
多執行緒系列五:併發工具類和併發容器
一、併發容器
1.ConcurrentHashMap
為什麼要使用ConcurrentHashMap
在多執行緒環境下,使用HashMap進行put操作會引起死迴圈,導致CPU利用率接近100%,HashMap在併發執行put操作時會引起死迴圈,是因為多執行緒會導致HashMap的Entry連結串列
形成環形資料結構,一旦形成環形資料結構,Entry的next節點永遠不為空,就會產生死迴圈獲取Entry。
HashTable容器使用synchronized來保證執行緒安全,但線上程競爭激烈的情況下HashTable的效率非常低下。因為當一個執行緒訪問HashTable的同步方法,其他執行緒也訪問HashTable的同步方法時,會進入阻塞或輪詢狀態。如執行緒1使用put進行元素新增,執行緒2不但不能使用put方法新增元素,也不能使用get方法來獲取元素,所以競爭越激烈效率越低。
ConcurrentHashMap的一些有用的方法
很多時候我們希望在元素不存在時插入元素,我們一般會像下面那樣寫程式碼
synchronized(map){
if (map.get(key) == null){
return map.put(key, value);
} else{
return map.get(key);
}
}
putIfAbsent(key,value)方法原子性的實現了同樣的功能
V putIfAbsent(K key, V value)
如果key對應的value不存在,則put進去,返回null。否則不put,返回已存在的value。
boolean remove(Object key, Object value)
如果key對應的值是value,則移除K-V,返回true。否則不移除,返回false。
boolean replace(K key, V oldValue, V newValue)
如果key對應的當前值是oldValue,則替換為newValue,返回true。否則不替換,返回false。
Hash的解釋
雜湊,任意長度的輸入,通過一種演算法,變換成固定長度的輸出。屬於壓縮的對映。
hash演算法示例圖演示:
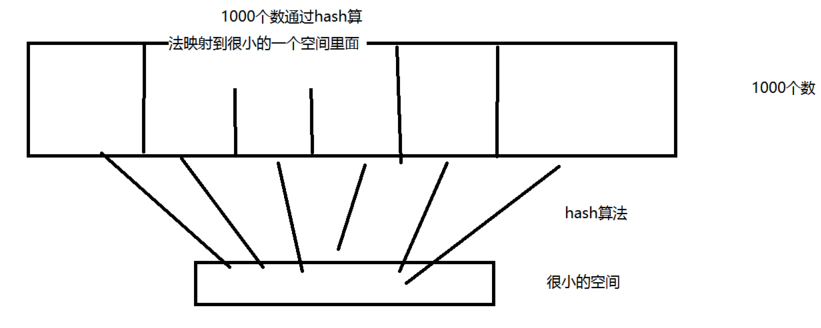
類似於HaspMap的實現就是使用雜湊,比如把1000個元素放到長度為10的hashmap裡面去,放入之前會把這1000個數經過hash演算法對映到10個數組裡面去,這時候就會存在相同的對映值在一個數組的相同位置,就會產生hash碰撞,此時hashmap就會在產生碰撞的陣列的後面使用Entry連結串列來儲存相同對映的值,然後使用equals方法來判斷同一個連結串列儲存的值是否一樣來獲取值,連結串列就是hashmap用來解決碰撞的方法,所以我們一般在寫一個類的時候要寫自己的hashcode方法和equals方法,如果鍵的hashcode相同,再使用鍵的equals方法判斷鍵內容是不是一樣的,一樣的就獲取值
Md5,Sha,取餘都是雜湊演算法,ConcurrentHashMap中是wang/jenkins演算法
ConcurrentHashMap在1.7下的實現
分段鎖的設計思想。
分段鎖的思想示例圖:
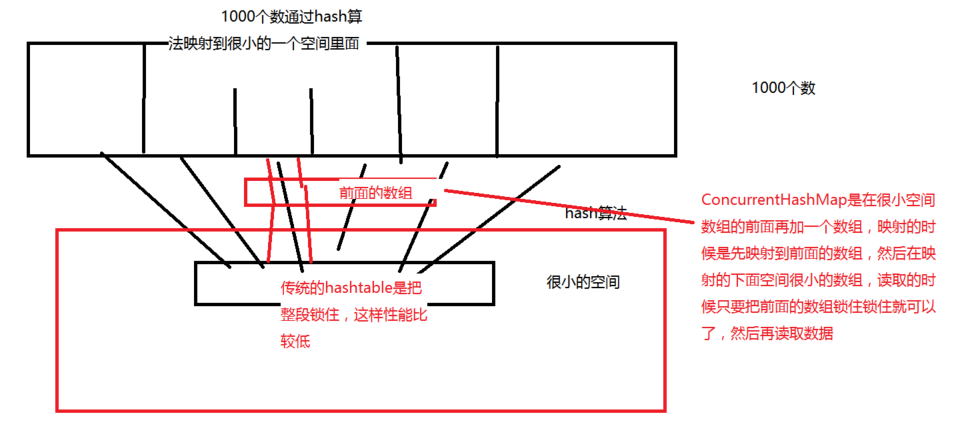
說明:
a)傳統的hashtable是很小空間的陣列整段鎖住,這樣效能比較低
b)ConcurrentHashMap是在很小空間陣列的前面再加一個數組,對映的時候先對映到前面的陣列,然後再對映到後面的很小空間的陣列;讀取的時候只需要把前面的陣列鎖住就可以了。這就是分段鎖的思想
ConcurrentHashMap是由Segment陣列結構和HashEntry陣列結構組成。Segment實際是一種可重入鎖(ReentrantLock),也就是用於分段的鎖。HashEntry則用於儲存鍵值對資料。一個ConcurrentHashMap裡包含一個Segment陣列。Segment的結構和HashMap類似,是一種陣列和連結串列結構。一個Segment裡包含一個HashEntry陣列,每個HashEntry是一個連結串列結構的元素,每個Segment守護著一個HashEntry數組裡的元素,當對HashEntry陣列的資料進行修改時,必須首先獲得與它對應的Segment鎖。
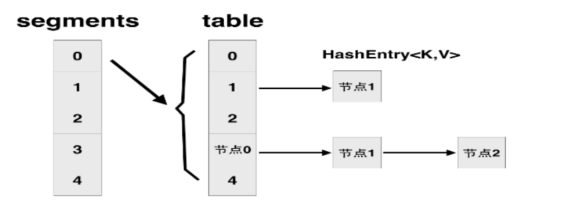
說明:上圖存在兩次雜湊的過程:比如插入一個1000的數,首先是把1000的位數(最多是高16位)做一次雜湊找到在segments陣列中的位置,然後再把1000本身做一次雜湊找到在table中的位置
獲取值時一樣
ConcurrentHashMap初始化方法是通過initialCapacity、loadFactor和concurrencyLevel(引數concurrencyLevel是使用者估計的併發級別,就是說你覺得最多有多少執行緒共同修改這個map,根據這個來確定Segment陣列的大小concurrencyLevel預設是DEFAULT_CONCURRENCY_LEVEL = 16;)。
ConcurrentHashMap完全允許多個讀操作併發進行,讀操作並不需要加鎖。ConcurrentHashMap實現技術是保證HashEntry幾乎是不可變的。HashEntry代表每個hash鏈中的一個節點,可以看到其中的物件屬性要麼是final的,要麼是volatile的。
總結:ConcurrentHashMap在1.7及以下的實現使用陣列+連結串列的方式,採用了分段鎖的思想
ConcurrentHashMap在1.8下的實現
改進一:取消segments欄位,直接採用transient volatile HashEntry<K,V>[] table儲存資料,採用table陣列元素作為鎖,從而實現了對每一行資料進行加鎖,進一步減少併發衝突的概率。
改進二:將原先table陣列+單向連結串列的資料結構,變更為table陣列+單向連結串列+紅黑樹的結構。對於個數超過8(預設值)的列表,jdk1.8中採用了紅黑樹的結構,那麼查詢的時間複雜度可以降低到O(logN),可以改進效能。
總結:ConcurrentHashMap在1.8下的實現使用陣列+連結串列+紅黑樹的方式,當連結串列個數超過8的時候就把原來的連結串列轉成紅黑樹,使用紅黑樹來存取,採用了元素鎖的思想
2. ConcurrentSkipListMap 和ConcurrentSkipListSet
ConcurrentSkipListMap TreeMap的併發實現
ConcurrentSkipListSet TreeSet的併發實現
瞭解什麼是SkipList?
二分查詢和AVL樹查詢
二分查詢要求元素可以隨機訪問,所以決定了需要把元素儲存在連續記憶體。這樣查詢確實很快,但是插入和刪除元素的時候,為了保證元素的有序性,就需要大量的移動元素了。
如果需要的是一個能夠進行二分查詢,又能快速新增和刪除元素的資料結構,首先就是二叉查詢樹,二叉查詢樹在最壞情況下可能變成一個連結串列。
於是,就出現了平衡二叉樹,根據平衡演算法的不同有AVL樹,B-Tree,B+Tree,紅黑樹等,但是AVL樹實現起來比較複雜,平衡操作較難理解,這時候就可以用SkipList跳躍表結構。
傳統意義的單鏈表是一個線性結構,向有序的連結串列中插入一個節點需要O(n)的時間,查詢操作需要O(n)的時間。

如果我們使用上圖所示的跳躍表,就可以減少查詢所需時間為O(n/2),因為我們可以先通過每個節點的最上面的指標先進行查詢,這樣子就能跳過一半的節點。
比如我們想查詢19,首先和6比較,大於6之後,在和9進行比較,然後在和12進行比較......最後比較到21的時候,發現21大於19,說明查詢的點在17和21之間,從這個過程中,我們可以看出,查詢的時候跳過了3、7、12等點,因此查詢的複雜度為O(n/2)。
跳躍表其實也是一種通過“空間來換取時間”的一個演算法,通過在每個節點中增加了向前的指標,從而提升查詢的效率。
跳躍表又被稱為概率,或者說是隨機化的資料結構,目前開源軟體 Redis 和 lucence都有用到它。
3. ConcurrentLinkedQueue 無界非阻塞佇列
ConcurrentLinkedQueue LinkedList 併發版本
Add,offer:新增元素
Peek():get頭元素並不把元素拿走
poll():get頭元素把元素拿走
4. CopyOnWriteArrayList和CopyOnWriteArraySet
寫的時候進行復制,可以進行併發的讀。
適用讀多寫少的場景:比如白名單,黑名單,商品類目的訪問和更新場景,假如我們有一個搜尋網站,使用者在這個網站的搜尋框中,輸入關鍵字搜尋內容,但是某些關鍵字不允許被搜尋。這些不能被搜尋的關鍵字會被放在一個黑名單當中,黑名單每天晚上更新一次。當用戶搜尋時,會檢查當前關鍵字在不在黑名單當中,如果在,則提示不能搜尋。
弱點:記憶體佔用高,資料一致性弱
總結:寫的時候重新複製一份資料,然後在複製的資料裡面寫入資料,寫完以後再把原來的資料的引用執行復制的資料,所以存在資料的弱一致性,適用於讀多寫少的場景
5.什麼是阻塞佇列
取資料和存資料不滿足要求時,會對執行緒進行阻塞。例如取資料時發現佇列裡面沒有資料就在那裡阻塞等著有資料了再取;存資料時發現佇列已經滿了就在那裡阻塞等著有資料被取走時再存
| 方法 |
丟擲異常 |
返回值 |
一直阻塞 |
超時退出 |
| 插入 |
Add |
offer |
put |
offer |
| 移除 |
remove |
poll |
take |
poll |
| 檢查 |
element |
peek |
沒有 |
沒有 |
常用阻塞佇列
ArrayBlockingQueue: 陣列結構組成有界阻塞佇列。
先進先出原則,初始化必須傳大小,take和put時候用的同一把鎖
LinkedBlockingQueue:連結串列結構組成的有界阻塞佇列
先進先出原則,初始化可以不傳大小,put,take鎖分離
PriorityBlockingQueue:支援優先順序排序的無界阻塞佇列,
排序,自然順序升序排列,更改順序:類自己實現compareTo()方法,初始化PriorityBlockingQueue指定一個比較器Comparator
DelayQueue: 使用了優先順序佇列的無界阻塞佇列
支援延時獲取,佇列裡的元素要實現Delay介面。DelayQueue非常有用,可以將DelayQueue運用在以下應用場景。
快取系統的設計:可以用DelayQueue儲存快取元素的有效期,使用一個執行緒迴圈查詢DelayQueue,一旦能從DelayQueue中獲取元素時,表示快取有效期到了。
還有訂單到期,限時支付等等。
SynchronousQueue:不儲存元素的阻塞佇列
每個put操作必須要等take操作
LinkedTransferQueue:連結串列結構組成的無界阻塞佇列
Transfer,tryTransfer,生產者put時,當前有消費者take,生產者直接把元素傳給消費者
LinkedBlockingDeque:連結串列結構組成的雙向阻塞佇列
可以在佇列的兩端插入和移除,xxxFirst頭部操作,xxxLast尾部操作。工作竊取模式。
瞭解阻塞佇列的實現原理
使用了Condition實現。
生產者消費者模式
在併發程式設計中使用生產者和消費者模式能夠解決絕大多數併發問題。該模式通過平衡生
產執行緒和消費執行緒的工作能力來提高程式整體處理資料的速度。
線上程世界裡,生產者就是生產資料的執行緒,消費者就是消費資料的執行緒。在多執行緒開發
中,如果生產者處理速度很快,而消費者處理速度很慢,那麼生產者就必須等待消費者處理
完,才能繼續生產資料。同樣的道理,如果消費者的處理能力大於生產者,那麼消費者就必須等待生產者。為了解決這種生產消費能力不均衡的問題,便有了生產者和消費者模式。
生產者和消費者模式是通過一個容器來解決生產者和消費者的強耦合問題。生產者和消費者彼此之間不直接通訊,而是通過阻塞佇列來進行通訊,所以生產者生產完資料之後不用等待消費者處理,直接扔給阻塞佇列,消費者不找生產者要資料,而是直接從阻塞佇列裡取,阻塞佇列就相當於一個緩衝區,平衡了生產者和消費者的處理能力。
什麼是Fork/Join框架
並行執行任務的框架,把大任務拆分成很多的小任務,彙總每個小任務的結果得到大任務的結果。
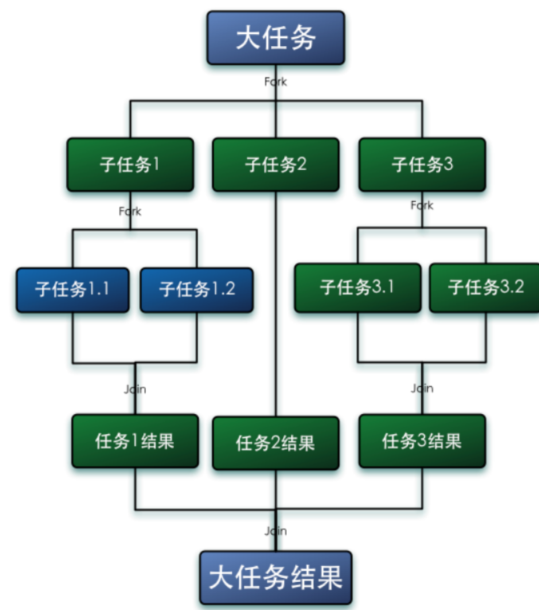
工作竊取演算法
工作竊取(work-stealing)演算法是指某個執行緒從其他佇列裡竊取任務來執行,執行完以後把結果放回去
那麼,為什麼需要使用工作竊取演算法呢?假如我們需要做一個比較大的任務,可以把這個任務分割為若干互不依賴的子任務,為了減少執行緒間的競爭,把這些子任務分別放到不同的佇列裡,併為每個佇列建立一個單獨的執行緒來執行佇列裡的任務,執行緒和佇列一一對應。
比如A執行緒負責處理A佇列裡的任務。但是,有的執行緒會先把自己佇列裡的任務幹完,而其他執行緒對應的佇列裡還有任務等待處理。幹完活的執行緒與其等著,不如去幫其他執行緒幹活,於是它就去其他執行緒的佇列裡竊取一個任務來執行。而在這時它們會訪問同一個佇列,所以為了減少竊取任務執行緒和被竊取任務執行緒之間的競爭,通常會使用雙端佇列,被竊取任務執行緒永遠從雙端佇列的頭部拿任務執行,而竊取任務的執行緒永遠從雙端佇列的尾部拿任務執行。
Fork/Join框架的使用
Fork/Join使用兩個類來完成以上兩件事情。
①ForkJoinTask:我們要使用ForkJoin框架,必須首先建立一個ForkJoin任務。它提供在任務
中執行fork()和join()操作的機制。通常情況下,我們不需要直接繼承ForkJoinTask類,只需要繼承它的子類,Fork/Join框架提供了以下兩個子類。
·RecursiveAction:用於沒有返回結果的任務。
·RecursiveTask:用於有返回結果的任務。
②ForkJoinPool:ForkJoinTask需要通過ForkJoinPool來執行。
Fork/Join有同步和非同步兩種方式。
案例1:孫悟空摘桃子fork/join的案例

1 /**
2 * 孫悟空摘桃子fork/join的案例,孫悟空去摘桃子時發現桃子太多就讓猴子猴孫去幫忙在桃子,
3 * 摘完以後再統一彙總求和
4 */
5 public class ForkJoinWuKong {
6
7 private static class XiaoWuKong extends RecursiveTask<Integer>{
8
9 private final static int THRESHOLD = 100;//閾值,陣列多小的時候,不再進行任務拆分操作
10 private PanTao[] src;
11 private int fromIndex;
12 private int toIndex;
13 private IPickTaoZi pickTaoZi;
14
15 public XiaoWuKong(PanTao[] src, int fromIndex, int toIndex, IPickTaoZi pickTaoZi) {
16 this.src = src;
17 this.fromIndex = fromIndex;
18 this.toIndex = toIndex;
19 this.pickTaoZi = pickTaoZi;
20 }
21
22 @Override
23 protected Integer compute() {
24 //計算完以後結果彙總
25 if (toIndex-fromIndex<THRESHOLD){
26 int count =0 ;
27 for(int i=fromIndex;i<toIndex;i++){
28 if (pickTaoZi.pick(src,i)) count++;
29 }
30 return count;
31 }
32 //大任務拆分成小任務
33 else{
34 //fromIndex....mid......toIndex
35 int mid = (fromIndex+toIndex)/2;
36 XiaoWuKong left = new XiaoWuKong(src,fromIndex,mid,pickTaoZi);
37 XiaoWuKong right = new XiaoWuKong(src,mid,toIndex,pickTaoZi);
38 invokeAll(left,right);
39 return left.join()+right.join();
40
41 }
42 }
43 }
44
45 public static void main(String[] args) {
46
47 ForkJoinPool pool = new ForkJoinPool();
48 PanTao[] src = MakePanTaoArray.makeArray();
49 IProcessTaoZi processTaoZi = new WuKongProcessImpl();
50 IPickTaoZi pickTaoZi = new WuKongPickImpl(processTaoZi);
51
52 long start = System.currentTimeMillis();
53
54 //構造一個ForkJoinTask
55 XiaoWuKong xiaoWuKong = new XiaoWuKong(src,0,
56 src.length-1,pickTaoZi);
57
58 //ForkJoinTask交給ForkJoinPool來執行。
59 pool.invoke(xiaoWuKong);
60
61 System.out.println("The count is "+ xiaoWuKong.join()
62 +" spend time:"+(System.currentTimeMillis()-start)+"ms");
63
64 }
65
66 }
案例2:使用Fork/Join框架實現計算1+2+3+....+100的結果
package com.study.demo.forkjoin;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.ForkJoinPool;
import java.util.concurrent.Future;
import java.util.concurrent.RecursiveTask;
/**
* Fork/Join框架設計思路:
* 第一步:分割任務。首先我們需要有一個fork類來把大任務分割成子任務,有可能子任務還是很大,所以還需要
* 不停的分割,直到分割出的子任務足夠小。
* 第二步:執行任務併合並結果。分割的子任務分別放在雙端佇列裡,然後啟動幾個執行緒分別從雙端佇列裡獲取任務執行。
* 子任務執行完的結果都統一放在一個佇列裡,啟動一個執行緒從佇列裡拿資料,然後合併這些資料。
*
* Fork/Join框架的具體實現:
* Fork/Join使用兩個類來完成以上兩件事情:
* ForkJoinTask:我們要使用ForkJoin框架,必須首先建立一個ForkJoin任務。它提供在任務中執行fork()和join()
* 操作的機制,通常情況下我們不需要直接繼承ForkJoinTask類,而只需要繼承它的子類,Fork/Join框架提供了以下兩個子類:
* RecursiveAction:用於沒有返回結果的任務。
* RecursiveTask :用於有返回結果的任務。
* ForkJoinPool :ForkJoinTask需要通過ForkJoinPool來執行,任務分割出的子任務會新增到當前工作執行緒所維護的雙端佇列中,
* 進入佇列的頭部。當一個工作執行緒的佇列裡暫時沒有任務時,它會隨機從其他工作執行緒的佇列的尾部獲取一個任務。
*
* 實戰:使用Fork/Join框架實現計算1+2+3+....+100的結果-100個數拆分成10個(閾值)子任務來執行最後彙總結果
*
*/
public class CountTask extends RecursiveTask<Integer> {
/**
* 序列化
*/
private static final long serialVersionUID = 1L;
private static final int THRESHOLD = 10;// 閾值
private int start;
private int end;
public CountTask(int start, int end) {
this.start = start;
this.end = end;
}
@Override
protected Integer compute() {
int sum = 0;
// 如果任務足夠小就計算任務
boolean canCompute = (end - start) <= THRESHOLD;
if (canCompute) {
for (int i = start; i <= end; i++) {
sum += i;
}
} else {
// 如果任務大於閥值,就分裂成兩個子任務計算
int middle = (start + end) / 2;
CountTask leftTask = new CountTask(start, middle);
CountTask rightTask = new CountTask(middle + 1, end);
// 執行子任務
leftTask.fork();
rightTask.fork();
// 等待子任務執行完,並得到其結果
int leftResult = leftTask.join();
int rightResult = rightTask.join();
// 合併子任務
sum = leftResult + rightResult;
}
return sum;
}
public static void main(String[] args) {
ForkJoinPool forkJoinPool = new ForkJoinPool();
// 生成一個計算任務,負責計算1+2+3+4
CountTask task = new CountTask(1, 100);
// 執行一個任務
Future result = forkJoinPool.submit(task);
try {
System.out.println(result.get());
} catch (InterruptedException e) {
} catch (ExecutionException e) {
}
}
}
二、併發工具類
1. CountDownLatch
允許一個或多個執行緒等待其他執行緒完成操作。CountDownLatch的建構函式接收一個int型別的引數作為計數器,如果你想等待N個點完成,這裡就傳入N。當我們呼叫CountDownLatch的countDown方法時,N就會減1,CountDownLatch的await方法會阻塞當前執行緒,直到N變成零。
由於countDown方法可以用在任何地方,所以這裡說的N個點,可以是N個執行緒,也可以是1個執行緒裡的N個執行步驟。用在多個執行緒時,只需要把這個CountDownLatch的引用傳遞到執行緒裡即可。
1 public class CountDownLatchCase {
2
3 static CountDownLatch c = new CountDownLatch(7);
4
5 private static class SubThread implements Runnable{
6
7 @Override
8 public void run() {
9 System.out.println(Thread.currentThread().getId());
10 c.countDown();
11 System.out.println(Thread.currentThread().getId()+" is done");
12 }
13 }
14
15 public static void main(String[] args) throws InterruptedException {
16
17 new Thread(new Runnable() {
18 @Override
19 public void run() {
20 System.out.println(Thread.currentThread().getId());
21 c.countDown();
22 System.out.println("sleeping...");
23 try {
24 Thread.sleep(1500);
25 } catch (InterruptedException e) {
26 e.printStackTrace();
27 }
28 System.out.println("sleep is completer");
29 c.countDown();
30 }
31 }).start();
32
33 for(int i=0;i<=4;i++){
34 Thread thread = new Thread(new SubThread());
35 thread.start();
36 }
37
38 c.await();
39 System.out.println("Main will gone.....");
40 }
41 }
2. CyclicBarrier
CyclicBarrier的字面意思是可迴圈使用(Cyclic)的屏障(Barrier)。它要做的事情是,讓一組執行緒到達一個屏障(也可以叫同步點)時被阻塞,直到最後一個執行緒到達屏障時,屏障才會開門,所有被屏障攔截的執行緒才會繼續執行。CyclicBarrier預設的構造方法是CyclicBarrier(int parties),其引數表示屏障攔截的執行緒數量,每個執行緒呼叫await方法告訴CyclicBarrier我已經到達了屏障,然後當前執行緒被阻塞。
1 public class CyclicBarrriesBase {
2
3 static CyclicBarrier c = new CyclicBarrier(2);
4
5 public static void main(String[] args) throws InterruptedException, BrokenBarrierException {
6 new Thread(new Runnable() {
7 @Override
8 public void run() {
9 System.out.println(Thread.currentThread().getId());
10 try {
11 c.await();//等待主執行緒完成
12 System.out.println(Thread.currentThread().getId()+"is going");
13 } catch (InterruptedException e) {
14 e.printStackTrace();
15 } catch (BrokenBarrierException e) {
16 e.printStackTrace();
17 }
18 System.out.println("sleeping...");
19
20 }
21 }).start();
22
23 System.out.println("main will sleep.....");
24 Thread.sleep(2000);
25 c.await();////等待子執行緒完成
26
27 System.out.println("All are complete.");
28 }
29
30
31
32 }
CyclicBarrier還提供一個更高階的建構函式CyclicBarrier(int parties,Runnable barrierAction),用於線上程到達屏障時,優先執行barrierAction,方便處理更復雜的業務場景。
CyclicBarrier可以用於多執行緒計算資料,最後合併計算結果的場景。
1 public class CyclicBarrierSum {
2
3 static CyclicBarrier c = new CyclicBarrier(5,new SumThread());
4 //子執行緒結果存放的快取
5 private static ConcurrentHashMap<String,Integer> resultMap =
6 new ConcurrentHashMap<>();
7
8 //所有子執行緒達到屏障後,會執行這個Runnable的任務
9 private static class SumThread implements Runnable{
10
11 @Override
12 public void run() {
13 int result =0;
14 for(Map.Entry<String,Integer> workResult:resultMap.entrySet()){
15 result = result+workResult.getValue();
16 }
17 System.out.println("result = "+result);
18 System.out.println("完全可以做與子執行緒,統計無關的事情.....");
19 }
20 }
21
22 //工作執行緒,也就是子執行緒
23 private static class WorkThread implements Runnable{
24
25 private Random t = new Random();
26
27 @Override
28 public void run() {
29 int r = t.nextInt(1000)+1000;
30 System.out.println(Thread.currentThread().getId()+":r="+r);
31 resultMap.put(Thread.currentThread().getId()+"",r);
32 try {
33 Thread.sleep(1000+r);
34 c.await();
35 } catch (InterruptedException e) {
36 e.printStackTrace();
37 } catch (BrokenBarrierException e) {
38 e.printStackTrace();
39 }
40
41 }
42 }
43
44 public static void main(String[] args) {
45 for(int i=0;i<=4;i++){
46 Thread thread = new Thread(new WorkThread());
47 thread.start();
48 }
49 }
50 }
CyclicBarrier和CountDownLatch的區別
CountDownLatch的計數器只能使用一次,而CyclicBarrier的計數器可以使用reset()方法重置,CountDownLatch.await一般阻塞主執行緒,所有的工作執行緒執行countDown,而CyclicBarrierton通過工作執行緒呼叫await從而阻塞工作執行緒,直到所有工作執行緒達到屏障。
4. 控制併發執行緒數的Semaphore
Semaphore(訊號量)是用來控制同時訪問特定資源的執行緒數量,它通過協調各個執行緒,以保證合理的使用公共資源。應用場景Semaphore可以用於做流量控制,特別是公用資源有限的應用場景,比如資料庫連線。假如有一個需求,要讀取幾萬個檔案的資料,因為都是IO密集型任務,我們可以啟動幾十個執行緒併發地讀取,但是如果讀到記憶體後,還需要儲存到資料庫中,而資料庫的連線數只有10個,這時我們必須控制只有10個執行緒同時獲取資料庫連線儲存資料,否則會報錯無法獲取資料庫連線。這個時候,就可以使用Semaphore來做流量控制。。Semaphore的構造方法Semaphore(int permits)接受一個整型的數字,表示可用的許可證數量。Semaphore的用法也很簡單,首先執行緒使用Semaphore的acquire()方法獲取一個許可證,使用完之後呼叫release()方法歸還許可證。還可以用tryAcquire()方法嘗試獲取許可證。
1 public class SemaphporeCase<T> {
2
3 private final Semaphore items;//有多少元素可拿
4 private final Semaphore space;//有多少空位可放元素
5 private List queue = new LinkedList<>();
6
7 public SemaphporeCase(int itemCounts){
8 this.items = new Semaphore(0);
9 this.space = new Semaphore(itemCounts);
10 }
11
12 //放入資料
13 public void put(T x) throws InterruptedException {
14 space.acquire();//拿空位的許可,沒有空位執行緒會在這個方法上阻塞
15 synchronized (queue){
16 queue.add(x);
17 }
18 items.release();//有元素了,可以釋放一個拿元素的許可
19 }
20
21 //取資料
22 public T take() throws InterruptedException {
23 items.acquire();//拿元素的許可,沒有元素執行緒會在這個方法上阻塞
24 T t;
25 synchronized (queue){
26 t = (T)queue.remove(0);
27 }
28 space.release();//有空位了,可以釋放一個存在空位的許可
29 return t;
30 }
31 }
Semaphore還提供一些其他方法,具體如下。
·intavailablePermits():返回此訊號量中當前可用的許可證數。
·intgetQueueLength():返回正在等待獲取許可證的執行緒數。
·booleanhasQueuedThreads():是否有執行緒正在等待獲取許可證。
·void reducePermits(int reduction):減少reduction個許可證,是個protected方法。
·Collection getQueuedThreads():返
5. Exchanger
Exchanger(交換者)是一個用於執行緒間協作的工具類。Exchanger用於進行執行緒間的資料交換。它提供一個同步點,在這個同步點,兩個執行緒可以交換彼此的資料。這兩個執行緒通過exchange方法交換資料,如果第一個執行緒先執行exchange()方法,它會一直等待第二個執行緒也執行exchange方法,當兩個執行緒都到達同步點時,這兩個執行緒就可以交換資料,將本執行緒生產出來的資料傳遞給對方。
1 public class ExchangeCase {
2
3 static final Exchanger<List<String>> exgr = new Exchanger<>();
4
5 public static void main(String[] args) {
6
7 new Thread(new Runnable() {
8
9 @Override
10 public void run() {
11 try {
12 List<String> list = new ArrayList<>();
13 list.add(Thread.currentThread().getId()+" insert A1");
14 list.add(Thread.currentThread().getId()+" insert A2");
15 list = exgr.exchange(list);//交換資料
16 for(String item:list){
17 System.out.println(Thread.currentThread().getId()+":"+item);
18 }
19 } catch (InterruptedException e) {
20 e.printStackTrace();
21 }
22 }
23 }).start();
24
25 new Thread(new Runnable() {
26
27 @Override
28 public void run() {
29 try {
30 List<String> list = new ArrayList<>();
31 list.add(Thread.currentThread().getId()+" insert B1");
32 list.add(Thread.currentThread().getId()+" insert B2");
33 list.add(Thread.currentThread().getId()+" insert B3");
34 System.out.println(Thread.currentThread().getId()+" will sleep");
35 Thread.sleep(1500);
36 list = exgr.exchange(list);//交換資料
37 for(String item:list){
38 System.out.println(Thread.currentThread().getId()+":"+item);
39 }
40 } catch (InterruptedException e) {
41 e.printStackTrace();
42 }
43 }
44 }).start();
45
46 }
47
48 }
一、併發容器
1.ConcurrentHashMap
為什麼要使用ConcurrentHashMap
在多執行緒環境下 1.悲觀鎖和樂觀鎖的基本概念
悲觀鎖:
總是認為當前想要獲取的資源存在競爭(很悲觀的想法),因此獲取資源後會立刻加鎖,於是其他執行緒想要獲取該資源的時候就會一直阻塞直到能夠獲取到鎖;
在傳統的關係型資料庫中,例如行鎖、表鎖、讀鎖、寫鎖等,都用到了悲觀鎖。還有java中的同步關鍵字Synchroniz
java.util.concurrent 包在java語言中可以說是比較難啃的一塊,但理解好這個包下的知識,對學習java來說,不可謂是一種大的提升,我也嘗試著用自己不聰明的腦袋努力的慢慢啃下點東西來。其實 java.util.concurrent 包中,最核心
Grand Central Dispatch(GCD)有很多部分構成,例如有很好的語言特性,執行庫,還提供了系統的、高效的方式來支援具有多核處理器的iOS和OS X裝置進行併發事件處理。
BSD子系統,CoreFoundation和Cocoa APIs 目錄1,獲取當前執行緒資訊2,管理執行緒狀態2.1 啟動與引數傳遞2.1.1 ParameterizedThreadStart2.1.2 使用靜態變數或類成員變數2.1.3 委託與Lambda2.2 暫停與阻塞2.3 執行緒狀態2.4 終止2.5 執行緒的不確定性2.6 執行緒優先順序、前臺執行緒和後臺執行緒 本章主要講述多執行緒競爭下的原子操作。
目錄知識點競爭條件執行緒同步CPU時間片和上下文切換阻塞核心模式和使用者模式Interlocked 類1,出現問題2,Interlocked.Increment()3,Interlocked.Exchange()4,Interlocked.CompareExchange
2018年10月03日
目錄
前言
前言
JVM允許應用程式併發執行多執行緒:最常用的是兩個方法:(1)基礎Thread類,重寫run()方法;(2)或實現Runnable 介面,實現介面的run()方法;(3)另外一種方法是:實現callable 介面 Java記憶體模型和執行緒的三大特性
多執行緒有三大特性:原子性、可見性、有序性
1、Java記憶體模型
Java記憶體模型(Java Memory Model ,JMM),決定一個執行緒對共享變數的寫入時,能對另一個執行緒可見。從抽象的角度來看,JMM定義了執行緒和主記憶體之間的抽象關係:執行緒之間的
原文地址:http://tutorials.jenkov.com/java-concurrency/index.html
以前計算機都是單核,同時只能執行一個程式。之後出現了多重任務處理,這意味著計算機同時可以處理多個程式(又名任務或流程)。但這不是真正的“同時執行”,只是單個CPU被多個程式共 實現多執行緒
java實現多執行緒的方法有三種,分別是繼承thread類,實現runnable介面,實現callable介面(call方法有返回值)
/**
* 繼承Thread
*/
public class MyThread extends Thread{
int a = 0;
CyclicBarrier是java.util.concurrent包下面的一個工具類,字面意思是可迴圈使用(Cyclic)的屏障(Barrier),通過它可以實現讓一組執行緒到達一個屏障(也可以叫同步點)時被阻塞,直到最後一個執行緒到達屏障時,所有被屏障攔截的執
作者:張振華 購買連結:天貓商城
(投入多少,收穫多少。參與多深,領悟多深,京東,亞馬遜,噹噹均有銷售。)
5.1 執行緒安全的阻塞佇列BlockingQueue
(1)先理解一下Queue、Deque、BlockingQueue的概念:
Queue(佇列) :用於儲存一組元素,不 當 Linux 最初開發時,在核心中並不能真正支援執行緒。但是它的確可以通過 clone() 系統呼叫將程序作為可排程的實體。這個呼叫建立了呼叫程序(calling process)的一個拷貝,這個拷貝與呼叫程序共享相同的地址空間。LinuxThreads 專案使用這個呼叫來完全在使用者空間模擬對執行緒的支援
Executor介面介紹ExecutorService常用介面介紹建立執行緒池的一些方法介紹3.1 newFixedThreadPool方法3.2 newCachedThreadPool方法3.3 newScheduledThreadPool方法疑問解答4.1. Runabl
什麼是設計模式 在軟體工程中,設計模式(design pattern)是對軟體設計中普遍存在(反覆出現)的各種問題 ,所提出的解決方案。 架構模式 – MVC – 分層 設計模式 – 提煉系統中的元件 程式碼模式(成例 Idiom)
這篇文章將介紹CountDownLatch這個同步工具類的基本資訊以及通過案例來介紹如何使用這個工具。
CountDownLatch是java.util.concurrent包下面的一個工具類,可以用來協調多個執行緒之間的同步,或者說起到執行緒之間的通訊(而不 死鎖
概念
當執行緒Thread-0持有鎖Lock1,Thread-1持有鎖Lock2,此時Thread-0申請Lock2鎖的使用權,Thread-1申請Lock1鎖的使用權,Thread-0和Thread-1都在無限地等待鎖的使用權。這樣就造成了死鎖。
死鎖是主要由於設計的問題。一旦出現死鎖,死鎖的執行
Android多執行緒分析之一:使用Thread非同步下載影象
羅朝輝 (http://blog.csdn.net/kesalin)
CC 許可,轉載請註明出處
打算整理一下對 Android Framework 中多執行緒相關知識的理解,主要集中在 Fra 轉自:https://www.cnblogs.com/skywang12345/p/3514593.html(含部分修改)
概要
AtomicInteger, AtomicLong和AtomicBoolean這3個基本型別的原子類的原理和用法相似。本章以AtomicLong對基本型別的原子類進行介紹。內容 轉自:https://www.cnblogs.com/skywang12345/p/3514604.html(含部分修改)
概要
AtomicIntegerArray, AtomicLongArray, AtomicReferenceArray這3個數組型別的原子類的原理和用法相似。本章以AtomicLo
相關推薦
多執行緒系列五:併發工具類和併發容器
java多執行緒系列3:悲觀鎖和樂觀鎖
關於java多執行緒淺析五: Condition條件
iOS-多執行緒程式設計學習之GCD——序列佇列和併發佇列(五)
C#多執行緒系列(1):Thread
C#多執行緒系列(3):原子操作
多執行緒學習(4):三種實現Java多執行緒的方法:Thread、Callable和Runable 的比較與區別
(Java多執行緒系列七)Java記憶體模型和執行緒的三大特性
java多執行緒系列翻譯之java併發/多執行緒教程
java多執行緒系列(一):Thread、Runnable、Callable實現多執行緒的區別
java多執行緒系列:通過對戰遊戲學習CyclicBarrier
《 Java併發程式設計從入門到精通》第5章 多執行緒之間互動:執行緒閥
多程序與多執行緒(五)--Linux 執行緒模型的比較:LinuxThreads 和 NPTL(轉)
java多執行緒系列:Executors框架
多執行緒之六:併發設計模式
java多執行緒系列:CountDownLatch
Java多執行緒(五):死鎖
Android多執行緒分析之一:使用Thread非同步下載影象
Java多執行緒系列--“JUC原子類”03之 AtomicLong原子類
Java多執行緒系列---“JUC原子類”04之 AtomicLongArray原子類