
學習排序演算法,結合這個方法太容易理解了
排序是一個經典的問題,它以一定的順序對一個數組或列表中的元素進行重新排序。而排序演算法也是各有千秋,每個都有自身的優點和侷限性。雖然這些演算法平常根本就不用自己去編寫,但作為一個有追求的程式設計師,還是要了解它們從不同角度解決排序問題的思想。
學習演算法是枯燥的,那怎麼高效的理解它的原理呢?顯然,如果以動圖的方式,生動形象的把演算法排序的過程展示出來,非常有助於學習。visualgo.net 就是一個視覺化演算法的網站,第一次訪問的時候,真的是眼前一亮。本文就對常用的排序進行下總結。
1. 氣泡排序
氣泡排序的基本思想就是:把小的元素往前調或者把大的元素往後調。假設陣列有 N 個元素,氣泡排序過程如下:
- 從當前元素起,向後依次比較每一對相鄰元素(a,b)
- 如果 a>b 則交換這兩個數
- 重複步驟1和2,直到比較最後一對元素(第 N-2 和 N-1 元素)
- 此時最大的元素已位於陣列最後的位置,然後將 N 減 1,並重復步驟1,直到 N=1
氣泡排序的核心程式碼:
public static void bubbleSort(int[] a, int n) { // 排序趟數,最後一個元素不用比較所以是 (n-1) 趟 for (int i = 0; i < n - 1; i++) { // 每趟比較的次數,第 i 趟比較 (n-1-i) 次 for (int j = 0; j < n - 1 - i; j++) { // 比較相鄰元素,若逆序則交換 if (a[j] > a[j+1]) { int tmp = a[j]; a[j] = a[j+1]; a[j+1] = tmp; } } } }
難點在於邊界的確定,演算法分析:
- 平均時間複雜度是 O(n^2),最佳情況是 O(n),最差情況是 O(n^2)
- 空間複雜度 O(1)
- 穩定的排序演算法(相等元素的前後順序排序後不變)
2. 選擇排序
選擇排序的基本思想就是:每次從未排序的列表中找到最小(大)的元素,放到已排序序列的末尾,直到所有元素排序完畢。假設陣列有 N 個元素且 L=0,選擇排序過程如下:
- 從 [L...N-1] 範圍中找到最小元素的下標 X
- 交換第 X 與第 L 位置的元素值
- L 加 1,重複以上步驟,直到 L=N-2
選擇排序的核心程式碼:
public static void selectionSort(int[] a, int n) { // 排序趟數,最後一個元素是最大的不用比較所以是 (n-1) 趟 for (int i = 0; i < n-1; i++) { int minIndex = i; // 無序列表中最小元素的下標 for (int j = i+1; j < n; j++) { // 在無序列表中查詢最小元素的小標並記錄 if (a[j] < a[minIndex]) { minIndex = j; } }// 將最小元素交換到本次迴圈的前端 int tmp = a[minIndex]; a[minIndex] = a[i]; a[i] = tmp; } }
演算法分析:
- 平均時間複雜度是 O(n^2),最佳和最差情況也是一樣
- 空間複雜度 O(1)
- 不穩定的排序演算法(相等元素的前後順序排序後可能改變)
3. 插入排序
插入排序的基本思想是:每次將待插入的元素,按照大小插入到前面已排序序列的適當位置上。插入排序過程如下:
- 從第一個元素開始,該元素可認為已排序
- 取出下一個元素,在已排序的元素序列中從後向前掃描
- 如果該元素(已排序)大於待插入元素 ,把它移到下一個位置
- 重複步驟 3,直到找到一個小於或等於待插入元素的位置,將待插入元素插入到下一個位置
- 重複步驟 2~5,直到取完陣列元素
插入排序的核心程式碼:
public static void insertionSort(int[] a, int n) {
// a[0] 看做已排序
for (int i = 1; i < n; i++) {
int x = a[i]; // 待插入元素
int j=i-1; // 插入的位置
while (j >= 0 && a[j] > x) {
a[j+1] = a[j]; // 為待插入元素騰地
j--;
}
a[j+1] = x; // 插入到下一個位置 j+1
}
}演算法分析:
- 平均時間複雜度是 O(n^2),最佳情況是 O(n),最差情況是 O(n^2)
- 空間複雜度 O(1)
- 穩定的排序演算法
4. 希爾排序
希爾排序也稱為增量遞減排序,是對直接插入演算法的改進,基於以下兩點性質:
- 插入排序在對幾乎已排好序的資料操作時,效率高,可以達到線性排序的效率
- 但插入排序一般來說是低效的,因為插入排序每次只能移動一位資料
希爾排序的改進是,使用一個增量將陣列切分不同的分組,然後在組內進行插入排序,遞減增量,直到增量為 1,好處就是資料能跨多個元素移動,一次比較就可能消除多個元素的交換。基本過程如下:
- 選取一個遞增序列,一般使用
x/2或者x/3+1 - 使用序列中最大的增量,對陣列分組,在組內插入排序,遞減增量,直到為 1
核心程式碼:
public static void shellSort(int[] a, int n) {
// 計算遞增序列,3x+1 : 1, 4, 13, 40, 121, 364, 1093, ...
int h = 1;
while (h < n/3) h = 3*h + 1;
while (h >= 1) {// 直到間隔為 1
// 按間隔 h 切分陣列
for (int i = h; i < n; i++) {
// 對 a[i], a[i-h], a[i-2*h], a[i-3*h]...使用插入排序
int x = a[i]; // 待插入元素
int j=i;
while (j >=h && x < a[j-h]) {
a[j] = a[j-h];// 為待插入元素騰地
j -= h;
}
a[j] = x; // 插入 x
}
// 遞減增量
h /= 3;
}
}希爾排序陣列拆分插入圖解,上面的動圖可以輔助理解,與下圖資料不一致:
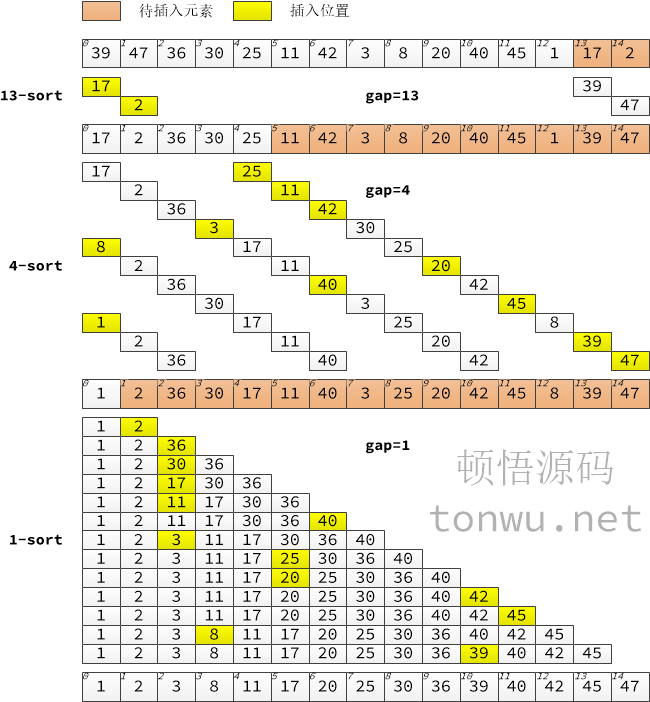
演算法分析:
- 時間複雜度與選擇的增量序列有關,可能的值時 O(n^2) > O(n^1.5) > O(nlg2n)
- 空間複雜度 O(1)
- 不穩定的排序演算法
5. 歸併排序(遞迴&非遞迴)
歸併排序是分而治之的排序演算法,基本思想是:將待排序序列拆分多個子序列,先使每個子序列有序,再使子序列間有序,最終得到完整的有序序列。歸併排序本質就是不斷合併兩個有序陣列的過程,實現時主要分為兩個過程:
- 拆分 - 遞迴的將當前陣列二分(如果N是偶數,兩邊個數平等,如果是奇數,則一邊多一個元素),直到只剩 0 或 1 個元素
- 歸併 - 分別將左右半邊陣列排序,然後歸併在一起形成一個大的有序陣列
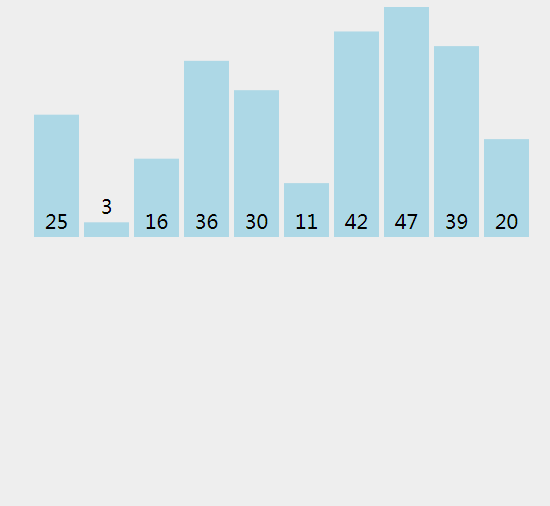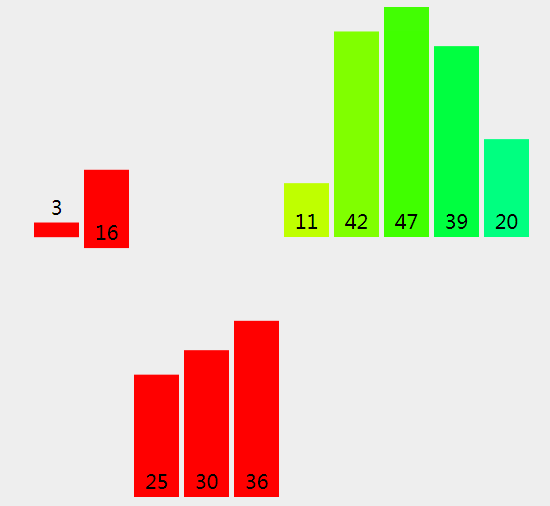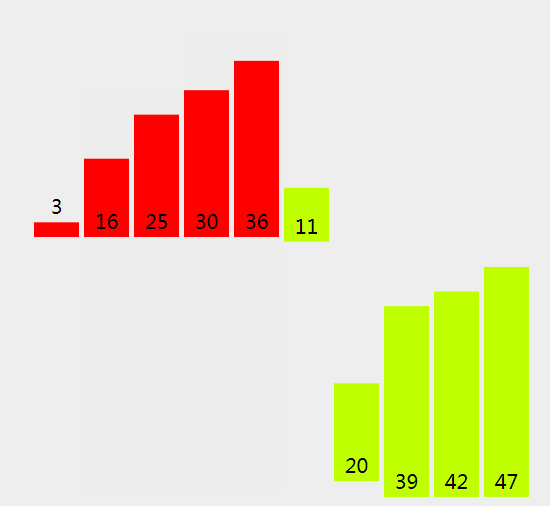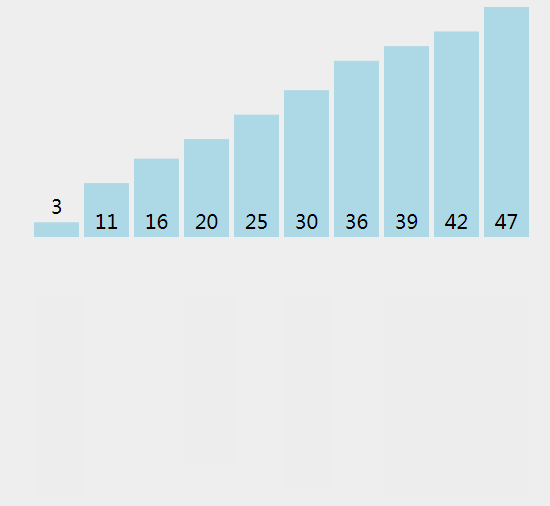
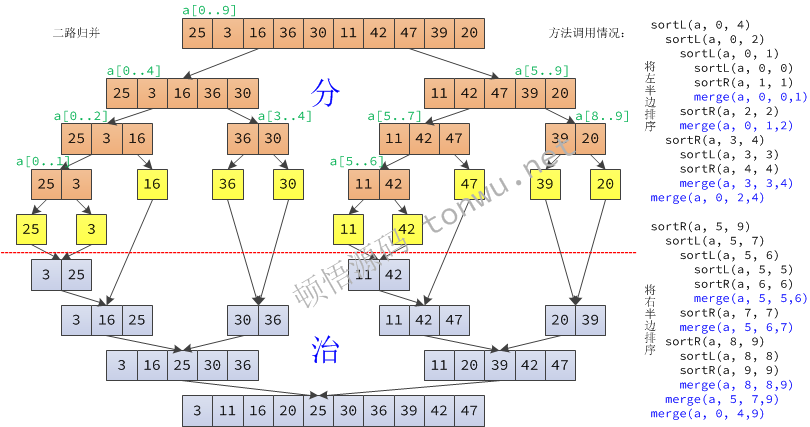
二路歸併遞迴實現,核心程式碼:
public static void mergeSort(int[] a, int low, int high) {
// 要排序的陣列 a[low..high]
if (low < high) {// 是否還能再二分 low >= high (0 或 1 個元素)
int mid = low + (high - low) / 2; // 取中間值,避免 int 溢位
mergeSort(a, low, mid); // 將左半邊排序
mergeSort(a, mid + 1, high); // 將右半邊排序
merge(a, low, mid, high); // 歸併左右兩邊
}
}
public static void merge(int[] a, int low, int mid, int high) {
int n = high - low + 1; // 合併後元素總數
int[] b = new int[n]; // 臨時合併陣列
int left = low, // 左邊有序序列起始下標
right = mid + 1, // 右邊有序序列起始下標
bIdx = 0;
// 按升序歸併到新陣列 b 中
while (left <= mid && right <= high) {
b[bIdx++] = (a[left] <= a[right]) ? a[left++] : a[right++];
}
// 右邊序列已拷貝完畢,左邊還有剩餘,將其依次拷貝到合併陣列中
while (left <= mid) {
b[bIdx++] = a[left++];
}
// 左邊序列已拷貝完畢,右邊還有剩餘,將其依次拷貝到合併陣列中
while (right <= high) {
b[bIdx++] = a[right++];
}
// 將歸併後的陣列元素拷貝到原陣列適當位置
for (int k = 0; k < n; k++) {
a[low + k] = b[k];
}
}陣列拆分和方法呼叫的動態情況如下圖(右鍵檢視大圖):
遞迴的本質就是壓棧,對於 Java 來說,呼叫層次太深有可能造成棧溢位。一般的,遞迴都能轉為迭代實現,有時迭代也是對演算法的優化。
歸併排序中的遞迴主要是拆分陣列,所以,非遞迴的重點就是把這部分改成迭代,它們的終止條件不同:
- 遞迴是在遇到基本情況時終止,比如遇到了兩個各包含1個元素的陣列,從大陣列到小陣列,自頂向下
- 迭代則相反,自底向上,它首先按 1 切分保證陣列中的每2個元素有序,然後按 2 切分,保證陣列中的每4個元素有序,以此類推,直到整個陣列有序
核心程式碼:
public static void unRecursiveMergeSort(int[] a, int n) {
int low = 0, high = 0, mid = 0;
// 待歸併陣列長度,1 2 4 8 ...
int len = 1; // 從最小分割單位 1 開始
while(len <= n) {
// 按分割單位遍歷陣列併合並
for (int i = 0; i + len <= n; i += len * 2) {
low = i;
// mid 變數主要是在合併時找到右半邊陣列的起始下標
mid = i + len - 1;
high = i + 2 * len - 1;
// 防止超過陣列長度
if (high > n - 1) {
high = n - 1;
}
// 歸併兩個有序的子陣列
merge(a, low, mid, high);
}
len *= 2; // 增加切分單位
}
}演算法分析:
- 平均時間複雜度,最佳和最差情況都是 O(nlgn)
- 空間複雜度 O(n),需要一個大小為 n 的臨時陣列
- 歸併排序也是一個穩定的排序演算法
6. 快速排序
快排可以說是應用最廣泛的演算法了,它的特點是使用很小的輔助棧原地排序。它也是一個分而治之的排序演算法,基本思想是:選取一個關鍵值,將陣列分成兩部分,一部分小於關鍵值,一部分大於關鍵值,然後遞迴的對左右兩部分排序。過程如下:
- 選取 a[low] 作為關鍵值-切分元素 p
- 使用兩個指標遍歷陣列(既可一前一後,也可同方向移動),將比 p 小的元素前移,最後交換切分元素
- 遞迴的對左右部分進行排序
遞迴實現快排核心程式碼:
public static void quickSort(int[] a, int low, int high) {
if (low < high) {
int m = partition(a, low, high); // 切分
quickSort(a, low, m-1); // 將左半部分排序
quickSort(a, m+1, high); // 將右半部分排序
}
}
public static int partition(int[] a, int low, int high) {
// 將陣列切分為 a[low..i-1], a[i], a[i+1..high]
int p = a[low]; // 切分元素
int i = low; // 下一個小於切分元素可插入的位置
// 從切分元素下一個位置開始,遍歷整個陣列,進行分割槽
for (int j = low + 1; j <= high; j++) {
// 往前移動比切分元素小的元素
if (a[j] < p && (i++ != j)) {
int tmp = a[j];
a[j] = a[i];
a[i] = tmp;
}
}
// 交換中樞(切分)元素
int tmp = a[low];
a[low] = a[i];
a[i] = tmp;
return i;
}演算法分析:
- 平均時間複雜度 O(nlgn),最佳情況 O(nlgn),最差情況是 O(n^2)
- 空間複雜度 O(lgn),因為遞迴,佔用呼叫棧空間
- 快排是一個不穩定的排序演算法
7. 堆排序
堆排序是利用堆這種資料結構設計的演算法。堆可看作一個完全二叉樹,它按層級在陣列中儲存,陣列下標為 k 的節點的父子節點位置分別如下:
- k 位置的父節點位置在 (k-1)/2 向下取整
- k 位置的左子節點位置在 2k+1
- k 位置的右子節點位置在 2k+2
堆的表示如下:
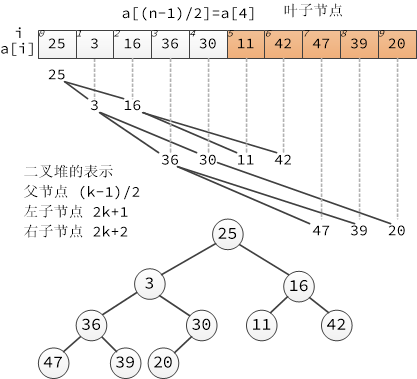
堆有序的定義是每個節點都大於等於它的兩個子節點,所以根節點是有序二叉堆中值最大的節點。堆排序就是一個不斷移除根節點,使用陣列剩餘元素重新構建堆的過程,和選擇排序有點類似(只不過按降序取元素),構建堆有序陣列基本步驟如下:
- 首先使用 (N-1)/2 之前的元素構建堆,完成後,整個堆最大元素位於陣列的 0 下標位置
- 把陣列首尾資料交換,此時陣列最大值以找到
- 把堆的尺寸縮小 1,重複步驟 1 和 2,直到堆的尺寸為 1
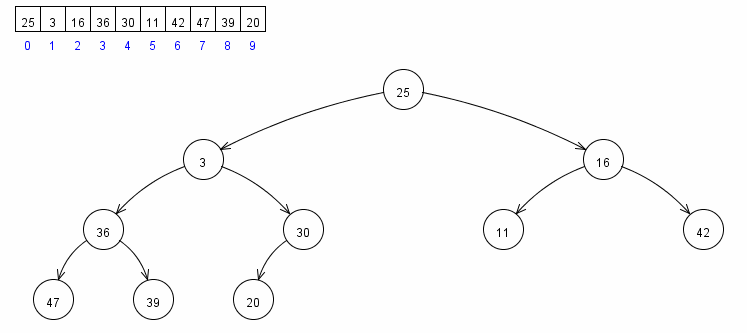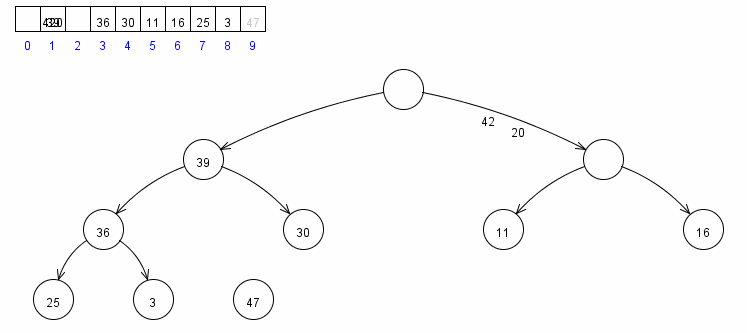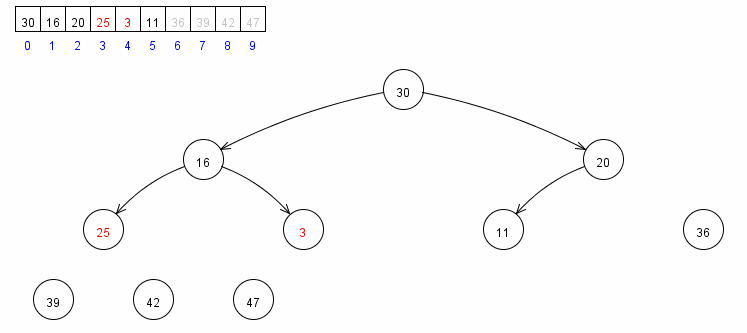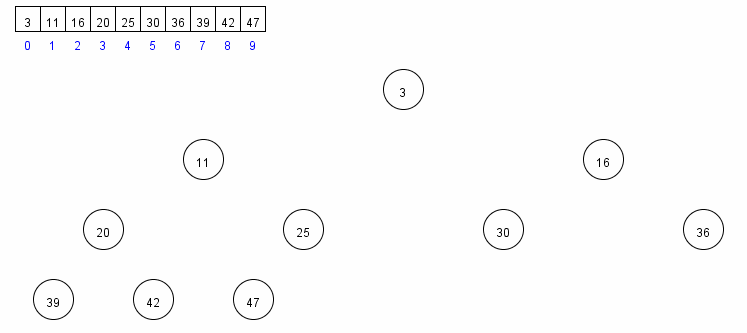
核心程式碼:
public static void heapSort(int[] a) {
int n = a.length - 1;
// 構建堆,一開始可將陣列看作無序的堆
// 將從下標為 n/2 開始到 0 的元素下沉到合適的位置
// 因為 n/2 後面的元素都是葉子結點,無需下沉
for (int k = n/2; k >= 0; k--)
sink(a, k, n);
// 下沉排序
// 堆的根結點永遠是最大值,所以只需將最大值和最後一位的元素交換即可
// 然後再維護一個除原最大結點以外的 n-1 的堆,再將新堆的根節點放在倒數第二的位置,如此反覆
while (n > 0) {
// 將 a[1] 與最大的元素 a[n] 交換,並修復堆
int tmp = a[0];
a[0] = a[n];
a[n] = tmp;
// 堆大小減1
n--;
// 下沉排序,重新構建
sink(a, 0, n);
}
}
/** 遞迴的構造大根堆 */
private static void sink(int[] a, int k, int n) {
// 是否存在左孩子節點
while ((2*k+1) <= n) {
// 左孩子下標
int left = 2*k+1;
// left < n 說明存在右孩子,判斷將根節點下沉到左還是右
// 如果左孩子小於右孩子,那麼下沉為右子樹的根,並且下次從右子樹開始判斷是否還要下沉
if (left < n && a[left] < a[left + 1])
left = left + 1;
// 如果根節點不小於它的子節點,表示這個子樹根節點最大
if (a[k] >= a[left])
break; // 不用下沉,跳出
// 否則將根節點下沉為它的左子樹或右子樹的根,也就是將較大的值上調
int tmp = a[k];
a[k] = a[left];
a[left] = tmp;
// 繼續從左子樹或右子樹開始,判斷根節點是否還要下沉
k = left;
}
}演算法分析:
- 平均時間複雜度、最佳和最壞均是 O(nlgn)
- 空間複雜度 O(1),原地排序
- 不穩定的排序演算法
8. 小結
每次看了,過段時間就忘,這次總結起來,方便檢視,也分享給大家,有問題歡迎交流。首發於公眾號「頓悟原始碼」,搜尋獲取更多原始碼分析和造的輪子