
Lambda plus: 雲上大資料解決方案
本文會簡述大資料分析場景需要解決的技術挑戰,討論目前主流大資料架構模式及其發展。最後我們將介紹如何結合雲上儲存、計算元件,實現更優的通用大資料架構模式,以及該模式可以涵蓋的典型資料處理場景。
大資料處理的挑戰
現在已經有越來越多的行業和技術領域需求大資料分析系統,例如金融行業需要使用大資料系統結合VaR(value at risk)或者機器學習方案進行信貸風控,零售、餐飲行業需要大資料系統實現輔助銷售決策,各種IOT場景需要大資料系統持續聚合和分析時序資料,各大科技公司需要建立大資料分析中臺等等。
抽象來看,支撐這些場景需求的分析系統,面臨的都是大致相同的技術挑戰:
- 業務分析的資料範圍橫跨實時資料和歷史資料,既需求低延遲的實時資料分析,也需求對PB級的歷史資料進行探索性的資料分析;
- 可靠性和可擴充套件性問題,使用者可能會儲存海量的歷史資料,同時資料規模有持續增長的趨勢,需要引入分散式儲存系統來滿足可靠性和可擴充套件性需求,同時保證成本可控;
- 技術棧深,需要組合流式元件、儲存系統、計算元件和;
- 可運維性要求高,複雜的大資料架構難以維護和管控;
簡述大資料架構發展
Lambda架構
Lambda架構是目前影響最深刻的大資料處理架構,它的核心思想是將不可變的資料以追加的方式並行寫到批和流處理系統內,隨後將相同的計算邏輯分別在流和批系統中實現,並且在查詢階段合併流和批的計算檢視並展示給使用者。Lambda的提出者Nathan Marz還假定了批處理相對簡單不易出現錯誤,而流處理相對不太可靠,因此流處理器可以使用近似演算法,快速產生對檢視的近似更新,而批處理系統會採用較慢的精確演算法,產生相同檢視的校正版本。
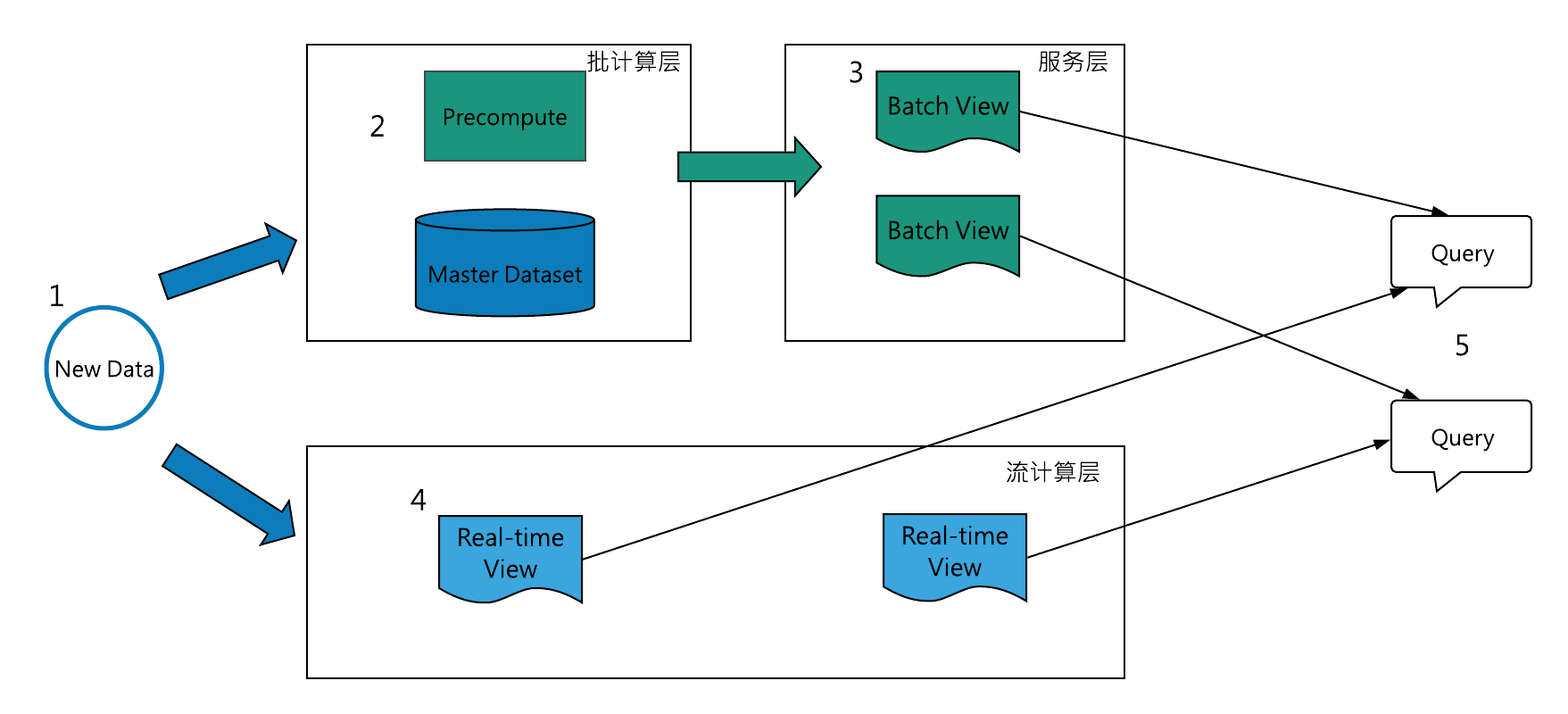
圖 1 Lambda架構示例
Lambda架構典型資料流程是(http://lambda-architecture.net/):
- 所有的資料需要分別寫入批處理層和流處理層;
- 批處理層兩個職責:(i)管理master dataset(儲存不可變、追加寫的全量資料), (ii)預計算batch view;
- 服務層對batch view建立索引,以支援低延遲、ad-hoc方式查詢view;
- 流計算層作為速度層,對實時資料計算近似的real-time view,作為高延遲batch view的補償快速檢視;
- 所有的查詢需要合併batch view和real-time view;
Lambda架構設計推廣了在不可變的事件流上生成檢視,並且可以在必要時重新處理事件的原則,該原則保證了系統隨需求演進時,始終可以建立相應的新檢視出來,切實可行的滿足了不斷變化的歷史資料和實時資料分析需求。
Lambda架構的四個挑戰
Lambda架構非常複雜,在資料寫入、儲存、對接計算元件以及展示層都有複雜的子課題需要優化:
- 寫入層上,Lambda沒有對資料寫入進行抽象,而是將雙寫流批系統的一致性問題反推給了寫入資料的上層應用;
- 儲存上,以HDFS為代表的master dataset不支援資料更新,持續更新的資料來源只能以定期拷貝全量snapshot到HDFS的方式保持資料更新,資料延遲和成本比較大;
- 計算邏輯需要分別在流批框架中實現和執行,而在類似Storm的流計算框架和Hadoop MR的批處理框架做job開發、除錯、問題調查都是比較複雜的;
- 結果檢視需要支援低延遲的查詢分析,通常還需要將資料派生到列存分析系統,並保證成本可控;
流批融合的Lambda架構
針對Lambda架構的問題3,計算邏輯需要分別在流批框架中實現和執行的問題,不少計算引擎已經開始往流批統一的方向去發展,例如Spark和Flink,從而簡化lambda架構中的計算部分。實現流批統一通常需要支援:1.以相同的處理引擎來處理實時事件和歷史回放事件;2.支援exactly once語義,保證有無故障情況下計算結果完全相同;3.支援以事件發生時間而不是處理時間進行視窗化;
Kappa架構
Kappa架構由Jay Kreps提出,不同於Lambda同時計算流計算和批計算併合並檢視,Kappa只會通過流計算一條的資料鏈路計算併產生檢視。Kappa同樣採用了重新處理事件的原則,對於歷史資料分析類的需求,Kappa要求資料的長期儲存能夠以有序log流的方式重新流入流計算引擎,重新產生歷史資料的檢視。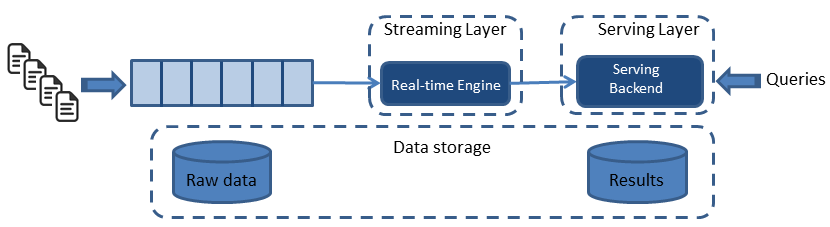
圖2 Kappa大資料架構
Kappa方案通過精簡鏈路解決了1資料寫入和3計算邏輯複雜的問題,但它依然沒有解決儲存和展示的問題,特別是在儲存上,使用類似kafka的訊息佇列儲存長期日誌資料,資料無法壓縮,儲存成本很大,繞過方案是使用支援資料分層儲存的訊息系統(如Pulsar,支援將歷史訊息儲存到雲上儲存系統),但是分層儲存的歷史日誌資料僅能用於Kappa backfill作業,資料的利用率依然很低。
Lambda和Kappa的場景區別:
- Kappa不是Lambda的替代架構,而是其簡化版本,Kappa放棄了對批處理的支援,更擅長業務本身為append-only資料寫入場景的分析需求,例如各種時序資料場景,天然存在時間視窗的概念,流式計算直接滿足其實時計算和歷史補償任務需求;
- Lambda直接支援批處理,因此更適合對歷史資料有很多ad hoc查詢的需求的場景,比如資料分析師需要按任意條件組合對歷史資料進行探索性的分析,並且有一定的實時性需求,期望儘快得到分析結果,批處理可以更直接高效地滿足這些需求;
Kappa+
Kappa+是Uber提出流式資料處理架構,它的核心思想是讓流計算框架直讀HDFS類的數倉資料,一併實現實時計算和歷史資料backfill計算,不需要為backfill作業長期儲存日誌或者把資料拷貝回訊息佇列。Kappa+將資料任務分為無狀態任務和時間視窗任務,無狀態任務比較簡單,根據吞吐速度合理併發掃描全量資料即可,時間視窗任務的原理是將數倉資料按照時間粒度進行分割槽儲存,視窗任務按時間序一次計算一個partition的資料,partition內亂序併發,所有分割槽檔案全部讀取完畢後,所有source才進入下個partition消費並更新watermark。事實上,Uber開發了Apache hudi框架來儲存數倉資料,hudi支援更新、刪除已有parquet資料,也支援增量消費資料更新部分,從而系統性解決了問題2儲存的問題。下圖3是完整的Uber大資料處理平臺,其中Hadoop -> Spark -> Analytical data user涵蓋了Kappa+資料處理架構。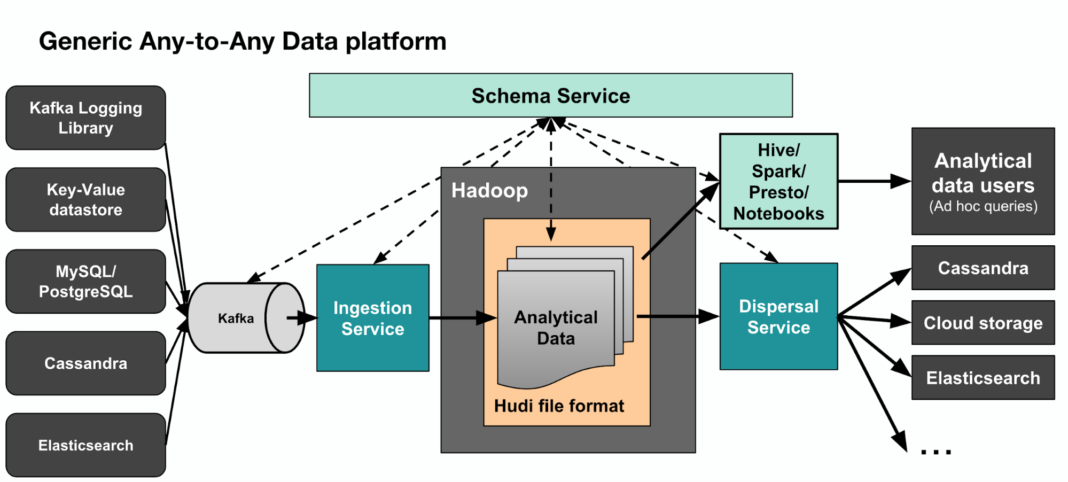
圖3 Uber圍繞Hadoop dataset的大資料架構
混合分析系統的Kappa架構
Lambda和Kappa架構都還有展示層的困難點,結果檢視如何支援ad-hoc查詢分析,一個解決方案是在Kappa基礎上衍生資料分析流程,如下圖4,在基於使用Kafka + Flink構建Kappa流計算資料架構,針對Kappa架構分析能力不足的問題,再利用Kafka對接組合ElasticSearch實時分析引擎,部分彌補其資料分析能力。但是ElasticSearch也只適合對合理資料量級的熱資料進行索引,無法覆蓋所有批處理相關的分析需求,這種混合架構某種意義上屬於Kappa和Lambda間的折中方案。
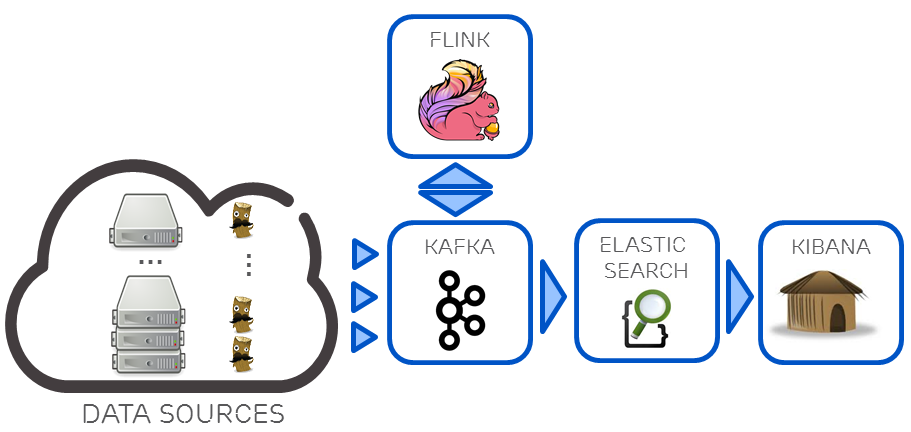
圖4 Kafka + Flink + ElasticSearch的混合分析系統
Lambda plus:Tablestore + Blink流批一體處理框架
Lambda plus是基於Tablestore和Blink打造的雲上存在可以複用、簡化的大資料架構模式,架構方案全serverless即開即用,易搭建免運維。
表格儲存(Tablestore)是阿里雲自研的NoSQL多模型資料庫,提供PB級結構化資料儲存、千萬TPS以及毫秒級延遲的服務能力,表格儲存提供了通道服務(TunnelService)支援使用者以按序、流式地方式消費寫入表格儲存的存量資料和實時資料,同時表格儲存還提供了多元索引功能,支援使用者對結果檢視進行實時查詢和分析。
Blink是阿里雲在Apache Flink基礎上深度改進的實時計算平臺,Blink旨在將流處理和批處理統一,實現了全新的 Flink SQL 技術棧,在功能上,Blink支援現在標準 SQL 幾乎所有的語法和語義,在效能上,Blink也比社群Flink更加強大。
在TableStore + blink的雲上Lambda架構中,使用者可以同時使用表格儲存作為master dataset和batch&stream view,批處理引擎直讀表格儲存產生batch view,同時流計算引擎通過Tunnel Service流式處理實時資料,持續生成stream view。
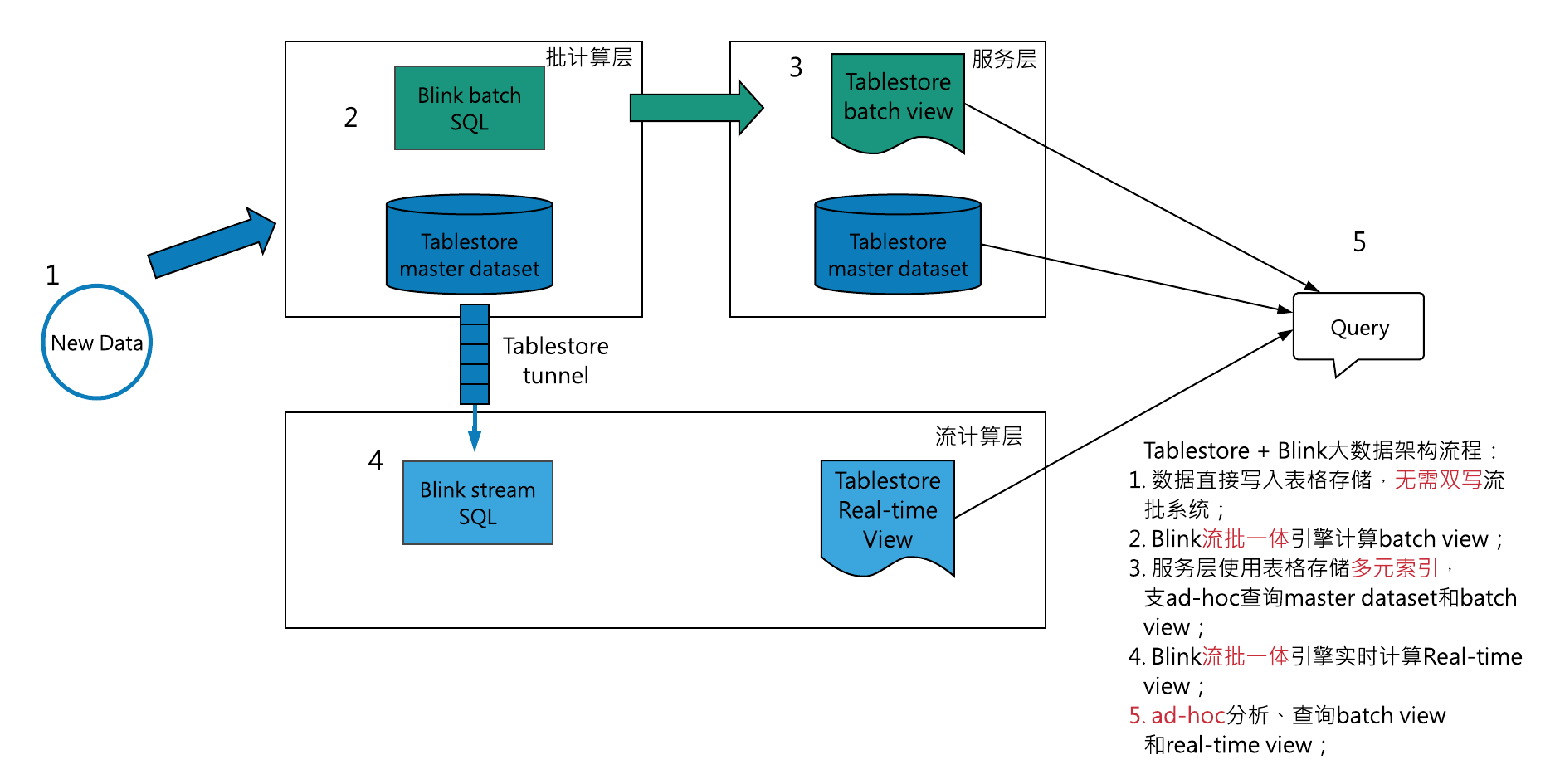
圖5 Tablestore + Blink的Lambda plus大資料架構
如上圖5,其具體元件分解:
-
Lambda batch層:
- Tablestore直接作為master dataset,支援使用者直讀,配合Tablestore多元索引,使用者的線上服務直讀、ad-hoc查詢master dataset並將結果返回給使用者;
- blink批處理任務向Tablestore下推SQL的查詢條件,直讀Tablestore master dataset,計算batch view,並將batch view重新寫回Tablestore;
-
Streaming層:
- blink流處理任務通過表格儲存TunnelService API直讀master dataset中的實時資料,持續產生stream view;
- Kappa架構的backfill任務,可以通過建立全量型別資料通道,流式消費master dataset的存量資料,從新計算;
-
Serving層:
- 為儲存batch view和stream view的Tablestore結果表建立全域性二級索引和多元索引,業務可以低延遲、ad-hoc方式查詢;
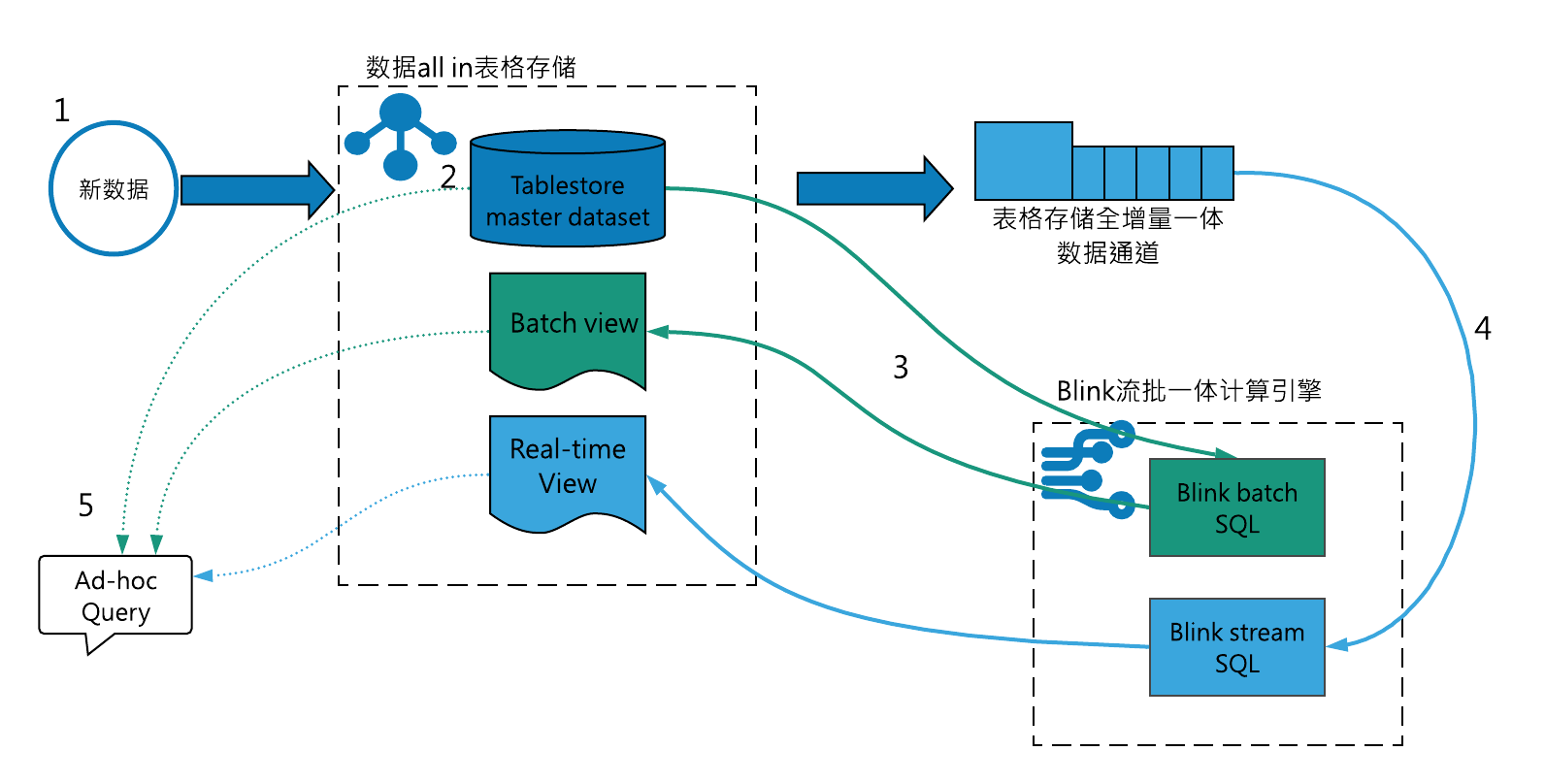
圖6 Lambda plus的資料鏈路
針對上述Lambda架構1-4的技術問題,Lambda plus的解決思路:
- 針對資料寫入的問題,Lambda plus資料只需要寫入表格儲存,Blink流計算框架通過通道服務API直讀表格儲存的實時資料,不需要使用者雙寫佇列或者自己實現資料同步;
- 儲存上,Lambda plus直接使用表格儲存作為master dataset,表格儲存支援使用者tp系統低延遲讀寫更新,同時也提供了索引功能ad-hoc查詢分析,資料利用率高,容量型表格儲存例項也可以保證資料儲存成本可控;
- 計算上,Lambda plus利用blink流批一體計算引擎,統一流批程式碼;
- 展示層,表格儲存提供了多元索引和全域性二級索引功能,使用者可以根據解決檢視的查詢需求和儲存體量,合理選擇索引方式;
總結,表格儲存實現了batch view、master dataset直接查詢、stream view的功能全集,Blink實現流批統一,Tablestore加blink的Lambda plus模式可以明顯簡化Lambda架構的元件數量,降低搭建和運維難度,拓展使用者資料價值。
表格儲存是如何實現支援上述功能全集的
-
儲存引擎的高併發、低延遲特性:
- 表格儲存面向線上業務提供高併發、低延遲的訪問,並且tps按分割槽水平擴充套件,可以有效支援批處理和Kappa backfill的高吞吐資料掃描和流計算按分割槽粒度併發實時處理;
-
使用通道服務精簡架構:
- Tablestore資料通道支援使用者以按序、流式地方式消費寫入表格儲存的存量資料和實時資料,避免Lambda架構引入訊息佇列系統以及master dataset和佇列的資料一致性問題;
-
- 儲存在表格儲存的batch view和real-time view可以使用多元索引和二級索引實現ad-hoc查詢,使用多元索引進行聚合分析計算;
- 同時展示層也可以利用二級索引和多元索引直接查詢表格儲存master dataset,不強依賴引擎計算結果;
Lambda plus的適用場景
基於Tablestore和Blink的Lambda plus架構,適用於基於分散式NoSQL資料庫儲存資料的大資料分析場景,如IOT、時序資料、爬蟲資料、使用者行為日誌資料儲存等,資料量以TB級為主。典型的業務場景如:
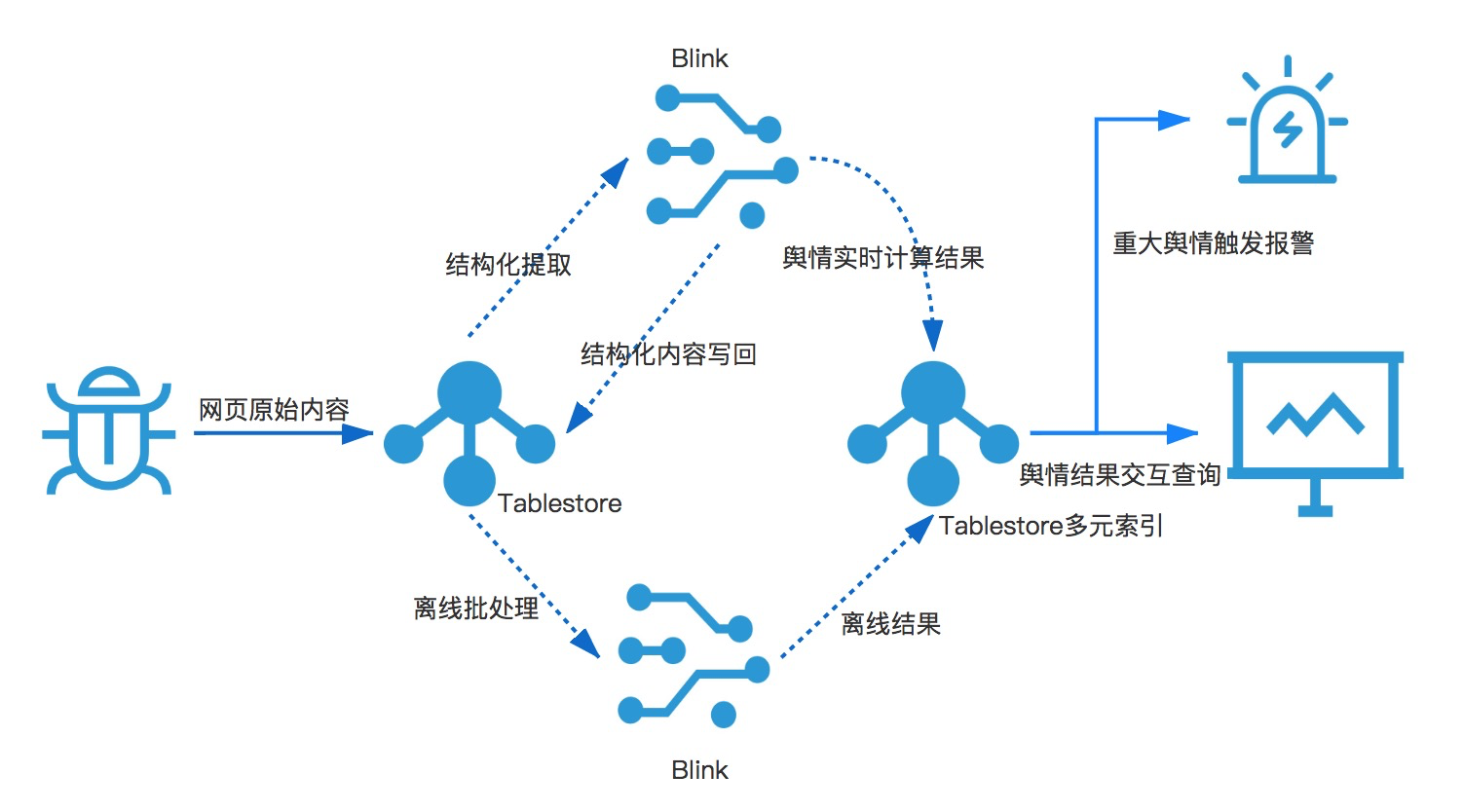
- 大資料輿情分析系統
拓展閱讀
可以參考下列資源快速體驗表格儲存+blink的大資料架構、表格儲存多元索引及其相關場景:
本文作者:Dendi
本文為雲棲社群原創內容,未經