
算法4:合並排序的套路 | 重用 | 分治
重用已經是一種被廣泛使用的套路,小程之前介紹了重用的含義,而合並排序的重用,體現在對自身的反復調用。首先,認定合並排序算法就是讓數列有序的,只要經過它處理,就一定會變得有序,這個信念很重要,做人要信。然後,把數列分為兩部分,分別重用合並排序,重用完,這兩部分就變得有序了。最後,把有序的兩部分數列,合並起來,就解決了排序的問題。
也就是,合並排序本身就是一個標準作業,可以反復被重用。
選定標準作業,是很重要的,它會演化出不同的算法。比如,插入排序是不能以自身作為標準作業的,因為如果這樣設計,它就不叫“插入排序”了,很可能變成了合並排序。
以上介紹了重用套路在合並排序算法中的體現。
另一個經典的套路,是分治。
分治,就是分而治之,你應該經常聽到這樣的說法:“沒有什麽是搞不定的!只要你把它分解得足夠小,就能解決!”,換一個說法就是:沒有什麽是退一步不能解決的,如果有,那就退兩步。
分是第一步,分出來解決後,還要把結果組合起來。
合並排序的分治套路,表現很明顯:把數列分為兩部分,重用自己令這兩部分有序後,再組合起來。
而且,合並排序的分治,是很簡單的分治,從中間分開再處理就可以了。當分到只有一個元素時,就不能再分,此時這一個元素是有序的。
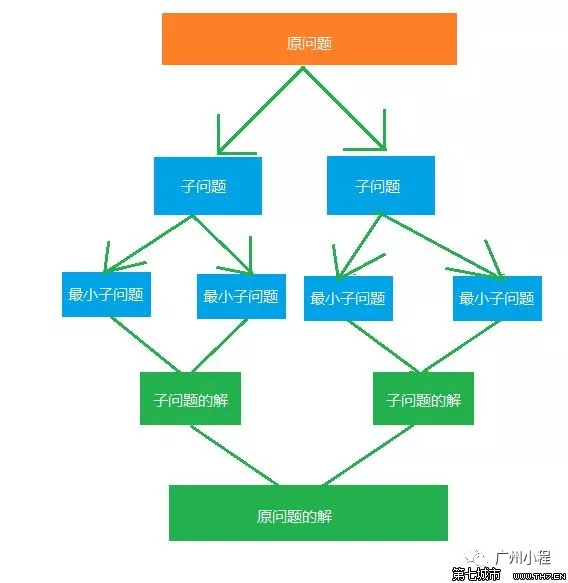
至此,合並排序的兩個重要的套路(重用與分治)就差不多介紹完畢了。
為了讓讀者更清晰地感受這兩個套路,小程接下來從具體的排序實例來詳細介紹。
合並排序,先是要分(一分為二),分到只有一個元素為止(一個元素時就是有序的)。然後是合,先是兩個元素合在一起,之後是多個元素合在一起。
參考以下這個演示圖,可以更好地理解合排的設計與實現:
上面這個圖,註意不同顏色框的變化(分與合的變化)。
再參考另一個演示圖(來自網絡):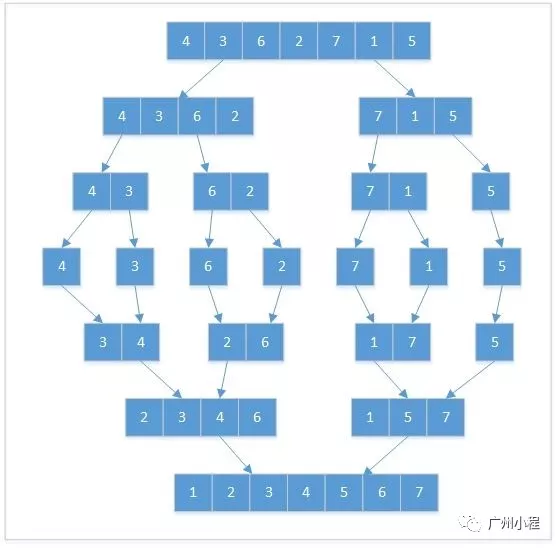
以上是算法套路,接下是代碼實現,這兩者是兩個話題,之前已經解釋過。
#include <stdio.h> #include <stdlib.h> void merge(int* arr, int f, int m, int l, int* tmparr) { int i=f, j=m+1; int k=0; while (i<=m && j<=l) { if (arr[i] > arr[j]) { tmparr[k++]=arr[j++]; } else { tmparr[k++]=arr[i++]; } } while (i<=m) { tmparr[k++]=arr[i++]; } while (j<=l) { tmparr[k++]=arr[j++]; } for (i=0; i<k; i++) { arr[f++]=tmparr[i]; } } void _sort_merge(int* arr, int f, int l, int* tmparr) { if (f < l) { int m=(f+l)>>1; _sort_merge(arr, f, m, tmparr); _sort_merge(arr, m+1, l, tmparr); merge(arr, f, m, l, tmparr); } } void sort_merge(int* arr, int size) { int* tmparr=(int*)malloc(sizeof(int) * size); _sort_merge(arr, 0, size-1, tmparr); free(tmparr); } int main(int argc, char *argv[]) { int arr[] = {4, 2, 5, 1, 6, 6, 8, 9, 8, 3}; int size=sizeof arr/sizeof *arr; for (int i = 0; i < size; i ++) { printf("%d, ", arr[i]); } sort_merge(arr, size); printf("\nafter_sort:\n"); for (int i = 0; i < size; i ++) { printf("%d, ", arr[i]); } printf("\n"); return 0; }
另外,在分治的套路中,可以混搭增量有序的套路,也就是,合並排序在劃分到數量較小時,可以使用插入排序來完成排序(因為在數量較小時,插入排序更快一些),這種套路混搭,打出來的就是組合拳。
以下這部分,介紹了合排與快排的對比,你可以忽略掉,因為時間復雜度或速度方面,跟套路並無直接關系。
小白:只要分成兩部分,再遞歸調用自己來排好序,再合並在一起即可。小程,你之前講的遞歸又發揮作用了!
小程:不要把遞歸實現跟設計思想混在一起。設計上,是一直分下去,再合起來。但實現時,不一定要用遞歸,比如可以把分出來的部分,用數組保存起來,再對這個數組內的部分作細分...,用叠代也能實現。只不過,遞歸是很自然的實現選擇,而且簡潔。但是,你要有“空手套白狼”的勇氣才敢於用上遞歸實現。
小白:就是先假設我的函數已經實現排序了,再在函數裏面調用自己,對某部分作排序了。東風吹戰鼓擂,這個世界誰怕誰?
合並排序的分(O(lgn))與合(O(n)),整體的時間復雜度是O(nlgn),而且是穩定排序。
小白:那豈不是比快排還要快,因為快排有可能變為n的平方?
小程:不是。快排有可能變成n的平方,這種極端的情況是低概率的,而且,可以先打亂再來快排,從而避免去到O(n^2),或者去到極低概率。在都為O(nlogn)時,快排的系數比合排更小,所以速度更快。另外,合排需要額外的空間來保存合並的結果,而快排不需要。
小白:這個...,看來quicksort是實至名歸!
在工程中,快排的效果比合排更優,但註意高層次的設計思想,也就是套路,是一樣的。
總結一下,本文介紹了合並排序的套路,即重用與分治,這兩種思想都是經典的套路,重用能簡化問題的思考,而分治能把問題變小,能熟練掌握這兩種套路就具備了很厲害的功力。

算法4:合並排序的套路 | 重用 | 分治