
手把手教你做中介軟體開發(分散式快取篇)-藉助redis已有的網路相關.c和.h檔案,半小時快速實現一個epoll非同步網路框架,程式demo
本文件配合主要對如下demo進行配合說明: 藉助redis已有的網路相關.c和.h檔案,半小時快速實現一個epoll非同步網路框架,程式demo
0. 手把手教你做中介軟體、高效能伺服器、分散式儲存技術交流群
手把手教你做中介軟體、高效能伺服器、分散式儲存等(redis、memcache、nginx、大容量redis pika、rocksdb、mongodb、wiredtiger儲存引擎、高效能代理中介軟體),git地址如下:
git地址:https://github.com/y123456yz/middleware_development_learning
1. epoll出現背景
epoll 是 linux 核心為處理大批量檔案描述符(網路檔案描述符主要是socket返回的套接字fd和accept處理的新連線fd)而作了改進的 poll,是 linux 下多路複用 io介面 select/poll 的增強版本。在 linux 的網路程式設計中,很長時間都在使用 select 來做事件觸發。在 2.6 核心中,有一種替換它的機制,就是 epoll。epoll替換select和poll的主要原因如下:
- select最多處理1024(核心程式碼fd_setsize巨集定義)個連線。
- select和poll採用輪訓方式檢測核心網路事件,演算法事件複雜度為o(n),n為連線數,效率低下。
epoll克服了select和poll的缺點,採用回撥方式來檢測就緒事件,演算法時間複雜度o(1),相比於select和poll,效率得到了很大的提升。
藉助epoll的事件回撥通知機制,工作執行緒可以在沒有網路事件通知的時候做其他工作,這樣可以最大限度的利用系統cpu資源,服務端不用再阻塞等待客戶端網路事件,而是依賴epoll事件通知機制來避免同步等待。
2. epoll系統呼叫介面
2.1 epoll_create函式
函式宣告:int epoll_create(int size)
該函式生成一個epoll專用的檔案描述符,其中的引數是指定生成描述符的最大範圍。在linux-2.4.32核心中根據size大小初始化雜湊表的大小,在linux2.6.10核心中該引數無用,使用紅黑樹管理所有的檔案描述符,而不是hash。
重點:該函式返回的fd將作為其他epoll系統介面的引數。
2.2 epoll_ctl函式
函式宣告:int epoll_ctl(int epfd, int op, int fd, struct epoll_event event)
該函式用於控制某個檔案描述符上的事件,可以註冊事件,修改事件,刪除事件。epoll_wait個引數說明如下:
epfd: epoll事件集檔案描述符,也就是epoll_create返回值
op: 對fd描述符進行的操作型別,可以是添加註冊事件、修改事件、刪除事件,分別對應巨集定義: EPOLL_CTL_ADD、EPOLL_CTL_MOD、EPOLL_CTL_DEL。
fd: 操作的檔案描述符。
event: 需要操作的fd對應的epoll_event事件物件,物件資料來源為fd和op。
2.3 epoll_wait函式
函式宣告:int epoll_wait(int epfd, struct epoll_event events, int maxevents, int timeout),該函式用於輪詢i/o事件的發生,改函式引數說明如下:
epfd: epoll事件集檔案描述符,也就是epoll_create返回值。
Events:該epoll時間集上的所有epoll_event資訊,每個fd對應的epoll_event都存入到該陣列中,陣列每個成員對應一個fd描述符。
Maxevents: 也就是events陣列長度。
Timeout: 超時時間,如果在這個超時時間內核心沒有I/O網路事件通知,則會超時返回,如果在超時時間內有時間通知,則立馬返回
3. epoll I/O對路複用主要程式碼實現流程
程式碼實現主要由以下幾個階段組成:
- 建立套接字獲取sd,bind然後listen該套接字sd。
- 把步驟1中的sd新增到epoll事件集中,epoll只關注sd套接字上的新連線請求,新連線對應的事件為讀事件AE_READABLE (EPOLLIN)。並設定新連線事件到來時對應的回撥函式為MainAcceptTcpHandler。
- 在新連接回調函式MainAcceptTcpHandler中,獲取新連線,並返回該新連線對應的檔案描述符fd,同時把新連線的fd新增到epoll事件集中,該fd開始關注epoll讀事件,如果檢測到該fd對應的讀事件(客戶端傳送的資料服務端收到後,核心會觸發該fd對應的epoll讀事件),則觸發讀資料回撥函式MainReadFromClient。多個連線,每個連線有各自的檔案描述符事件結構(該結構記錄了各自的私有資料、讀寫回調函式等),並且每個連線fd有各自的已就緒事件結構。不同連線有不同的結構資訊,最終藉助epoll實現I/O多路複用。
- 進入aeMain事件迴圈函式中,迴圈檢測步驟2中的新連線事件和步驟3中的資料讀事件。如果有對應的epoll事件,則觸發epoll_wait返回,並執行對應事件的回撥。
4. epoll I/O多路複用主要資料結構及函式說明
4.1 主要資料結構
struct aeEventLoop結構用於記錄整個epoll事件的各種資訊,主要成員如下:
typedef struct aeEventLoop {
// 目前已註冊的最大描述符
int maxfd; /* highest file descriptor currently registered */
// 目前已追蹤的最大描述符
int setsize; /* max number of file descriptors tracked */
// 用於生成時間事件 id
long long timeEventNextId;
// 最後一次執行時間事件的時間
time_t lastTime; /* Used to detect system clock skew */
// 已註冊的檔案事件,每個fd對應一個該結構,events實際上是一個數組
aeFileEvent *events; /* Registered events */
// 已就緒的檔案事件,參考aeApiPoll,陣列結構
aeFiredEvent *fired; /* Fired events */
// 時間事件,所有的定時器時間都新增到該連結串列中
aeTimeEvent *timeEventHead;
}
該結構主要由檔案描述符事件(即網路I/O事件,包括socket/bind/listen對應的sd檔案描述符和accept獲取到的新連線檔案描述符)和定時器事件組成,其中檔案事件主要由events、fired、maxfd、setsize,其中events和fired為陣列型別,陣列大小為setsize。
events陣列: 成員型別為aeFileEvent,每個成員代表一個註冊的檔案事件,檔案描述符與陣列遊標對應,例如如果fd=10,則該fd對應的檔案事件為event陣列的第十個成員Events[10]。
fired陣列: 成員型別為aeFiredEvent,每個成員代表一個就緒的檔案事件,檔案描述符和陣列遊標對應,例如如果fd=10,則該fd對應的已就緒的檔案事件為fired陣列的第十個成員fired [10]。
Setsize: 為events檔案事件陣列和fired就緒事件陣列的長度,初始值為REDIS_MAX_CLIENTS + REDIS_EVENTLOOP_FDSET_INCR。aeCreateEventLoop中提前分配好events和fired陣列空間。
maxfd: 為所有檔案描述符中最大的檔案描述符,該描述符的作用是調整setsize大小來擴大events和fired陣列長度,從而保證儲存所有的事件,不會出現陣列越界。
何時擴大events和fireds陣列長度?
例如redis最開始設定的預設最大連線數為REDIS_MAX_CLIENTS,如果程式執行一段時間後,我們想調大最大連線數,這時候就需要調整陣列長度。
為什麼events和fireds陣列長度需要加REDIS_EVENTLOOP_FDSET_INCR?
因為redis程式中除了網路相關accept新連線的描述符外,程式中也會有普通檔案描述符,例如套接字socket描述符、日誌檔案、rdb檔案、aof檔案、syslog等檔案描述符,確保events和fireds陣列長度大於配置的最大連線數,從而避免陣列越界。
4.2 主要函式實現
主要函式功能請參考以下幾個函式:
aeCreateFileEvent
aeDeleteFileEvent
aeProcessEvents
aeApiAddEvent
aeApiDelEvent
aeApiPoll
5. 定時器實現原理
5.1 定時器主要程式碼流程
Redis的定時器實際上是藉助epoll_wait實現的,epoll_wait的超時時間引數timeout是定時器連結串列中距離當前時間最少的時間差,例如現在是8點1分,我們有一個定時器需要8點1分5秒執行,那麼這裡epoll_wait的timeout引數就會設定為5s。
epoll_wait函式預設等待網路I/O事件,如果8點1分到8點1分5秒這段時間內沒有網路I/O事件到來,那麼到了8點1分5秒的時候,epoll_wait就會超時返回。Epoll_wait返回後就會在aeMain迴圈體中遍歷定時器連結串列,獲取到定時器到達時間比當前時間少的定時器,執行該定時器的對應回撥函式。
如果在8點1分3秒過程中有網路事件到達,epoll_wait會在3秒鐘返回,返回後處理完對應的網路事件回撥函式,然後繼續aeMain迴圈體中遍歷定時器連結串列,獲取離當前時間最近的定時器時間為5-3=2秒,也就是還有2秒該定時器才會到期,於是在下一個epoll_wait中,設定timeout超時時間為2秒,以此迴圈。
5.2 兩種不同的定時器(週期性定時器、一次性定時器)
週期性定時器: 指的是定時器到期對應的回撥函式執行後,需要重新設定該定時器的超時時間,以備下一個週期繼續執行。
一次性定時器: 本次定時時間到執行完對應的回撥函式後,把該定時器從定時器連結串列刪除。
兩種定時器程式碼主要程式碼流程區別如下:

5.3 主要資料結構及函式實現
主要資料結構如下:
typedef struct aeEventLoop {
// 時間事件,所有的定時器時間都新增到該連結串列中
aeTimeEvent *timeEventHead;
}

主要函式實現參考:
aeCreateTimeEvent
aeDeleteTimeEvent
aeSearchNearestTimer
processTimeEvents
6. 常用套接字選項設定
套接字選項可以通過setsockopt函式進行設定,函式宣告如下:
int setsockopt( int socket, int level, int option_name, const void *option_value, size_t option_len);
setsockopt引數說明如下:
socket: 可以是bind/listen對應的sd,也可以是accept獲取到的新連線fd。
level: 引數level是被設定的選項的級別,套接字級別對應 SOL_SOCKET,tcp網路設定級別對應SOL_SOCKET.
option_name: 選項型別。
optlen:optval緩衝區長度。
6.1 SOL_SOCKET級別套接字選項
Level級別為SOL_SOCKET的option_name常用型別如下(說明:網路I/O的檔案描述符控制代碼有兩類,一類是針對socket()/bind/listen對應的sd,一類是新連線到來後accept返回的新的連線控制代碼fd):
SO_REUSEADDR: 複用地址,針對socket()/bind/listen對應的sd,避免服務端程序退出再重啟後出現error:98,Address already in use。
SO_RECVBUF: 設定連線fd對應的核心網路協議棧接收緩衝區buf大小,每個連線都會有一個recv buf來接收客戶端傳送的資料。實際應用中,使用預設值就可以,但如果連線過多,負載過大,記憶體可能吃不消,這時候可以調小該值。
SO_SNDBUF:設定連線fd對應的核心網路協議棧傳送緩衝區buf大小,每個連線都會有一個send buf來快取需要傳送的連線資料。實際應用中,使用預設值就可以,但如果連線過多,負載過大,記憶體可能吃不消,這時候可以調小該值。
SO_KEEPALIVE:針對socket()/bind/listen對應的sd,設定TCP的keepalive機制,由核心網路協議棧實現連線保活。通過該設定可以判斷對端異常斷電、網路不通的連線問題(如網線鬆動)。因為客戶端異常斷電或者網線鬆動,服務端是不會有epoll異常事件通知的。如果沒有設計應用層保活超時報文,則可以依賴協議棧keepalive來檢測連線是否異常。
SO_LINGER:決定關閉連線fd的方式,因為關閉連線的時候,該fd對應的核心協議棧buf可能資料還沒有傳送出去,如果強制立即關閉可能會出現丟資料的情況。可以根據傳入optval引數決定立即關閉連線(可能丟資料),還是等待資料傳送完畢後關閉釋放連線或者超時關閉連線。
SO_RCVTIMEO:針對sd和新連線fd,接收資料超時時間,這個針對阻塞讀方式。如果read超過這麼多時間還沒有獲取到核心協議棧資料,則超時返回。
SO_SNDTIMEO:針對sd和新連線fd,傳送資料超時時間,這個針對阻塞寫方式。如果write超過這麼多時間還沒有把資料成功寫入到核心協議棧,則超時返回。
6.2 IPPROTO_TCP級別套接字選項
Level級別為IPPROTO_TCP的option_name常用型別如下:
TCP_NODELAY:針對連線fd,是否啟用naggle演算法,一般禁用,這樣可以保證服務端快速回包,降低時延。
7. 阻塞、非阻塞
服務端和網路I/O相關相關的幾個系統函式主要是:accept()接收客戶端連線、read()從核心網路協議棧讀取客戶端傳送來的資料、write()寫資料到核心協議棧buf,然後由核心排程傳送出去。請參考阻塞demo和非阻塞demo。
7.1阻塞及其demo程式驗證說明
網上相關說明很多,但是都比較抽象。這裡以服務端呼叫accept為例說明:accept()函式會進行系統呼叫,從應用層走到核心空間,最終呼叫核心函式SYSCALL_DEFINE3(),如果accept對應的sd(socket/bind/listen對應的檔案描述符)是阻塞呼叫(如果不進行設定,預設就是阻塞呼叫),SYSCALL_DEFINE3()對應的函式會判斷核心是否收到客戶端新連線,如果沒有則一直等待,直到有新連線到來或者超時才會返回。
從上面的描述可以看出,如果是阻塞方式,accept()所在的現場會一直等待,整個執行緒不能做其他事情,這就是阻塞。Accept()阻塞超時時間可以通過上面的SO_RCVTIMEO設定。
Read()和write()阻塞操作過程和acept()類似,只有在接收到資料和寫資料到協議棧成功才會返回,或者超時返回,超時時間分別可以通過SO_RCVTIMEO和SO_SNDTIMEO設定。
下面以如下demo為例,來體驗阻塞和非阻塞,以下是阻塞操作例子,分別對應服務端和客戶端程式碼:
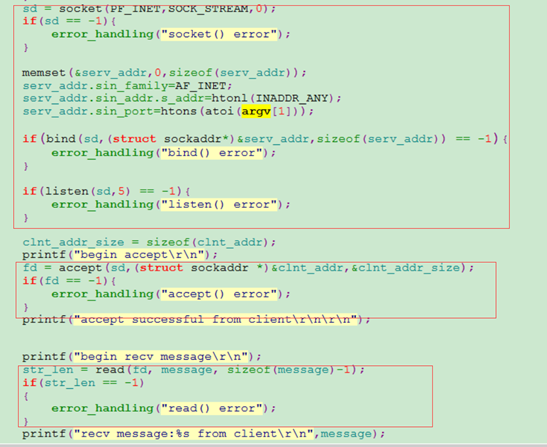
從上面的程式,服務端建立套接字後,繫結地址後開始監聽,然後阻塞accept()等待客戶端連線。如果客戶端有連線,則開始阻塞等待read()讀客戶端傳送來的資料,讀到資料後列印返回,程式執行結束。
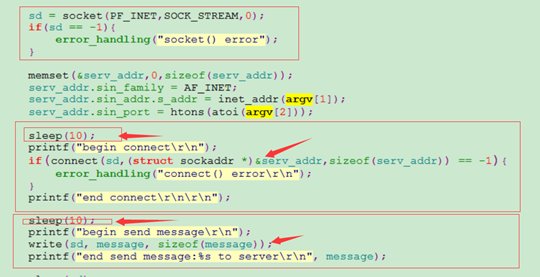
客戶端程式建立好套接字,設定好需要連線的伺服器Ip和埠,先延時10秒鐘才開始連線伺服器,連線成功後再次延時10秒,然後傳送”block test message”字串給服務端。
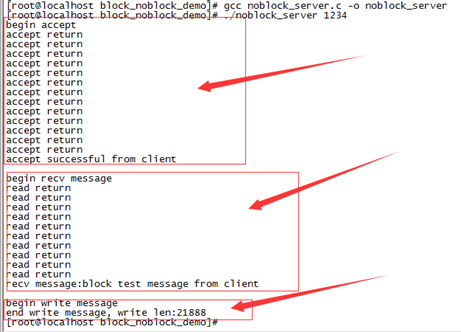
通過CRT開兩個視窗,同時啟動服務端和客戶端程式,服務端列印資訊如下:
[root@localhost block_noblock_demo]# gcc block_server.c -o block_server
[root@localhost block_noblock_demo]#
[root@localhost block_noblock_demo]# ./block_server 1234
begin accept //在這裡阻塞等待客戶端連線
accept successful from client
begin recv message //這裡阻塞等待客戶端傳送資料過來
recv message:block test message from client
[root@localhost block_noblock_demo]#
客戶端列印資訊如下:
[root@localhost block_noblock_demo]# gcc block_client.c -o block_client
[root@localhost block_noblock_demo]# ./block_client 127.0.0.1 1234
begin connect //begin和end見有10s延時
end connect
begin send message //begin和end間有10s延時
end send message:block test message to server
從執行服務端程式和客戶端程式的列印可以看出,如果客戶端不發起連線,服務端accept()函式會阻塞等待,知道有新連線到來才會返回。同時啟用服務端和客戶端程式,服務端accept()函式10s才會返回,因為客戶端我故意做了10s延時。Read()阻塞讀函式過程和accept()類似。
Write()阻塞驗證過程,服務端設定好該連結對應的核心網路協議棧傳送快取區大小,然後傳遞很大的一個數據給write函式,期望把這個大資料通過write函式寫入到核心協議棧傳送快取區。如果核心協議棧快取區可用buf空間比需要write的資料大,則資料通過write函式拷貝到核心傳送快取區後會立馬返回。為了驗證write的阻塞過程,我這裡故意讓客戶端不去讀資料,這樣服務端write的資料就會緩衝到協議棧傳送緩衝區,如果緩衝區空間沒那麼大。Write就會一直等待核心排程把傳送緩衝區資料通過網絡卡傳送出去,這樣就會騰出空間,繼續拷貝使用者態write需要寫的資料。由於這裡我故意讓客戶端不讀資料,該連結對應的傳送緩衝區很快就會寫滿,由於我想要寫的資料比這個buf緩衝區大很多,那麼write函式就需要阻塞等待,直到把期望傳送的資料全部寫入到該傳送快取區才會返回,或者超過系統預設的write超時時間才會返回。
7.2 非阻塞及其demo程式驗證說明
非阻塞通過系統呼叫fcntl設定,函式程式碼如下:

函式中的fd檔案描述符可以是socket/bind/listen對應的sd,也可以是accept獲取到的新連線fd。非阻塞程式demo github地址如下:
編譯程式,先啟動服務端程式,然後啟動客戶端程式,驗證方法如下:
對應客戶端:

客戶端啟動後,延遲10秒向服務端發起連線,連線建立成功後,延遲10秒向服務端傳送資料。服務端啟動後,設定sd為非阻塞,開始accept等待接收客戶端連線,如果accept系統呼叫沒有獲取到客戶端連線,則延時1秒鐘,然後繼續accept。由於客戶端啟動後要延遲10s鍾才發起連線,因此accept會有十次accept return列印。read過程和accept類似,可以檢視demo程式碼。
我們知道write操作是把使用者態向要傳送的資料拷貝到核心態連線對應的send buf緩衝區,如果是阻塞方式,如果核心快取區空間不夠,則write會阻塞等待。但是如果我們把新連線的fd設定為非阻塞,及時核心傳送緩衝區空間不夠,write也會立馬返回,並返回本次寫入到核心空間的資料量,不會阻塞等待。可以通過執行demo自己來體驗這個過程。
大家應該注意到,則非阻塞操作服務端demo中,accept(),read()如果沒有返回我們想要的連線或者資料,demo中做了sleep延時,為什麼這裡要做點延時呢?
原因是如果不做延時,這裡會不停的進行accept read系統呼叫,系統呼叫過程是個非常消耗效能的過程,會造成CPU的大量浪費。假設我們不加sleep延時,通過top可以檢視到如下現象:

8. 同步、非同步
同步和非同步是比較抽象的概念,還是用程式demo來說明。
8.1 同步
上面的服務端阻塞操作程式demo github地址和服務端非阻塞操作程式demo github地址實際上都是同步呼叫的過程。這兩個demo都是單執行緒的,以accept()呼叫為例,不管是阻塞操作還是非阻塞操作,由於服務端不知道客戶端合適發起連線,因此只能阻塞等待,或者非阻塞輪訓查詢。不管是阻塞等待還是輪訓查詢,效率都非常低下,整個執行緒不能做其他工作,CPU完全利用不起來。
8.2 非同步
藉助redis已有的網路相關.c和.h檔案,半小時快速實現一個epoll非同步網路框架,程式demo,這個demo是非同步操作。還是以該demo的accept為例說明,從這個demo可以看出,sd設定為非阻塞,藉助epoll機制,當有新的連線事件到來後,觸發epoll_wait返回,並返回所有的檔案描述符對應的讀寫事件,這樣就觸發執行對應的新連接回調函式MainAcceptTcpHandler。藉助epoll事件通知機制,就避免了前面兩個demo的阻塞等待過程和輪訓查詢過程,整個accept()操作由事件觸發,不必輪訓等待。本非同步網路框架demo也是單執行緒,就不存在前面兩個demo只能做accept這一件事,如果沒有accept事件到來,本非同步網路框架demo執行緒還可以處理其他已有連線的讀寫事件,這樣執行緒CPU資源也就充分利用起來了。
打個形象的比喻,假設我們每年單位都有福利體檢,體檢後一到兩週出體檢結果,想要獲取體檢結果有兩種方式。第一種方式: 體檢結束一週後,你就坐在醫院一直等,直到體檢結果出來,整個過程你是無法正常去單位上班的(這就相當於前面的服務端阻塞demo方式)。第二種方式:你每天都跑去體檢醫院詢問,我的體檢結果出了嗎,如果沒有,第二天有去體檢醫院,以此重複,直到有一天你去體檢醫院拿到體檢結果。在你每天去醫院詢問是否已經出體檢結果的過程中,你是不能正常上班的(這種方式類似於前面的服務端非阻塞demo方式)。第三種方式:你每天正常上班,等體檢醫院打電話通知你拿體檢結果,你再去拿,電話通知你拿體檢結果的過程就相當於非同步事件通知,這樣你就可以正常上班了。第一、二種方式就是同步操作,第三種方式就是非同步操作。
總結: 同步和非同步的區別就是非同步操作藉助epoll的事件通知機制,從而可以充分利用