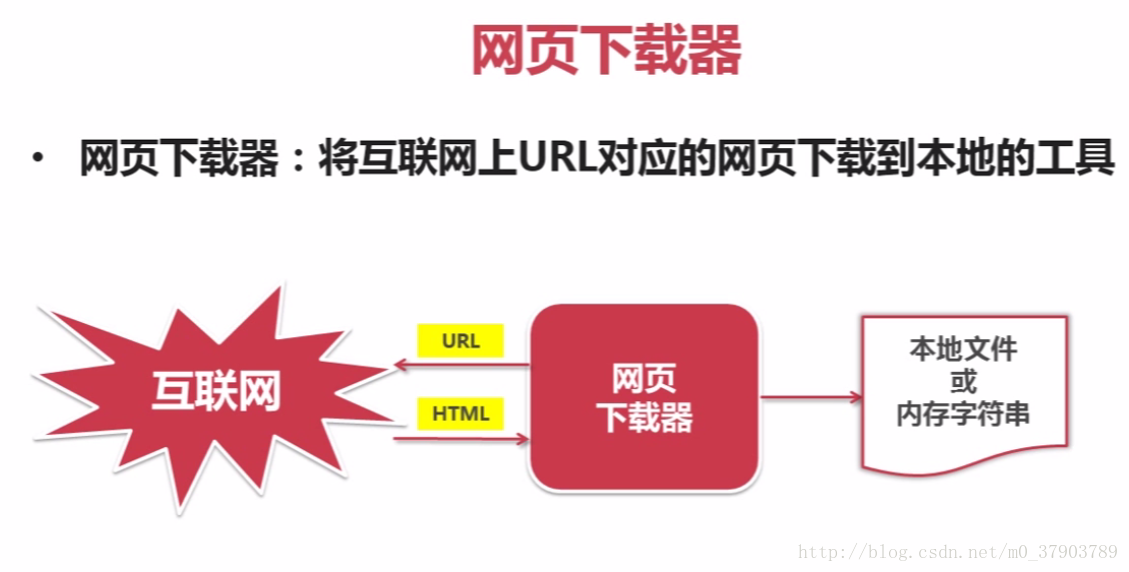
5.網頁下載器
所謂網頁下載器,即是將互聯網上URL對應的網頁下載到本地的工具
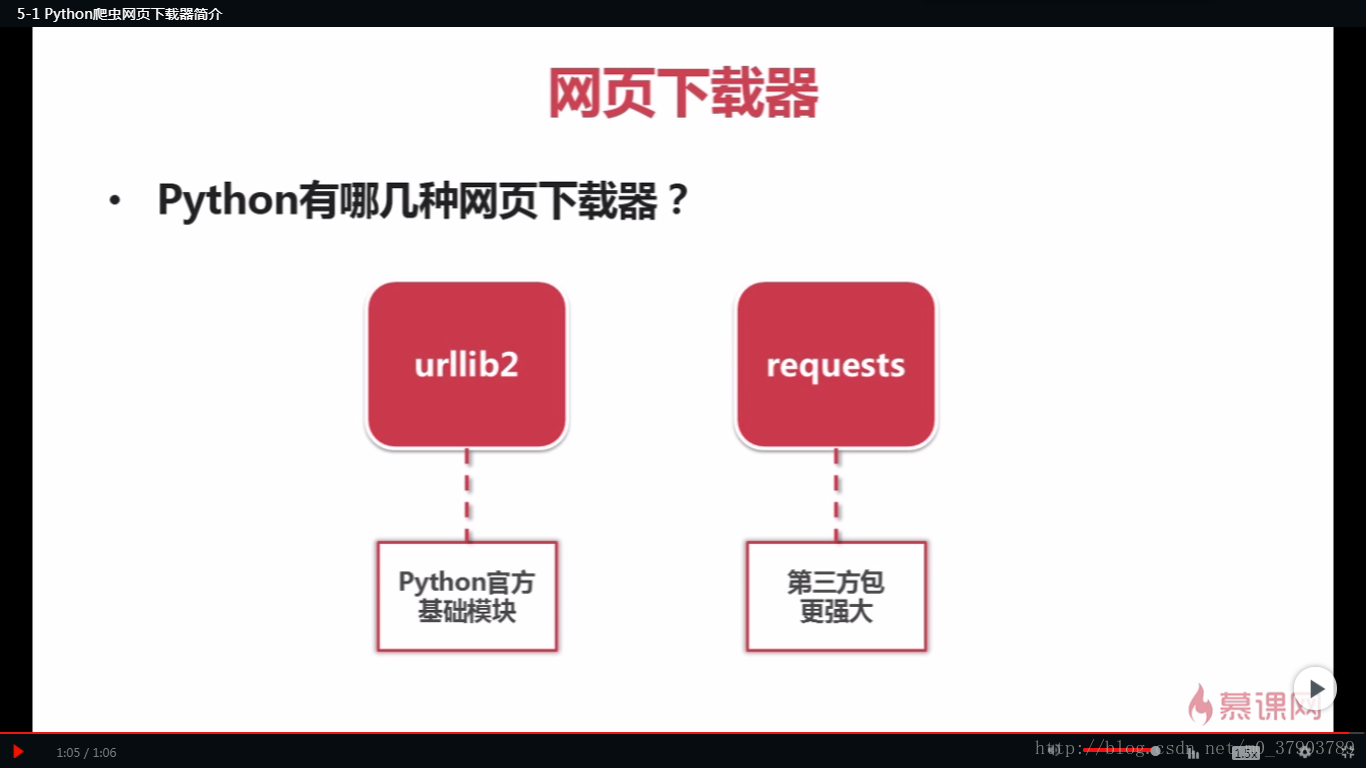
網頁下載器,大致為request和urllib2兩種;
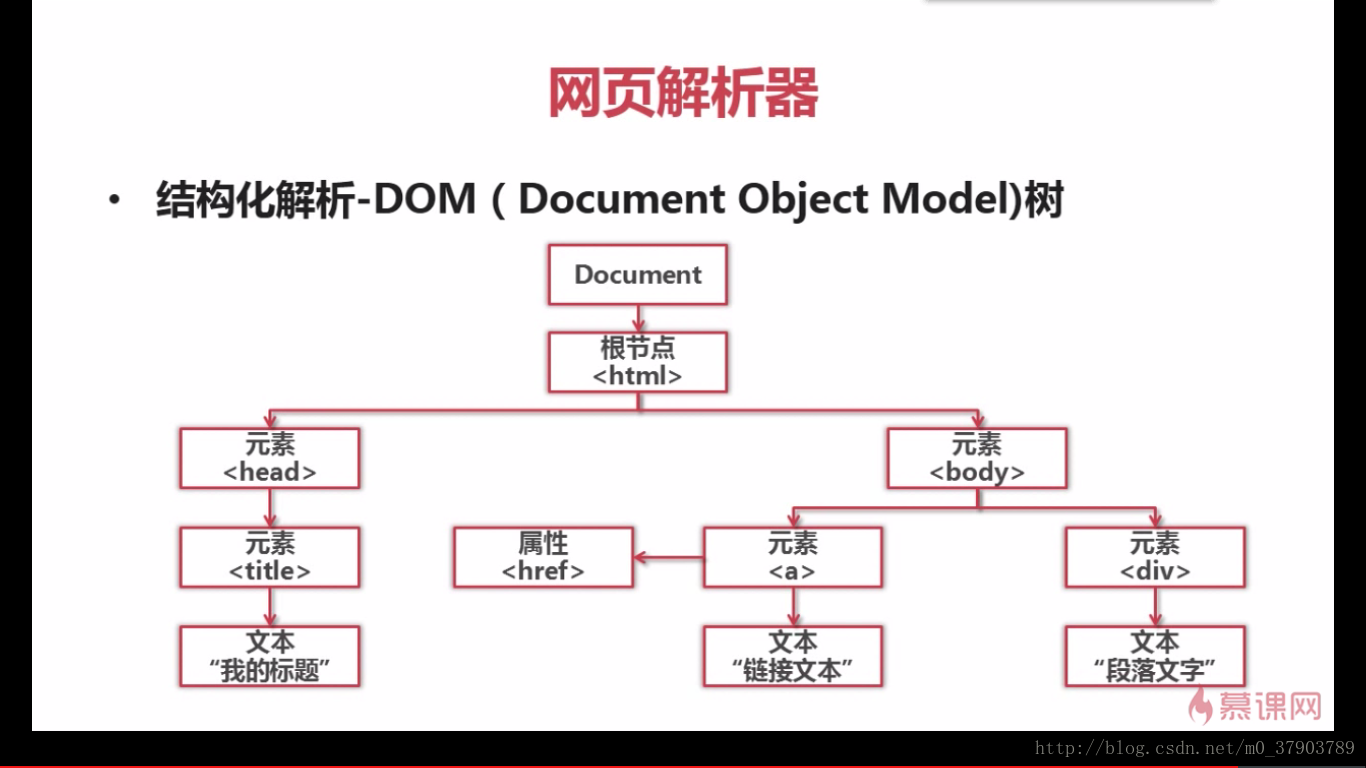
6.網頁解析器
什麽是網頁解析器?
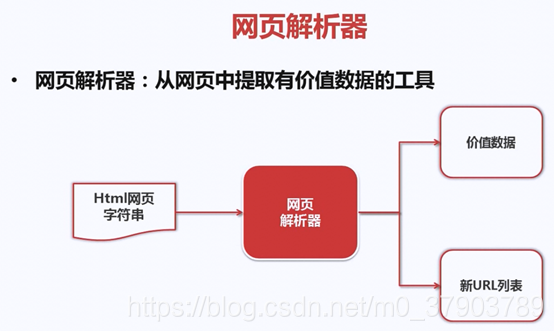
下面,我們來看看,如何解析一個網頁文件
解析器種類: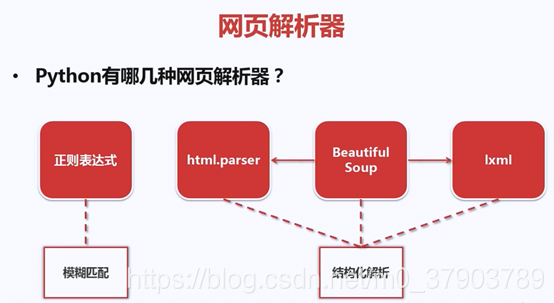
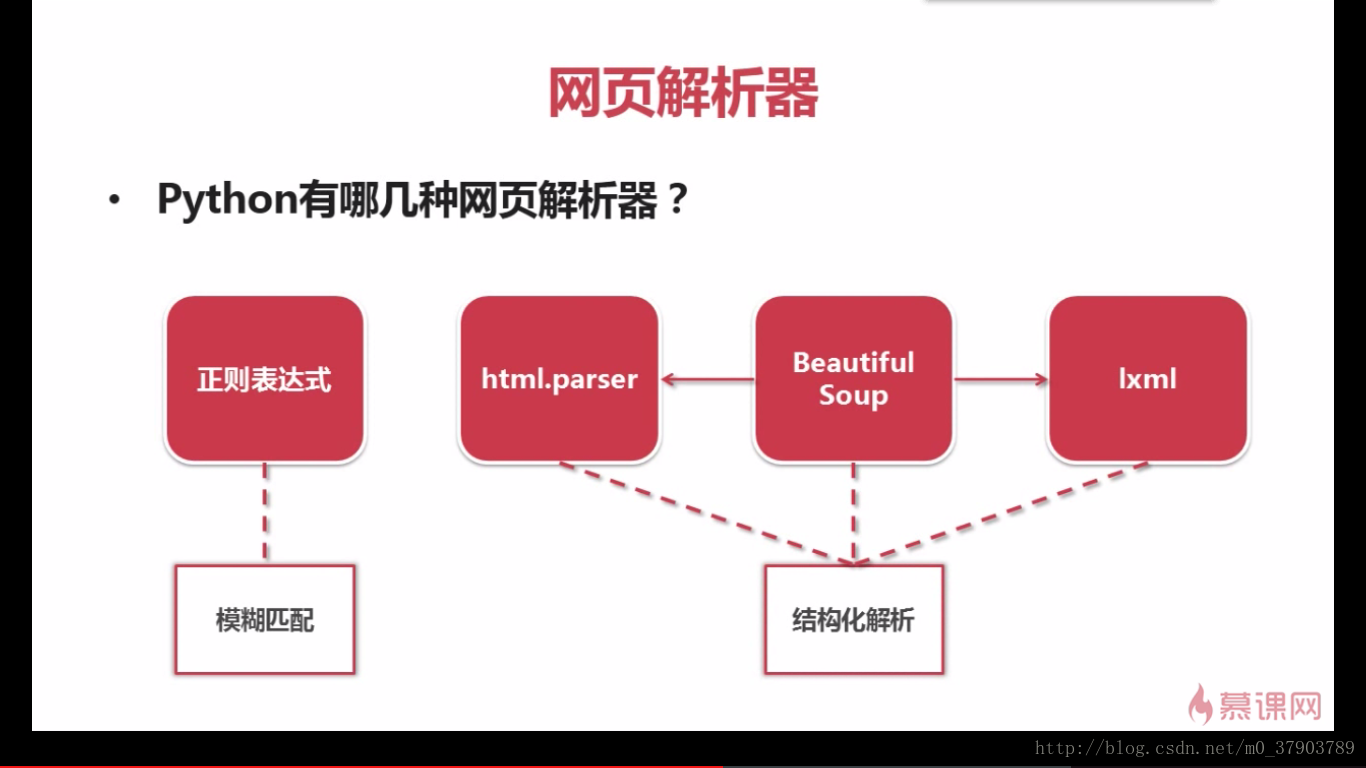
好了,通過以上的學習,我們掌握了Python爬蟲的簡單框架。那麽怎樣才能寫一個好的python爬蟲呢?又該如何去編寫代碼,實現我們的爬蟲功能呢?下一步又該如何優化我們的爬蟲代碼呢?
(轉)Python爬蟲--通用框架