
Redis為什麼設計成單執行緒
今天下午,煙哥吃飽了撐著沒事幹,上班時間到處工(zhuang)作(bi)!只見同事小劉的桌上擺了一本Redis相關的書籍,內心嘿嘿一笑:“終於,又有機會勾搭小劉了!

"嗯,不要著急,跟著我思路來想!"煙哥道。
"假設,此刻有任務A和任務B,現在有如下兩種執行方式"
-
方式一 : 兩個執行緒,一個執行緒執行A,另一個執行緒執行B
-
方式二 : 一個執行緒,先執行A,執行完以後繼續執行B
"請問,哪種方式執行更快?"

只見煙哥眉頭微微一皺,說道:"我夜觀天象,掐指一算,小劉你大學在上《計算機組成原理》這門課的時候,一定逃課了!"
"應該是方式二更快,因為方式一中,CPU在切換執行緒的時候,有一個上下文切換時間,而這個上下文切換時間是非常耗時的

"OK,就是在I/O操作都時候,例如磁碟I/O,網路I/O等!為什麼一般是在I/O操作都時候,要用多執行緒呢(面試高頻題,必背)?因為I/O操作一般可以分為兩個階段:即等待I/O準備就緒和真正操作I/O資源!"
"以磁碟操作為例,磁碟的結構如下"
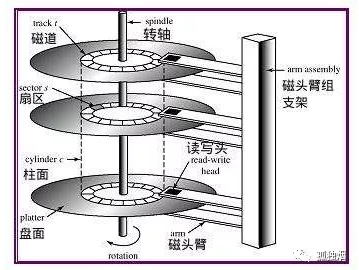
"在磁碟上資料是分磁軌、分簇儲存的,而資料往往並不是連續排列在同一磁軌上,所以磁頭在讀取資料時往往需要在磁軌之間反覆移動,因此這裡就有一個尋道耗時
"那麼,在這一時間段(即"I/O等待")內,執行緒是在“阻塞”著等待磁碟,此時作業系統可以將那個空閒的CPU核心用於服務其他執行緒。因此在I/O操作的情況下,使用多執行緒,效率會更高!"
"OK,現在回到我們的問題!Redis讀寫資料有涉及到I/O操作麼?"

"所以啊,Redis不涉及I/O操作,因此設計為單執行緒是效率最高的!那麼,既然你知道既然Redis的效能和CPU無關,那你知道Redis的效能瓶頸在哪麼?"
小劉無奈的搖了搖頭!
一般在兩個地方
-
其一是機器記憶體大小,記憶體大小關係到Redis儲存的資料量
-
其二是網路頻寬,這點我仔細說一下
Redis客戶端執行一條命令分為四個過程:傳送命令、命令排隊、命令執行、返回結果
而其中傳送命令+返回結果這一過程被稱為Round Trip Time(RTT,往返時間)
Redis的客戶端和服務端可能部署在不同的機器上。例如客戶端在北京,Redis服務端在上海,兩地直線距離約為1300公里,那麼1次RTT時間=1300×2/(300000×2/3)=13毫秒(光在真空中傳輸速度為每秒30萬公里,這裡假設光纖為光速的2/3),那麼客戶端在1秒內大約只能執行80次左右的命令,這就和Redis的高併發高吞吐特性背道而馳啦!所以一般情況下,都是就近