
lua-resty-r3 高效能 OpenResty 路由實現
大家下午好!首先做下自我介紹,我於 2014 年加入奇虎 360,後與溫銘結識,當時他正在基於 OpenResty 做天擎服務端,用於提供 API 服務。2015 年我們一起寫了《 OpenResty 最佳實踐 》,原因是當時我們團隊想擴充,但是身邊的同事都不知道如何學習 OpenResty,OpenResty 相關的學習資料也少。我們完成這本書的寫作後,就給身邊的同事們使用,而不再需要每次都通過口傳和培訓的方式來影響。意外的是我們在公司內影響的人並不多,反而在公司外卻通過這本書聚集了上萬人的社群成員。《 OpenResty 最佳實踐 》從無到有,完全是以開源的方式公開的。2015 年 12 月,老羅在錘子科技產品釋出會上宣佈將門票收入全部捐贈給開源專案 OpenResty,這次也讓更多的人知道了 OpenResty。2017 年 3 月,春哥(章亦春,網名:agentzh)準備創業,我就跟他一起作為技術合夥加入了 OpenResty Inc.。
今天跟大家分享我最近在做的基於 OpenResty 的高效能路由實現。我瞭解到很多人用 OpenResty 做閘道器,也有做 Web Server,由於 OpenResty 成立到現在周邊的庫和基礎設施並沒有很完善,所以我們一直想通過社群的方式來提供一個大家比較認同的開發框架來做 Web Server。對於 Web 框架裡面比較經典的是 MVC 結構,其中包括 Model、View 和 Controller 三層,目前 Model 和 View 層已經有了比較好的實現,而路由一直沒有特別強大、高效的解決方案。這次與大家介紹 lua-resty-r3 路由實現 ,和大家分享我在與春哥合作之後的一個感悟,作為一個開發什麼事情是值得我們吹牛?

首先說一說程式設計師的“牛皮”,之所以說這些是因為其中大部分是我曾經跟別人吹過的牛皮,比如“一天寫了幾千行程式碼”、“收入也不錯”、“做過超大專案,幾億 PV 小意思”等,這些都可能是程式設計師跟別人炫耀的話,但是我認為程式設計師真正的牛皮逃不出兩個點:“都在用我的程式碼”和“執行在更多計算機上”。金山的口號概括地特別好“希望我們寫的程式碼可以跑在每臺計算機上”,我們作為程式設計師,如果創造的每行程式碼可以讓所有人享受到這個程式碼的好處,這是一件非常榮耀的事情。
今天我們聚集在一起討論 OpenResty ,很大一部分原因是春哥創造了 OpenResty,而我們都在使用。春哥創造了我們每天都在用的東西,這就是他最“牛”的地方。
基礎元件開發特點
如果我們要寫程式碼讓更多的人使用,那麼程式碼就必須要下沉到基礎元件,因為基礎元件的開發所要求的嚴謹程度遠大於業務應用,基礎元件的開發通常需要滿足以下的要求:
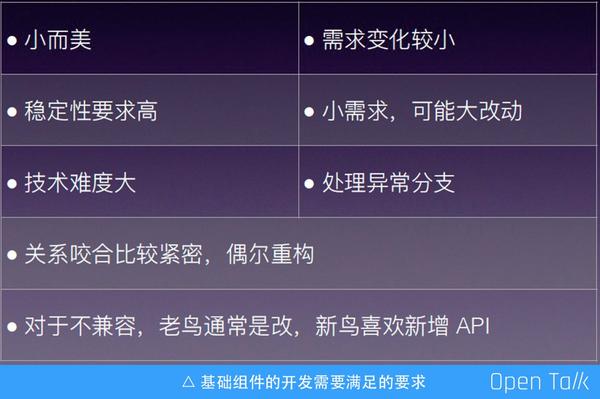
- 小而美,任何人都不希望基礎元件是一個很龐大的東西;
- 需求變化小;
- 穩定性要求高;
- 小需求,可能大改動;
- 能夠處理異常分支。這裡的處理要大於正常的業務邏輯,需要把所有的異常都包括在內;
- 技術難度大,甚至維護的難度也大。優秀的程式設計師能夠把一個難事做的很簡單;
- 關係咬合比較緊密,偶爾重構。由於基礎元件位於業務的底層,所以它需要支援的場景自己是不知道的;
- 基礎元件在迭代的時候,針對不相容的情況,老鳥通常是改,新鳥喜歡新增 API。
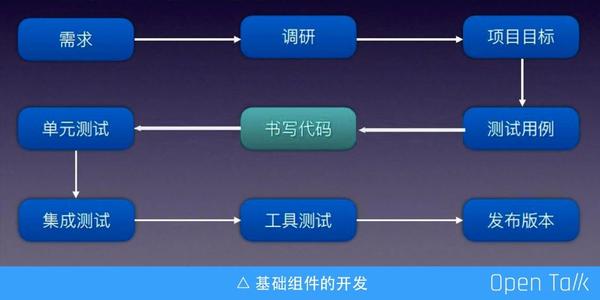
上圖是一條比較完整的基礎元件開發的流程,這裡列舉的並非包含了所有要素,而是我認為現在做基礎元件時哪些是必備的。最中心的是書寫程式碼,這個環節往往是重中之重,但如果要維持一個良好的基礎元件,實際上從最開始的需求提出到最後釋出版本全流程都需要注意。今天分享的議題是根據我對春哥以及 OpenResty 體系的研究,總結出最常見的基礎元件的維護的完整流程。
首先需求、調研和專案目標,甚至包括最簡單的測試用例,這些資訊主要是用來確定專案目標,我們首先要知道要做什麼?技術目標是什麼?以及要暴露哪些 API?當暴露了 API 之後,需要討論最小的使用迷你 case 是什麼樣子,從而梳理出前期的基本需求,這個環節通常開發可以自己拍板,主要涉及一些文件的工作。
測試模式
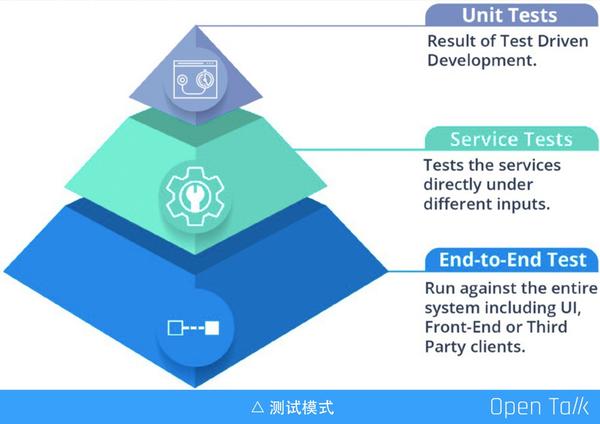
下面介紹三種測試模式,大部分人會接觸其中的 1-2 種。我認為其中可以適當輕鬆一下的是 Service Tests,而 Unit Tests(單元測試)是必須要有的,它能保證所有 API 的細節符合我們的輸入輸出。End-to-End Test (端到端測試),實際上是為了保證業務本身符合我們一開始的設計,它是直接面對使用者的,手機 App 點選選單,輸出各種各樣的效果,都是有自動化的工具來實現的。單元測試提供的是開發內部,而端到端測試是對於外部完整的聯動起來,這二者是必須要有的。
單元測試
OpenResty 體系內使用了在其他領域很少見的測試框架 Test::Nginx,OpenResty
裡面用了大量的 Lua ,而 Lua 的測試用例幾乎都是使用 busted 來書寫的,這二者之間有很大的區別。

OpenResty 能力很強的人,不一定能寫 Test::Nginx 的測試用例,因為它的語言是 Perl,很多人不熟悉。此外 Test::Nginx 是一個通用的測試框架,並不僅僅只服務於 OpenResty,它可以擴充延伸,甚至有其他很多不同測試的用途。但是右邊的 busted,明顯是隻能用於 Lua。
為什麼 OpenResty 要選 Test::Nginx 這個測試框架呢?原因是因為使用場景,OpenResty 的測試場景既要能夠測 C 模組,也要有能力測 Lua 模組,甚至有時候還要有能力測試一個服務,我們不僅需要測試進行內部,還需要測試程序的外部輸出,比如 HTTP 請求檢視結果。OpenResty 有執行階段的概念,同樣一串 Lua 程式碼在不同的階段行為是不一樣的。比如在 init 和 content 階段,所能夠使用的 API 完全不一樣,但是這種模式在 Lua 層面是完全做不到的。Test::Nginx 的功能點覆蓋比較強,由於它是可以跨階段,可以把 OpenResty 裡面所有特殊的情況排列組合,達到測試目的。
Test::Nginx 有這麼多優點,自然也會存在一些問題。首先是抽象的層次比較高,這就導致只看測試用例看不出它是用什麼語言支撐的,因為它都是抽象的配置項,比如要測試訪問碼,它是由單獨的配置項來實現的,和語言無關,這就需要專門看文件學習;第二個缺點是學習的難度比較高,尤其是需要做自定義修改時,比如擴充套件選項,這都是需要做二次開發或整合的。此外,Test::Nginx 是沒有程式碼覆蓋率的,因為程式碼覆蓋率必須要在原始碼內部才有,所以 busted 是有程式碼覆蓋率的。
選擇 Test::Nginx 的測試框架,還有一個很重要的原因是它是一個通用的測試框架,這意味著可以用這個測試框架測試現有的大部分的測試平臺軟體,比如 Java、Go 等。
以下是 Test::Nginx 測試框架的特點:
- 基於 Test::Base;
- Perl 語⾔(上⼿難);
- 語⾔無關的測試框架;
- 很強的擴充套件性(雖然難),既是優勢,也是劣勢;
- 可搭配 valgrind;
- 可搭配 ASAN;
目前 Test::Nginx 測試框架已經很好地集成了 valgrind 和 ASAN 這兩個記憶體整合工具,可以相互配合,他們都是用來做記憶體檢測的,檢查記憶體是否被正確釋放、使用等情況。
我最近兩年在寫服務的時候都是用的 Test::Nginx 測試框架,也給大家推薦一下,雖然有它的不足,但是帶來的好處也很多,最大的好處就是不需要在不同的測試體系下來回地切換思維。
書寫程式碼
接下來介紹一個技術細節,前面提到做基礎元件的開發會分幾步走,在書寫完測試用例後會進行程式碼書寫,我這次的路由書寫程式碼用的框架是基於 r3 ,它是一個開源的專案。它可以把路由規則編譯成一個字首樹,從而使匹配效率更高,可以直接用 Lua 呼叫 libr3.so 的庫,這種程式碼結構會非常簡單。但是缺點是如果通過 FFI 的方式來直接呼叫動態庫,需要知道動態庫調入時傳入的引數的所有結構,如果它的入參只是一些字串、數值,這樣會很簡單,直接包就可以。但是 libr3.so 的庫比較複雜,它有非常強的記憶體結構,它的很多輸入引數都是有結構體的,而且它也用了很多巨集定義來實現資料結構,然後用這樣的儲存結構來做傳參。當我們用 FFI 的方式來描述所有引數的結構體時,需要在 FFI 的檔案描述裡完整地寫出所用到的所有的頭、匯出的函式,以及依賴的結構體。
網上可以找到 Lua-resty-r3 的另一個開源實現,關於 C 標頭檔案描述用了 170 行程式碼,但是那個版本和 r3 最近的變化是衝突的,於是我嘗試修改了專案的程式碼,把現有的結構體的宣告、函式匯出的宣告都改一遍,修改到一半就遇到了問題,因為 r3 的結構體的實現一層套一層,而且裡面還有各種巨集的替換,導致人工來改的成本很高。
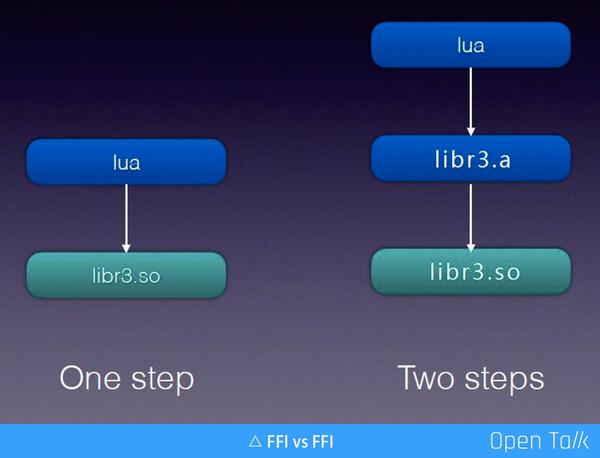
於是我對原本的 libr3 做一層封裝,把他內部所有呼叫的結構體的傳參全部藏起來,簡單地說就是把所有是結構體的地方都換成了一個指標,如果裡面的呼叫函式可以合併,就可以對外匯出一個標準的函式。如上圖右側 ”Two steps“,Lua 呼叫我們封裝的 libr3.so,libr3.so 底層呼叫的是原本的實現 libr3.a ,中間套了一層之後就看不到原來 r3 的結構體。
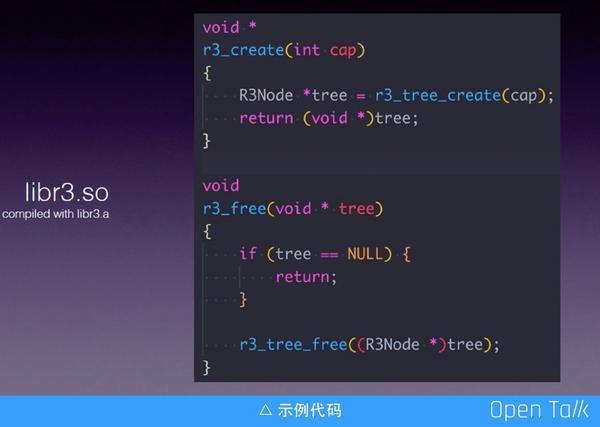
上圖是一段示例程式碼,可以看出大多數的封裝只是把型別轉了一下,並沒有特別複雜的封裝,只是把結構體都變成 void* 。這樣做的缺點是,對於結構體,C/C++ 編譯器編譯階段很容易找到引數型別傳錯的問題,而當我們換成 void* 的傳參,由於 void* 可以被任意傳參, 編譯器只能幫我們檢測錯誤的可能,這個問題是開發者需要注意的。
但是優勢也比較明顯,FFI 只需要匯出圖中的函式:
void*
r3_create(int cap)
void
r3_free(void*tree)它們匯出是不依賴任何的結構體,會讓庫寫起來非常方便,所以會讓 170 行程式碼變成 20 行。
持續整合
前面已經有了測試框架,我們需要有一種方式能夠做對當前所有的業務請求做一個完整的測試用例的迴歸。
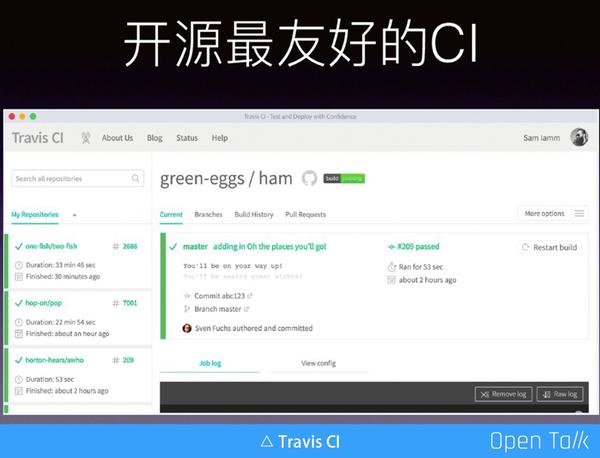
大家如果在用 Github 應該都會了解 Travis ,Travis 是對開源專案最友好的通用測試平臺。服務一旦開啟了 Travis ,每一次提交它都可以在平臺上做自動的迴歸測試,當然我們需要書寫一個 .yml 檔案,告訴它你要幹什麼事情、需要什麼環境、怎麼編譯、怎麼檢測等,它會給你一個結果的反饋,利用這個結果,就可以跟進軟體持續的開發。
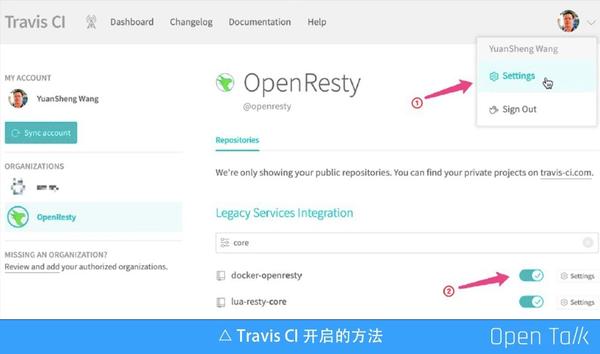
上圖是開啟 Travis CI 的方法,登陸自己的使用者,點選 Settings,在使用者的分組裡面,找到一個具體的專案,點選勾選就開啟了。
曾經很多人問過我,春哥的牛皮到底是什麼?其實這個問題,我在不同的階段也有不同的回答。現階段我認為春哥的測試體系非常厲害。OpenResty 這個軟體如果有哪個人能把春哥所有的東西以及這些子專案之間的關係全部搞清楚,我覺得已經很厲害了,而春哥卻以一己之力把這些東西玩的很轉,其中很大一部分原因是他把測試體系看的很重要,他在測試體系上的積累能夠讓他把 OpenResty 這個專案可持續地往前推進,所以大家以後要對測試體系要額外地重視,尤其是做一個比較複雜的元件。
測試工具

下面詳細介紹一下 C / C++ 的測試工具,我用這種方式發現了 r3 的兩個 bug。其中兩個測試都是與記憶體洩露相關,使用 ASAN mode 和 valgrind mode ,ASAN 是使用 clang 加編譯引數完成;valgrind 執行之前需要通過 valgrind 命令列的方式,它會模擬 CPU 完成記憶體的管理,幫我們檢查是否有記憶體洩露等情況。
wrk 和火焰圖是輔助工具,也是輔助我們發現問題。wrk 是一個壓測的工具,它和 OpenResty 存在的方式幾乎是一模一樣的,都是通過 C + Lua 實現,不過這裡的 Lua 和 OpenResty 裡面的 Lua 是兩回事,畢竟 Lua 是一門寄宿語言,是由它的宿主決定它具有什麼擴充套件性。火焰圖主要可以確定性能瓶頸,比如 CPU 佔時、記憶體持續洩露等問題。如果是效能問題,可以根據火焰圖橫座標的長度,確定問題大概在什麼位置,是哪段程式碼佔用過多 CPU 時間,如果時間消耗不是符合預期,就可以著手修他了。
在我的開發的習慣中,除了使用 ASAN 和 valgrind 來檢查記憶體問題,到最後一定會跑效能,跑完效能用後面的輔助工具來檢驗,觀察效能的指標是否符合預期。指標是一部分,還有是觀察火焰圖中看它表現出來的行為和預期的是否一樣,比如現在做的庫是 r3 路由,我們期望它所有的 CPU 消耗都在路由的預算上。兩個點可以關注:第一,是不是把大部分的時間都確實花在路由預算上,第二,路由預算的方法過程本身,是不是還有可優化的空間,這兩個問題都可以在火焰圖中找到非常好的答案。
建立里程碑
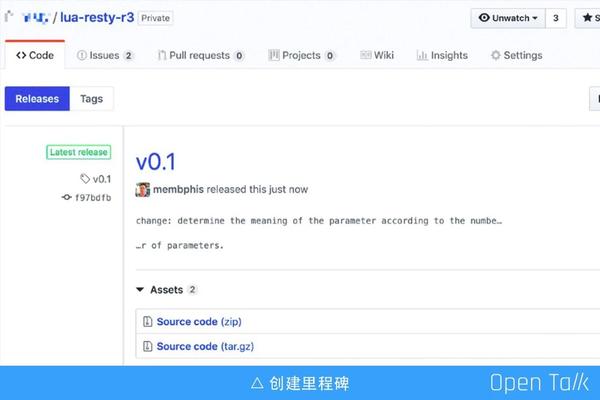
最後需要建立里程碑,完成了一個階段如果沒有里程碑,就沒有辦法跟領導申請立項,也拿不到專案的預算資金,所以里程碑非常重要,它可以關注每個階段的東西。除此之外,當我們做一個開源專案的時候,它的作用就更加明顯,它代表的是專案對外的穩定版本。
上圖是我對 lua-resty-r3 專案打的一個 tag ,這個版本是一個相對比較重要的穩定性階段,這個專案相關的所有東西我都會放到 Issues 裡面,目前這還是一個私有專案,不過過不了多久就會開源給大家。
今天分享的內容主要側重在開發流程上,純粹的技術細節不是很多,謝謝大家!
演講視訊及PPT:
lua-resty-r3 高效能 OpenResty 路由實現