
第2章 構造函數語意學
第2章 構造函數語意學
2.1 默認構造函數的構造
考慮如下代碼
class Foo {
public:
int val;
Foo *pnext;
}
void foo_bar() {
// 程序要求bar's members都被清為0
Foo bar;
if (bar.val || bar.pnext)
// ... don something
// ...
}上述代碼是否會合成默認的構造函數? 這裏有兩個問題要弄明白:
- 編譯器需要
- 程序需要: 上述代碼就是"程序需要", 編譯器會聲明一個構造函數, 但是並不會合成出來, 所以還是沒有構造函數, 在這種情況下為程序執行初始化應該是程序員的責任
那麽在未來是否會合成默認構造函數:
- 在C++ Annotated Reference Mannual(ARM)中: 只有在編譯器需要需要時才會合成默認的構造函數
- C++ Standard: 如果沒有任何用戶聲明的構造函數(註意: 是任何聲明的構造函數, 包括拷貝構造函數), 那麽就會有一個默認構造函數被隱式的聲明出來, 但是這樣被聲明出來的默認構造函數是trivial(淺薄無能, 就是沒啥用)constructor. 只有當一個默認構造函數是nontrivial時, 才會被合成出來. 所以, 上面的代碼會聲明一個trivial的默認構造函數, 但是因為是trivial, 所以不會合成出來, 編譯器會報錯
有4種情況, 會使編譯器為沒有聲明構造函數的類合成一個默認構造函數, 即nontrivial的默認構造函數
- 類包含帶有默認構造函數的成員, 合成出來的默認構造函數並不會初始化本類的其他成員, 初始化其他成員是程序員的責任
- 類是由帶有默認構造函數的基類所派生出來的
- 類中帶有一個虛函數
1. class聲明或繼承了一個虛函數
2. class派生自一個繼承串鏈, 其中有一個或更多的虛基類 - 類中帶有一個虛基類 有些疑問
被合成出來的構造函數只能滿足編譯器(而非程序)的需要, 它之所以能夠完成任務, 是借著"調用成員對象或基類的默認構造函數"或是"為每一個對象初始化其虛函數機制或虛基類機制"而完成的
在合成的默認構造函數中, 只有基類子對象和類成員對象會被初始化. 所有其他的nonstatic數據成員(如整數, 整數指針, 整數數組等等)都不會初始化. 這些初始化操作對程序而言或許有需要, 但對編譯器則是非必要. 如果程序需要一個"把某指針設為0"的默認構造函數, 那麽提供它的人應該是程序員
總結就是都會聲明, 但是會不會合成又是另一回事了, 取決於是trivial還是nontrivial
2.2 拷貝構造函數的構造初始化
有3種情況會以一個對象內容作為另一個對象的初值, 1. 顯示以一個對象內容作為另一個對象的初值(初始化, 而不是單純等號操作); 2. 當對象做參數交給某個函數(做形參, 非引用指針形式); 3. 對象做返回值(非引用指針形勢)
- 默認逐成員初始化(Default Memberwise Initialization)
- 逐成員初始化(Memberwise Initialization)
- 位逐次拷貝(Bitwise Copy Semantic)
// 以下聲明展現了bitwide copy semantic
class Word {
public:
Word(const char *);
~Word() { delete[] str; };
// ...
private:
int cnt;
char *str;
}如果類X沒有顯式的拷貝構造函數, 那麽在用一個類X的對象a初始化這個類的對象b時, 內部采用的就是默認逐位成員初始化. 具體來講, 就是把a的數據一個個單獨拷貝到b中. 如果類X裏面還包含有成員類對象(Member Class Object), 如類Y的對象, 那麽此時就不會把a的成員對象拷貝到b中, 而是遞歸的進行逐成員初始化, 逐成員初始化用的就是逐位拷貝和拷貝構造函數
就像默認拷貝構造函數一樣, C++ Standard上說, 如果類沒有聲明一個拷貝構造函數, 就會有隱式的聲明或隱式的定義出現. 和以前一樣, C++ Standard把拷貝構造函數區分為trivial和nontrivial兩用, 只有nontrivial的實例才會被合成於程序之中. 如果展現出"bitwise copy semantic"(位逐次拷貝語義), 那麽拷貝構造函數就是trivial的
qu
如果一個類沒有定義顯示的拷貝構造函數, 那麽編譯器是否會為其合成取決於類是否展現"位逐次拷貝":
- 如果類展現出"位逐次拷貝", 則編譯器不需要合成一個默認的拷貝構造函數
- 如果類不展現"位逐次拷貝", 則編譯器必須合成一個默認的拷貝構造函數, 不展現"位逐次拷貝"的情況有以下4種:
- 1. 類包含具有拷貝構造函數的成員
- 2. 類繼承自一個具有拷貝構造函數的基類
- 3. 類中聲明一個或多個虛函數
- 4. 類派生自一個繼承串鏈, 其中有一個或多個虛基類
前2種情況中, 編譯器必須將成員或基類的"拷貝構造函數調用操作"安插到被合成的拷貝構造函數中
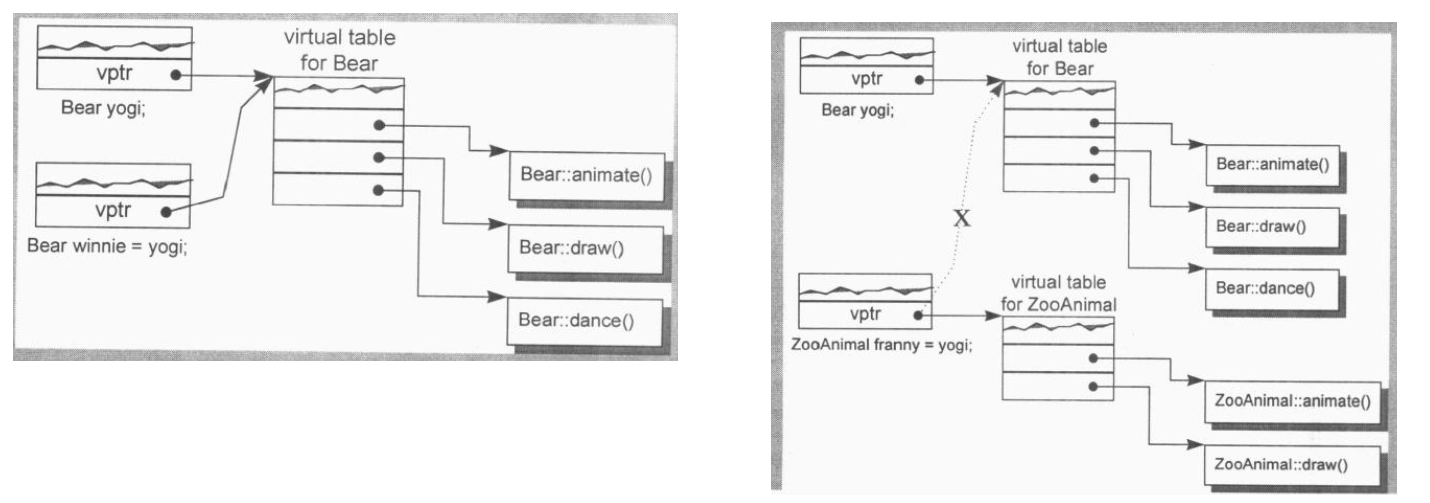
第3種情況不展現出"位逐次拷貝"是因為需要正確的處理虛函數指針vptr. (1)如果使用子類的一個對象初始化另一個子類的對象, 可以直接靠"位逐次拷貝"完成; (2)如果用一個子類對象初始化一個父類對象, 會發生切割行為, 父類對象的虛函數指針必須指向父類的虛函數表vtlb, 如果使用"位逐次拷貝", 那麽父類的虛函數指針會執行子類的vtlb
第4中情況不展現"位逐次拷貝"是因為虛基類對象部分能夠正確初始化. (1)如果使用虛基類子類的一個對象, 初始化虛基類子類另一個對象, 那麽"位逐次拷貝"綽綽有余; (2)但如果企圖以一個虛基類子類的子類對象, 初始化一個虛基類子類的對象, 編譯器就必須判斷"後續當程序員企圖存取其虛基類子對象能否正確執行", 因此必須合成一個拷貝構造函數, 安插一些代碼以設定虛基類指針和偏移量的初始值(或只是簡單的確定它沒有被抹銷)
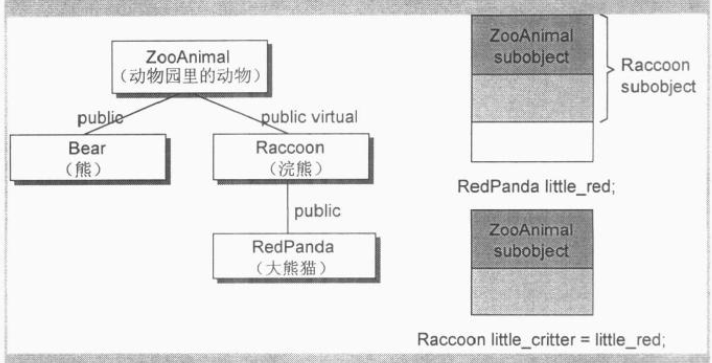
在下面的情況下, 編譯器無法知道"位逐次拷貝"是否還保持著, 因為他無法知道Raccoon指針是否指向一個真正的Raccoon對象或者是指向一個Raccoon的子類對象
Raccoon *ptr;
Raccoon little_critter = *ptr;總結就是, 按照C++ Standard, 如果用戶沒有聲明, 就會隱式的聲明一個, 但是會不會合成取決於聲明出的是trivial還是nontrivial
2.3 程序轉換語意學
class Test {
public:
Test() { cout << "默認構造函數" << endl; }
Test(const Test &obj) { cout << "拷貝構造函數" << endl; }
};
Test foo() {
Test t;
return t;
}
int main() {
// 輸出默認構造函數
Test t = foo();
return 0;
}拷貝構造函數的應用, 迫使編譯器多多少少對程序代碼做部分轉化. 尤其是當一個函數以值的方式傳回一個類對象, 而該類有一個拷貝構造函數(無論是顯式定義出來還是合成出來)時, 這將導致深奧的程序轉化為-->無論在函數的定義上還是在使用上. 此外, 編譯器將拷貝構造的調用操作優化, 以一個額外的第一參數(數值被直接存放其中)取代NRV(named return value). 如果了解那些轉換, 已經拷貝構造函數優化後的可能狀態, 就比較能夠控制程序的執行效率
2.4 成員初始化列表
為使程序能夠被正確編譯, 在下列情況中必須使用初始化列表:
- 當初始化一個引用成員時
- 當初始化一個常成員時
- 當調用一個基類的構造函數, 而它擁有一組參數時
- 當調用一個類類型成員的構造函數, 而它擁有一組參數時
編譯器會對初始化列表一一處理, 以反應出成員的聲明順序. 它會安插一些代碼到構造函數體內, 並置於任何用戶代碼(explicit user code)之前
和默認構造函數, 拷貝構造函數相關的問題: 是否可以使用memset來初始化一個對象, 使用memcpy來拷貝一個對象?
只有在"class不含任何由編譯器產生的members"時才能有效運行. 如果class聲明一個或多個以上的virtual functions, 或者內含一個virtu base class, 那麽上述函數將會導致哪些"被編譯器產生的內部members"的初值改寫
class Shape { public: // 會改變內部vptr Shape() { memset(this, 0, sizeof(Shape)); } // 當傳入一個子類對象的地址時, vptr會指向子類的虛函數表 Shape(const Shape &rhs) { memcpy(this, & rhs, sizeof(Shape)); } virtual ~Shape(); }
第2章 構造函數語意學