
nginx-rtmp-module的缺陷分析
Arut最初在開發nginx-rtmp-module的時候只實現了單程序模式,好處是架構簡單,推送和播放,資料統計,流媒體控制等都在一個程序上完成。但是這顯然浪費了Nginx多程序(在Linux和FreeBSD平臺上每個程序都可以繫結一個CPU核心,以減少程序切換帶來的開銷)的處理能力。但是,如果開啟多程序模式,推送和播放如果不在同一個程序上,會造成播放失敗的問題:
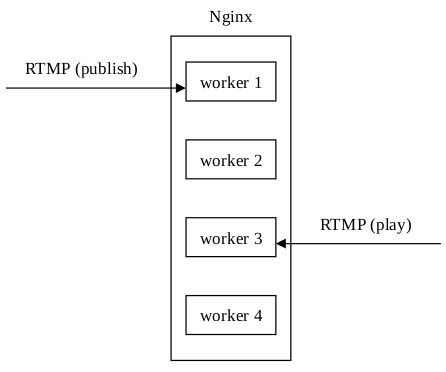
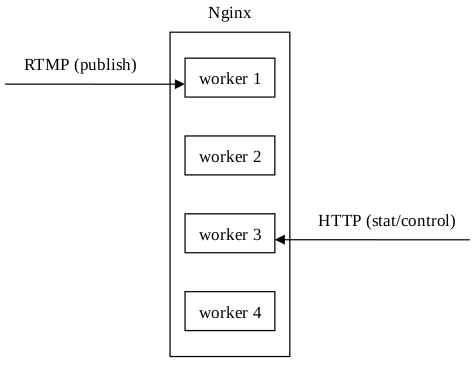
另外,請求資料統計資訊也是個問題,因為採取HTTP方式請求資料統計資訊時,在多程序模式下,請求被Nginx隨機分配給了worker程序,可能造成我想看worker 1上的資料統計資訊,但是Nginx返回的是worker 3上的資料統計資訊。流媒體控制也採取了HTTP請求的方式,所以也存在著同樣的問題:
針對推送和播放不在同一個程序上的問題,Arut後來加入了auto push的功能,即把原始的推流資料再relay到其他程序上去。這個功能需要Unix domain socket的支援(所以類Unix系統都支援,Windows在Windows 10的某個版本後才開始支援):
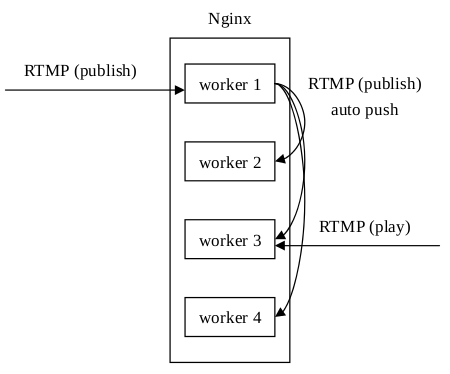
這樣處理後,不管播放請求落在哪個程序上,都能獲得推送資料。
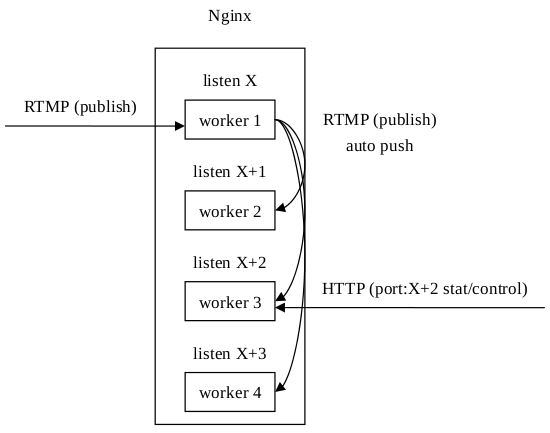
對於後面兩個問題,Arut給出了一個布丁,需要修改Nginx本身的原始碼,詳情見per-worker-listener。這樣處理後,在HTTP請求時加上埠號資訊,就可以指定請求某個程序上的資料統計資訊了,流媒體控制類似:
在測試中發現auto push的併發效能並不能隨著CPU個/核數的提高而提高,一般在400~500路後就無法再提升(筆記本測試)。是什麼原因呢?簡單分析一下:假設伺服器的CPU個/核數為N(Nginx的程序數一般配置為跟CPU個/核數相等),推流路數為M,且有M>>N,例如M=1000,N為4。假設M個推流請求被平均分配到N個程序上(實際上是不會被絕對平均分配的,但是相差不會很大),那麼每個程序需要處理分配給自己本身的請求數為:
Publishers(self) = M / N
另外,要保證某個播放請求不管被哪個程序接受都能成功,那麼每個程序都要接受另外N-1個程序的auto push過來的流,即:
Publishers(others) = M / N x (N - 1) = M - M / N
那麼每個程序需要處理的推送路數為:
Publishers(all) = Publishers(self) + Publishers(others) = M / N + M - M / N = M
即每個程序需要處理的推流數跟CPU個/核數是沒有關係的,並不能用增加CPU個/核數來試圖提高推流併發效能,即相當於原本能將M個推流請求“平均”分配到N個程序上的方案不但沒起作用,還讓每個程序都處理了全部M個推流請求。
那麼怎麼解決這個問題呢?答案是使用被動拉的方案替代主動推(auto push)的方案。此方案要用到共享記憶體和互斥鎖,當一個推流請求被某個程序接受後,在共享記憶體中記錄推送的流和某個程序的對映資訊。而當一個播放請求被某個程序接受後,需要先查詢要播放的流是在哪個程序上釋出的,然後再到釋出流的程序上去請求資料:
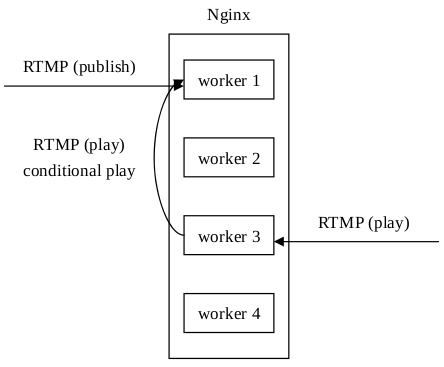
這樣就解決了上述的每個程序都要處理全部程序接收到的推流請求的問題。
關於nginx-rtmp-module的缺陷暫時介紹到這兒,其實nginx-rtmp-module還有很多其他的缺陷,後續有時間我會寫文章介紹。
歡迎關注我在nginx-rtmp-module的基礎上開發的專案:nginx-h