
利用【mapreduce】來實現——【wordcount的設計思路】
1.wordcount示例開發
map階段:將每行文字資料變成<單詞,1>這樣的k,v資料
reduce階段:將相同單詞的一組kv資料進行聚合,累加所有的v
1.1注意事項
mapreduce程式中: 1.map階段的進,出資料 2.reduce階段的進,出資料 型別都應該是實現了Hadoop序列化框架型別 比如:String對應Text;Integer對應IntWritable;Long對應LongWritable
1.2wordcount程式整體執行流程示意圖
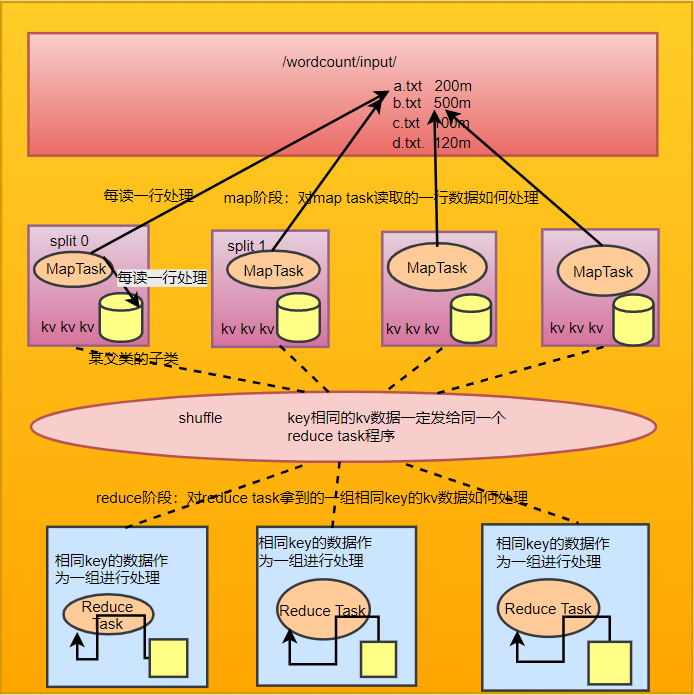
2.yarn的基本概念
yarn是一個分散式程式的執行排程平臺
yarn中有兩大核心角色:
1、Resource Manager
接受使用者提交的分散式計算程式,併為其劃分資源
管理、監控各個Node Manager上的資源情況,以便於均衡負載
2、Node Manager
管理它所在機器的運算資源(cpu + 記憶體)
負責接受Resource Manager分配的任務,建立容器、回收資源
2.1.YARN的安裝
node manager在物理上應該跟data node部署在一起 resource manager在物理上應該獨立部署在一臺專門的機器上
2.2修改配置檔案
參考官網:http://hadoop.apache.org/docs/stable/hadoop-yarn/hadoop-yarn-common/yarn-default.xml
cd /root/apps/hadoop-2.7.2/etc/hadoop
vi yarn-site.xml2.3在<configuratiomn></configuration>裡面新增
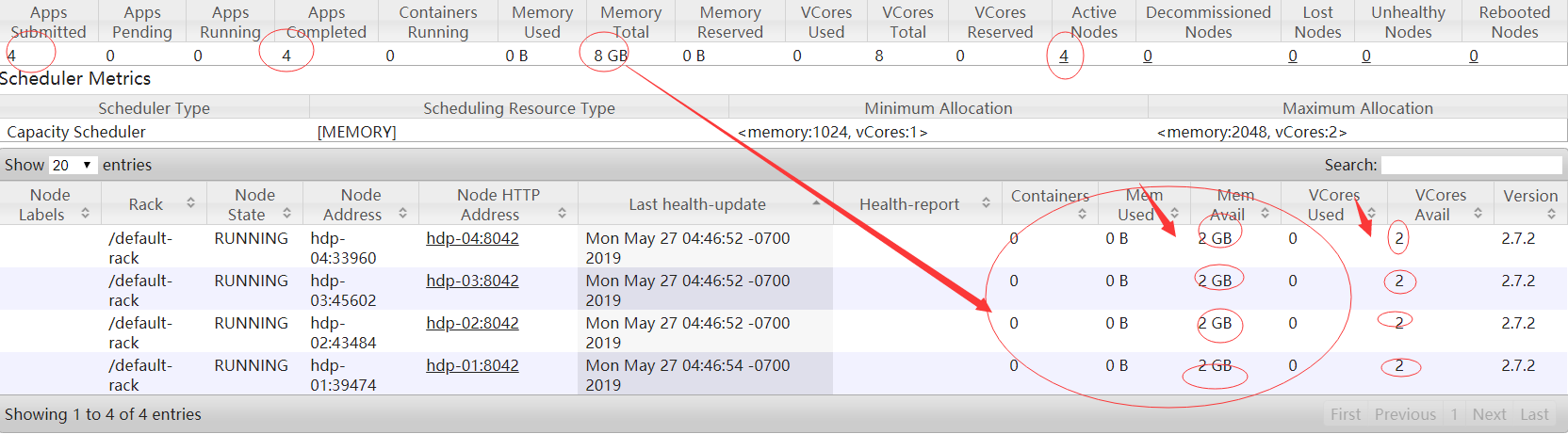
<property> <name>yarn.resourcemanager.hostname</name> <value>hdp-01</value> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.nodemanager.resource.memory-mb</name> <value>2048</value> </property> <property> <name>yarn.nodemanager.resource.cpu-vcores</name> <value>2</value> </property>
2.4拷貝配置檔案到其它節點上
scp yarn-site.xml hdp-02:$PWD
scp yarn-site.xml hdp-03:$PWD
scp yarn-site.xml hdp-04:$PWD3.啟動和停止hdfs叢集和yarn叢集命令
1.hdfs:
stop-dfs.sh:停止配置的namenode datanode
start-dfs.sh:啟動namenode datanode
2.yarn:
start-yarn.sh:啟動resourcemanager和nodemanager(注:該命令應該在resourcemanager所在的機器上執行)
stop-yarn.sh:停止resourcemanager和nodemanager4.其它命令
jps檢視ResourceManager程序號
netstat -nltp | grep 程序號
8088是網頁的
free -m:檢視還剩多少記憶體5.編碼實現
1.WordcountMapper類開發
2.WordcountReducer類開發
3.JobSubmitter客戶端類開發
5.1.WordcountMapper類開發
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
/**
* 1.KEYIN:是map task讀取到的資料的key的型別,是一行的起始偏移量Long
* 2.VALUEIN:是map task讀取到的資料的value的型別,是一行的內容String
* 3.KEYOUT:是使用者的自定義map方法要返回的結果kv資料的key型別,在
* word count邏輯中,返回單詞String
* 4.VALUEOUT:是使用者的自定義map方法要返回的結果kv資料的value型別,
* 在word count邏輯返回Integer
*
* 但是在mapreduce中,map 產生的資料需要傳輸給reduce,需要進行序列化和反序列化,
* 而Jdk 中的原生序列化機制產生的資料比較冗餘就會導致資料在mapreduce執行過程比
* 較慢,Hadoop專門設計了自己序列化機制,那麼,mapreduce 中傳輸的資料的資料型別
* 就必須實現Hadoop自己的序列化介面
* Hadoop為jdk 中常用的基本型別Long,String,Integer,Float等資料型別封裝了自己
* 的實現Hadoop序列化介面型別:LongWritable,Text(String),IntWritable..
*/
public class WordcountMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
//1.切單詞
String line = value.toString();
String[] words = line.split(" ");
for(String word:words){
context.write(new Text(word),new IntWritable(1));
}
}
}
5.2.WordcountReducer類開發
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
import java.util.Iterator;
/**
* 1.前面的Text,IntWritable:表示接收到map傳過來的引數
* 2.後面的Text, IntWritable:表示Reduce返回的資料型別
*/
public class WordcountReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
//idea快捷鍵(ctrl+o)檢視重寫的方法
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context)
throws IOException, InterruptedException {
int count=0;
Iterator<IntWritable> iterator = values.iterator();
while (iterator.hasNext()){
IntWritable value = iterator.next();
count += value.get();
}
context.write(key,new IntWritable(count));
}
}5.3.JobSubmitter客戶端類開發
/**
* 用於提交MapReduce的客戶端程式
* 功能:
* 1,封裝本次job執行時所需要的必要引數
* 2.跟yarn進行互動,將mapreduce 程式成功的啟動,執行
*/
public class JobSubmitter {
public static void main(String[] args)throws Exception {
//在程式碼中設定JVM系統引數,用於給job物件來獲取訪問HDFS的使用者身份
System.setProperty("HADOOP_USER_NAME","root");
Configuration conf = new Configuration();
//1.設定job執行時預設要訪問的檔案系統
conf.set("fs.defaultFS","hdfs://hdp-01:9000");
//2.設定job提交到哪裡去執行(放本地local,這裡放在yarn上執行)
conf.set("mapreduce.framework.name","yarn");
//3.指定位置
conf.set("yarn.resourcemanager.hostname","hdp-01");
//4.如果需要在Windows系統執行這個job提交客戶端程式,則需要加這個跨平臺提交引數
conf.set("mapreduce.app-submission.cross-platform","true");
Job job = Job.getInstance(conf);
//1.封裝引數:jar包所在的位置
job.setJar("d:/wc.jar");
//動態獲取jar包在哪裡
//job.setJarByClass(JobSubmitter.class);
//2.封裝引數:本次job所要呼叫的mapper實現類
job.setMapperClass(WordcountMapper.class);
job.setReducerClass(WordcountReducer.class);
//3.封裝引數:本次job的Mapper實現類產生的資料key,value的型別
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
//4.封裝引數:本次Reduce返回的key,value資料型別
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
Path output=new Path("/wordcount/output5");
FileSystem fs = FileSystem.get(new URI("hdfs://hdp-01:9000"),conf,"root");
if(fs.exists(output)){
fs.delete(output,true);
}
//5.封裝引數:本次job要處理的輸入資料集所在路徑,最終結果的輸出路徑
FileInputFormat.setInputPaths(job,new Path("/wordcount/input"));
FileOutputFormat.setOutputPath(job,output);
//6.封裝引數:想要啟動的reduce task的數量
job.setNumReduceTasks(2);
//7.向yarn提交本次job
//job.submit();
//等待任務完成,把ResourceManage反饋的資訊打印出來
boolean res = job.waitForCompletion(true);
System.exit(res ? 0:-1);
}
}5.4.pom依賴
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.8.1</version>
</dependency>
</dependencies>5.5.執行mapreduce程式
1.將工程整體打成一個jar包並上傳到linux機器上,
2.準備好要處理的資料檔案放到hdfs的指定目錄中
3.用命令啟動jar包中的Jobsubmitter,讓它去提交jar包給yarn來執行其中的mapreduce程式 : hadoop jar wc.jar cn.xuyu.JobSubmitter .....
4.去hdfs的輸出目錄中檢視結果
5.6.測試說明
本次測試在Windows環境,所以需要打成jar包,改名為wc.jar放在本地D:/盤目錄下5.7.執行結果
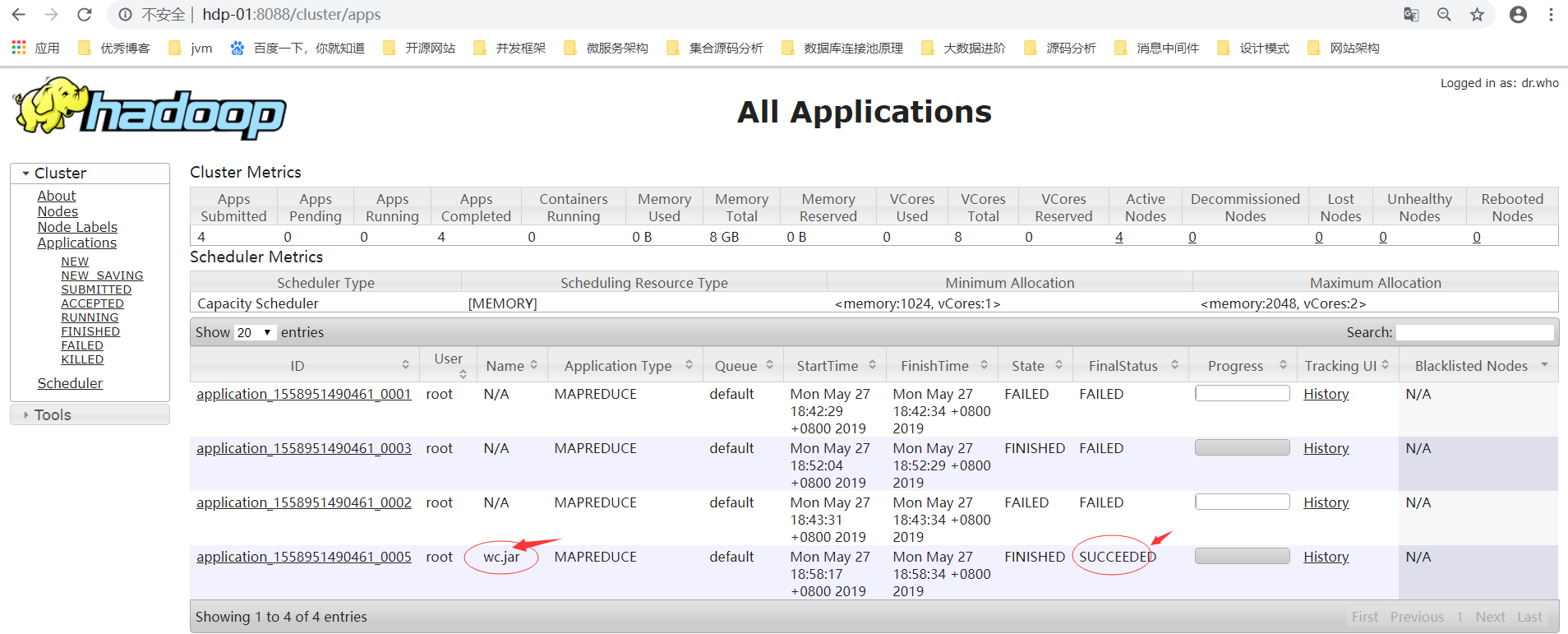
5.7.1.訪問:http://hdp-01:8088/cluster/apps
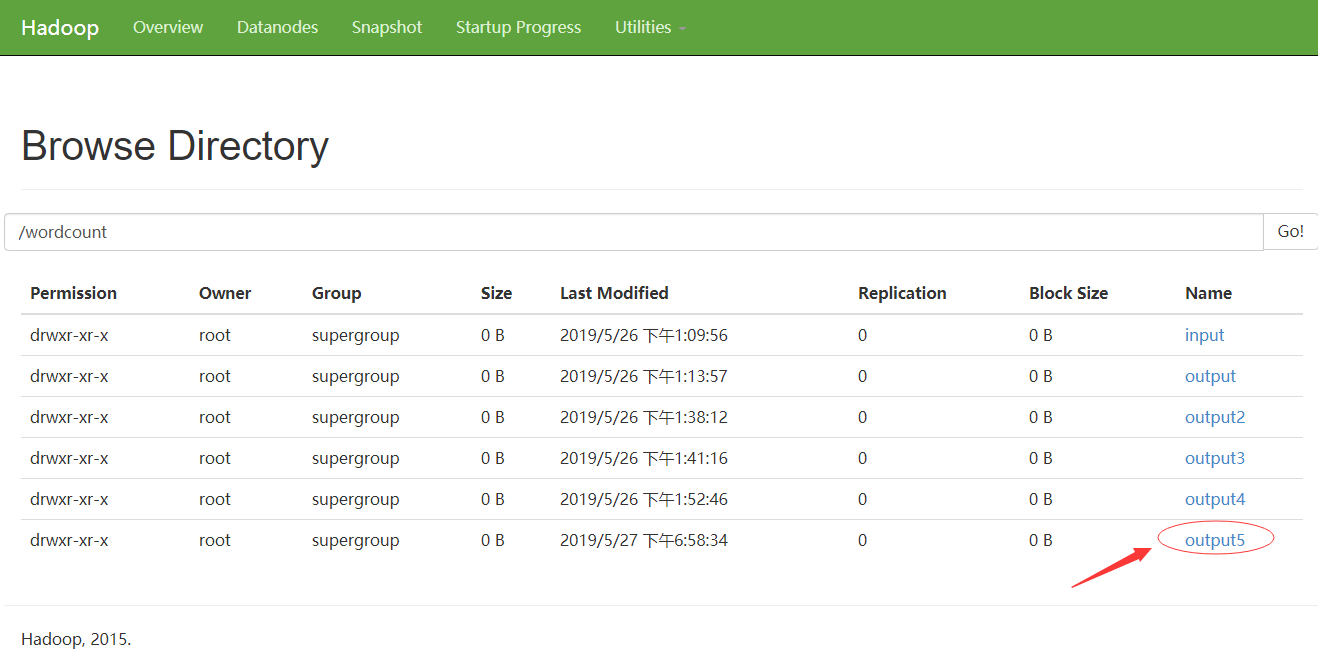
5.7.2.訪問:http://hdp-01:50070/explorer.html#/wordcount
5.7.3.命令列輸入命令檢視統計結果
[root@hdp-01 ~]# hadoop fs -ls /wordcount/output
Found 1 items
-rw-r--r-- 2 root supergroup 59 2019-05-25 22:13 /wordcount/output/res .dat
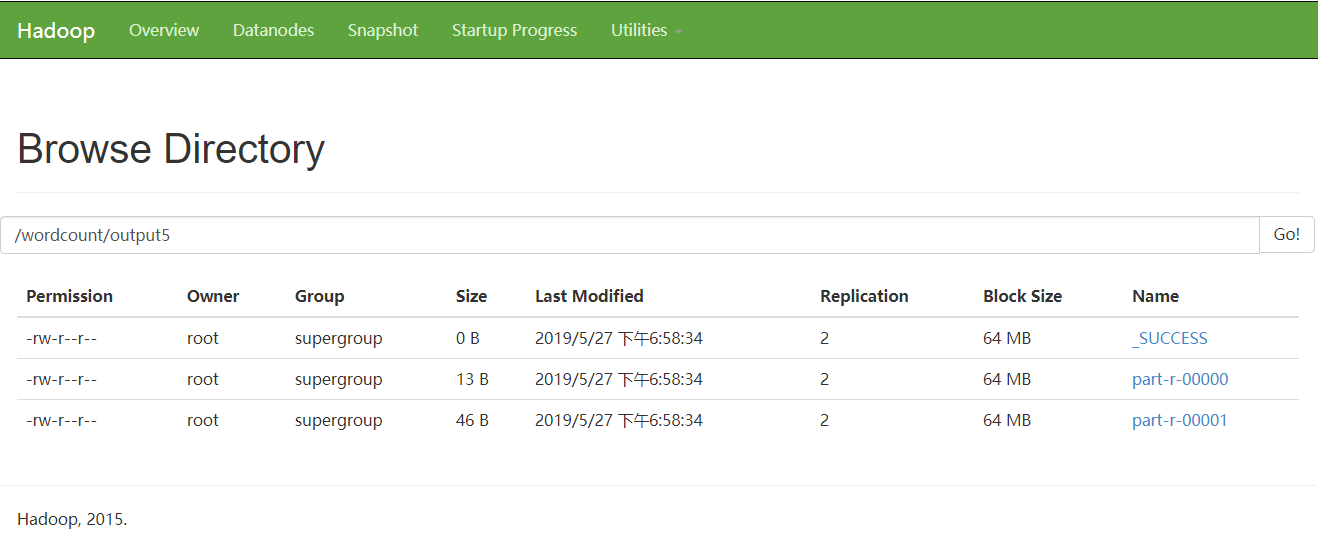
[root@hdp-01 ~]# hadoop fs -ls /wordcount/output5
Found 3 items
-rw-r--r-- 2 root supergroup 0 2019-05-27 03:58 /wordcount/output5/_S UCCESS
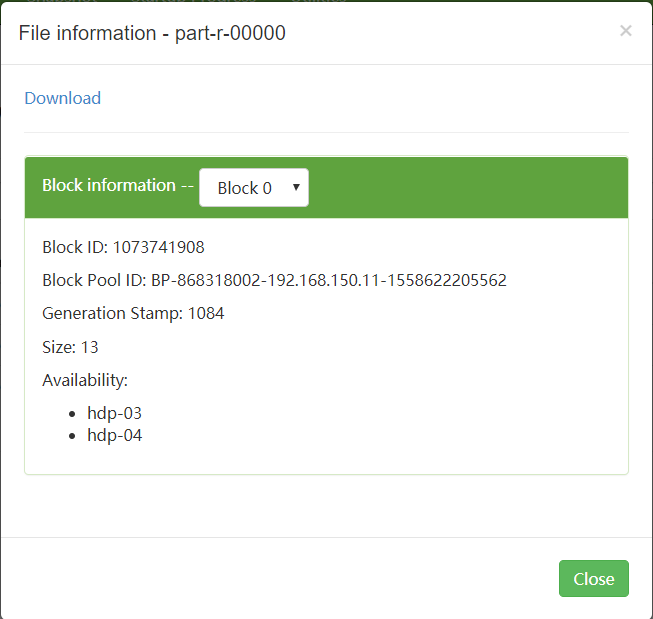
-rw-r--r-- 2 root supergroup 13 2019-05-27 03:58 /wordcount/output5/pa rt-r-00000
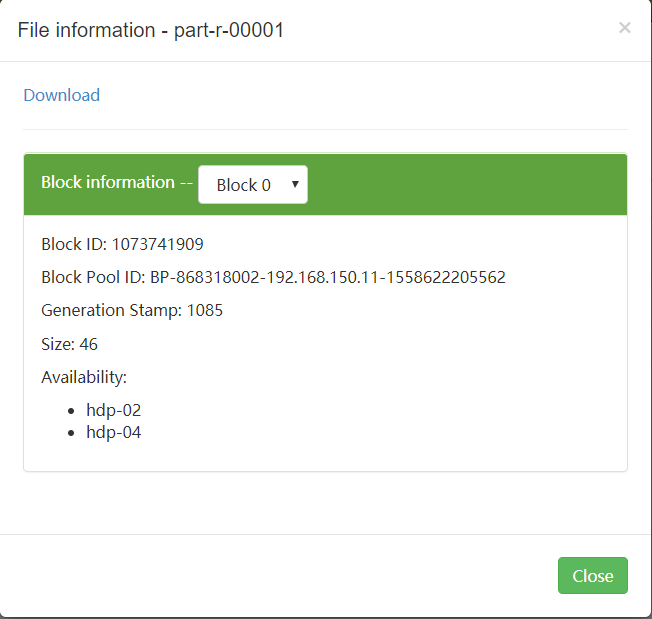
-rw-r--r-- 2 root supergroup 46 2019-05-27 03:58 /wordcount/output5/pa rt-r-00001
[root@hdp-01 ~]# hadoop fs -cat /wordcount/output5/part-r-00001
3
FFH 3
GGH 3
Helllo 3
Hello 15
Jasd 3
Tom 3
[root@hdp-01 ~]# hadoop fs -cat /wordcount/output5/part-r-00000
GGG 3
xuyu 3
5.7.4.在瀏覽器中檢視內容
5.7.5.下載下來可以看到如下內容
相關推薦
利用【mapreduce】來實現——【wordcount的設計思路】
1.wordcount示例開發 map階段:將每行文字資料變成<單詞,1>這樣的k,v資料 reduce
如何巧用設計模式【模板+工廠】來實現【聚合支付平臺非同步回撥】
核心設計要點 AbstractClass : 抽象類,定義並實現一個模板方法。這個模板方法定義了演算法的骨架,而邏輯的
程式設計師突發奇想,如何巧用設計模式來實現【聚合支付非同步回撥】
什麼是模版方法 1.定義了一個操作中的演算法的骨架,而將部分步驟的實現在子類中完成。 模板方法模式使得子類可以不改變一個演算法
利用spring的AOP來實現Redis快取
為什麼使用Redis 資料查詢時每次都需要從資料庫查詢資料,資料庫壓力很大,查詢速度慢,因此設定快取層,查詢資料時先從redis中查詢,如果查詢不到,則到資料庫中查詢,然後將資料庫中查詢的資料放到redis中一份,下次查詢時就能直接從redis中查到,不需要查
【乾貨分享】花坊類字型設計思路
今天帶給大家一波花坊類字型設計思路,希望可以幫打各位設計師小夥伴。 字型名稱:花兒花坊 行業:鮮花 創意思路:鮮花最能醉人,短暫的時光綻放自己最美的花樣,字型的視覺體現重點抓住美麗、自然、浪漫這幾個關鍵詞。 設計方法: 由於前幾篇都有詳細過程,此處就不再累贅重
利用htmlunit和jsoup來實現爬取js的動態網頁實踐(執行js)
更新,這就尷尬了,這篇文章部落格閱讀文章最多,但是被踩得也最多。 爬取思路: 所謂動態,就是通過請求後臺,可以動態的改變相應的html頁面,頁面並不是一開始就全部展現出來的。 大部分操作都是通過請求完成的,一次請求,一次返回。而在大多數網頁中請求往往都被開發者隱藏在了js程
安卓開發-利用smart-image-view來實現網路中的圖片在手機上的顯示
1.在專案中匯入smart-image-view的檔案如圖: 2.在activity_main.xml中,引入SmartImageView: <com.loopj.android.im
利用Rocketmq4.2版來實現分散式事務
花了點時間學了RocketMQ,下面是本人的一點點心得,如果覺的寫的好就點個贊,但如果你要借鑑話,我還是勸你看下面參考資料裡的視訊(作者為阿里牛人),雖然他分享的視訊是為了推銷阿里雲的DRDS、ONS(RocketMQ阿里版),只是講了個大概,沒有細說,但是指明一個大的方向,
【android】音樂播放器之設計思路
學習Android有一個多月,看完了《第一行程式碼》以及mars老師的第一期視訊通過音樂播放器小專案加深對知識點的理解。從本文開始,將詳細的介紹簡單仿多米音樂播放器的實現,以及網路解析資料獲取百度音樂最新排行音樂以及下載功能。 功能介紹
EXCEL 中利用 INDEX 和match 來實現多條件查詢
1: 先建立一個sheet: 2: 測試:有兩個人叫同一個“胡天”,只是來自不同的省份: 先測試一下match: MATCH(A24&B24,A2:A16&B2:B16,0) 注意是 要 ctrl + shift + enter 一起按下去,才生效。看到
java 利用common-httpclient包來實現post請求
專案中需要請求第三方介面,而且要求請求引數資料為json型別的。本來首先使用的是httpclient的jar包,但是因為專案中已經使用了common-httpclient的jar包,引起了衝突,所以不得不使用common-httpclient來實現。 impo
利用SpringMVC的AOP來實現後臺系統的操作日誌記錄
最近在專案中要求把後臺的一些關鍵操作記錄下來,想了好半天能想到的也就那兩三種方式,要麼就是寫一個攔截器,然後再web.xml裡面進行配置,要麼就是就是在每個需要記錄操作日誌的程式碼裡面進行攔截,最後我選擇了第三種,也就是基於AOP的攔截,用這種方式,只需要在需記
cocos2dx 利用遮罩層來實現地圖的簡單尋路
談到地圖不少人都說要做地圖編輯器了,但是我暫時繞過這一步,如果不用尋路地圖就不能移動?尋路就是會繞過障礙物的演算法。 我做了一個簡單的地圖的思想,就是地圖分層3層:背景層、可行區域層、遮罩層,但是地圖就不尋路了,通過設定可行區域層來 實現地圖障礙物的方法。下面看一個檢視,
在可停靠窗格中使用對話方塊來實現視覺化設計
摘要:本文將介紹如何在可停靠視窗(Dockable Pane)中使用對話方塊來來實現視覺化設計,即將一個對話方塊(Dialog)作為子視窗填充在可停靠窗格之中,這樣做的好處是使得可以通過Visual Studio的對話方塊資源編輯功能視覺化地設計視窗,並輕鬆地實現控制元件的訊息處理程式。 關鍵字
web應用高複用,可擴充套件實現的一點設計思路
一:環境配置 開發環境:lnmp 開發框架:Yii2.0 二:目的 1.實現業務流程的清晰化 2.實現功能的高可複用性 3.實現業務的高可擴充套件性 4.可在web app,console app, api等形式中自由遷移
【利用鎖的三種方法來實現在多個執行緒時只執行一個執行緒】
package test.thread; public class TestSync { public static void main(String[] args) {
【selenium】利用excel來實現關鍵字驅動-Java
參考地址:https://my.oschina.net/hellotest/blog/531932#comment-list一、新建專案二、匯入包三、例子-excel 以CSDN的登入為例,首先我們可以分解登入的步驟,寫入excel,如下:四、編碼1、首先需要寫一個可以
【redis】spring boot利用redis的Keyspace Notifications實現消息通知
客戶 無效 handler mage extend width psu 消息通知 queue 前言 需求:當redis中的某個key失效的時候,把失效時的value寫入數據庫。 github: https://github.com/vergilyn/RedisSampl
【SQL】 藉助遊標來實現文字的分列與合併
有時我們會遇到需要把表中個別欄位拆分成多條資料或是把多條資料合併到一起的情況。一般的程式語言都有函式“split”和“join”來實現,而SQL中既沒有這些函式也沒有類似陣列和列表這類方便儲存成組資料的資料型別,一些對於字串的處理功能實現起來比較麻煩。直到SQL Server 2016才新增了string_s
【SQL】 借助遊標來實現文本的分列與合並
ack 沒有 成了 數據類型 close server ins http nodes 有時我們會遇到需要把表中個別字段拆分成多條數據或是把多條數據合並到一起的情況。一般的編程語言都有函數“split”和“join”來實現,而SQL中既沒有這些函數也沒有類似數組和列表這類方便