
spark單機模式 和 叢集模式 安裝

1.spark單機模式安裝
實現步驟:
1)安裝和配置好JDK
2)上傳和解壓Spark安裝包
3)進入Spark安裝目錄下的conf目錄
複製conf spark-env.sh.template 檔案為 spark-env.sh
在其中修改,增加如下內容:
SPARK_LOCAL_IP=伺服器IP地址
Spark單機模式啟動
在bin目錄下執行:sh spark-shell --master=local
啟動後 發現列印訊息
Spark context Web UI available at http://localhost:4040//Spark的瀏覽器介面
看到這個頁面單機模式也就安裝成功了
2.叢集模式安裝
實現步驟:
1)上傳解壓spark安裝包
2)進入spark安裝目錄的conf目錄
3)配置spark-env.sh檔案
配置示例:
#本機ip地址
SPARK_LOCAL_IP=spark01
#spark的shuffle中間過程會產生一些臨時檔案,此項指定的是其存放目錄,不配置預設是在 /tmp目錄下
SPARK_LOCAL_DIRS=/home/software/spark/tmp
export JAVA_HOME=/home/software/jdk1.8
4)在conf目錄下,編輯slaves檔案
配置示例:
spark01
spark02
spark03
5)配置完後,將spark目錄傳送至其他節點,並更改對應的 SPARK_LOCAL_IP 配置
啟動叢集
1)如果你想讓 01 虛擬機器變為master節點,則進入01 的spark安裝目錄的sbin目錄
執行: sh start-all.sh
2)通過jps檢視各機器程序,
01:Master +Worker
02:Worker
03:Worker
3)通過瀏覽器訪問管理介面
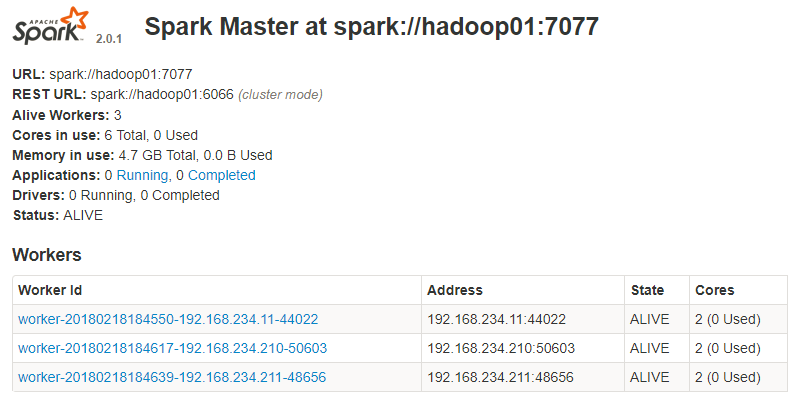
4)通過spark shell 連線spark叢集
進入spark的bin目錄
執行:sh spark-shell.sh --master spark://192.168.222.22:7077
6)在叢集中讀取檔案:
sc.textFile("/root/work/words.txt")
預設讀取本機資料 這種方式需要在叢集的每臺機器上的對應位置上都一份該檔案 浪費磁碟
7)所以應該通過hdfs儲存資料
sc.textFile("hdfs://hadoop01:9000/mydata/words.txt");
注:可以在spark-env.sh 中配置選項 HADOOP_CONF_DIR 配置為hadoop的etc/hadoop的地址 使預設訪問的是hdfs的路徑
注:如果修改預設地址是hdfs地址 則如果想要訪問檔案系統中的檔案 需要指明協議為file 例如 sc.t