
Node.js 應用故障排查手冊 —— 綜合性 GC 問題和優化

楔子
本章前面兩節生產案例分別側重於單一的 CPU 高和單一的記憶體問題,我們也給大家詳細展示了問題的定位排查過程,那麼實際上還有一類相對更復雜的場景——它本質上是 V8 引擎的 GC 引發的問題。
簡單的給大家介紹下什麼是 GC,GC 實際上是語言引擎實現的一種自動垃圾回收機制,它會在設定的條件觸發時(比如堆記憶體達到一定值)時檢視當前堆上哪些物件已經不再使用,並且將這些沒有再使用到的物件所佔據的空間釋放出來。許多的現代高階語言都實現了這一機制,來減輕程式設計師的心智負擔。
本書首發在 Github,倉庫地址:https://github.com/aliyun-node/Node.js-Troubleshooting-Guide,雲棲社群會同步更新。
GC 帶來的問題
雖然上面介紹中現代語言的 GC 機制解放了程式設計師間接提升了開發效率,但是萬事萬物都存在利弊,底層的引擎引入 GC 後程序員無需再關注物件何時釋放的問題,那麼相對來說程式設計師也就沒辦法實現對自己編寫的程式的精準控制,它帶來兩大問題:
- 程式碼編寫問題引發的記憶體洩漏
- 程式執行的效能降低
記憶體洩漏問題我們已經在上一節的生產案例中體驗了一下,那麼後者是怎麼回事呢?
其實理解起來也很簡單:原本一個程式全部的工作都是執行業務邏輯,但是存在了 GC 機制後,程式總會在一定的條件下耗費時間在掃描堆空間找出不再使用的物件上,這樣就變相降低了程式執行業務邏輯的時間,從而造成了效能的下降,而且降低的效能和耗費在 GC 上的時間,換言之即 GC 的次數 * 每次 GC 耗費的時間成正比。
問題現象與原始分析
現在大家應該對 GC 有了一個比較整體的瞭解,這裡我們可以看下 GC 引發的問題在生產中的表現是什麼樣的。在這個案例中,表象首先是 Node.js 效能平臺 上監控到程序的 CPU 達到 100%,但是此時伺服器負載其實並不大,QPS 只有 100 上下,我們按照前面提到的處理 CPU 問題的步驟抓取 CPU Profile 進行分析可以看到:
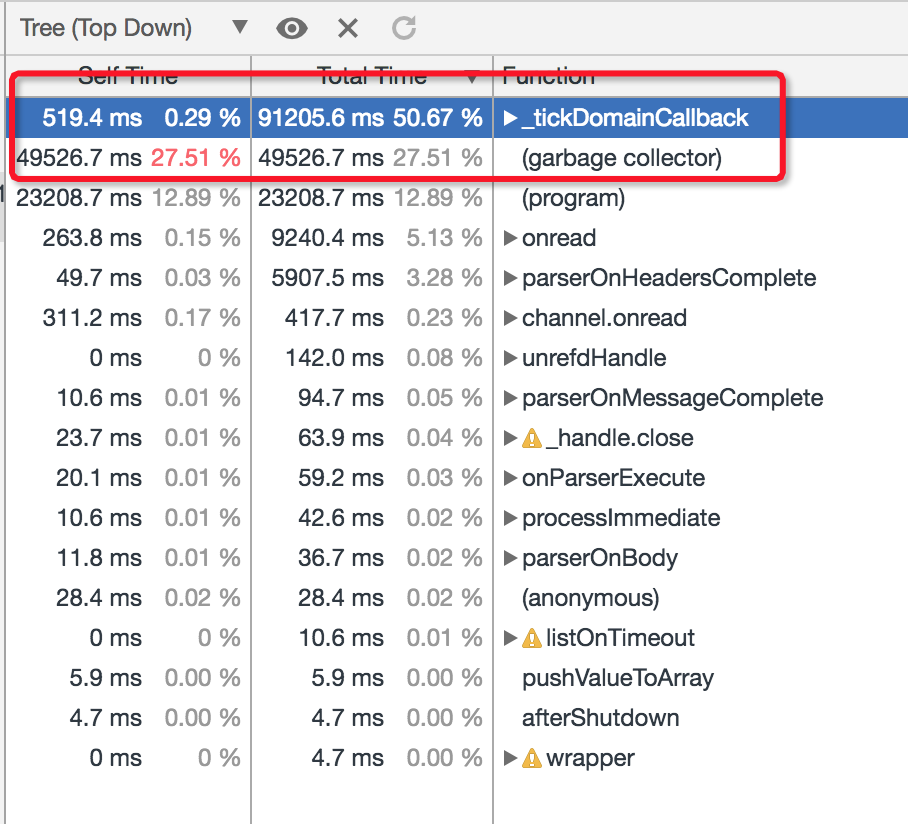
這次的問題顯然是 Garbage Collector 耗費的 CPU 太多了,也就是 GC 的問題。實際上絕大部分的 GC 機制引發的問題往往表象都是反映在 Node.js 程序的 CPU 上,而本質上這類問題可以認為是引擎的 GC 引起的問題,也可以理解為記憶體問題,我們看下這類問題的產生流程:
- 堆記憶體不斷達到觸發 GC 動作的預設條件
- 程序不斷觸發 GC 操作
- 程序 CPU 飆高
而且 GC 問題不像之前的 ejs 模板渲染引發的問題,就算我們在 CPU Profile 中可以看到這部分的耗費,但是想要優化解決這個問題基本是無從下手的,幸運的是 Node.js 提供了(其實是 V8 引擎提供的)一系列的啟動 Flag 能夠輸出程序觸發 GC 動作時的相關日誌以供開發者進行分析:
- --trace_gc: 一行日誌簡要描述每次 GC 時的時間、型別、堆大小變化和產生原因
- --trace_gc_verbose: 結合 --trace_gc 一起開啟的話會展示每次 GC 後每個 V8 堆空間的詳細狀況
- --trace_gc_nvp: 每一次 GC 的一些詳細鍵值對資訊,包含 GC 型別,暫停時間,記憶體變化等資訊
加粗的 Flag 意味著我們需要在啟動應用前加上才能在執行時生效,這部分的日誌實際上是一個文字格式,可惜的是 Chrome devtools 原生並不支援 GC 日誌的解析和結果展示,因此需要大家獲取到以後進行對應的按行解析處理,當然我們也可以使用社群提供 v8-gc-log-parser 這個模組直接進行解析處理,對這一塊有興趣的同學可以看 @joyeeCheung 在 JS Interactive 的分享: Are Your V8 Garbage Collection Logs Speaking To You?,這裡不詳細展開。
更好的 GC 日誌展示
雖然 Chrome devtools 並不能直接幫助我們解析展示 GC 日誌的結果,但是 Node.js 效能平臺 其實給大家提供了更方便的動態獲取線上執行程序的 GC 狀態資訊以及對應的結果展示,換言之,開發者無需在執行你的 Node.js 應用前開啟上面提到的那些 Flag 而仍然可以在想要獲取到 GC 資訊時通過控制檯拿到 3 分鐘內的 GC 資料。
對應在這個案例中,我們可以進入平臺的應用例項詳情頁面,找到 GC 耗費特別大的程序,然後點選 GC Trace 抓取 GC 資料:
這裡預設會抓取 3 分鐘的對應程序的 GC 日誌資訊,等到結束後生成的檔案會顯示在 檔案 頁面:

此時點選 轉儲 即可上傳到雲端以供線上分析展示了,如下圖所示:

最後點選這裡的 分析 按鈕,即可看到 AliNode 定製後的 GC 資訊分析結果的展現:
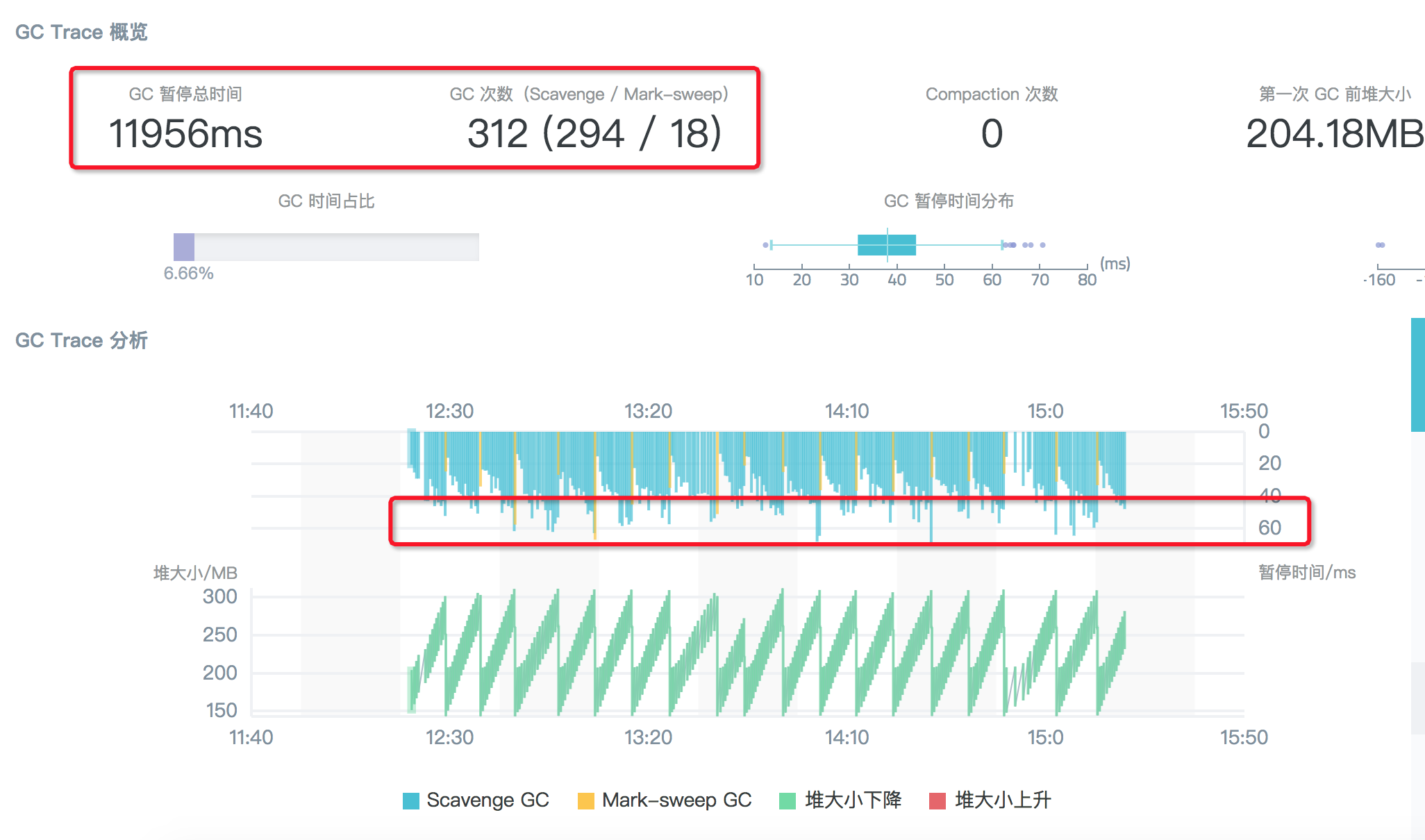
結果展示中,可以比較方便的看到問題程序的 GC 具體次數,GC 型別以及每次 GC 的耗費時間等資訊,方便我們進一步的分析定位。比如這次問題的 GC Trace 結果分析圖中,我們可以看到紅圈起來的幾個重要資訊:
- GC 總暫停時間高達 47.8s,大頭是 Scavenge
- 3min 的 GC 追蹤日誌裡面,總共進行了 988 次的 Scavenge 回收
- 每次 Scavenge 耗時均值在 50 ~ 60ms 之間
從這些解困中我們可以看到此次 GC 案例的問題點集中在 Scavenge 回收階段,即新生代的記憶體回收。那麼通過翻閱 V8 的 Scavenge 回收邏輯可以知道,這個階段觸發回收的條件是:Semi space allocation failed。
這樣就可以推測,我們的應用在壓測期間應該是在新生代頻繁生成了大量的小物件,導致預設的 Semi space 總是處於很快被填滿從而觸發 Flip 的狀態,這才會出現在 GC 追蹤期間這麼多的 Scavenge 回收和對應的 CPU 耗費,這樣這個問題就變為如何去優化新生代的 GC 來提升應用效能。
優化新生代 GC
通過平臺提供的 GC 資料抓取和結果分析,我們知道可以去嘗試優化新生代的 GC 來達到提升應用效能的目的,而新生代的空間觸發 GC 的條件又是其空間被佔滿,那麼新生代的空間大小由 Flag --max-semi-space-size 控制,預設為 16MB,因此我們自然可以想到要可以通過調整預設的 Semi space 的值來進行優化。
這裡需要注意的是,控制新生代空間的 Flag 在不同的 Node.js 版本下並不是一樣的,大傢俱體可以檢視當前的版本來進行確認使用。
在這個案例中,顯然是預設的 16M 相對當前的應用來說顯得比較小,導致 Scavenge 過於頻繁,我們首先嚐試通過啟動時增加 --max-semi-space-size=64 這個 Flag 來將預設的新生代使用到的空間大小從 16M 的值增大為 64M,並且在流量比較大而且程序 CPU 很高時抓取 CPU Profile 觀察效果:
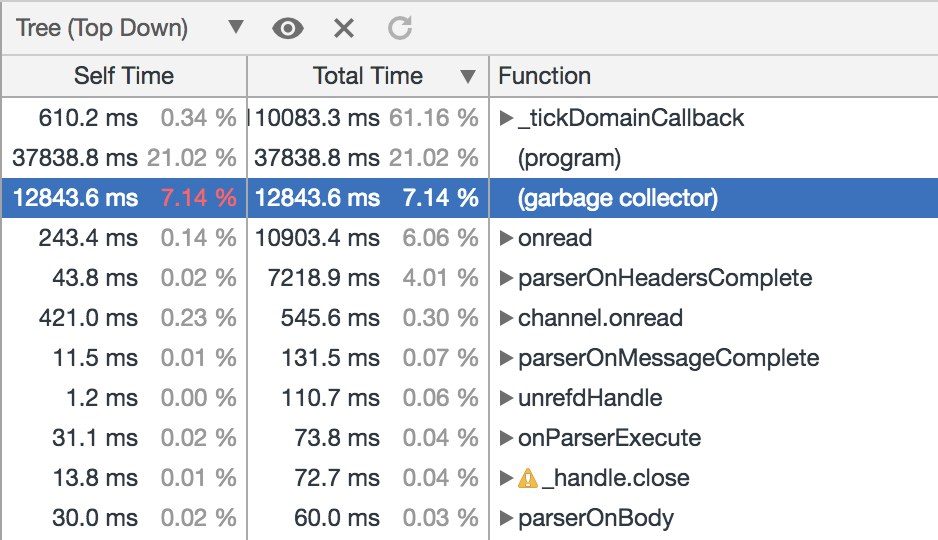
調整後可以看到 Garbage collector 階段 CPU 耗費佔比下降到 7% 左右,再抓取 GC Trace 並觀察其展示結果確認是不是 Scavenge 階段的耗費下降了:
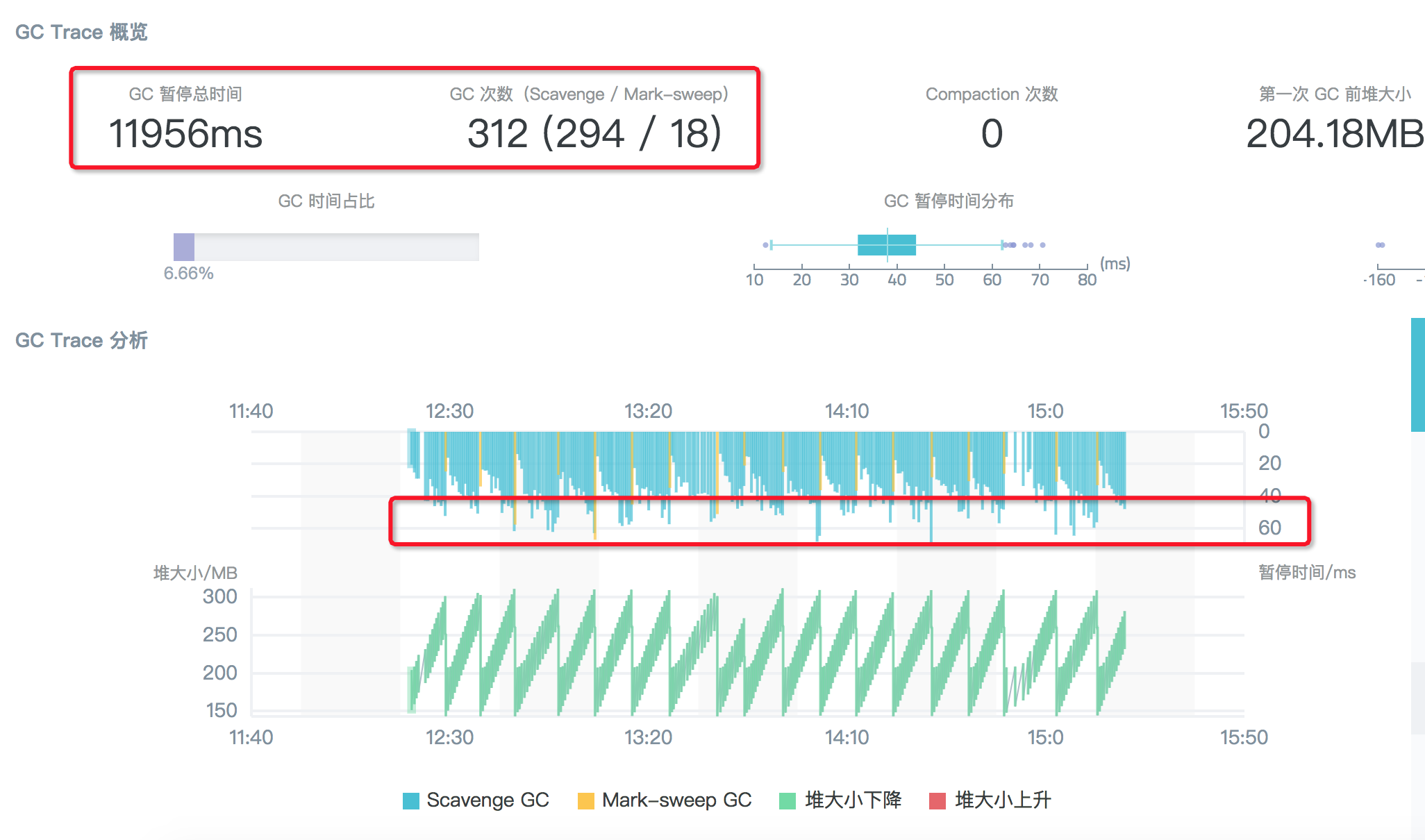
顯然,Semi space 調大為 64M 後,Scavenge 次數從近 1000 次降低到 294 次,但是這種狀況下每次的 Scavenge 回收耗時沒有明顯增加,還是在 50 ~ 60ms 之間波動,因此 3 分鐘的 GC 追蹤總的停頓時間從 48s 下降到 12s,相對應的,業務的 QPS 提升了約 10% 左右。
那麼如果我們通過 --max-semi-space-size 這個 Flag 來繼續調大新生代使用到的空間,是不是可以進一步優化這個應用的效能呢?此時嘗試 --max-semi-space-size=128 來從 64M 調大到 128M,在程序 CPU 很高時繼續抓取 CPU Profile 來檢視效果:
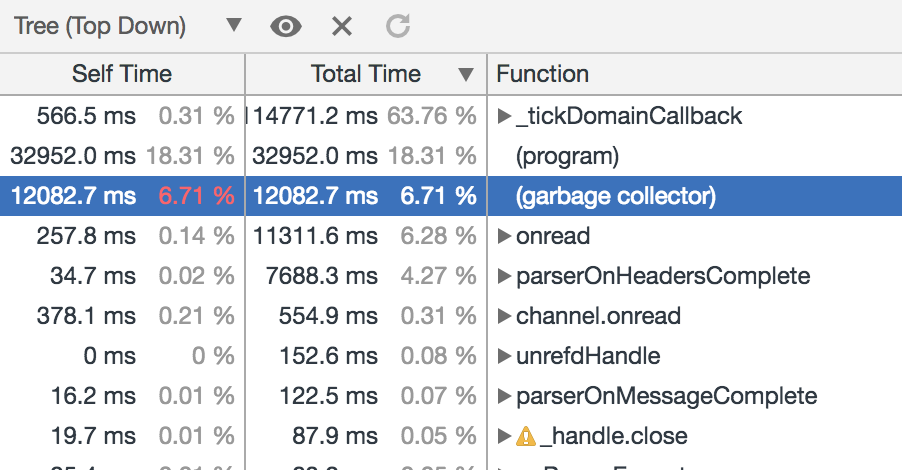
此時 Garbage collector 耗費下降相比上面的設定為 64M 並不是很明顯,GC 耗費下降佔比不到 1%,同樣我們來抓取並觀察下 GC Trace 的結果來檢視具體的原因:
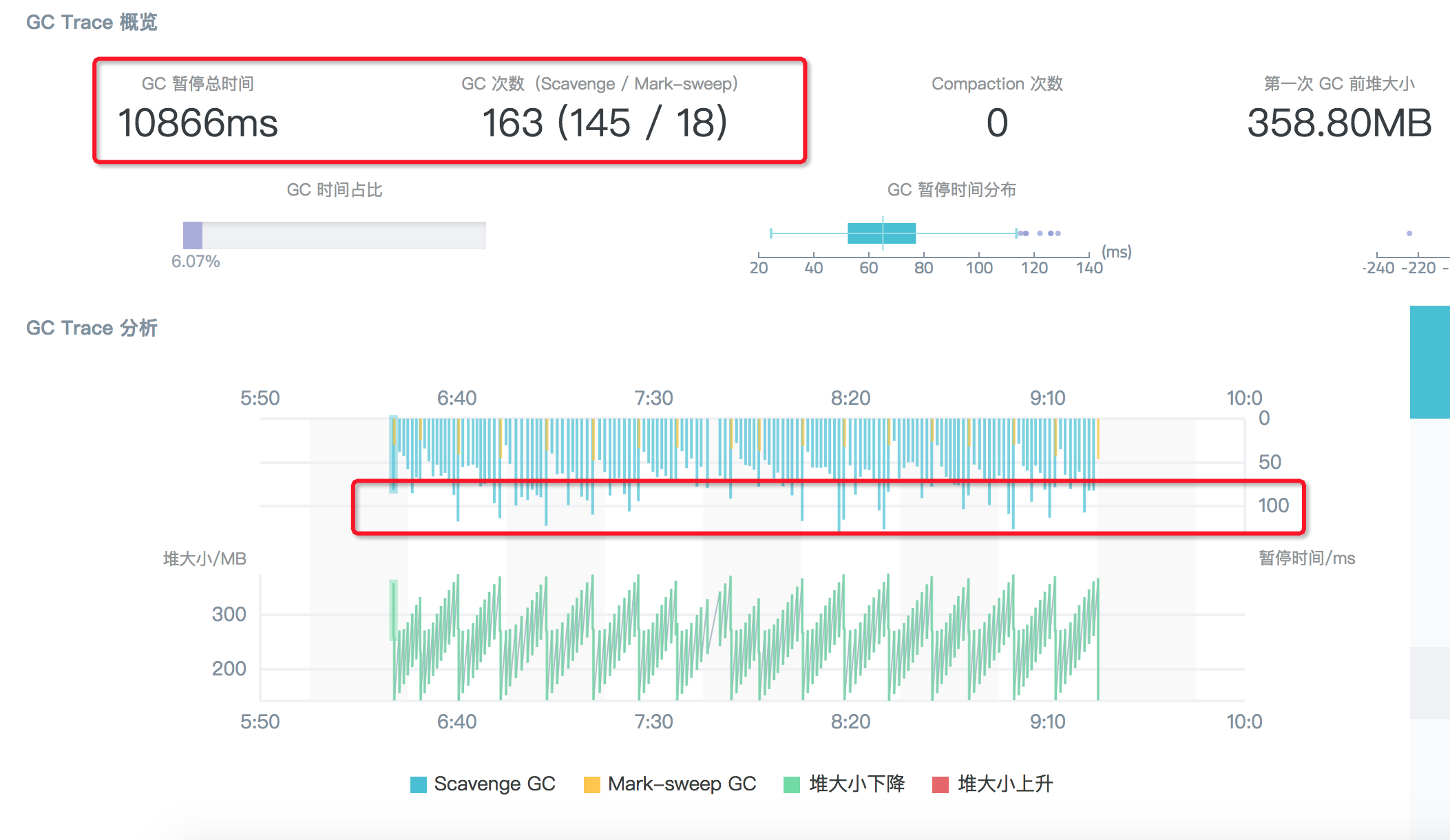
很明顯,造成相比設定為 64M 時 GC 佔比提升不大的原因是:雖然此時進一步調大了 Semi space 至 128M,並且 Scavenge 回收的次數確實從 294 次下降到 145 次,但是每次演算法回收耗時近乎翻倍了,因此總收益並不明顯。
按照這個思路,我們再使用 --max-semi-space-size=256 來將新生代使用的空間進一步增大到 256M 再來進行最後一次的觀察:
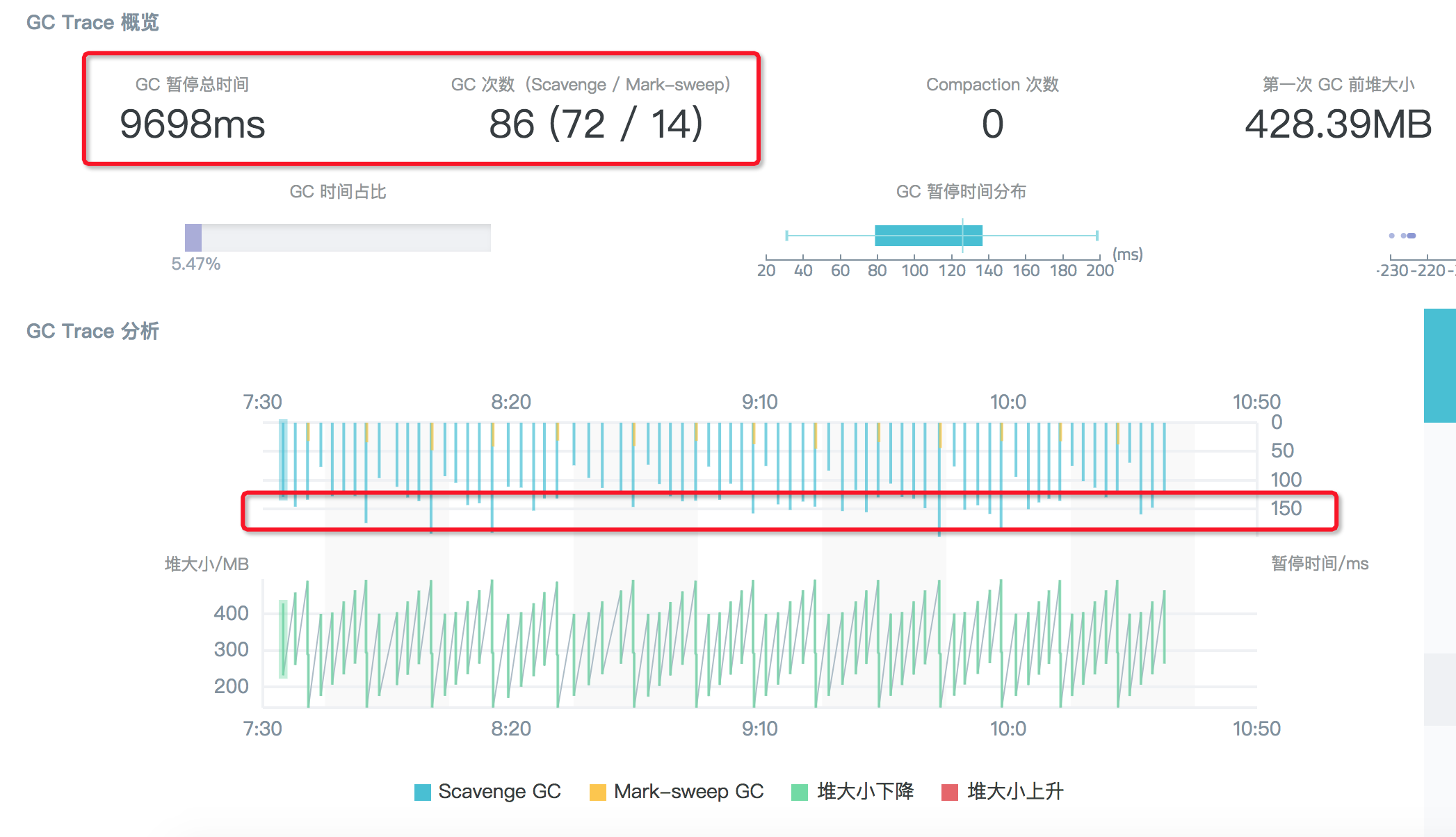
這裡和調整為 128M 時是類似的情況: 3 分鐘內 Scavenge 次數從 294 次下降到 72 次,但是相對的每次演算法回收耗時波動到了 150ms 左右,因此整體效能並沒有顯著提升。
藉助於效能平臺的 GC 資料抓取和結果展示,通過以上的幾次嘗試改進 Semi space 的值後,我們可以看到從預設的 16M 設定到 64M 時,Node 應用的整體 GC 效能是有顯著提升的,並且反映到壓測 QPS 上大約提升了 10%;但是進一步將 Semi space 增大到 128M 和 256M 時,收益確並不明顯,而且 Semi space 本身也是作用於新生代物件快速記憶體分配,本身不宜設定的過大,因此這次優化最終選取對此專案 最優的執行時 Semi space 的值為 64M。
結尾
在本生產案例中,我們首先可以看到,專案使用的三方庫其實也並不總是在所有場景下都不會有 Bug 的(實際上這是不可能的),因此在遇到三方庫的問題時我們要敢於去從原始碼的層面來對問題進行深入的分析。
最後實際上在生產環境下通過 GC 方面的執行時調優來提升我們的專案效能是一種大家不那麼常用的方式,這也有很大一部分原因是應用執行時 GC 狀態本身不直接暴露給開發者。通過上面這個客戶案例,我們可以看到藉助於 Node.js 效能平臺,實時感知 Node 應用 GC 狀態以及進行對應的優化,使得不改一行程式碼提升專案效能變成了一件非常容易的事情。
作者:奕鈞
原文連結
本文為雲棲社群原創內容,未經