
Kylin構建Cube過程詳解
1 前言
在使用Kylin的時候,最重要的一步就是建立cube的模型定義,即指定度量和維度以及一些附加資訊,然後對cube進行build,當然我們也可以根據原始表中的某一個string欄位(這個欄位的格式必須是日期格式,表示日期的含義)設定分割槽欄位,這樣一個cube就可以進行多次build,每一次的build會生成一個segment,每一個segment對應著一個時間區間的cube,這些segment的時間區間是連續並且不重合的,對於擁有多個segment的cube可以執行merge,相當於將一個時間區間內部的segment合併成一個。下面開始分析cube的build過程。
2 Cube示例
以手機銷售為例,表SALE記錄各手機品牌在各個國家,每年的銷售情況。表PHONE是手機品牌,表COUNTRY是國家列表,兩表通過外來鍵與SALE表相關聯。這三張表就構成星型模型,其中SALE是事實表,PHONE、COUNTRY是維度表。
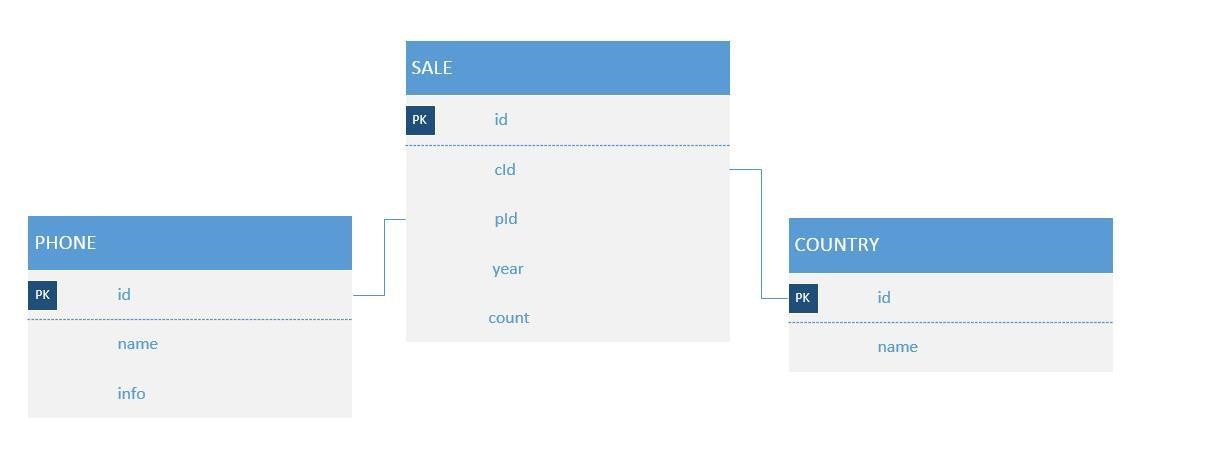
現在需要知道各品牌手機於2010-2012年,在中國的總銷量,那麼查詢sql為:
SELECT b.`name`, c.`NAME`, SUM(a.count) FROM SALE AS a LEFT JOIN PHONE AS b ON a.`pId`=b.`id` LEFT JOIN COUNTRY AS c ON a.`cId`=c.`id` WHERE a.`time` >= 2010 AND a.`time` <= 2012 AND c.`NAME` = "中國" GROUP BY b.`NAME`
其中時間(time), 手機品牌(b.name,後文用phone代替),國家(c.name,後文用country代替)是維度,而銷售數量(a.count)是度量。手機品牌的個數可用於表示手機品牌列的基度。各手機品牌在各年各個國家的銷量可作為一個cuboid,所有的cuboid組成一個cube,如下圖所示:
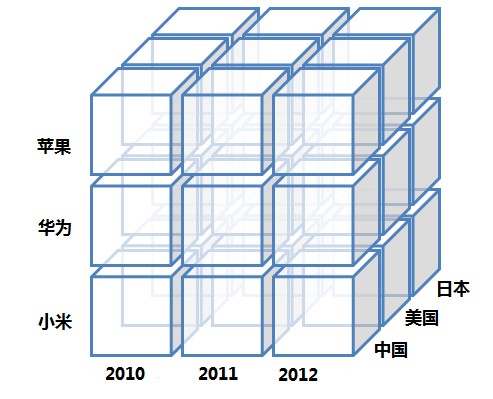
上圖展示了有3個維度的cube,每個小立方體代表一個cuboid,其中儲存的是度量列聚合後的結果,比如蘋果在中國2010年的銷量就是一個cuboid。
3 入口介紹
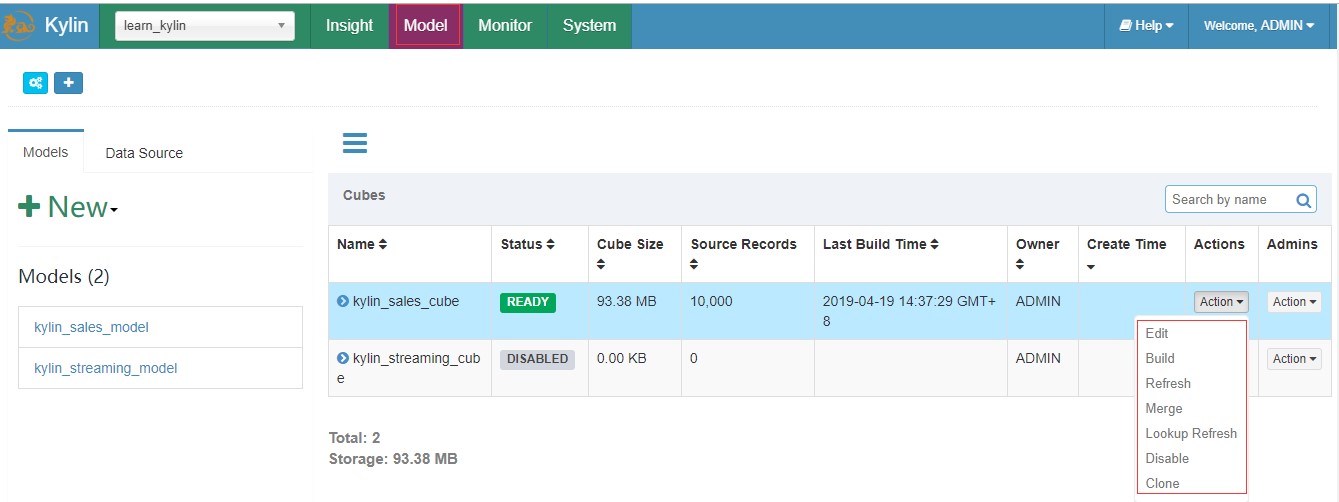
在kylin的web頁面上建立完成一個cube之後可以點選action下拉框執行build或者merge操作,這兩個操作都會呼叫cube的rebuild介面,呼叫的引數包括:
1、cube名,用於唯一標識一個cube,在當前的kylin版本中cube名是全域性唯一的,而不是每一個project下唯一的;
2、本次構建的startTime和endTime,這兩個時間區間標識本次構建的segment的資料來源只選擇這個時間範圍內的資料;對於BUILD操作而言,startTime是不需要的,因為它總是會選擇最後一個segment的結束時間作為當前segment的起始時間。
3、buildType標識著操作的型別,可以是”BUILD”、”MERGE”和”REFRESH”。
4 構建Cube過程
Kylin中Cube的Build過程,是將所有的維度組合事先計算,儲存於HBase中,以空間換時間,HTable對應的RowKey,就是各種維度組合,指標存在Column中,這樣,將不同維度組合查詢SQL,轉換成基於RowKey的範圍掃描,然後對指標進行彙總計算,以實現快速分析查詢。整個過程如下圖所示:
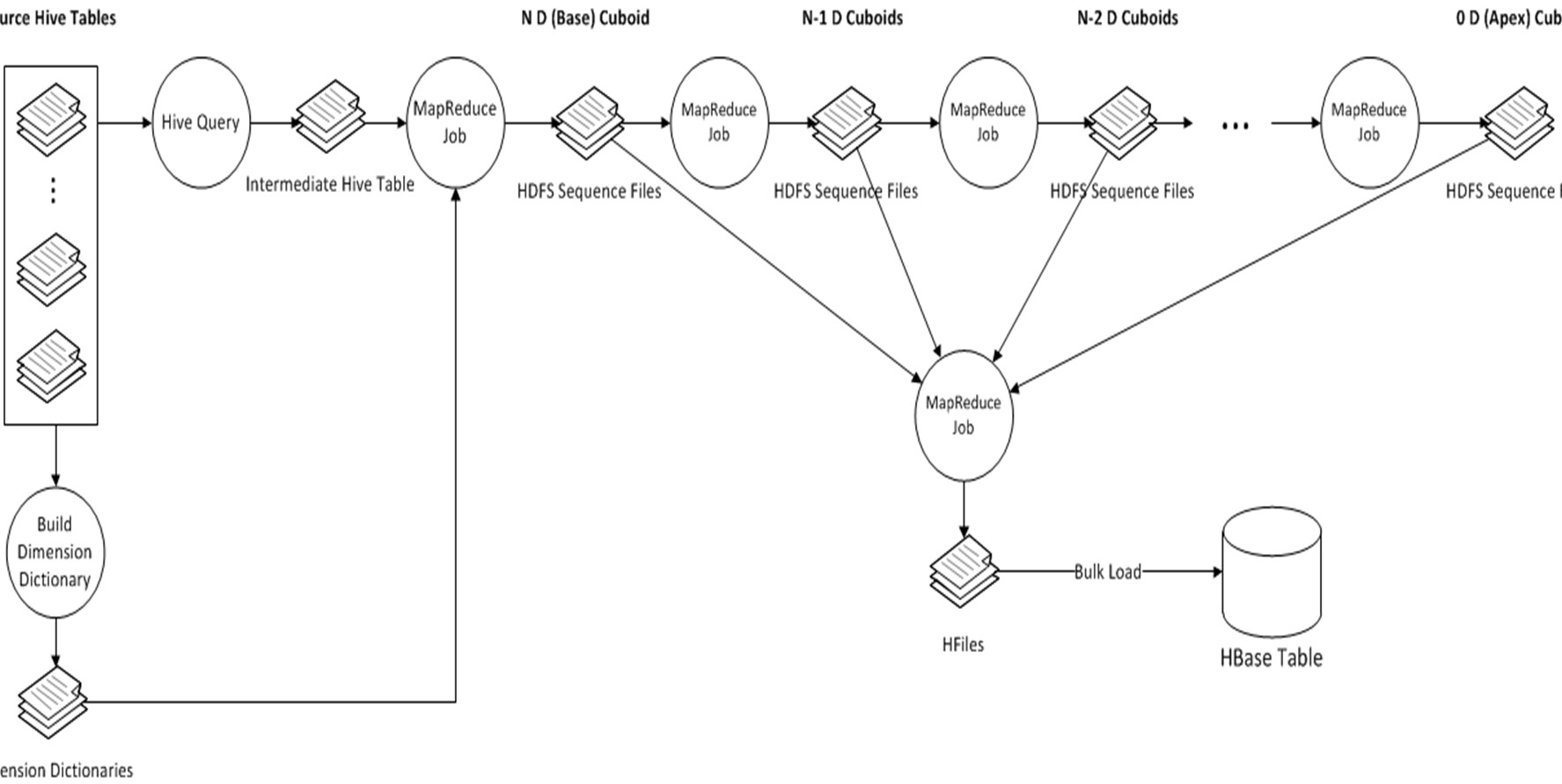
主要的步驟可以按照順序分為幾個階段:
1、根據使用者的cube資訊計算出多個cuboid檔案;
2、根據cuboid檔案生成htable;
3、更新cube資訊;
4、回收臨時檔案。
每一個階段操作的輸入都需要依賴於上一步的輸出,所以這些操作全是順序執行的。下面對這幾個階段的內容細分為11步具體講解一下:
4.1 建立Hive事實表中間表(Create Intermediate Flat Hive Table)
這一步的操作會新建立一個hive外部表,然後再根據cube中定義的星狀模型,查詢出維度和度量的值插入到新建立的表中,這個表是一個外部表,表的資料檔案(儲存在HDFS)作為下一個子任務的輸入。
4.2 重新分配中間表(Redistribute Flat Hive Table)
在前面步驟,hive會在HDFS資料夾中生成資料檔案,一些檔案非常大,一些有些小,甚至是空的。檔案分佈不平衡會導致隨後的MR作業不平衡:一些mappers作業很快執行完畢,但其它的則非常緩慢。為了平衡作業,kylin增加這一步“重新分配”資料。首先,kylin獲取到這中間表的行數,然後根據行數的數量,它會重新分配檔案需要的資料量。預設情況下,kylin分配每100萬行一個檔案。
4.3 提取事實表不同列值 (Extract Fact Table Distinct Columns)
在這一步是根據上一步生成的hive中間表計算出每一個出現在事實表中的維度列的distinct值,並寫入到檔案中,它是啟動一個MR任務完成的,它關聯的表就是上一步建立的臨時表,如果某一個維度列的distinct值比較大,那麼可能導致MR任務執行過程中的OOM。
4.4 建立維度字典(Build Dimension Dictionary)
這一步是根據上一步生成的distinct column檔案和維度表計算出所有維度的子典資訊,並以字典樹的方式壓縮編碼,生成維度字典,子典是為了節約儲存而設計的。
每一個cuboid的成員是一個key-value形式儲存在hbase中,key是維度成員的組合,但是一般情況下維度是一些字串之類的值(例如商品名),所以可以通過將每一個維度值轉換成唯一整數而減少記憶體佔用,在從hbase查找出對應的key之後再根據子典獲取真正的成員值。
4.5 儲存Cuboid的統計資訊(Save Cuboid Statistics)
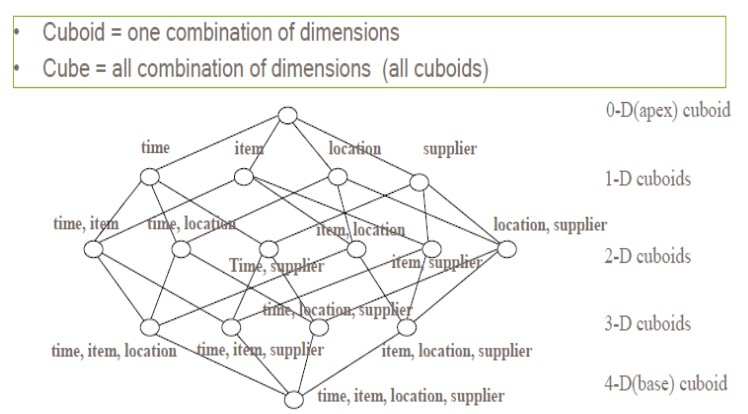
計算和統計所有的維度組合,並儲存,其中,每一種維度組合,稱為一個Cuboid。理論上來說,一個N維的Cube,便有2的N次方種維度組合,參考網上的一個例子,一個Cube包含time, item, location, supplier四個維度,那麼組合(Cuboid)便有16種:
4.6 建立HTable
建立一個HTable的時候還需要考慮一下幾個事情:
1、列簇的設定。
2、每一個列簇的壓縮方式。
3、部署coprocessor。
4、HTable中每一個region的大小。
在這一步中,列簇的設定是根據使用者建立cube時候設定的,在HBase中儲存的資料key是維度成員的組合,value是對應聚合函式的結果,列簇針對的是value的,一般情況下在建立cube的時候只會設定一個列簇,該列包含所有的聚合函式的結果;
在建立HTable時預設使用LZO壓縮,如果不支援LZO則不進行壓縮,在後面kylin的版本中支援更多的壓縮方式;
kylin強依賴於HBase的coprocessor,所以需要在建立HTable為該表部署coprocessor,這個檔案會首先上傳到HBase所在的HDFS上,然後在表的元資訊中關聯,這一步很容易出現錯誤,例如coprocessor找不到了就會導致整個regionServer無法啟動,所以需要特別小心;region的劃分已經在上一步確定了,所以這裡不存在動態擴充套件的情況,所以kylin建立HTable使用的介面如下:
public void createTable(final HTableDescriptor desc , byte [][] splitKeys)
4.7 用Spark引擎構建Cube(Build Cube with Spark)
在Kylin的Cube模型中,每一個cube是由多個cuboid組成的,理論上有N個普通維度的cube可以是由2的N次方個cuboid組成的,那麼我們可以計算出最底層的cuboid,也就是包含全部維度的cuboid(相當於執行一個group by全部維度列的查詢),然後在根據最底層的cuboid一層一層的向上計算,直到計算出最頂層的cuboid(相當於執行了一個不帶group by的查詢),其實這個階段kylin的執行原理就是這個樣子的,不過它需要將這些抽象成mapreduce模型,提交Spark作業執行。
使用Spark,生成每一種維度組合(Cuboid)的資料。
Build Base Cuboid Data;
Build N-Dimension Cuboid Data : 7-Dimension;
Build N-Dimension Cuboid Data : 6-Dimension;
……
Build N-Dimension Cuboid Data : 2-Dimension;
Build Cube。
4.8 將Cuboid資料轉換成HFile(Convert Cuboid Data to HFile)
建立完了HTable之後一般會通過插入介面將資料插入到表中,但是由於cuboid中的資料量巨大,頻繁的插入會對Hbase的效能有非常大的影響,所以kylin採取了首先將cuboid檔案轉換成HTable格式的Hfile檔案,然後在通過bulkLoad的方式將檔案和HTable進行關聯,這樣可以大大降低Hbase的負載,這個過程通過一個MR任務完成。
4.9 導HFile入HBase表(Load HFile to HBase Table)
將HFile檔案load到HTable中,這一步完全依賴於HBase的工具。這一步完成之後,資料已經儲存到HBase中了,key的格式由cuboid編號+每一個成員在字典樹的id組成,value可能儲存在多個列組裡,包含在原始資料中按照這幾個成員進行GROUP BY計算出的度量的值。
4.10 更新Cube資訊(Update Cube Info)
更新cube的狀態,其中需要更新的包括cube是否可用、以及本次構建的資料統計,包括構建完成的時間,輸入的record數目,輸入資料的大小,儲存到Hbase中資料的大小等,並將這些資訊持久到元資料庫中。
4.11 清理Hive中間表(Hive Cleanup)
這一步是否成功對正確性不會有任何影響,因為經過上一步之後這個segment就可以在這個cube中被查詢到了,但是在整個執行過程中產生了很多的垃圾檔案,其中包括:
1、臨時的hive表;
2、因為hive表是一個外部表,儲存該表的檔案也需要額外刪除;
3、fact distinct這一步將資料寫入到HDFS上為建立子典做準備,這時候也可以刪除了;
4、rowKey統計的時候會生成一個檔案,此時可以刪除;
5、生成HFile時檔案儲存的路徑和hbase真正儲存的路徑不同,雖然load是一個remove操作,但是上層的目錄還是存在的,也需要刪除。
至此整個Build過程結束