
[案例]如何異構一個數十億級別的資料庫
阿新 • • 發佈:2019-06-06
本文記錄工作中一次異構數十億級別資料庫的過程,資料來源為mysql,目標介質為elasticsearch。
1、 我們能利用的資源
1.1 源資料模型
源庫是別人(庫存)的資料,分為A,B,C三種類型的庫存模型,需要將三種類型的模型整合成一中通用庫存模型方便我方(商家)做業務。
典型的網際網路企業是協作方式,通過資料副本實現業務之間的解耦。
1.2 特殊表(非重點)
D為庫存佔用訂單詳情,也要異構一份。
1.3 分庫分表
ABCD均做了分庫分表,A(16個庫,4096張表),B(1,512),C(1,256),D(8,1024)
1.4 資料量
資料總量在數十億級別
1.5 線上影響
不影響對方業務,資料來源只有對方mysql分組中對應的抽數從庫。
mysql分組解釋
1.6 效能要求
未來要支援複雜的條件查詢,對查效能有很高要求,目標介質是ES。
2、 難點
2.1 導數
交易庫存複雜的分片規則,資料量大,導數是個大工程。
2.2 更新頻繁
寫操作頻繁,ES 建立索引的tps能否滿足要求。
2.3 一致性如何保證
通過mq 實現 base最終一致性。
3、 最終方案
3.1 系統整體架構
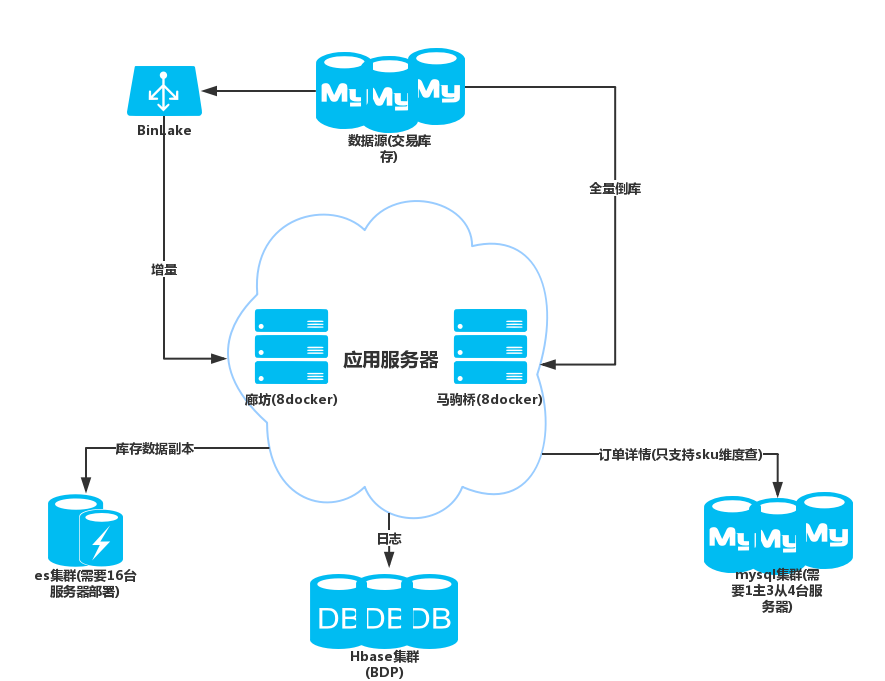
首先增量資料採用canal做收集(圖中binLake同叢集化canal),ABC庫全部存入es,D庫存入mysql。
3.2 如何做全量倒庫
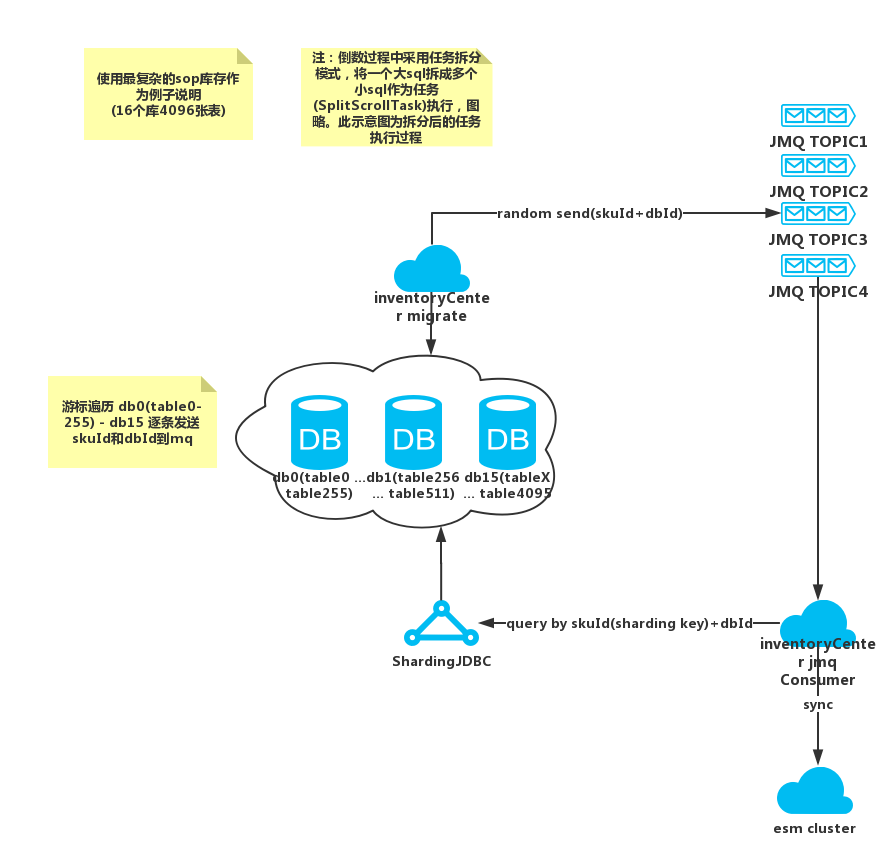
sop對應的型別A,使用多個topic分散訊息中介軟體壓力,同時解決中介軟體同一topic的連線數限制。
3.3 如何提高es寫效能(bulk)
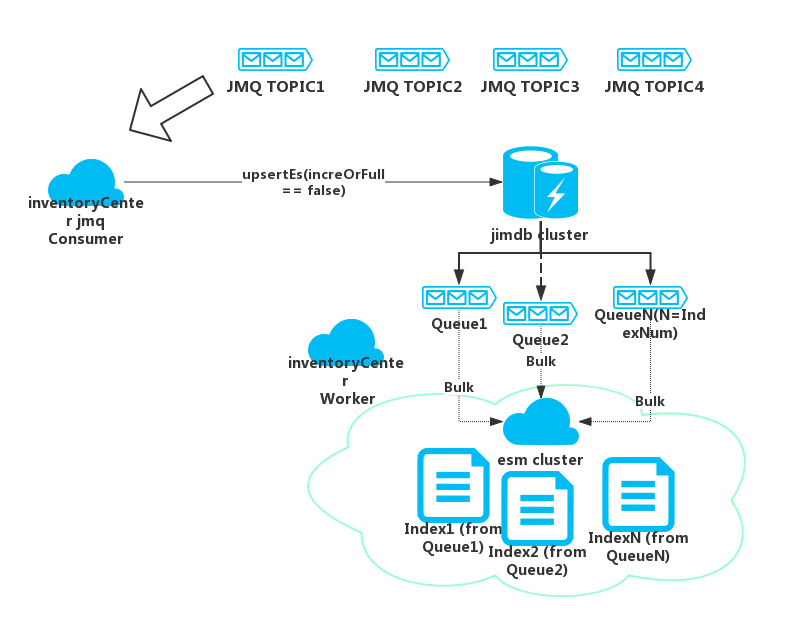
通過jmq非同步建立es索引,通過redis佇列實現bulk模式提交對應用的透