
【論文翻譯】NIN層論文中英對照翻譯--(Network In Network)
【論文翻譯】NIN層論文中英對照翻譯--(Network In Network)
【開始時間】2018.09.27
【完成時間】2018.10.03
【論文翻譯】NIN層論文中英對照翻譯--(Network In Network)
【中文譯名】 網絡中的網絡
【論文鏈接】https://arxiv.org/abs/1312.4400
【補充】
1)NIN結構的caffe實現:
因為我們可以把全連接層當作為特殊的卷積層,所以呢, NIN在caffe中是非常 容易實現的:
https://github.com/BVLC/caffe/wiki/Model-Zoo#network-in-network-model
這是由BVLC(Berkeley Vision Learning Center)維護的一個caffe的各種model及訓練好的參數權值,可以直接下載下來用的;
2)NIN的第一個N指mlpconv,第二個N指整個深度網絡結構,即整個深度網絡是由多個mlpconv構成的。
3)論文的發表時間是: 4 Mar 2014

題目:網絡中的網絡
Abstract(摘要)
We propose a novel deep network structure called “Network In Network”(NIN) to enhance model discriminability for local patches within the receptive field. The conventional convolutional layer uses linear filters followed by a nonlinear activation function to scan the input. Instead, we build micro neural networks with more complex structures to abstract the data within the receptive field. We instantiate the micro neural network with a multilayer perceptron, which is a potent function approximator. The feature maps are obtained by sliding the micro networks over the input in a similar manner as CNN; they are then fed into the next layer. Deep NIN can be implemented by stacking mutiple of the above described structure. With enhanced local modeling via the micro network, we are able to utilize global average pooling over feature maps in the classification layer, which is easier to interpret and less prone to overfitting than traditional fully connected layers. We demonstrated the state-of-the-art classification performances with NIN on CIFAR-10 and CIFAR-100, and reasonable performances on SVHN and MNIST datasets.
我們提出了一種新的深層網絡結構-“網絡中的網絡”(NetworkinNetwork,nin),以提高接收域內局部區域的模型識別能力。傳統的卷積層采用線性濾波器和非線性增益函數對輸入進行掃描。作為替代的 ,我們建立了具有更復雜結構的微神經網絡來抽象接受域內的數據。我們用一個多層感知器實例化了微型神經網絡,它是一種強有效的函數逼近器。特征映射是通過將微網絡以類似於CNN的方式在輸入上滑動獲得的,然後將它們輸入到下一層。通過上述結構的多層疊加,可以實現深度nin。通過微網絡增強局部建模,我們能夠在分類層對特征圖進行全局平均池化,這比傳統的完全連接的圖層更容易解釋,也不太容易過擬合。 我們展示了NIN在CIFAR-10和CIFAR-100上得到了有史以來最佳的表現以及在SVHN和MNIST數據集上合理的表現。
1 Introduction(介紹)
Convolutional neural networks (CNNs) [1] consist of alternating convolutional layers and pooling layers. Convolution layers take inner product of the linear filter and the underlying receptive field followed by a nonlinear activation function at every local portion of the input. The resulting outputs are called feature maps.
卷積神經網絡(CNNs)[1]由交替的卷積層和匯聚層組成。卷積層在輸入的每個局部部分取線性濾波器和底層接收場的內積,然後是一個非線性激活函數。結果輸出稱為特征映射。
The convolution filter in CNN is a generalized linear model (GLM) for the underlying data patch,and we argue that the level of abstraction is low with GLM. By abstraction we mean that the feature is invariant to the variants of the same concept [2]. Replacing the GLM with a more potent nonlinear function approximator can enhance the abstraction ability of the local model. GLM can achieve a good extent of abstraction when the samples of the latent concepts are linearly separable,i.e. the variants of the concepts all live on one side of the separation plane defined by the GLM. Thus conventional CNN implicitly makes the assumption that the latent concepts are linearly separable. However, the data for the same concept often live on a nonlinear manifold, therefore the representations that capture these concepts are generally highly nonlinear function of the input. In NIN, the GLM is replaced with a ”micro network” structure which is a general nonlinear function approximator. In this work, we choose multilayer perceptron [3] as the instantiation of the micro network,which is a universal function approximator and a neural network trainable by back-propagation.
CNN的卷積濾波器是底層數據塊的廣義線性模型(generalized linear model )(GLM),而且我們認為它的抽象程度較低。抽象是指特征對同一概念的變體是不變的[2]。用更強(有效)的非線性函數逼近器代替GLM,可以提高局部模型的抽象能力。當樣本的隱含概念(latent concept)是線性可分時,GLM可以達到很好的抽象程度,例如:這些概念的變體都在GLM分割平面的同一邊。因此,傳統的CNN隱含地假設潛在的概念是線性可分的。然而,同一概念的數據通常是非線性流形的(nonlinear manifold),捕捉這些概念的表達通常都是輸入的高維非線性函數。在NIN中,用一種一般非線性函數逼近器的“微網絡結構”代替了GLM。在本文中,我們選擇多層感知器[3]作為微網絡的實例化,它是一種通用函數逼近器,是一個可通過反向傳播進行訓練的神經網絡。
The resulting structure which we call an mlpconv layer is compared with CNN in Figure 1. Both the linear convolutional layer and the mlpconv layer map the local receptive field to an output feature vector. The mlpconv maps the input local patch to the output feature vector with a multilayer perceptron (MLP) consisting of multiple fully connected layers with nonlinear activation functions. The MLP is shared among all local receptive fields. The feature maps are obtained by sliding the MLP over the input in a similar manner as CNN and are then fed into the next layer. The overall structure of the NIN is the stacking of multiple mlpconv layers. It is called “Network In Network” (NIN) as we have micro networks (MLP), which are composing elements of the overall deep network, within mlpconv layers.
我們稱之為mlpconv層的結果結構在圖1中與CNN進行了比較。線性卷積層和mlpconv層都將局部接收場映射到輸出特征向量。 mlpconv 層將局部塊( input local patch)的輸入通過一個由全連接層和非線性激活函數組成的多層感知器(MLP)映射到了輸出的特征向量。 MLP在所有局部感受野中共享。特征圖通過用像CNN一樣的方式在輸入上滑動MLP得到,NIN的總體結構是一系列mplconv層的堆疊。 它被稱為“網絡中的網絡”(NIN),因為我們有微型網絡(MLP),它在mlpconv層中構成整個深層網絡的組成部分。
Instead of adopting the traditional fully connected layers for classification in CNN, we directly output the spatial average of the feature maps from the last mlpconv layer as the confidence of categories via a global average pooling layer, and then the resulting vector is fed into the softmax layer. In traditional CNN, it is difficult to interpret how the category level information from the objective cost layer is passed back to the previous convolution layer due to the fully connected layers which act as a black box in between. In contrast, global average pooling is more meaningful and interpretable as it enforces correspondance between feature maps and categories, which is made possible by a stronger local modeling using the micro network. Furthermore, the fully connected layers are prone to overfitting and heavily depend on dropout regularization [4] [5], while global average pooling is itself a structural regularizer, which natively prevents overfitting for the overall structure.
我們不采用在CNN中傳統的完全連通層進行分類,而是通過全局平均池層(global average pooling layer)直接輸出最後一個mlpconv層的特征映射的空間平均值作為類別的可信度,然後將得到的向量輸入到Softmax層。 在傳統的CNN中,很難解釋如何將來自分類層(objective cost layer)的分類信息傳遞回前一個卷積層,因為全連接層像一個黑盒一樣。相反,全局平均池更有意義和可解釋,因為它強制特征映射和類別之間的對應,這是通過使用微型網絡進行更強的局部建模而實現的。此外,完全連接層容易過度擬合,嚴重依賴於Dropout正則化[4][5],而全局平均池本身就是一個結構正則化,這在本質上防止了對整體結構的過度擬合。
2 Convolutional Neural Networks(卷積神經網絡)
Classic convolutional neuron networks [1] consist of alternatively stacked convolutional layers and spatial pooling layers. The convolutional layers generate feature maps by linear convolutional filters followed by nonlinear activation functions (rectifier, sigmoid, tanh, etc.). Using the linear rectifier as an example, the feature map can be calculated as follows:
經典卷積神經元網絡[1]由交替疊加的卷積層和空間匯聚層組成。卷積層通過線性卷積濾波器和非線性激活函數(整流器(rectifier)、Sigmoid、tanh等)生成特征映射。以線性整流器為例,可以按以下方式計算特征圖:
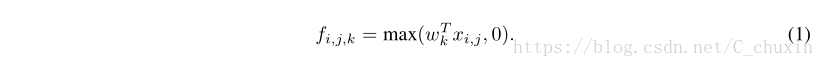
Here (i,j) is the pixel index in the feature map, x ij stands for the input patch centered at location(i,j), and k is used to index the channels of the feature map.
這裏的(i, j)是特征圖像素的索引,xij代表以位置(i, j)為中心的輸入塊,k用來索引特征圖的顏色通道。
This linear convolution is sufficient for abstraction when the instances of the latent concepts are linearly separable. However, representations that achieve good abstraction are generally highly non-linear functions of the input data. In conventional CNN, this might be compensated by utilizing an over-complete set of filters [6] to cover all variations of the latent concepts. Namely, individual linear filters can be learned to detect different variations of a same concept. However, having too many filters for a single concept imposes extra burden on the next layer, which needs to consider all combinations of variations from the previous layer [7]. As in CNN, filters from higher layers map to larger regions in the original input. It generates a higher level concept by combining the lower level concepts from the layer below. Therefore, we argue that it would be beneficial to do a better abstraction on each local patch, before combining them into higher level concepts.
當隱性概念( the latent concepts )的實例是線性可分的時,這種線性卷積就足以進行抽象。然而,實現良好抽象的表示通常是輸入數據的高度非線性函數。 在傳統的CNN中,這可以通過利用一套完整的濾波器來彌補,覆蓋所有隱含概念的變化。也就是說,可以學習獨立的線性濾波器來檢測同一概念的不同變化。然而,對單個概念有太多的過濾器會給下一層帶來額外的負擔,(因為)下一層需要考慮上一層的所有變化組合[7]。在CNN中, 來自更高層的濾波器會映射到原始輸入的更大區域。它通過結合下面層中的較低級別概念來生成更高級別的概念。因此,我們認為,在將每個本地塊(local patch)合並為更高級別的概念之前,對每個本地快進行更好的抽象是有益的。
In the recent maxout network [8], the number of feature maps is reduced by maximum pooling over affine feature maps (affine feature maps are the direct results from linear convolution without applying the activation function). Maximization over linear functions makes a piecewise linear approximator which is capable of approximating any convex functions. Compared to conventional convolutional layers which perform linear separation, the maxout network is more potent as it can
separate concepts that lie within convex sets. This improvement endows the maxout network with the best performances on several benchmark datasets.
在最近的Maxout網絡[8]中,特征映射的數目通過仿射特征映射上的最大池來減少(仿射特征映射是線性卷積不應用激活函數的直接結果)。線性函數的極大化使分段線性逼近器( piecewise linear approximator)能夠逼近任意凸函數。與進行線性分離的傳統卷積層相比,最大輸出網絡更強大,因為它能夠分離凸集中的概念。 這種改進使maxout網絡在幾個基準數據集上有最好的表現。
However, maxout network imposes the prior that instances of a latent concept lie within a convex set in the input space, which does not necessarily hold. It would be necessary to employ a more general function approximator when the distributions of the latent concepts are more complex. We seek to achieve this by introducing the novel “Network In Network” structure, in which a micro network is introduced within each convolutional layer to compute more abstract features for local patches.
但是,Maxout網絡強制要求潛在概念的實例存在於輸入空間中的凸集中,這並不一定成立。當隱性概念的分布更加復雜時,需要使用更一般的函數逼近器。我們試圖通過引入一種新穎的“Network In Network”結構來實現這一目標,即在每個卷積層中引入一個微網絡來計算局部塊的更抽象的特征。
Sliding a micro network over the input has been proposed in several previous works. For example, the Structured Multilayer Perceptron (SMLP) [9] applies a shared multilayer perceptron on different patches of the input image; in another work, a neural network based filter is trained for face detection[10]. However, they are both designed for specific problems and both contain only one layer of the sliding network structure. NIN is proposed from a more general perspective, the micro network is integrated into CNN structure in persuit of better abstractions for all levels of features.
在以前的一些工作中,已經提出了在輸入端滑動一個微網絡。例如,結構化多層感知器(SMLP)[9]在輸入圖像的不同塊上應用共享多層感知器;在另一項工作中,基於神經網絡的濾波器被訓練用於人臉檢測[10]。然而,它們都是針對特定的問題而設計的,而且都只包含一層滑動網絡結構。NIN是從更一般的角度提出的,將微網絡集成到CNN結構中,對各個層次的特征進行更好的抽象。
3 Network In Network(網絡中的網絡)
We first highlight the key components of our proposed “Network In Network” structure: the MLP convolutional layer and the global averaging pooling layer in Sec. 3.1 and Sec. 3.2 respectively.Then we detail the overall NIN in Sec. 3.3.
我們首先強調了我們提出的“網絡中的網絡”結構的關鍵組成部分:MLP卷積層和全局平均池層分別在3.1節和3.2節中。然後我們在3.3節中詳細描述整個nin。
3.1 MLP Convolution Layers(MLP卷積層)
Given no priors about the distributions of the latent concepts, it is desirable to use a universal function approximator for feature extraction of the local patches, as it is capable of approximating more abstract representations of the latent concepts. Radial basis network and multilayer perceptron are two well known universal function approximators. We choose multilayer perceptron in this work for two reasons. First, multilayer perceptron is compatible with the structure of convolutional neural networks, which is trained using back-propagation. Second, multilayer perceptron can be a deep model itself, which is consistent with the spirit of feature re-use [2]. This new type of layer is called mlpconv in this paper, in which MLP replaces the GLM to convolve over the input. Figure1 illustrates the difference between linear convolutional layer and mlpconv layer. The calculation performed by mlpconv layer is shown as follows:
由於沒有關於潛在概念分布的先驗信息,使用通用函數逼近器來提取局部塊的特征是可取的,因為它能夠逼近潛在概念的更抽象的表示。徑向基網絡和多層感知器是兩種著名的通用函數逼近器。我們在這項工作中選擇多層感知器有兩個原因。首先,多層感知器與采用反向傳播訓練的卷積神經網絡的結構兼容;第二,多層感知器本身可以是一個深層次的模型,這與特征重用的精神是一致的[2]。在本文中,這種新型的層稱為mlpconv,其中MLP取代GLM,在輸入上進行轉換。圖1說明了線性卷積層和mlpconv層之間的區別。由mlpconv層執行的計算如下:
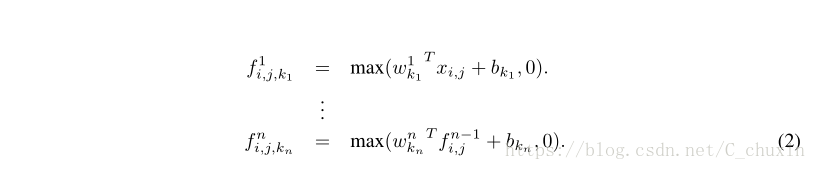
Here n is the number of layers in the multilayer perceptron. Rectified linear unit is used as the activation function in the multilayer perceptron.
這裏n是多層感知器中的層數。在多層感知器中,采用整流線性單元作為激活函數。

圖1、線性卷積層與mlpconv層的比較。線性卷積層包括線性濾波器,而mlpconv層包含微網絡(本文選擇了多層感知器)。這兩層都將局部接受域映射為隱性概念的置信度值。
From cross channel (cross feature map) pooling point of view, Equation 2 is equivalent to cascaded cross channel parametric pooling on a normal convolution layer. Each pooling layer performs weighted linear recombination on the input feature maps, which then go through a rectifier linear unit. The cross channel pooled feature maps are cross channel pooled again and again in the next layers. This cascaded cross channel parameteric pooling structure allows complex and learnable interactions of cross channel information.
從跨信道(跨特征圖--cross feature map)池的角度看,方程2等價於正規卷積層上的級聯跨信道參數池( cascaded cross channel parametric pooling)。每個池層對輸入特征映射執行加權線性重組,然後通過整流線性單元。跨通道池功能映射在下一層中一次又一次地跨通道池。這種級聯的跨信道參數池結構允許復雜且可學習的交叉信道信息交互。
The cross channel parametric pooling layer is also equivalent to a convolution layer with 1x1 convolution kernel. This interpretation makes it straightforawrd to understand the structure of NIN.
跨信道參數池層也等價於具有1x1卷積核的卷積層。這一解釋使得理解nin的結構更為直觀。
Comparison to maxout layers: the maxout layers in the maxout network performs max pooling across multiple affine feature maps [8]. The feature maps of maxout layers are calculated as follows:
與maxout層的比較:maxout網絡中的maxout層跨多個仿射特征映射執行max池化[8]。最大層的特征圖計算如下:

Maxout over linear functions forms a piecewise linear function which is capable of modeling any convex function. For a convex function, samples with function values below a specific threshold form a convex set. Therefore, by approximating convex functions of the local patch, maxout has the capability of forming separation hyperplanes for concepts whose samples are within a convex set (i.e. l 2 balls, convex cones). Mlpconv layer differs from maxout layer in that the convex function approximator is replaced by a universal function approximator, which has greater capability in modeling various distributions of latent concepts.
線性函數上的極大值形成一個分段線性函數,它能夠建模任何凸函數。對於凸函數,函數值低於特定閾值的樣本構成凸集。因此,通過逼近局部塊的凸函數,maxout對樣本位於凸集(即L2球、凸錐)的概念具有形成分離超平面的能力。mlpconv層與maxout層的不同之處在於,凸函數逼近器被一個通用函數逼近器所代替,它在建模各種隱性概念分布方面具有更強的能力。
3.2 Global Average Pooling(全球平均池化)
Conventional convolutional neural networks perform convolution in the lower layers of the network.For classification, the feature maps of the last convolutional layer are vectorized and fed into fully connected layers followed by a softmax logistic regression layer [4] [8] [11]. This structure bridges the convolutional structure with traditional neural network classifiers. It treats the convolutional layers as feature extractors, and the resulting feature is classified in a traditional way.
傳統的卷積神經網絡在網絡的底層進行卷積。在分類方面,將上一卷積層的特征映射矢量化,並將其輸入到完全連通的層中,然後是Softmax Logistic回歸層[4][8][11]。該結構將卷積結構與傳統的神經網絡分類器連接起來。它將卷積層作為特征提取器,並對生成的特征進行傳統的分類。
However, the fully connected layers are prone to overfitting, thus hampering the generalization ability of the overall network. Dropout is proposed by Hinton et al. [5] as a regularizer which randomly sets half of the activations to the fully connected layers to zero during training. It has improved the generalization ability and largely prevents overfitting [4].
然而,全連通層容易過度擬合,從而阻礙了整個網絡的泛化能力。Dropout是由Hinton等人提出的[5]。它作為一個正則化,在訓練期間隨機地將半個完全連接的層的激活設置為零。它提高了泛化能力,在很大程度上防止了過度擬合[4]。
In this paper, we propose another strategy called global average pooling to replace the traditional fully connected layers in CNN. The idea is to generate one feature map for each corresponding category of the classification task in the last mlpconv layer. Instead of adding fully connected layers on top of the feature maps, we take the average of each feature map, and the resulting vector is fed directly into the softmax layer. One advantage of global average pooling over the fully connected layers is that it is more native to the convolution structure by enforcing correspondences between feature maps and categories.Thus the feature maps can be easily interpreted as categories confidence maps. Another advantage is that there is no parameter to optimize in the global average pooling thus overfitting is avoided at this layer. Futhermore, global average pooling sums out the spatial information, thus it is more robust to spatial translations of the input.
在本文中,我們提出了另一種策略,稱為全局平均池,以取代CNN中傳統的全連通層。其思想是為最後一個mlpconv層中的分類任務的每個對應類別生成一個特征映射。我們沒有在特征映射的頂部添加完全連通的層,而是取每個特征映射的平均值,並將得到的向量直接輸入到Softmax層。全局平均池取代完全連通層上的一個優點是,通過增強特征映射和類別之間的對應關系,它更適合於卷積結構。因此,特征映射可以很容易地解釋為類別信任映射。另一個優點是在全局平均池中沒有優化參數,從而避免了這一層的過度擬合。此外,全局平均池綜合了空間信息,從而對輸入的空間平移具有更強的魯棒性。
We can see global average pooling as a structural regularizer that explicitly enforces feature maps to be confidence maps of concepts (categories). This is made possible by the mlpconv layers, as they makes better approximation to the confidence maps than GLMs.
我們可以看到全局平均池是一個結構正則化器,它顯式地將特征映射強制為概念(類別)的信任映射。這是由mlpconv層實現的,因為它們比GLMS更接近置信度圖。
3.3 Network In Network Structure(網絡的網絡結構)
The overall structure of NIN is a stack of mlpconv layers, on top of which lie the global average pooling and the objective cost layer. Sub-sampling layers can be added in between the mlpconv layers as in CNN and maxout networks. Figure 2 shows an NIN with three mlpconv layers. Within each mlpconv layer, there is a three-layer perceptron. The number of layers in both NIN and the micro networks is flexible and can be tuned for specific tasks.
NIN的總體結構是一個由mlpconv層組成的堆棧,上面是全局平均池和目標成本層。在mlpconv 層之間可以添加下采樣層,如cnn和maxout網絡中的那樣。圖2顯示了一個包含三個mlpconv層的nin。在每個mlpconv層中,有一個三層感知器。NIN和微網絡中的層數都是靈活的,可以根據特定的任務進行調整。

圖2:網絡中網絡的總體結構。在本文中,NINS包括三個mlpconv層和一個全局平均池層的疊加。
4 Experiments(實驗)
4.1 Overview(概觀)
We evaluate NIN on four benchmark datasets: CIFAR-10 [12], CIFAR-100 [12], SVHN [13] and MNIST [1]. The networks used for the datasets all consist of three stacked mlpconv layers, and the mlpconv layers in all the experiments are followed by a spatial max pooling layer which downsamples the input image by a factor of two. As a regularizer, dropout is applied on the outputs of all but the last mlpconv layers. Unless stated specifically, all the networks used in the experiment sec-
tion use global average pooling instead of fully connected layers at the top of the network. Another regularizer applied is weight decay as used by Krizhevsky et al. [4]. Figure 2 illustrates the overall structure of NIN network used in this section. The detailed settings of the parameters are provided in the supplementary materials. We implement our network on the super fast cuda-convnet code developed by Alex Krizhevsky [4]. Preprocessing of the datasets, splitting of training and validation
sets all follow Goodfellow et al. [8].
我們對四個基準數據集進行了評估:CIFAR-10[12]、CIFAR-100[12]、Svhn[13]和Mnist[1]。用於數據集的網絡都由三個層疊的mlpconv層組成,所有實驗中的mlpconv層隨後都是一個空間最大池層,它對輸入圖像進行二倍的向下采樣。作為正則化器,除最後一個mlpconv層外,所有輸出都應用了Dropout。除非具體說明,實驗部分中使用的所有網絡都使用全局平均池,而不是網絡頂部完全連接的層。另一個應用的正則化方法是Krizhevsky等人使用的權重衰減[4]。圖2說明了本節中使用的nin網絡的總體結構。補充材料中提供了詳細的參數設置。我們在AlexKrizhevsky[4]開發的超快Cuda-ConvNet代碼上實現我們的網絡。據集的預處理、訓練和驗證集的分割都遵循GoodFelt等人的觀點[8]。
We adopt the training procedure used by Krizhevsky et al. [4]. Namely, we manually set proper initializations for the weights and the learning rates. The network is trained using mini-batches of size 128. The training process starts from the initial weights and learning rates, and it continues until the accuracy on the training set stops improving, and then the learning rate is lowered by a scale of 10. This procedure is repeated once such that the final learning rate is one percent of the
initial value.
我們采用Krizhevsky等人使用的訓練過程[4]。也就是說,我們手動設置適當的初始化權值和學習率。該網絡是使用規模為128的小型批次進行訓練的。訓練過程從初始權重和學習率開始,一直持續到訓練集的準確性停止提高,然後學習率降低10。這個過程被重復一次,(因此)最終的學習率是初始值的百分之一。
4.2 CIFAR-10
The CIFAR-10 dataset [12] is composed of 10 classes of natural images with 50,000 training images in total, and 10,000 testing images. Each image is an RGB image of size 32x32. For this dataset, we apply the same global contrast normalization and ZCA whitening as was used by Goodfellow et al. in the maxout network [8]. We use the last 10,000 images of the training set as validation data.
CIFAR-10數據集[12]由10類自然圖像組成,總共有50000幅培訓圖像和10000幅測試圖像。每個圖像都是大小為32x32的RGB圖像。對於這個數據集,我們應用了古德費羅等人使用的相同的全局對比規範化和ZCA白化(global contrast normalization and ZCA whitening)。我們使用最後10000張培訓集的圖像作為驗證數據。
The number of feature maps for each mlpconv layer in this experiment is set to the same number as in the corresponding maxout network. Two hyper-parameters are tuned using the validation set, i.e. the local receptive field size and the weight decay. After that the hyper-parameters are fixed and we re-train the network from scratch with both the training set and the validation set. The resulting model is used for testing. We obtain a test error of 10.41% on this dataset, which improves more than one percent compared to the state-of-the-art. A comparison with previous methods is shown in Table 1.
本實驗中每個mlpconv層的特征映射數被設置為與相應的maxout網絡中相同的數目。使用驗證集對兩個超參數進行了調整,即局部接收場大小和權重衰減(the local receptive field size and the weight decay)。在此之後,超參數是固定的,我們用訓練集和驗證集從零開始對網絡進行重新訓練。結果模型用於測試。在此數據集上,我們獲得了10.41%的測試誤差,與最新的數據集相比,測試誤差提高了1%以上。與以往方法的比較見表1。

It turns out in our experiment that using dropout in between the mlpconv layers in NIN boosts the performance of the network by improving the generalization ability of the model. As is shown in Figure 3, introducing dropout layers in between the mlpconv layers reduced the test error by
more than 20%. This observation is consistant with Goodfellow et al. [8]. Thus dropout is added in between the mlpconv layers to all the models used in this paper. The model without dropout regularizer achieves an error rate of 14.51% for the CIFAR-10 dataset, which already surpasses many previous state-of-the-arts with regularizer (except maxout). Since performance of maxout without dropout is not available, only dropout regularized version are compared in this paper.
實驗結果表明,通過提高模型的泛化能力,NIN中的MLpconv層之間使用Dropout可以提高網絡的性能。如圖3所示,在mlpconv層間引用dropout層錯誤率減少了20%多。這一結果與Goodfellow等人的一致,所以本文的所有模型mlpconv層間都加了dropout。沒有dropout的模型在CIFAR-10數據集上錯誤率是14.5%,已經超過之前最好的使用正則化的模型(除了maxout)。由於沒有dropout的maxout網絡不可靠,所以本文只與有dropout正則器的版本比較。

圖3:在mlpconv層之間Dropout的正則化效果。給出了前200次訓練中有無輟學的nin的訓練和測試誤差。
To be consistent with previous works, we also evaluate our method on the CIFAR-10 dataset with translation and horizontal flipping augmentation. We are able to achieve a test error of 8.81%, which sets the new state-of-the-art performance.
為了與以前的工作相一致,我們還對CIFAR-10數據集的平移和水平翻轉增強的方法進行了評估。我們可以達到8.81%的測試誤差,這就達到了新的最先進的性能。
4.3 CIFAR-100
The CIFAR-100 dataset [12] is the same in size and format as the CIFAR-10 dataset, but it contains 100 classes. Thus the number of images in each class is only one tenth of the CIFAR-10 dataset. For CIFAR-100 we do not tune the hyper-parameters, but use the same setting as the CIFAR-10 dataset. The only difference is that the last mlpconv layer outputs 100 feature maps. A test error of 35.68% is obtained for CIFAR-100 which surpasses the current best performance without data augmentation by more than one percent. Details of the performance comparison are shown in Table 2.
CIFAR-100數據集[12]的大小和格式與CIFAR-10數據集相同,但它包含100個類。因此,每個類中的圖像數量僅為CIFAR-10數據集的十分之一。對於CIFAR-100,我們不調優超參數,而是使用與CIFAR-10數據集相同的設置。唯一的區別是最後一個mlpconv層輸出100個功能映射。CIFAR-100的測試誤差為35.68%,在不增加數據的情況下,其性能優於目前的最佳性能。CIFAR-100的測試誤差為35.68%,在不增加數據的情況下,其性能優於目前的最佳性能。

4.4 Street View House Numbers(街景房號)
The SVHN dataset [13] is composed of 630,420 32x32 color images, divided into training set, testing set and an extra set. The task of this data set is to classify the digit located at the center of each image. The training and testing procedure follow Goodfellow et al. [8]. Namely 400 samples per class selected from the training set and 200 samples per class from the extra set are used for validation. The remainder of the training set and the extra set are used for training. The validation
set is only used as a guidance for hyper-parameter selection, but never used for training the model.
SVHN數據集[13]由630420張32x32彩色圖像組成,分為訓練集、測試集和額外集。該數據集的任務是對位於每幅圖像中心的數字進行分類。訓練和測試程序遵循古德費羅等人的要求[8]。也就是說,從訓練集中選擇的每類400個樣本和從額外集合中選出的每類200個樣本用於驗證。訓練集的其余部分和額外集用於培訓。驗證集僅用作超參數選擇的指導,而從未用於模型的訓練。
Preprocessing of the dataset again follows Goodfellow et al. [8], which was a local contrast normalization. The structure and parameters used in SVHN are similar to those used for CIFAR-10, which consist of three mlpconv layers followed by global average pooling. For this dataset, we obtain a test error rate of 2.35%. We compare our result with methods that did not augment the data, and the comparison is shown in Table 3.
數據集的預處理也同Goodfellow[8],即使用局部對比度歸一化(local contrast normalization)。Svhn中使用的結構和參數類似於CIFAR-10的結構和參數,也是由三個mlpconv層和之後的全局平均池組成。 我們在這個數據集上得到2.35%的錯誤率。我們將結果與其他沒有做數據增強的方法結果進行比較,如表3所示。

4.5 MNIST
The MNIST [1] dataset consists of hand written digits 0-9 which are 28x28 in size. There are 60,000 training images and 10,000 testing images in total. For this dataset, the same network structure as used for CIFAR-10 is adopted. But the numbers of feature maps generated from each mlpconv layer are reduced. Because MNIST is a simpler dataset compared with CIFAR-10; fewer parameters are needed. We test our method on this dataset without data augmentation. The result is compared with previous works that adopted convolutional structures, and are shown in Table 4.
MNIST[1]數據集由大小為28x28的手寫數字0-9組成。共有6萬張培訓圖像和1萬張測試圖像。對於這個數據集,采用了與CIFAR-10相同的網絡結構.但是,從每個mlpconv層生成的特征映射的數量減少了。因為mnist是一個比CIFAR-10更簡單的數據集,所以需要更少的參數。我們在這個數據集上測試我們的方法而不增加數據。計算結果與以往采用卷積結構的工作結果進行了比較,如表4所示。

We achieve comparable but not better performance (0.47%) than the current best (0.45%) since MNIST has been tuned to a very low error rate.
我們得到了0.47%的表現,但是沒有當前最好的0.45%好,因為MNIST的錯誤率已經非常低了。
4.6 Global Average Pooling as a Regularizer(作為正則化者的全局平均池)
Global average pooling layer is similar to the fully connected layer in that they both perform linear transformations of the vectorized feature maps. The difference lies in the transformation matrix. For global average pooling, the transformation matrix is prefixed and it is non-zero only on block diagonal elements which share the same value. Fully connected layers can have dense transformation matrices and the values are subject to back-propagation optimization. To study the regularization effect of global average pooling, we replace the global average pooling layer with a fully connected layer, while the other parts of the model remain the same. We evaluated this model with and without dropout before the fully connected linear layer. Both models are tested on the CIFAR-10 dataset,
and a comparison of the performances is shown in Table 5.
全局平均池層與完全連接層相似,因為它們都執行矢量化特征映射的線性轉換。差別在於變換矩陣。對於全局平均池,變換矩陣是前綴的( prefixed), 並且僅在共享相同值的塊對角線元素上是非零的。完全連通的層可以有密集的變換矩陣,並且這些值要經過反向傳播優化。為了研究全局平均池的正則化效應,我們將全局平均池層替換為完全連通層,而模型的其他部分保持不變。為了研究全局平均池的正則化效應,我們將全局平均池層替換為完全連通層,而模型的其他部分保持不變。這兩種模型都在CIFAR-10數據集上進行了測試,性能比較見表5。

As is shown in Table 5, the fully connected layer without dropout regularization gave the worst performance (11.59%). This is expected as the fully connected layer overfits to the training data if no regularizer is applied. Adding dropout before the fully connected layer reduced the testing error(10.88%). Global average pooling has achieved the lowest testing error (10.41%) among the three.
如表5所示,全連接層沒有dropout的表現最差,11.59%,與預期一樣,全連接層沒有正則化器會過擬合。在完全連接層之前增加dropout,降低了測試誤差(10.88%)。全局平均池的測試誤差最低(10.41%)。
We then explore whether the global average pooling has the same regularization effect for conventional CNNs. We instantiate a conventional CNN as described by Hinton et al. [5], which consists of three convolutional layers and one local connection layer. The local connection layer generates 16 feature maps which are fed to a fully connected layer with dropout. To make the comparison fair, we reduce the number of feature map of the local connection layer from 16 to 10, since only one feature map is allowed for each category in the global average pooling scheme. An equivalent network with global average pooling is then created by replacing the dropout + fully connected layer with global average pooling. The performances were tested on the CIFAR-10 dataset.
接著,我們探討全局平均池是否對常規CNN具有相同的正則化效果。我們實例化了傳統的CNN,如Hinton等人所描述的[5],由三個卷積層和一個局部連接層組成。局部連接層(local connection layer)生成16個特征映射,這些特征映射被饋送給一個完全連接的具有dropout的層。為了使比較公平,我們將本地連接層的特征映射從16減少到10,因為在全局平均池方案中,每個類別只允許一個特征映射。然後,通過用全局平均池替換掉完全連接的層,創建具有全局平均池的等效網絡。在CIFAR-10數據集上進行了性能測試。
This CNN model with fully connected layer can only achieve the error rate of 17.56%. When dropout is added we achieve a similar performance (15.99%) as reported by Hinton et al. [5]. By replacing the fully connected layer with global average pooling in this model, we obtain the error rate of 16.46%, which is one percent improvement compared with the CNN without dropout. It again verifies the effectiveness of the global average pooling layer as a regularizer. Although it is
slightly worse than the dropout regularizer result, we argue that the global average pooling might be too demanding for linear convolution layers as it requires the linear filter with rectified activation to model the confidence maps of the categories.
這種全連通層CNN模型的誤碼率僅為17.56%。當加入Dropout時,我們實現了類似的性能(15.99%),正如Hinton等人所報告的[5]。在該模型中,用全局平均池代替完全連通層,我們得到了16.46%的誤差率,與無Dropout的CNN相比,誤差提高了1%。再次驗證了全局平均池層作為正則化層的有效性。雖然它略差於退出正則化結果,但我們認為對於線性卷積層來說,全局平均池可能要求過高,因為它需要經過修正激活的線性濾波器來建模類別的置信圖。
4.7 Visualization of NIN(NIN可視化)
We explicitly enforce feature maps in the last mlpconv layer of NIN to be confidence maps of the categories by means of global average pooling, which is possible only with stronger local receptive field modeling, e.g. mlpconv in NIN. To understand how much this purpose is accomplished, we extract and directly visualize the feature maps from the last mlpconv layer of the trained model for CIFAR-10.
我們在nin的最後一個mlpconv層顯式地執行特征映射,通過全局平均池將其作為類別的置信度映射,這只有通過更強的局部接受域建模(如nin中的mlpconv)才能實現。為了了解這一目的實現程度,我們從CIFAR-10訓練模型的最後一個mlpconv層中提取並直接可視化了特征映射。
Figure 4 shows some examplar images and their corresponding feature maps for each of the ten categories selected from CIFAR-10 test set. It is expected that the largest activations are observed in the feature map corresponding to the ground truth category of the input image, which is explicitly enforced by global average pooling. Within the feature map of the ground truth category, it can be observed that the strongest activations appear roughly at the same region of the object in the original image. It is especially true for structured objects, such as the car in the second row of Figure 4. Note that the feature maps for the categories are trained with only category information. Better results are expected if bounding boxes of the objects are used for fine grained labels.
圖4顯示了從CIFAR-10測試集中選擇的10個類別中的每個類別的一些示例圖像及其相應的特征圖。預期最大的激活(activations )是在對應於輸入圖像的地面真相類別( the ground truth category)的特征圖中觀察到的,這是通過全局平均池顯式執行的。在地面真實類別的特征圖中,可以觀察到最強烈的激活出現在原始圖像中物體的同一區域。對於結構化對象尤其如此,例如圖4第二行中的CAR。請註意,類別的特征映射僅使用類別信息進行訓練。如果使用對象的包圍框作為細粒度標簽,則期望得到更好的結果。
The visualization again demonstrates the effectiveness of NIN. It is achieved via a stronger local receptive field modeling using mlpconv layers. The global average pooling then enforces the learning of category level feature maps. Further exploration can be made towards general object detection.Detection results can be achieved based on the category level feature maps in the same flavor as in the scene labeling work of Farabet et al. [20].
可視化再次證明了nin的有效性。它是通過使用mlpconv層進行更強的局部接收場建模來實現的。然後,全局平均池強制學習類別級特征圖。之後,可以對一般的目標檢測做進一步的探索。檢測結果可以基於與Farabet等人的場景標記工作相同的類別級特征圖來實現。

圖4:最後一個mlpconv層的特征映射的可視化。只有前10%的激活功能地圖顯示。特征映射對應的分類如下:1.飛機,2.汽車,3.小鳥,4.貓,5.鹿,6.狗,7.青蛙,8.馬,9.飛船,10.卡車。特征映射對應於輸入圖像的地面真相被突出顯示。左面板和右面板只是不同的例子。
5 Conclusions(結論)
We proposed a novel deep network called “Network In Network” (NIN) for classification tasks. This new structure consists of mlpconv layers which use multilayer perceptrons to convolve the input and a global average pooling layer as a replacement for the fully connected layers in conventionalCNN. Mlpconv layers model the local patches better, and global average pooling acts as a structuralregularizer that prevents overfitting globally. With these two components of NIN we demonstrated state-of-the-art performance on CIFAR-10, CIFAR-100 and SVHN datasets. Through visualization of the feature maps, we demonstrated that featuremaps from the last mlpconv layer of NIN were confidence maps of the categories, and this motivates the possibility of performing object detection
via NIN.
我們提出了一種新的用於分類任務的深度網絡-“網絡中的網絡”(NetworkinNetwork,NIN)。這種新結構由多層感知器來轉換輸入的mlpconv層和一個全局平均池層組成,作為傳統CNN中完全連接層的替代。mlpconv層更好地模型化了局部塊,全局平均池充當了防止全局過度擬合的結構正則化器。使用這兩個NIN組件,我們在CIFAR-10、CIFAR-100和Svhn數據集上演示了最新的性能。通過特征映射的可視化,證明了NIN最後一個mlpconv層的特征映射是類別的置信度映射,這就激發了通過nin進行目標檢測的可能性。
References(參考文獻)
[1] Yann LeCun, Léon Bottou, Yoshua Bengio, and Patrick Haffner. Gradient-based learningapplied to document recognition. Proceedings of the IEEE, 86(11):2278–2324, 1998.
[2] Y Bengio, A Courville, and P Vincent. Representation learning: A review and new perspec-tives. IEEE transactions on pattern analysis and machine intelligence, 35:1798–1828, 2013.
[3] Frank Rosenblatt. Principles of neurodynamics. perceptrons and the theory of brain mechanisms. Technical report, DTIC Document, 1961.
[4] Alex Krizhevsky, Ilya Sutskever, and Geoff Hinton. Imagenet classification with deep convolutional neural networks. In Advances in Neural Information Processing Systems 25, pages 1106–1114, 2012.
[5] Geoffrey E Hinton, Nitish Srivastava, Alex Krizhevsky, Ilya Sutskever, and Ruslan R Salakhutdinov. Improving neural networks by preventing co-adaptation of feature detectors. arXiv preprint arXiv:1207.0580, 2012.
[6] Quoc V Le, Alexandre Karpenko, Jiquan Ngiam, and Andrew Ng. Ica with reconstruction cost for efficient overcomplete feature learning. In Advances in Neural Information Processing Systems, pages 1017–1025, 2011.
[7] Ian J Goodfellow. Piecewise linear multilayer perceptrons and dropout. arXiv preprint arXiv:1301.5088, 2013.
[8] Ian J Goodfellow, David Warde-Farley, Mehdi Mirza, Aaron Courville, and Yoshua Bengio. Maxout networks. arXiv preprint arXiv:1302.4389, 2013.
[9] C¸a? glar Gülc ¸ehre and Yoshua Bengio. Knowledge matters: Importance of prior information for optimization. arXiv preprint arXiv:1301.4083, 2013.
[10] Henry A Rowley, Shumeet Baluja, Takeo Kanade, et al. Human face detection in visual scenes. School of Computer Science, Carnegie Mellon University Pittsburgh, PA, 1995.
[11] Matthew D Zeiler and Rob Fergus. Stochastic pooling for regularization of deep convolutional neural networks. arXiv preprint arXiv:1301.3557, 2013.
[12] Alex Krizhevsky and Geoffrey Hinton. Learning multiple layers of features from tiny images.Master’s thesis, Department of Computer Science, University of Toronto, 2009.
[13] Yuval Netzer, Tao Wang, Adam Coates, Alessandro Bissacco, Bo Wu, and Andrew Y Ng. Reading digits in natural images with unsupervised feature learning. In NIPS Workshop on Deep Learning and Unsupervised Feature Learning, volume 2011, 2011.
[14] Jasper Snoek, Hugo Larochelle, and Ryan P Adams. Practical bayesian optimization of machine learning algorithms. arXiv preprint arXiv:1206.2944, 2012.
[15] Li Wan, Matthew Zeiler, Sixin Zhang, Yann L Cun, and Rob Fergus. Regularization of neural networks using dropconnect. In Proceedings of the 30th International Conference on MachineLearning (ICML-13), pages 1058–1066, 2013.
[16] Mateusz Malinowski and Mario Fritz. Learnable pooling regions for image classification. arXiv preprint arXiv:1301.3516, 2013.
[17] Nitish Srivastava and Ruslan Salakhutdinov. Discriminative transfer learning with tree-based priors. In Advances in Neural Information Processing Systems, pages 2094–2102, 2013.
[18] Nitish Srivastava. Improving neural networks with dropout. PhD thesis, University of Toronto, 2013.
[19] Ian J Goodfellow, Yaroslav Bulatov, Julian Ibarz, Sacha Arnoud, and Vinay Shet. Multi-digit number recognition from street view imagery using deep convolutional neural networks. arXiv preprint arXiv:1312.6082, 2013.
[20] Clément Farabet, Camille Couprie, Laurent Najman, Yann Lecun, et al. Learning hierarchical features for scene labeling. IEEE Transactions on Pattern Analysis and Machine Intelligence, 35:1915–1929, 2013.
【論文翻譯】NIN層論文中英對照翻譯--(Network In Network)