
復現一篇深度強化學習論文之前請先看了這篇文章!
去年,OpenAI和DeepMind聯手做了當時最酷的實驗,不用經典的獎勵信號來訓練智能體,而是根據人類反饋進行強化學習的新方法。有篇博客專門講了這個實驗 Learning from Human Preferences,原始論文是《 Deep Reinforcement Learning from Human Preferences》(根據人類偏好進行的深度增強學習)。
鏈接:https://arxiv.org/pdf/1706.03741.pdf

過一些深度強化學習,你也可以訓練木棍做後空翻
我曾經看到過一些建議:復現論文是提高機器學習能力的一種很好的方法,這對我自己來說是一個有趣的嘗試。Learning from Human Preferences 的確是一個很有意思的項目,我很高興能復現它,但是回想起來這段經歷,卻和預期有出入。
如果你也想復現論文,以下是一些深度強化學習的註意事項:
· · ·
首先,通常來說,強化學習要比你預期的要復雜得多。
很大一部分原因是,強化學習非常敏感。有很多細節需要正確處理,如果不正確的話,你很難判斷出哪裏出了問題。
情況1:完成基本實現後,執行訓練卻沒有成功。對於這個問題,我有各種各樣的想法,但結果證明是因為激勵的正則化和關鍵階段1的像素數據。盡管事後我知道是哪裏出了問題,但也找不到可循的通關路徑:基於像素數據的激勵預測器網絡準確性的確很好,我花了很長時間仔細檢查激勵預測器,才發現註意到激勵正則化錯誤。找出問題發生的原因很偶然,因為註意到一個小的差錯,才找到了正確的道路。
情況2:在做最後的代碼清理時,我意識到我把Dropout搞錯了。激勵預測器網絡以一對視頻片段作為輸入,每個視頻片段由兩個具有共享權重的網絡進行相同的處理。如果你在每個網絡中都添加了Dropout,並且不小心忘記給每個網絡提供相同的隨機種子,那麽對於每個網絡,Dropout出的網絡都是不同的,這樣視頻剪輯就不會進行相同的處理了。盡管預測網絡的準確性看起來完全一樣,但實際上完全破壞了原來的網絡訓練。
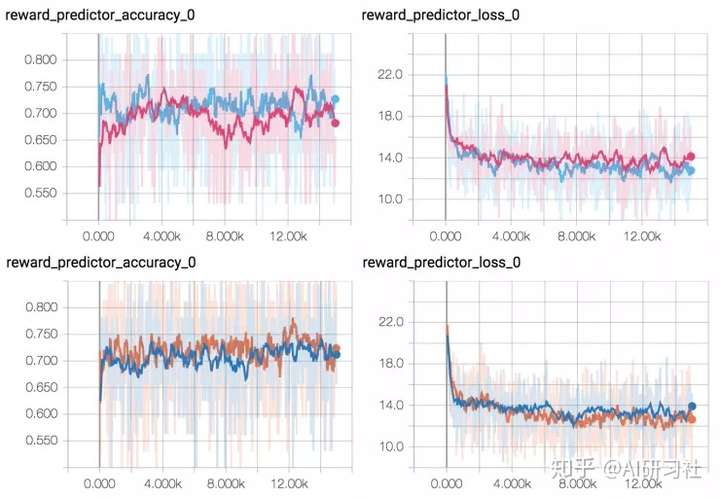
哪一個是壞的?嗯,我也看不明白
我覺得這是經常會發生的事情 (比如:《Deep Reinforcement Learning Doesn’t Work Yet 》)。我的收獲是,當你開始一個強化學習項目的時候,理論上會遇到一個像被數學題困住了一樣的困境。這並不像我通常的編程經驗:在你被困的地方,通常有一條清晰的線索可以遵循,你最多可以在幾天之內擺脫困境。 這更像是當你試圖解決一個難題時,問題沒有明顯的進展,唯一的方法就是各種嘗試,直到你找到關鍵的證據,或者找到重要的靈感,讓你找到答案。
所以結論是在感到疑惑時應該盡可能註意到細節。
在這個項目中有很多要點,唯一的線索來自於註意那些微不足道的小事情。 例如,有時將幀之間的差異作為特征會很有效。直接利用新的特征是很有誘惑力的,但是我意識到,我並不清楚為什麽它對我當時使用的簡單環境產生如此大的影響。 只有處在這樣的困惑下,才能發現,將背景歸零後取幀之間的差異會使得正則化問題顯現出來。
我不太確定怎麽樣能讓人意識這些,但我目前最好的猜測是:
- 學會了解困惑是什麽樣的感覺。 有很多各種各樣“不太對”的感覺。 有時候你知道代碼很難看。 有時候擔心在錯誤的事情上浪費時間。 但有時你看到了一些你沒有預料到的東西:困惑。 能夠認識到不舒服的確切程度是很重要的,這樣你就可以發現問題。
- 養成在困惑中堅持的習慣。 有一些不舒服的地方可以暫時忽略 (例如:原型開發過程中的代碼嗅覺 ),但困惑不能忽略。當你感到到困惑時,盡量去找到原因這是很重要的。
還有,最好做好每幾周就會陷入困境的準備。如果你堅持下去,註意那些小細節並且充滿信心,你就能到達彼岸。
· · ·
說到過去編程經驗的不同,第二個主要的學習經驗是在長叠代時間下工作所需的思維方式的差異。
調試似乎涉及四個基本步驟:
- 搜集關於問題可能性的相關證據
- 形成關於這個問題的假設(根據你迄今為止搜集到的證據)
- 選擇最有可能的假設,實現修復,看看會發生什麽
- 重復以上步驟,直到問題消失
在我以前做過的大多數編程中,我已經習慣了快速反饋。如果有些東西不起作用,你可以做一個改變,看看它在幾秒鐘或幾分鐘內會產生什麽不同。收集這些證據很容易。
事實上,在快速反饋的情況下,收集證據比形成假設要容易得多。當你能在短時間內驗證第一個想法時,為什麽要花15分鐘仔細考慮所有的事情,即使它們可能是導致現象的原因?換句話說:如果你能獲得快速反饋的話,不用經過認真思考,只要不停嘗試就行了。
如果你采用的是嘗試策略,每次嘗試都需要花10小時,是種非常浪費時間的做法。如果最後一次都沒有成功呢?好吧,我承認事情有時候就是這樣。那我們就再檢查一次。第二天早上回來:還是沒用?好吧,也許是另一種,那我們就再跑一次吧。一個星期過後,你還沒有解決這個問題。
同時進行多次運行,每次嘗試不同的事情,在某種程度上都會有所幫助。但是 a) 除非你能夠用集群,否則你最終可能會在雲計算上付出大量的代價(見下文); b) 由於上面提到的強化學習的困難,如果你試圖叠代得太快,你可能永遠不會意識到你到底需要什麽樣的證據。
從大量的實驗和少量的思考,轉變為少量的嘗試和大量的思考,是生產力的一個關鍵轉變。在較長的叠代時間進行調試時,你確實需要投入大量的時間到建立假設--形成步驟--思考所有的可能性是什麽,它們自己看起來有多大的可能性,以及根據到目前為止所看到的一切,它們看起來有多大的可能性。盡可能多地花你時間在上面,即使需要30分鐘或一個小時。一旦你把假設空間盡可能完善了充實了,知道哪些證據可以讓你能夠最好地區分不同的可能性才可以著手實驗。
(如果你把該項目作為業余項目,那麽仔細考慮這個問題就顯得尤為重要了。 如果你每天只在這個項目上工作一個小時,每次叠代都需要一天的時間,那麽每周運行的次數更像你必須充分利用的稀有商品。每天擠出工作時間來思考怎麽樣改善運行結果,會讓人感覺壓力非常大。所以轉變思路,花幾天的時間思考,而不是開始任何運行,直到我對“問題是什麽”的假設非常有信心為止。)
要想更多地思考,堅持做更詳細的工作日誌是非常重要的一環。當進展時間不到幾個小時的時候,沒有工作日誌也無關緊要, 但是如果再長一點的話,你就很容易忘記你已經嘗試過的東西,結果只能是在原地打轉。 我總結的日誌格式是:
Log 1: 我現在在做的有什麽具體的輸出?
Log 2: 大膽思考,例如關於當前問題的假設,下一步該做什麽?
Log 3: 對當前的運行做個記錄,並簡短地提醒你每次運行應該回答哪些問題。
Log 4: 運行的結果 (TensorBoard 圖, 任何其他重要的觀察結果), 按運行類型分類 (例如:根據智能體訓練時的環境)
一開始,我的日誌相對較少,但在項目結束時,我的態度更傾向於“記錄我所想的一切”。 雖然付出的時間成本很高,但我認為是值得的,部分原因是有些調試需要相互參照的結果和想法,往往要間隔數天或數周,部分是因為(至少這是我的印象)從大規模升級轉變為有效的思維的整體改進。

典型的日誌
· · ·
為了將實驗成果效益最大化,在實驗過程中我做了兩件事情,這些事也許會在未來發揮作用。
首先,記錄所有指標,這樣你能最大限度提升每次運行時收集的證據數量。其中有一些明顯的指標,比如訓練/驗證準確性。當然,用大量時間來頭腦風暴,研究其他指標對於診斷潛在的問題也很重要。
我之所以提出這個建議,部分是因為後視偏差,因為我知道應該更早地開始記錄哪些指標。很難預測哪些指標在高級階段會有用。不過,可能有用的策略方法是:
對於系統中的每一個重要組件,考慮一下可以測量什麽。如果有一個數據庫,測量它在大小上增長的速度。如果有隊列,測量處理項目的速度。
對於每一個復雜的過程,測量它的不同部分花了多長時間。如果你有一個訓練循環,測量每一批運行所需的時間。如果你有一個復雜的推理過程,測量每個子推理所花費的時間。這些時間對以後的性能調試會有很大幫助,有時還會發現一些其他很難發現的錯誤。 (例如,如果你看到某些結果的時間越來越長,可能是因為內存泄漏。)
同樣,請考慮分析不同組件的內存使用情況。小內存泄漏可以指向各種事情。
另一種策略是觀察其他人在衡量什麽。在深入強化學習的背景下,John Schulman在他的研究Nuts and Bolts of Deep RL talk(https://www.youtube.com/watch?v=8EcdaCk9KaQ) 中有一些很好的建議。對於策略梯度方法,我發現策略熵是一個很好的指標,它可以很好地反映訓練是否再進行,比每一次訓練的獎勵都要敏感得多。
不健康和健康的策略熵圖。失敗模式1(左):收斂到常量熵(隨機選擇一個行為子集);失敗模式2(中間):收斂到零熵(每次選擇相同的動作)。右:成功的乒乓球訓練運行的策略熵
當你在記錄的度量中看到一些可疑的東西時,記住要註意困惑,寧願錯誤地假設它是重要的東西,而不僅僅把它當做一些數據結構的低效實現。(我忽略了每秒的幀中一個微小但莫名的衰變,從而導致幾個月的多線程錯誤。)
如果能在一個地方看到所有的度量標準,調試就容易得多。我喜歡盡可能多得使用Tensorboard。使用Tensorflow記錄度量標準比較困難,所以考慮使用查看easy-tf-log(https://github.com/mrahtz/easy-tf-log),它提供了一個簡單的沒有任何額外的設置界面的接口 tflog(key, value) 。
第二件看起來很有意義的是花時間嘗試和提前預測失敗。
多虧了後視偏差在回顧實驗時失敗原因往往是顯而易見的。但真正令人沮喪的是,在你觀察到它是什麽之前,失敗模式已經顯而易見了。當你開始訓練一個模型,等你第二天回來一看它失敗了,甚至在你研究失敗原因之前,你就意識到“哦,那一定是因為我忘了設置frobulator”?
簡單的是有時你可以提前觸發這種半事後認知(half-hindsight-realisation)。它需要有意識的努力,在開始運行之前先停下來思考五分鐘哪裏可能出錯。我認為最有用的腳本是: 2
1、問問自己,“如果運行失敗了自己會有多驚訝?”
2、如果答案是“不是很驚訝”,那麽設想自己處於未來場景中——這次運行已經失敗了,然後問問自己,“如果失敗了,哪些地方錯了?”
3、修正想到的任何地方
4、重復上述步驟知道問題1的答案是“非常驚訝”(或者至少“要多驚訝有多驚訝”)
總是會有一些你無法預測的錯誤,並且有時你仍然會忽略一些明顯可以避免的錯誤,但是這個方法至少看起來能夠減少一些你會因為沒有事先想到而犯的非常愚蠢的錯誤。
· · ·
最後,該項目最令人驚訝的是花費的時間,以及所需的計算資源。
我最初估計作為一個業余項目,它會耗費3個月的時間。但是實際上它耗費了大約8個月時間。(最初的估計其實已經很悲觀了!)部分原因是低估了每個階段可能花費的時間,但是最大的低估是沒有預測到該項目之外出現的其他事情。很難說這個推論有多麽嚴謹,但是對於業余項目來說,將你初始的預估時間(已經悲觀估計的)加倍或許是個不錯的經驗方法。
更令人感到意外的是:每個階段實際花費的時間。我初始的項目計劃中主要階段的時間表基本如下:
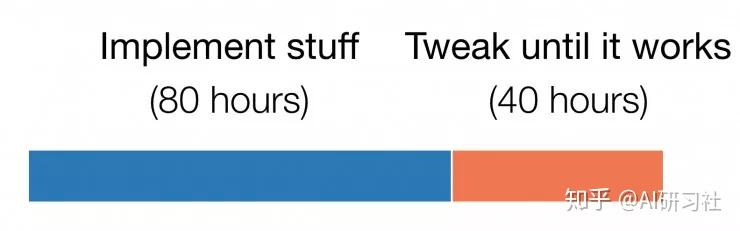
這是每個階段實際花費的時間
不是寫代碼花費了很長時間,而是調試代碼。實際上,在一個所謂的簡單環境上運行起來花費了4倍最初預想的實現時間。(這是第一個我連續花費數小時時間的業余項目,但是所獲得的經驗與過去機器學習項目類似。)
(備註:從一開始就仔細設計,你想象中強化學習的“簡單”環境。尤其是,要仔細考慮:a)你的獎勵是否能夠真正傳達解決任務的正確信息;b)獎勵是否只僅依賴之前的觀測結果還是也依賴當前的動作。實際上,如果你在進行任意的獎勵預測時,後者可能也是相關的,例如,使用一個critic)
另一個是所需的計算資源總量。我很幸運可以使用學校的集群,雖然機器只有 CPU ,但對一些工作來說已經很好了。對於需要 GPU 的工作(如在一些小部分上進行快速叠代)或集群太繁忙的時候,我用兩個雲服務進行實驗:谷歌雲計算引擎的虛擬機(https://console.cloud.google.com/projectselector/compute/instances?supportedpurview=project&pli=1)、FloydHub(https://www.floydhub.com/)。
如果你只想通過shell訪問GPU機器,谷歌雲計算引擎還是不錯的,不過我更多是在FloydHub上進行嘗試的。FloydHub基本上是一個專門面向機器學習的雲計算服務。運行floyd run python awesomecode.py 命令,FloydHub會初始化一個容器,將你的代碼上傳上去,並且運行你的代碼。FloydHub如此強大有兩個關鍵因素:
- 容器預裝了GPU驅動和常用庫。(甚至在2018年,我仍然在谷歌雲計算引擎虛擬機上花費了好幾個小時處理更新TensorFlow時CUDA的版本問題。)
- 每次運行都是自動存檔的。對於每次運行,使用的代碼、用來運行代碼的命令、命令行任意輸出以及任何輸出的數據都會自動保存,並且通過一個網頁接口建立索引。
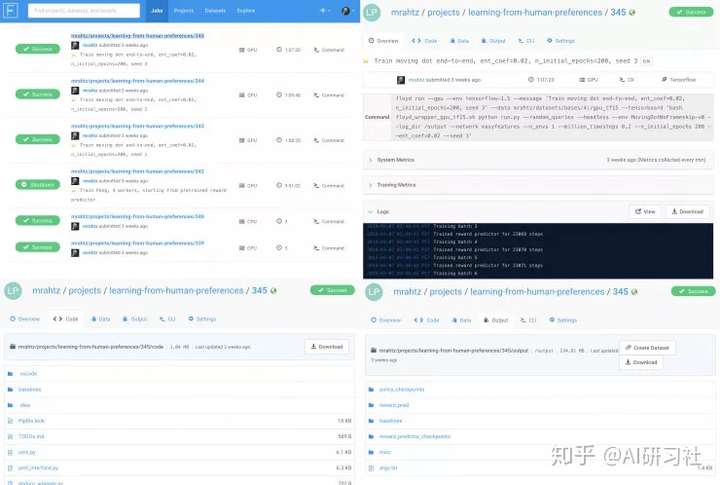
如圖為FloydHub的網頁接口。上面:歷史運行的索引,和單次運行的概觀。下面:每次運行所使用的代碼和運行輸出的任意數據都被自動存檔。
第二點的重要程度我難以言表。對於任何項目,這種長期且詳細記錄操作和復現之前實驗的能力都是絕對有必要的。雖然版本控制軟件也能有所幫助,但是a)管理大量輸出非常困難;b)需要非常勤奮。(例如,如果你開始運行了一些,然後做了一點修改後又運行了另一個,當你提交首次運行的結果時,能否清楚使用了哪份代碼?)你可以仔細記筆記或者檢查你自己的系統,但是在FloydHub上,它都自動完成壓根不需要你花費這麽多精力。
我喜歡FloydHub的其他一些方面還有:
- 一旦運行結束,容器會自動關閉。不用擔心地查看運行是否完成、虛擬機是否關閉。
- 付費比谷歌雲更加直接。比如說你支付了10小時的費用,你的虛擬機立馬就被充值了10個小時。這樣使得每周的預算更加容易。
我用FloydHub遇到的一個麻煩是它不能自定義容器。如果你的代碼有非常多的依賴包,你在每次運行前都需要安裝這些依賴包。這就限制了短期運行上的叠代速率。但是,你可以通過創建一個包含安裝這些依賴包之後文件系統變更的“dataset”,然後再每次開始運行時都從“dataset”中拷貝出來這些文件解決這個問題(例如 create_floyd_base.sh)。雖然這很尷尬,但仍然比解決GPU驅動問題要好一些。
FloydHub比谷歌雲稍微貴一點:FloydHub上一個K80 GPU機器1.2美元/小時,而谷歌雲上類似配置的機器只需要0.85美元/小時(如果你不需要高達61G 內存的機器的話費用更低)。除非你的預算真的有限,我認為FloydHub帶來的額外便利是值這個價的。只有在並行運行大量計算的情況下,谷歌雲才算是更加劃算,因為你可以在單個大型虛擬機上運行多個。
(第三個選擇是谷歌的新Colaboratory服務,這就相當於提供給你了一個能夠在K80 GPU 機器上免費訪問的Jupyter筆記本。但不會因為Jupyter而延遲:你可以執行任意命令,並且如果你真的想的話可以設置shell訪問。這個最大的弊端是如果你關閉了瀏覽器窗口,你的代碼不會保持運行,而且還有在托管該筆記本的容器重置之前能夠運行時間的限制。所以這一點不適宜長期運行,但對運行在GPU上快速原型是有幫助的。)
這個項目總共花費了:
- 谷歌計算引擎上150個小時GPU運行時間,和7700小時(實際時間x核數)的CPU運行時間,
- FloydHub上292小時的GPU運行時間,
- 和我大學集群上 1500 小時的CPU運行時間(實際時間,4到16核)。
我驚訝地發現在實現這個項目的8個月時間裏,總共花費了大約850美元(FloydHub上花了200美元,谷歌雲計算引擎上花了650美元)。
其中一些原因是我笨手笨腳(見上文慢叠代思想章節)。一些原因是強化學習仍然是如此低效,運行起來需要花費很長時間(每次都需要花費多達10小時的時間來訓練一個Pong代理)。
但其中很大一部分原因是我在這個項目最後階段遇到意外:強化學習可能不太穩定,我們需要使用不同的隨機種子重復運行多次以確定性能。
舉例來說,一旦我認為基本完成了所有事情,我就會在這個環境上進行端到端測試。但是即使我一直使用最簡單的環境,當訓練一個點移動到正方形中央上,仍然遇到了非常大的問題。因此我重新回到 FloydHub 進行調整並運行了三個副本,事實證明我認為優秀的超參數在三次測試中只成功了一次。
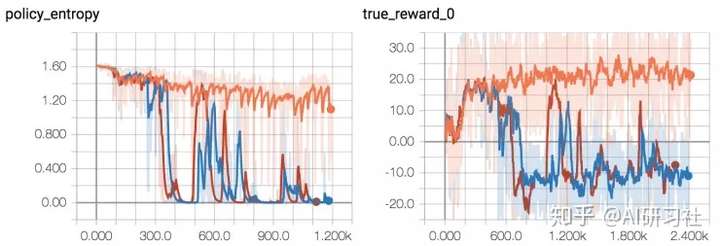
2/3 的隨機種子出現失敗(紅/藍)並不罕見
對需要的計算量,我給你一個直觀的數字:
- 使用 A3C和16名人員,Pong 需要花費 10 小時訓練;
- 花費160小時CPU時間;
- 運行3個隨機數種子, 需要CPU花費480小時(20天)。
成本方面:
- FloydHub 每小時收費 $0.50 美金,使用8核的設備;
- 所以每運行10小時收費5美金;
- 同時運行3個不同的隨機數種子,每運行一次需要花費15美元。
就相當於每驗證一次你的想法就需要花費3個三明治的錢。
再次,從 《Deep Reinforcement Learning Doesn’t Work Yet》這篇文章中可以看到,這種不穩定貌似正常也可接受。事實上,即使“ 五個隨機種子 (一種通用標準) 可能不足以說明結果有意義, 通過仔細選擇,你會得到不重疊的置信區間。”
(突然之間,OpenAI學者計劃提供的25,000美元的AWS學分看起來並不那麽瘋狂,這可能與你給予某人的數量有關,因此計算完全不用擔心。)
我的意思是,如果你想要解決一個深入的強化學習項目,請確保你知道你在做什麽。確保你準備好需要花費多少時間,花多少錢。
· · ·
總的來說,復現一篇強化學習方面的論文作為業余項目還是很有趣的。反過來看,也可以想想從中學到了什麽技能,我也想知道花費幾個月時間復現一篇論文是否值得。
另一方面, 我感覺到我在機器學習方面的研究能力並沒有很大提升 (回想起來,這實際上是我的目標),反而應用能力得到了提升,研究中相當多的困難似乎會產生出很多有趣和具體的想法;這些想法會讓你覺得為此花費的時間是值得的。 產生一個有趣的想法似乎是一個問題 a) 需要大量可供利用的概念, b) 對好的想法或創意擁有敏銳的嗅覺 (例如,什麽樣的工作會對社區有用)。為了達成以上目的,我認為一個好的做法是閱讀有影響力論文,總結並批判性分析這些論文。
所以我認為我從這個項目中得到的主要結論是,無論你是想提高工程技能還是研究技能都值得仔細思考。並不是說沒有兩者兼得的情況; 但是如果某方面是你的弱項的話,你可以找一個專門針對此項的項目做,來提高你的水平。
如果這兩項技能你都想提升,比較好的方法或許是閱讀大量論文,尋找你感興趣且有清晰代碼的論文,並嘗試實現或擴展它。
· · ·
如果你想做深度強化學習的項目,這裏有一些細節需要註意。
找些研究論文來復現
找一些知識點相對單一的論文,避免需要多個知識點協同工作的論文;
強化學習
- 如果你做的項目是將強化學習算法作為大型系統的一部分,不要嘗試自己編寫強化學習算法,盡管這是一個有趣的挑戰,你也可以學到很多東西,但是強化學習目前還不足夠穩定,你有可能會無法確定你的系統不工作是因為你的強化學習算法有bug,還是因為你的這個系統有Bug。
- 做任何事之前, 檢查如何在你的環境中使用基線算法簡化智能體訓練。
- 不要忘記標準化觀察,這些觀察有可能使用在所有地方。
- 一旦你覺得你做出了什麽,就盡快寫一個端到端的測試。成功的訓練可能比你期望的要更脆弱。
- 如果你使用 OpenAI Gym 環境,註意使用 -v0 環境, 有25%的可能,當前的操作被忽略,反而重復之前的操作 (降低環境的確定性)。如果你不希望出現那麽多隨機性的話,請使用 -v4 環境 。另外註意默認的環境每次只提供給你從仿真器得到的4幀,與早期的DeepMInd論文一致。如果你不想這樣的話,請使用 NoFrameSkip 環境。因為這是一個完全穩定的環境,它實際呈現出的和仿真器上給你的完全一致,例如可以使用 PongNoFrameskip-v4。
通用機器學習
- 端到端測試需要運行很長時間,如果後面要進行大規模的重構,你將浪費大量時間。 第一次運行時就做好總比先計算出來然後保存重構留著後面再說要好。
- 初始化一個模塊需要花費20秒。比如因為語法錯誤而浪費時間,確實讓人頭疼。如果你不喜歡IDE開發環境,或者因為你只能在shell的命令行窗口進行編輯,就值得花時間為你的編輯器創建一個Linter。(對 Vim來說, 我喜歡帶Pylint 和 Flake8的ALE. Flake8更像一個格式檢查器, 它可以發現Pylint不能發現的問題,比如傳遞錯誤參數給某個函數。)不管怎樣,花點時間在linter工具上,可以在運行前發現一個愚蠢的錯誤。
- 不僅僅dropout你要小心,在實現權分享網絡中時,你也需要格外小心 - 這也是批規範化。 別忘了網絡中有很多規範化統計數據和額外的變量需要匹配。
- 經常看到運行過程中內存的峰值? 這可能是你的驗證批量規模太大了。
- 如果你在使用Adam作為優化器使用時看到了奇怪的事情發生,這可能是由於 Adam 的動量參數引起。 嘗試使用沒有動量參數的優化器,比如RMSprop,或者通過設置 β1 =0 屏蔽動量參數。
TensorFlow
- 如果你想調試看計算圖中間的一些節點發生了什麽,使用 tf.Print,可以將每次運行的輸入值打印出來。
- 如果你正在保存推斷的檢查點,你可以通過忽略優化器參數來節省大量空間。
- session.run() 很燒錢。盡量批量調用。
- 如果您在同一臺機器上運行多個TensorFlow實例時,會出現GPU內存不足的錯誤, 這很可能是因為其中一個實例試圖占用所有內存空間導致的,並不是因為你的模型太大。這是TensorFlow的默認做法,你需要告訴TensorFlow只按需使用內存空間,可以參考 allow_growth 操作。
- 如果你想在正在運行的的很多東西的時候,及時訪問一個圖表,就像你從多個進程訪問同一個圖表一樣,但是有一種鎖只允許同一時間只能有一個進程進行進行相關操作。這似乎與Python的全局解釋鎖明顯不同,TensorFlow會在執行繁重工作前釋放鎖。對此我不敢確定,也沒有時間做徹底調試。但如果你也遇到相同狀況,可以使用多進程,並用分布式TensorFlow將圖表分復制每個進程,將會比較簡便。
- 使用Python不用擔心溢出,但應用TensorFlow時,你就需要格外小心了:

當不能使用GPU時,請註意使用 allow_soft_placement 切換到CPU。如果你偶爾寫的代碼無法在GPU上運行時,它可以平滑切換到CPU。例如:

我不清楚有多少像這樣無法在GPU上運行的操作,但安全起見,手動切換到CPU,例如:

健康的心理
- 不要對TensorBoard上癮。 我是認真的。這是一個關於不可預知的獎勵上癮的完美例子:你檢查自己的操作是如何運行的時候,而且它在不停的運行,有時檢查時你會突然中大獎!這是件超級興奮的事。 如果你每過一段時間就有檢查 TensorBoard 的沖動,這時對你來說,應該設置一個規則,規定合理的檢查時間間隔。
· · ·
如果你毫不猶豫地讀了這篇文章,那就太棒了!
如果你也想進入深度強化學習領域,這裏有一些資源供你入門時參考:
- Andrej Karpathy的 Deep Reinforcement Learning: Pong from Pixels 是一份關於建立動機和直覺方面很好的介紹文章。
- 想了解更多關於強化學習方面的理論,可以參考 David Silver的演講 。這篇演講沒有過多關於深度強化學習的內容( 基於神經網絡的強化學習 ),但至少教會了你很多詞匯,幫助你理解相關論文。
- John Schulman的 Nuts and Bolts of Deep RL talk 有很多實際應用方面的建議,這些問題你在後面都可能遇到。
想了解目前深度強化學習領域發生了什麽,可以參考一下這些內容:
- Alex Irpan的 Deep Reinforcement Learning Doesn’t Work Yet 對目前的狀況有一個很好的概述。
- Vlad Mnih的 Recent Advances and Frontiers in Deep RL ,有很多關於實際例子,用以解決 Alex 文章中提到的問題。
- Sergey Levine的 Deep Robotic Learning 談話,聚焦改善機器人的泛化和樣本效率問題。
- Pieter Abbeel 在2017 NIPS會議上 Deep Learning for Robotics 主題演講, 提到很多最新的深度強化學習技術。
復現一篇深度強化學習論文之前請先看了這篇文章!