
Node.js 應用故障排查手冊 —— 雪崩型記憶體洩漏問題
楔子
實踐篇一中我們也看到了一個比較典型的由於開發者不當使用第三方庫,而且在配置資訊中攜帶了三方庫本身使用不到的資訊,導致了記憶體洩漏的案例,實際上類似這種相對緩慢的 Node.js 應用記憶體洩漏問題我們總是可以在合適的機會抓取堆快照進行分析,而且堆快照一般來說確實是分析記憶體洩漏問題的最佳手段。
但是還有一些問題場景下下應用的記憶體洩漏非常嚴重和迅速,甚至於在我們的告警系統感知之前就已經造成應用的 OOM 了,這時我們來不及或者說根本沒辦法獲取到堆快照,因此就沒有辦法藉助於之前的辦法來分析為什麼程序會記憶體洩漏到溢位進而 Crash 的原因了。這種問題場景實際上屬於線上 Node.js 應用記憶體問題的一個極端狀況,本節將同樣從源自真實生產的一個案例來來給大家講解下如何處理這類極端記憶體異常。
本書首發在 Github,倉庫地址:https://github.com/aliyun-node/Node.js-Troubleshooting-Guide,雲棲社群會同步更新。
最小化復現程式碼
同樣我們因為例子的特殊性,我們需要首先給出到大家生產案例的最小化復現程式碼,建議讀者自行執行一番此程式碼,這樣結合起來看下面的排查分析過程會更有收穫。最小復現程式碼還是基於 Egg.js,如下所示:
'use strict'; const Controller = require('egg').Controller; const fs = require('fs'); const path = require('path'); const util = require('util'); const readFile = util.promisify(fs.readFile); class DatabaseError extends Error { constructor(message, stack, sql) { super(); this.name = 'SequelizeDatabaseError'; this.message = message; this.stack = stack; this.sql = sql; } } class MemoryController extends Controller { async oom() { const { ctx } = this; let bigErrorMessage = await readFile(path.join(__dirname, 'resource/error.txt')); bigErrorMessage = bigErrorMessage.toString(); const error = new DatabaseError(bigErrorMessage, bigErrorMessage, bigErrorMessage); ctx.logger.error(error); ctx.body = { ok: false }; } } module.exports = MemoryController;
這裡我們還需要在 app/controller/ 目錄下建立一個 resource 資料夾,並且在這個資料夾中新增一個 error.txt,這個 TXT 內容隨意,只要是一個能超過 100M 的很大的字串即可。
值得注意的是,其實這裡的問題已經在 egg-logger >= 1.7.1 的版本中修復了,所以要復現當時的狀況,你還需要在 Demo 的根目錄執行以下的三條命令以恢復當時的版本狀況:
rm -rf package-lock.json rm -rf node_modules/egg/egg-logger npm install [email protected]
最後使用 npm run dev 啟動這個問題最小化復現的 Demo。
感知程序出現問題
這個案例下,實際上我們的線上 Node.js 應用幾乎是觸發了這個 Bug 後瞬間記憶體溢位然後 Crash 的,而平臺預設的記憶體閾值告警,實際上是由一個定時上報的邏輯構成,因此存在延時,也導致了這個案例下我們無法像 冗餘配置傳遞引發的記憶體溢位 問題那樣獲取到 Node.js 程序級別的記憶體超過預設閾值的告警。
那麼我們如何來感知到這裡的錯誤的呢?這裡我們的伺服器配置過了 ulimit -c unlimited ,因此 Node.js 應用 Crash 的時候核心會自動生成核心轉儲檔案,而且效能平臺目前也支援核心轉儲檔案的生成預警,這一條規則目前也被放入了預設的快速新增告警規則中,可以參考工具篇中 Node.js 效能平臺使用指南 - 配置合適的告警 一節,詳細的規則內容如下所示:

這裡需要注意的是,核心轉儲檔案告警需要我們在伺服器上安裝的 Agenthub/Agentx 依賴的 Commandx 模組的版本在 1.5.2 之上(包含),這一塊更詳細的資訊也可以看官方文件 核心轉儲分析能力 一節。
問題排查過程
I. 分析棧資訊
依靠上面提到的平臺提供的核心轉儲檔案生成時給出的告警,我們在收到報警簡訊時登入控制檯,可以看到 Coredump 檔案列表出現了新生成的核心轉儲檔案,繼續參照工具篇中 Node.js 效能平臺使用指南 - 核心轉儲分析 中給出的轉儲和 AliNode 定製分析的過程,我們可以看到如下的分析結果展示資訊:
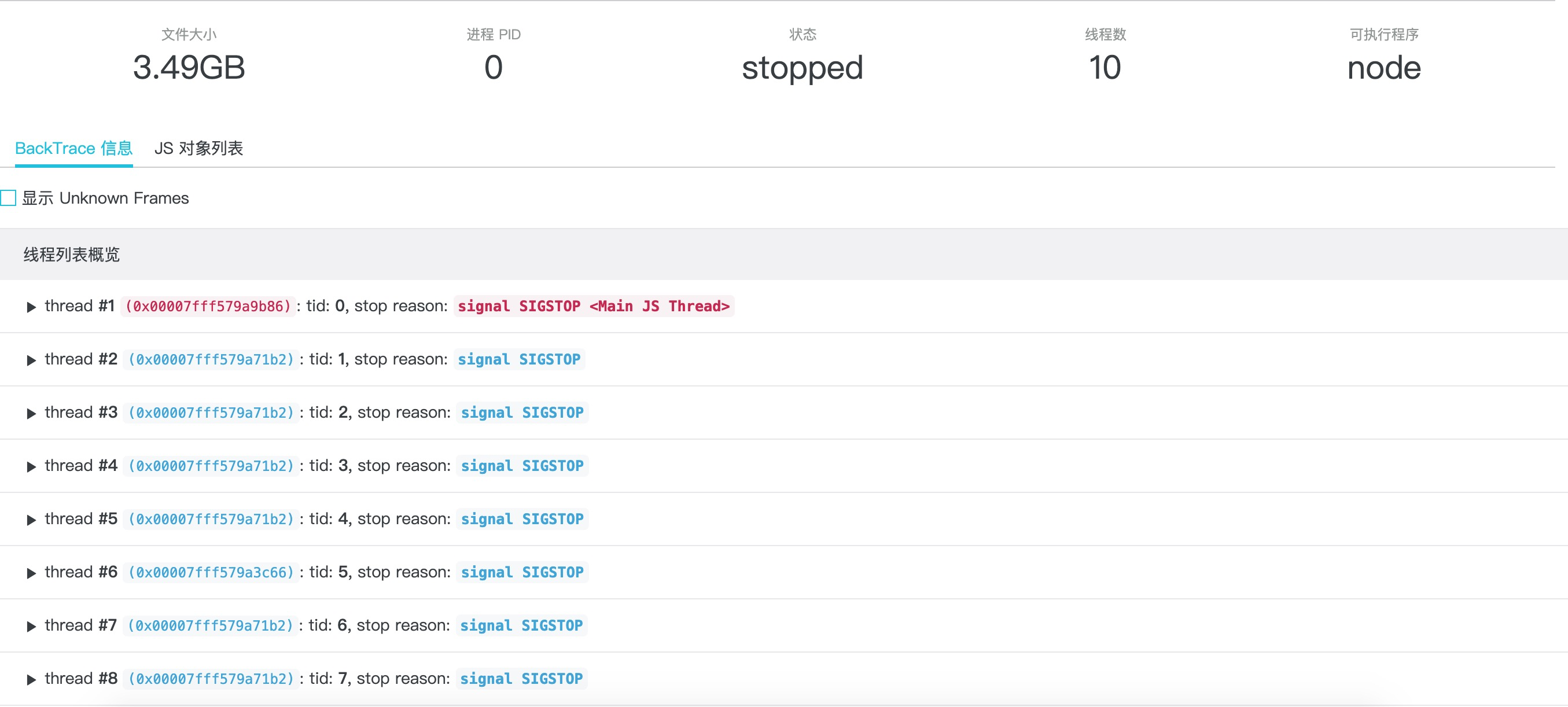
同樣我們直接展開 JavaScript 棧資訊檢視應用 Crash 那一刻的棧資訊:
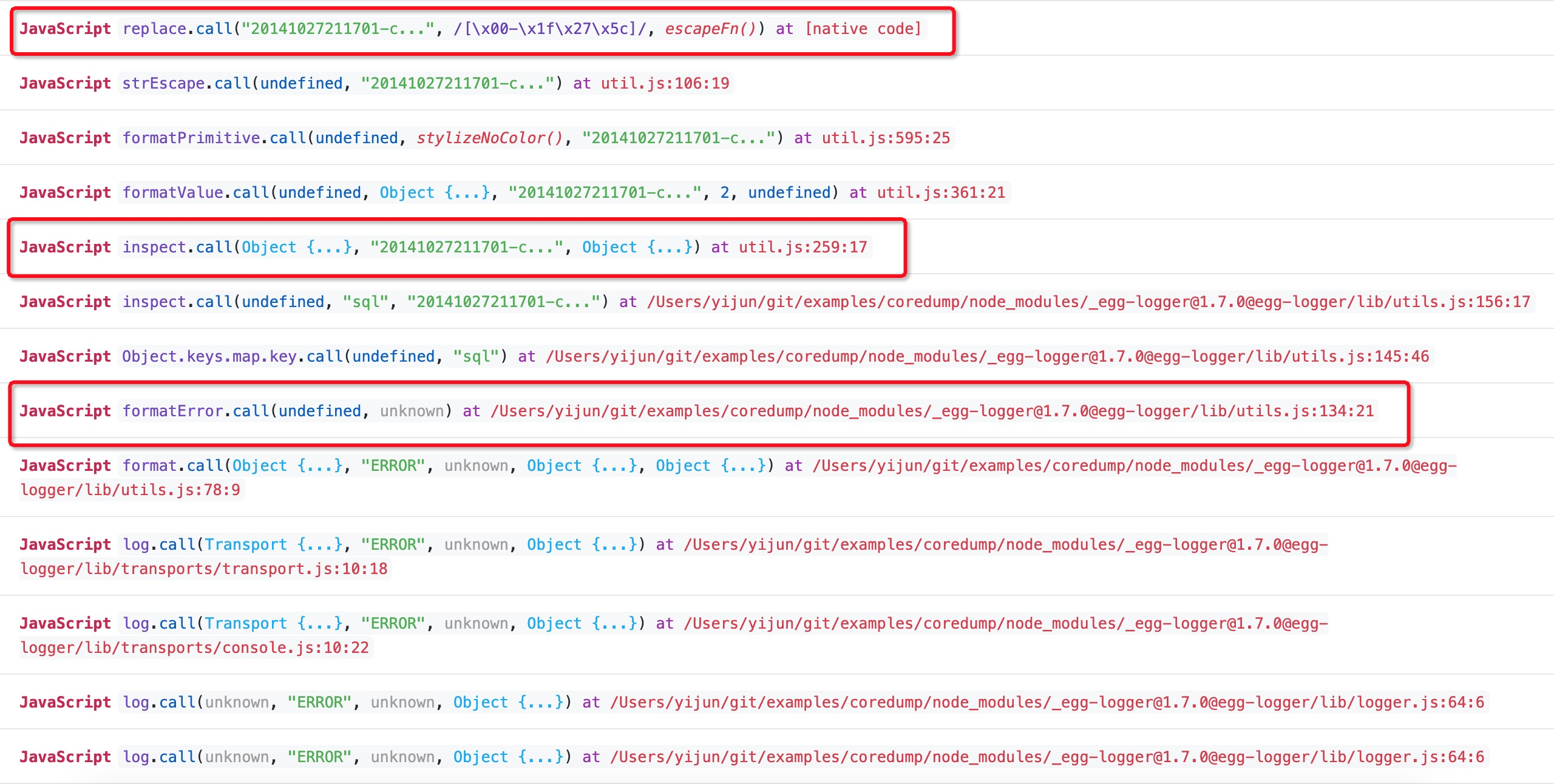
截圖中忽略掉了 Native C/C++ 程式碼的棧資訊,這裡其實僅僅看 JavaScript 棧資訊就能得到結論了,通過翻閱比對出問題的 [email protected] 中 lib/utils.js 的程式碼內容:
function formatError(err) {
// ...
// 這裡對 Error 物件的 key 和 value 呼叫 inspect 方法進行序列化
const errProperties = Object.keys(err).map(key => inspect(key, err[key])).join('\n');
// ...
}
// inspect 方法實際上是呼叫 require('util').inspect 來對錯誤物件的 value 進行序列化
function inspect(key, value) {
return `${key}: ${util.inspect(value, { breakLength: Infinity })}`;
}這樣我們就知道了線上 Node.js 應用在 Crash 的那一刻正在使用 require('util').inspect 對某個字串進行序列化操作。
II. 可疑字串
那麼這個序列化的動作究竟是不是造成程序 Crash 的元凶呢?我們接著來點選 inspect 函式的引數來展開檢視這個可疑的字串的詳細資訊,如下圖所示:

點選紅框中的引數,得到字串的詳情頁面連結,如下圖所示:

再次點選這裡的 detail 連結,既可在彈出的新頁面中看到這個可疑字串的全部資訊:
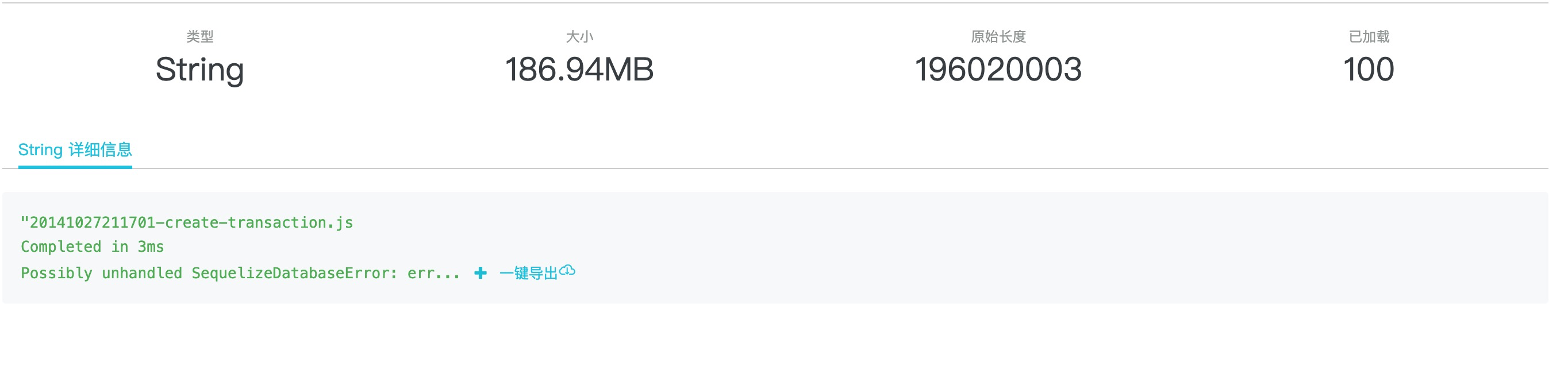
這裡可以看到,這個正在被 util.inspect 的字串大小高達 186.94 兆,顯然正是在序列化這麼大的字串的時候,造成了線上 Node.js 應用的堆記憶體雪崩,幾乎在瞬間就記憶體溢位導致 Crash。
值得一提的是,我們還可以點選上圖中的 + 號來在當前頁面展示更多的問題字串內容:
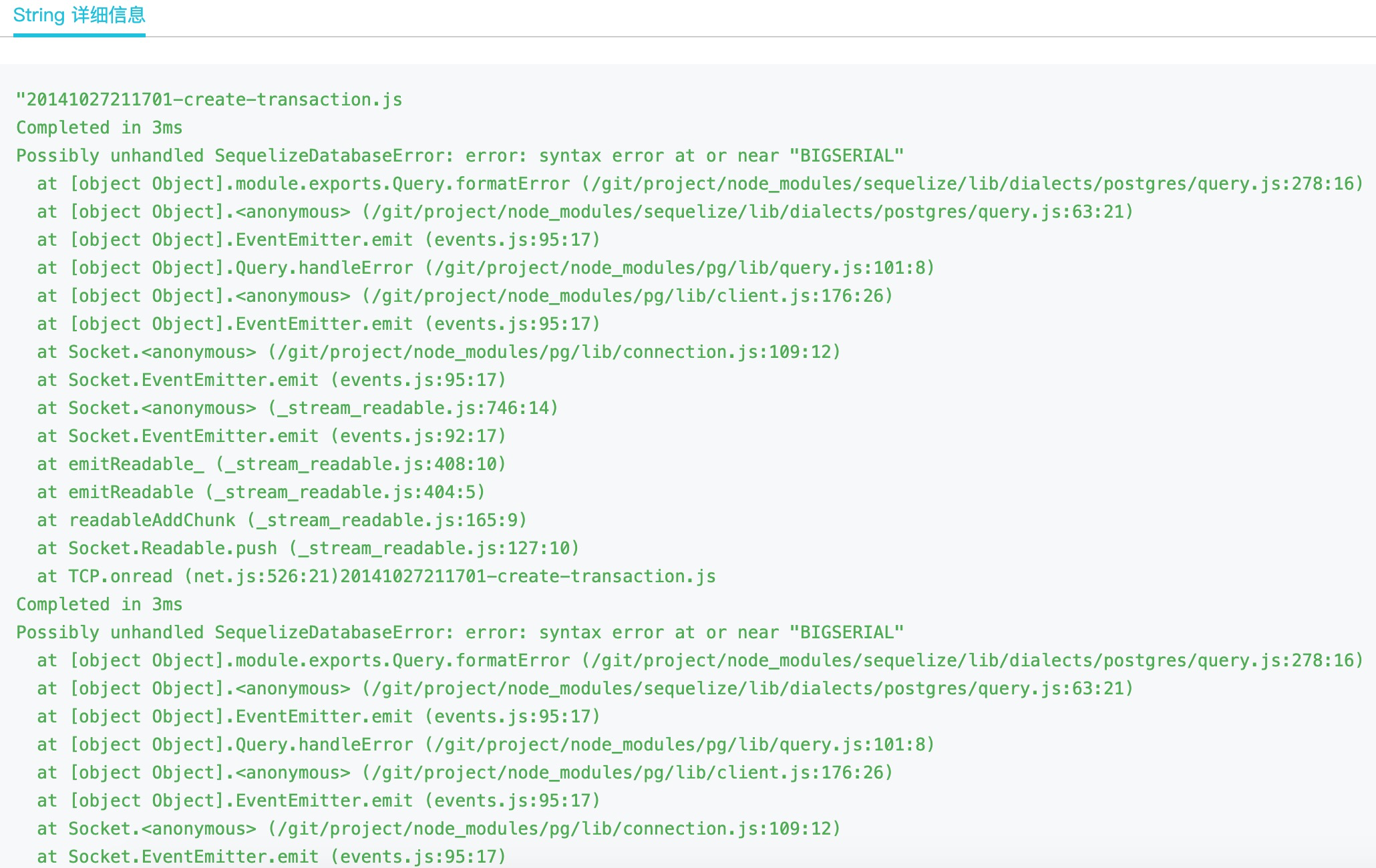
也可以在頁面上點選 一鍵匯出 按鈕下載問題完整的字串:
畢竟對於這樣的問題來說,如果能抓到產生問題的元凶引數,起碼能更方便地進行本地復現。
III. 修復問題
那麼知道了原因,其實修復此問題就比較簡單了,Egg-logger 官方是使用 circular-json 來替換掉原生的 util.inspect 序列化動作,並且增加序列化後的字串最大隻保留 10000 個字元的限制,這樣就解決這種包含大字串的錯誤物件在 Egg-logger 模組中的序列化問題。
結尾
本節的給大家展現了對於線上 Node.js 應用出現瞬間 Crash 問題時的排查思路,而在最小化復現 Demo 對應的那個真實線上故障中,實際上是拼接的 SQL 語句非常大,大小約為 120M,因此首先導致資料庫操作失敗,接著資料庫操作失敗後輸出的 DatabaseError 物件例項上則原封不動地將問題 SQL 語句設定到屬性上,從而導致了 ctx.logger.error(error) 時堆記憶體的雪崩。
在 Node.js 效能平臺 提供的 核心轉儲告警 + 線上分析能力 的幫助下,此類無法獲取到常規 CPU Profile 和堆快照等資訊的程序無故崩潰問題也變得有跡可循了,實際上它作為一種兜底分析手段,在很大程度上提升了開發者真正將 Node.js 運用到服務端生產環境中的信心。
作者:奕鈞
原文連結
本文為雲棲社群原創內容,未經