
HDFS工作機制——自開發分散式資料採集系統
需求描述:
在業務系統的伺服器上,業務程式會不斷生成業務日誌(比如網站的頁面訪問日誌)
業務日誌是用log4j生成的,會不斷地切出日誌檔案,需要定期(比如每小時)從業務伺服器上的日誌目錄中,探測需要採集的日誌檔案(access.log不能採),發往HDFS
注意點:業務伺服器可能有多臺(hdfs上的檔名不能直接用日誌伺服器上的檔名)
當天採集到的日誌要放在hdfs的當天目錄中,採集完成的日誌檔案,需要移動到到日誌伺服器的一個備份目錄中定期檢查(每小時檢查一下備份目錄),將備份時長超出24小時的日誌檔案清除
資料採集流程分析
1.流程 啟動一個定時任務 定時探測日誌源目錄 獲取需要採集得檔案 移動這些檔案到一個待上傳得臨時目錄 遍歷待上傳目錄中得檔案,逐一傳輸到HDFS得目標路徑 同時將傳輸得檔案移動到備份目錄 啟動一個定時任務: 探測備份目錄中得備份資料,檢查是否超出最長備份時長,超出,則刪除 2.規劃各種路徑 日誌源路徑:d:/logs/accesslog/ 待上傳臨時目錄:d:/logs/toupload/ 備份目錄:d:/logs/backup/日期 HDFS 儲存路徑:/logs/日期 HDFS中檔案的字首:acceaa_log_ HDFS中檔案的字尾:.log
準備工作
[root@hdp-01 ~]# start-dfs.sh Starting namenodes on [hdp-01] hdp-01: starting namenode, logging to /root/apps/hadoop-2.7.2/logs/hadoop-root-namenode-hdp-01.out hdp-01: starting datanode, logging to /root/apps/hadoop-2.7.2/logs/hadoop-root-datanode-hdp-01.out hdp-03: starting datanode, logging to /root/apps/hadoop-2.7.2/logs/hadoop-root-datanode-hdp-03.out hdp-02: starting datanode, logging to /root/apps/hadoop-2.7.2/logs/hadoop-root-datanode-hdp-02.out hdp-04: starting datanode, logging to /root/apps/hadoop-2.7.2/logs/hadoop-root-datanode-hdp-04.out Starting secondary namenodes [hdp-02] hdp-02: starting secondarynamenode, logging to /root/apps/hadoop-2.7.2/logs/hadoop-root-secondarynamenode-hdp-02.out

程式碼如下
public class DataCollection {
public static void main(String[] args) {
Timer timer = new Timer();
//1.【定時探測日誌源目錄】,每一小時執行一次
timer.schedule(new CollectTask(),0,60*60*1000L);
}
}package com.xuyu.datacollection; import org.apache.commons.io.FileUtils; import org.apache.commons.logging.Log; import org.apache.commons.logging.LogFactory; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import java.io.File; import java.io.FilenameFilter; import java.net.URI; import java.text.SimpleDateFormat; import java.util.Arrays; import java.util.Date; import java.util.TimerTask; import java.util.UUID; public class CollectTask extends TimerTask { //構造一個log4j日誌物件 public static Log log = LogFactory.getLog(CollectTask.class); public void run() { /** * 1.定時探測日誌源目錄 * 2.獲取需要採集得檔案 * 3.移動這些檔案到一個待上傳得臨時目錄 * 4.遍歷待上傳目錄中得檔案,逐一傳輸到HDFS得目標路徑 * 5.同時將傳輸得檔案移動到備份目錄 */ //獲取本次採集時的日期 SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd-HH"); String day = sdf.format(new Date()); //獲取本地要上傳檔案目錄 File srcDir = new File("d:/logs/accesslog/"); //2.【獲取需要採集得檔案】 File[] listFiles = srcDir.listFiles(new FilenameFilter() { public boolean accept(File dir, String name) { if(name.startsWith("access.log.")){ return true; } return false; } }); //記錄日誌 log.info("探測到如下檔案需要採集:"+Arrays.toString(listFiles)); try { //獲取臨時上傳目錄中的檔案 File toUploadDir = new File("d:/logs/toupload/"); //3.【移動這些檔案到一個待上傳得臨時目錄】 for (File file:listFiles) { //將採集的檔案移到臨時上傳目錄,將源目錄中需要上傳的檔案移動到臨時上傳目錄中 FileUtils.moveFileToDirectory(file,toUploadDir,true); } //記錄日誌 log.info("上述檔案移動到待上傳目錄"+toUploadDir.getAbsolutePath()); //構造一個HDFS的客戶端物件 FileSystem fs = FileSystem.get(new URI("hdfs://hdp-01:9000"), new Configuration(), "root"); //從臨時上傳目錄中列出所有檔案 File[] toUploadFiles = toUploadDir.listFiles(); //1.檢查hdfs 中的日期是否存在 Path hdfsDestPath = new Path("/logs/" + day); if(!fs.exists(hdfsDestPath)){ fs.mkdirs(hdfsDestPath); } //2.檢查本地的備份目錄是否存在 File backupDir = new File("d:/logs/backup/" + day); if(!backupDir.exists()){ backupDir.mkdirs(); } //4.【遍歷待上傳目錄中得檔案,逐一傳輸到HDFS得目標路徑】 for (File file:toUploadFiles) { //傳輸檔案到HDFS並改名 Path destPath = new Path(hdfsDestPath + "/access_log_" + UUID.randomUUID() + ".log"); //將臨時上傳目錄中的檔案上傳到hdfs中 fs.copyFromLocalFile(new Path(file.getAbsolutePath()),destPath); //記錄日誌 log.info("檔案傳輸到hdfs完成:"+file.getAbsolutePath() +"-->"+destPath); //5.【同時將傳輸得檔案移動到備份目錄】 FileUtils.moveFileToDirectory(file,backupDir,true); //記錄日誌 log.info("檔案備份完成:"+file.getAbsolutePath() +"-->"+backupDir); } } catch (Exception e) { e.printStackTrace(); } } }
日誌配置
log4j.rootLogger=CONSOLE,stdout,logfile
#stdout控制器
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.Target=System.out
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
#輸出格式
log4j.appender.stdout.layout.ConversionPattern=%d %p [%c]:%L - %m%n
#檔案路徑輸出
log4j.appender.logfile=org.apache.log4j.RollingFileAppender
log4j.appender.logfile.File=d:/logs/collect/collect.log
log4j.appender.logfile.layout=org.apache.log4j.PatternLayout
log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%npom依賴
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>RELEASE</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-core</artifactId>
<version>2.8.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.7.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.7.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.7.2</version>
</dependency>
</dependencies>控制檯輸出
...
47 - 探測到如下檔案需要採集:[d:\logs\accesslog\access.log.1, d:\logs\accesslog\access.log.2, d:\logs\accesslog\access.log.3]
57 - 上述檔案移動到待上傳目錄d:\logs\toupload
79 - 檔案傳輸到hdfs完成:d:\logs\toupload\access.log.1-->/logs/2019-05-25-12/access_log_9dc0542e-0153-4bb3-b804-d85115c20153.log
83 - 檔案備份完成:d:\logs\toupload\access.log.1-->d:\logs\backup\2019-05-25-12
79 - 檔案傳輸到hdfs完成:d:\logs\toupload\access.log.2-->/logs/2019-05-25-12/access_log_5ce3450d-8874-4dd7-a23e-8d6a7a52c6d9.log
83 - 檔案備份完成:d:\logs\toupload\access.log.2-->d:\logs\backup\2019-05-25-12
79 - 檔案傳輸到hdfs完成:d:\logs\toupload\access.log.3-->/logs/2019-05-25-12/access_log_f7b7c741-bb87-4778-98ad-e33f06501441.log
83 - 檔案備份完成:d:\logs\toupload\access.log.3-->d:\logs\backup\2019-05-25-12
...
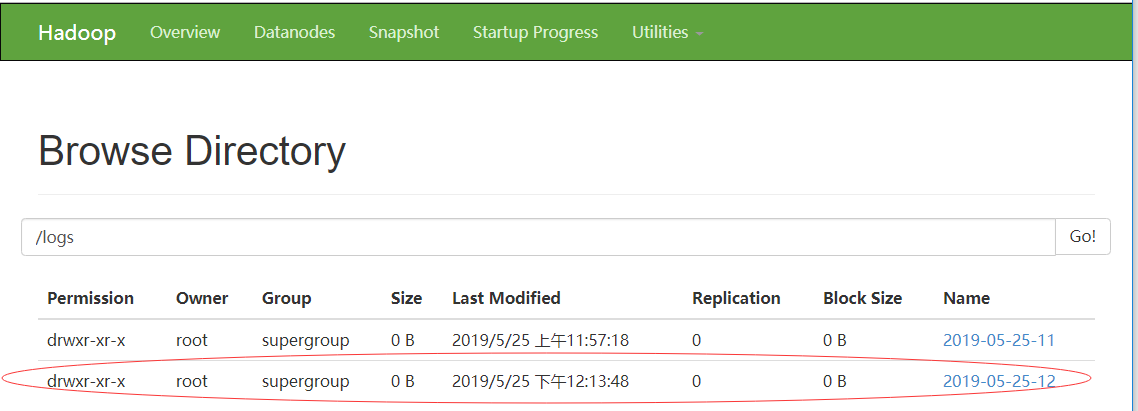
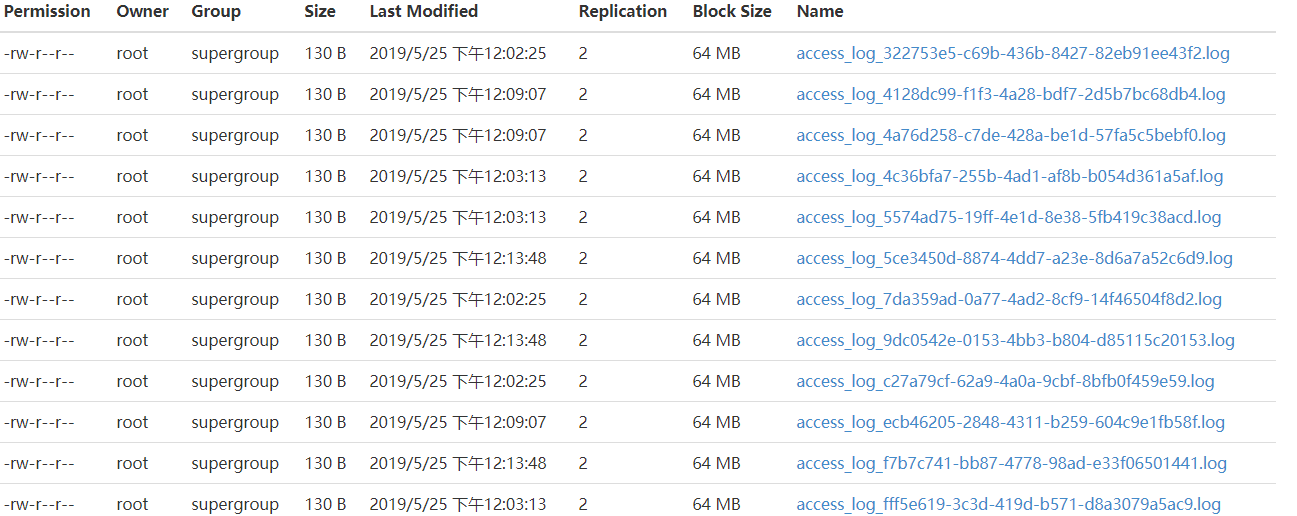
效果圖
相關推薦
HDFS工作機制——自開發分散式資料採集系統
需求描述: 在業務系統的伺服器上,業務程式會不斷生成業務日誌(比如網站的頁面訪問日誌) 業務日誌是用log4j生成的,
大資料(4)---HDFS工作機制簡述
一、name node管理元資料 元資料:hdfs的目錄結構以及檔案檔案的塊資訊(塊副本數量,存放位置等)。 Namenode把元資料存在記憶體中,以方便改動,同時也會在某個時間點上面將其寫到磁碟上(fsimage映象檔案)。同時還會把引起元資料變化的操作記錄在edits日誌檔案中。重新啟動或者是服務掛了的時
hadoop namenode datanode hdfs工作機制
node 節點 客戶 行合並 滿了 oop 重命名 技術 namenode 大家都知道namenode是hadoop中的一個很重要的節點,因為他存在著跟datanode的交互跟客戶端的交互,存儲著dotanode中的元數據,所以就很想學習他們是如何溝通並能保證數據在任何
【待完成】[HDFS_3] HDFS 工作機制
str 檢查 reat 輸出流 com default font === 過程 0. 說明 HDFS 初始化文件系統分析 && HDFS 文件寫入流程 && HDFS 文件讀取流程分析 1. HDFS 初始化文件系
開發感想 基於8051的資料採集系統(科技)
競賽作品名稱 基於8051的資料採集系統 簡介 下位機:8051開發板上的感測器採集需要的資料,通過RS-232傳送給上位機。
開發感想 基於8051的資料採集系統(人文)
競賽作品名稱 基於8051的資料採集系統 簡介 下位機:8051開發板上的感測器採集需要的資料,通過RS-232傳送給上位機。
如何用elasticsearch構架億級資料採集系統(第1集:非生產環境windows安裝篇)
(一)做啥的? 基於Elasticsearch,可以為實現,大資料量(億級)的實時統計查詢的方案設計,提供底層資料框架。 本小節jacky會在非生產環境下,在 window 系統下,給大家分享著部分的相關內容。 (二)Elasticsearch的安裝 2.1 版本選擇:ela
創業公司做資料分析(三)使用者行為資料採集系統
作為系列文章的第三篇,本文將重點探討資料採集層中的使用者行為資料採集系統。這裡的使用者行為,指的是使用者與產品UI的互動行為,主要表現在Android App、IOS App與Web頁面上。這些互動行為,有的會與後端服務通訊,有的僅僅引起前端UI的變化,但是
資料採集系統DMS
資料採集系統DMS 一、軟體專案開發流程 1.需求分析:業務語言->技術語言、歸納和整理《需求規格說明書》 2.概要設計:技術路線、結構框架、開發計劃《概要設計說明書》 3.詳細設計:功能性詳細描述、型別、函式、各種條件、流程設計、關鍵演算法、關鍵庫介面《詳細設計說明書》 4.編寫程式碼:
003用LabVIEW和Arduino開發一個溫度採集系統
1背景 其實滿打滿算,今天是自己接觸LabVIEW的第四天,只是是由於國慶節之前報名參加了一個比賽,國慶節期間又沒有引起足夠的重視,所以當比賽只剩下四天的時候才開始研究LabVIEW。雖然趕在截止時間
[大資料] 搜尋日誌資料採集系統 flume+hbase+kafka架構 (資料搜狗實驗室)
1 採集規劃 說明: D1 日誌所在伺服器1 —bigdata02.com D2 日誌所在伺服器2 —bigdata03.com 日誌收集 日誌收集 日誌整合 儲存到kafka 儲存到HBase 2版本 kafka kafka_2.11-0.10
elk+kafka 分散式日誌採集系統設計
Filebeat (每個微服務啟動一個)--->Kafka叢集--->Logstash(one)-->Elasticsearch叢集 一、資料流從檔案端到Kafka 叢集端,通過Filebeat 1.下載 Filebeat #cd /opt/filebeat
flume分散式日誌採集系統實戰-陳耀武-專題視訊課程
flume分散式日誌採集系統實戰—4303人已學習 課程介紹 隨著公司業務的不斷增長,劃分了許多應用,不同應用的日誌在不同伺服器上面,很難進行統一管理,通過學習該課程,你可以自己搭建日誌採集系統,可以進行資料分析,挖掘等工作課程收益 通過學習該課程,可以快
網頁資料採集系統(58同城、美團)
QQ/微信 112908676 下載過程中彈出輸入密碼框,請選擇取消,不影響使用 支援Windows XP/Vista/7/8/10 需求 美團獲取外賣和團購商戶的基本資訊,比如商戶名稱、地址以及聯絡電話 將搜尋的結果匯出至Excel表中,無需使用者手動翻頁
高效能資料採集系統
使用元件 Go + Cassandra Go: 負責高併發請求處理 Cassandra: 負責高速寫、儲存及擴充套件
大資料理論篇 - 通俗易懂,揭祕分散式資料處理系統的核心思想(一)
> 作者:[justmine]( https://www.cnblogs.com/justmine/) > > 頭條號:[大資料達摩院]( https://www.cnblogs.com/justmine/) > > 創作不易,未經授權,禁止轉載,否則保留追究法律責任的權利。 [TOC]
hadoop[4]-hdfs分散式檔案系統的基本工作機制
一、Namenode 和 Datanode HDFS採用master/slave架構。一個HDFS叢集是由一個Namenode和一定數目的Datanodes組成。Namenode是一箇中心伺服器,負責管理檔案系統的名字空間(namespace)以及客戶端對檔案的訪問。叢集中的Datanode一般是一個節點一
Atittit HDFS hadoop 大資料檔案系統java使用總結 目錄 1. 作業系統,進行操作 1 2. Hdfs 類似nfs ftp遠端分散式檔案服務 2 3. 啟動hdfs服務start
Atittit HDFS hadoop 大資料檔案系統java使用總結 目錄 1. 作業系統,進行操作 1 2. Hdfs 類似nfs ftp遠端分散式檔案服務 2 3. 啟動hdfs服務start-dfs.cmd 2 3.1. 配置core-site
web———資料連線池的工作機制是什麼?
1.資料庫連線池屬於建立時間昂貴,並且數量有限的資源。如果每次執行sql時都建立新的連線,使用完即刻關閉連線,不僅會造成資源的浪費,而且在併發量大的情況下還會拖慢甚至拖垮資料庫。(測試得出結果單獨執行緒建立資料庫建立時間遠遠大於執行時間) 2. 因此需要使用連線池的概念:預先建立好一批資
大資料(十四):多job串聯與ReduceTask工作機制
一、多job串聯例項(倒索引排序) 1.需求 查詢每個單詞分別在每個檔案中出現的個數 預期第一次輸出(表示單詞分別在個個檔案中出現的次數) apple--a.txt 3 apple--b.txt 1 apple--c.txt 1 grape--a.txt