
基於Custom-metrics-apiserver實現Kubernetes的HPA(內含踩坑)
前言
這裡要說一下Prometheus的檢控指標從哪裡來,它有3個渠道:
主機監控,也就是部署了Node Exporter元件的主機,它以DaemonSet或者系統程序的形式執行,Prometheus會從這裡獲取關於宿主機相關的資源指標
從Kubernetes自身元件,比如API Server或者Kubelet的/metrics,可以獲取工作佇列長度、請求QPS以及kubelet暴露出來的關於POD和容器的相關指標,其中容器的是通過Kubelet內建的cAdvisor服務暴露的,它是監控容器內部的。
通過外掛獲取的,也就是Heapster的替代者Metrics Server,這個用來獲取Pod和Node資源使用情況,它主要是用來供HPA使用。它的資料並不是來自於Prometheus,不過Prometheus可以獲取。
今天我們說的自定義API其實就是和Metrics Server的實現方式一樣,都是通過註冊API的形式來完成和Kubernetes的整合的,也就是在API Server增加原本沒有的API。不過新增API還可以通過CRD的方式完成,不過我們這裡直說聚合方式。看下圖:
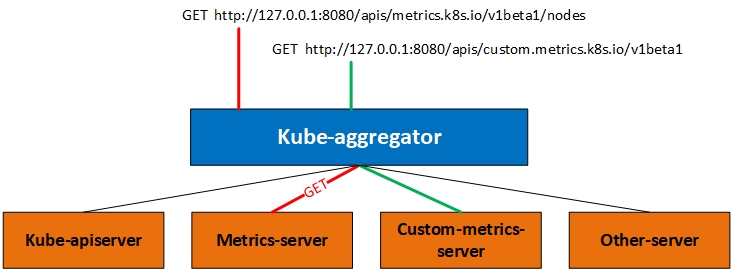
實際上我們訪問API的時候訪問的是一個aggregator的代理層,下面綠色的都是可用的後端。我們訪問上圖中的2個URL其實是被代理到不同的後端,在這個機制下你可以新增更多的後端,而我們今天要說的Custome-metrics-apiserver就是綠色線條的路徑。如果你部署Metrics-server的話對於理解今天的內容也不會很難。
通過聚合器實現自定義API需要的步驟
首先在API Server中啟用API聚合功能,在kube-apiserver啟動引數中加入如下內容,其中證書名稱換成你自己環境中的:
# CA根證書 --requestheader-client-ca-file= --requestheader-extra-headers-prefix=X-Remote-Extra- --requestheader-group-headers=X-Remote-Group --requestheader-username-headers=X-Remote-User # 在請求期間驗證aggregator的客戶端CA證書,我這裡就是CA根證書 --proxy-client-cert-file= # 私鑰,我這裡配置的就是CA根證書私鑰 --proxy-client-key-file=
另外在kube-controller-manager元件上也有一些引數可以配置,但是不是必須的:
# HPT控制器同步Pod副本數量的時間間隔,預設15秒
--horizontal-pod-autoscaler-sync-period=15s
# 執行縮容的等待時間,預設5分鐘
--horizontal-pod-autoscaler-downscale-stabilization=5m0s
# 等待Pod到達Reday狀態的延時,預設30秒
--horizontal-pod-autoscaler-initial-readiness-delay=30s其次定義api,然後向API Server進行註冊
最後部署提供服務的應用。
演示
本次演示使用的配置清單檔案請提前下載。下面對每個檔案做一下簡要說明。
custom-metrics-apiserver-auth-delegator-cluster-role-binding:
custom-metrics-apiserver-auth-reader-role-binding:
custom-metrics-apiserver-deployment:自定義指標提供者的容器
custom-metrics-apiserver-resource-reader-cluster-role-binding:
custom-metrics-apiserver-service:為deployment建立的service
custom-metrics-apiserver-service-account:建立服務賬號
custom-metrics-apiservice:需要註冊的apiserver名稱以及關聯的service
custom-metrics-cluster-role:
custom-metrics-config-map:配置檔案
custom-metrics-resource-reader-cluster-role:
hpa-custom-metrics-cluster-role-binding:
上面的檔案看起來比較多,我們合併一下,便於演示。
custom-metrics-apiserver-auth-delegator-cluster-role-binding、custom-metrics-apiserver-auth-reader-role-binding、custom-metrics-apiserver-resource-reader-cluster-role-binding、custom-metrics-apiserver-service-account、custom-metrics-cluster-role、custom-metrics-resource-reader-cluster-role、hpa-custom-metrics-cluster-role-binding,這幾個合併到一個檔案中,主要是服務賬號和授權類的。其他保持單獨的。合併檔案custom-metrics-apiserver-rabc.yaml內容如下:
# 建立名稱空間
kind: Namespace
apiVersion: v1
metadata:
name: custom-metrics
---
# 建立服務賬號
kind: ServiceAccount
apiVersion: v1
metadata:
name: custom-metrics-apiserver
namespace: custom-metrics
---
# 把系統角色system:auth-delegator繫結到服務賬號,使該服務賬號可以將認證請求轉發到自定義的API上
apiVersion: rbac.authorization.k8s.io/v1beta1
kind: ClusterRoleBinding
metadata:
name: custom-metrics:system:auth-delegator
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: system:auth-delegator
subjects:
- kind: ServiceAccount
name: custom-metrics-apiserver
namespace: custom-metrics
---
# 建立叢集角色custom-metrics-resource-reader
apiVersion: rbac.authorization.k8s.io/v1beta1
kind: ClusterRole
metadata:
name: custom-metrics-resource-reader
rules:
- apiGroups:
- ""
resources:
- namespaces
- pods
- services
verbs:
- get
- list
---
# 把叢集角色custom-metrics-resource-reader繫結到服務賬號
apiVersion: rbac.authorization.k8s.io/v1beta1
kind: ClusterRoleBinding
metadata:
name: custom-metrics-resource-reader
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: custom-metrics-resource-reader
subjects:
- kind: ServiceAccount
name: custom-metrics-apiserver
namespace: custom-metrics
---
# 把系統自帶的角色extension-apiserver-authentication-reader繫結到服務賬號,允許服務賬號可以訪問系統的ConfigMap extension-apiserver-authentication
apiVersion: rbac.authorization.k8s.io/v1beta1
kind: RoleBinding
metadata:
name: custom-metrics-auth-reader
namespace: kube-system
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: Role
name: extension-apiserver-authentication-reader
subjects:
- kind: ServiceAccount
name: custom-metrics-apiserver
namespace: custom-metrics
---
# 建立叢集角色custom-metrics-server-resources
apiVersion: rbac.authorization.k8s.io/v1beta1
kind: ClusterRole
metadata:
name: custom-metrics-server-resources
rules:
- apiGroups:
- custom.metrics.k8s.io
resources: ["*"]
verbs: ["*"]
---
# 把叢集角色custom-metrics-server-resources繫結到系統自帶的服務賬號horizontal-pod-autoscaler
apiVersion: rbac.authorization.k8s.io/v1beta1
kind: ClusterRoleBinding
metadata:
name: hpa-controller-custom-metrics
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: custom-metrics-server-resources
subjects:
- kind: ServiceAccount
name: horizontal-pod-autoscaler
namespace: kube-system原始檔中使用的monitoring這個Namespace,但是它沒有建立Namespace的內容,所以上面檔案第一部分我自己增加了一個,然後我使用的Namespace是custom-metrics,並把原始檔中的做了修改。
應用custom-metrics-apiserver-rabc.yaml檔案
建立證書檔案和Secret
#!/bin/bash
TEMP_WORK_DIR="/tmp/work"
cd ${TEMP_WORK_DIR}
cat << EOF > custom-metrics-apiserver-csr.json
{
"CN": "custom-metrics-apiserver",
"hosts": [
"custom-metrics-apiserver.custom-metrics.svc"
],
"key": {
"algo": "rsa",
"size": 2048
},
"names": [
{
"C": "CN",
"L": "Beijing",
"ST": "Beijing"
}
]
}
EOF
# 會產生 custom-metrics-apiserver.pem custom-metrics-apiserver-key.pem
cfssl gencert -ca=ca.pem -ca-key=ca-key.pem -config=ca-config.json -profile=kubernetes custom-metrics-apiserver-csr.json | cfssljson -bare custom-metrics-apiserver
# 建立secret
kubectl create secret generic cm-adapter-serving-certs --from-file=serving.crt=./custom-metrics-apiserver.pem --from-file=serving.key=./custom-metrics-apiserver-key.pem -n custom-metricsca-config.json檔案內容
{
"signing": {
"default": {
"expiry": "87600h"
},
"profiles": {
"kubernetes": {
"expiry": "87600h",
"usages": [
"signing",
"key encipherment",
"server auth",
"client auth"
]
},
"etcd": {
"expiry": "87600h",
"usages": [
"signing",
"key encipherment",
"server auth",
"client auth"
]
},
"client": {
"expiry": "87600h",
"usages": [
"signing",
"key encipherment",
"client auth"
]
}
}
}
}前提是你安裝好了cfssl工具、配置好了kubectl環境變數以及在當前工作目錄具有ca-config.json檔案,這個檔案不一定是這個名字。這個檔案是我之前部署k8s叢集時候使用的,所以現在繼續使用,它用於配置證書的通用屬性資訊。

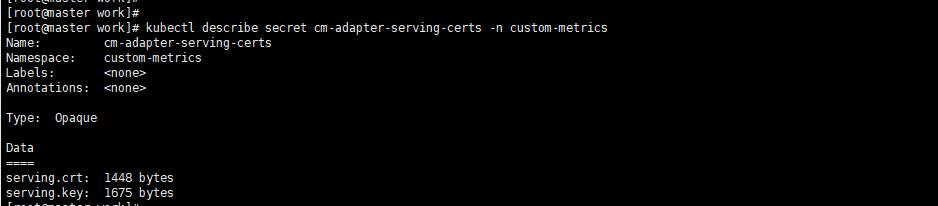
上圖看到的TYPE是Opaque型別,因為Secret有4中型別Opaque是base64編碼的Secret,用於儲存密碼和祕鑰等加密比較弱。kubernetes.io/dockerconfigjson是用來儲存私有docker倉庫的認證資訊。kubernetes.io/service-account-token是用來被service account使用的,是K8S用於驗證service account的有效性的token。還有一種是tls專門用於加密證書檔案的。
註冊api檔案
該檔案的主要作用就是向Api server註冊一個api,此API名稱是關聯到一個service名稱上。
# 這個是向K8S apiserver註冊自己的api以及版本
apiVersion: apiregistration.k8s.io/v1beta1
kind: APIService
metadata:
name: v1beta1.custom.metrics.k8s.io
spec:
# 該API所關聯的service名稱,也就是訪問這個自定義API後,被轉發到哪個service來處理,custom-metrics-apiserver-service這裡定義的
service:
name: custom-metrics-apiserver
namespace: custom-metrics
# api所屬的組名稱
group: custom.metrics.k8s.io
# api版本
version: v1beta1
insecureSkipTLSVerify: true
groupPriorityMinimum: 100
versionPriority: 100從下圖可以看到這個api以及註冊上了。

這個註冊的api的其實就是hpa去api server訪問這個註冊的api,這個註冊的api其實起到的是代理作用,把請求代理到某一個service上,這個service的endpoint其實就是提供檢控資料的一個應用,也就是下面的介面卡,介面卡的作用就是從prometheus中查詢資料然後重新組裝成k8s可以識別的資料格式。
部署介面卡
這裡我們應用剩餘的三個配置清單。這裡我們主要說一下deployment檔案。
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: custom-metrics-apiserver
name: custom-metrics-apiserver
namespace: custom-metrics
spec:
replicas: 1
selector:
matchLabels:
app: custom-metrics-apiserver
template:
metadata:
labels:
app: custom-metrics-apiserver
name: custom-metrics-apiserver
spec:
serviceAccountName: custom-metrics-apiserver
containers:
- name: custom-metrics-apiserver
image: quay.io/coreos/k8s-prometheus-adapter-amd64:v0.4.1
args:
- /adapter
- --secure-port=6443
# 這裡是custom-metrics-apiserver連線k8s apiserver使用的證書和私鑰,這個證書你可以自己生成,主要注意CN和hosts欄位。另外使用k8s的CA根證書來簽發
# CN可以寫service名稱,hosts寫service的DNS名稱,鑑於IP會變所以不建議寫IP地址,然後使用sfssl來生成證書,最後建立secret。
# 該檔案下面secretName中的名稱。
- --tls-cert-file=/var/run/serving-cert/serving.crt
- --tls-private-key-file=/var/run/serving-cert/serving.key
- --logtostderr=true
# 這個是連線prometheus的地址,它這裡寫的是prometheus service的域名
- --prometheus-url=http://prometheus.kube-system.svc:9090/
- --metrics-relist-interval=30s
- --v=10
- --config=/etc/adapter/config.yaml
ports:
- containerPort: 6443
volumeMounts:
- mountPath: /var/run/serving-cert
name: volume-serving-cert
readOnly: true
- mountPath: /etc/adapter/
name: config
readOnly: true
volumes:
- name: volume-serving-cert
secret:
secretName: cm-adapter-serving-certs
- name: config
configMap:
name: adapter-config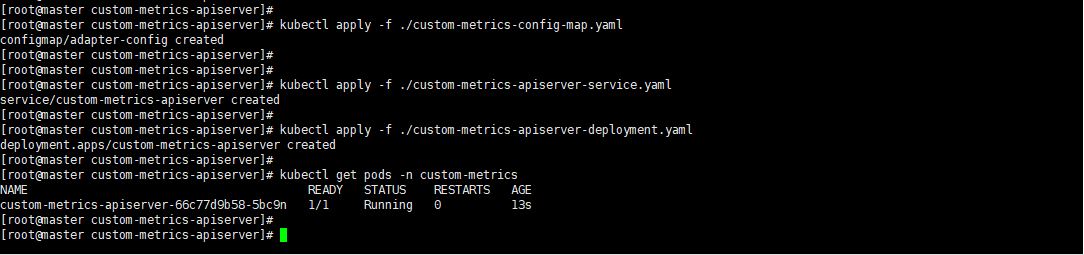
首先進入這個POD看看證書有沒有掛載上來

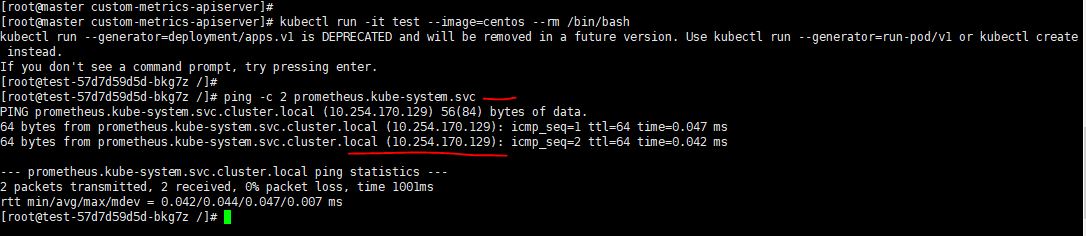
啟動一個容器測試一下看看是否可以ping通prometheus的域名,通過下面的命令啟動一個容器--rm是退出容器就刪除該容器。kubectl run -it test --image=centos --rm /bin/bash ,如下圖:
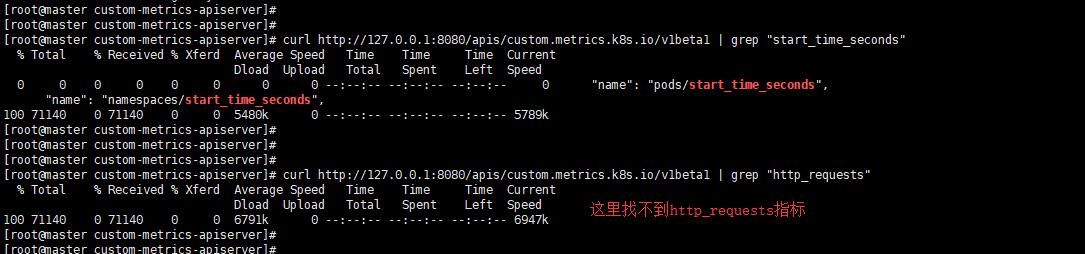
通過下面這個命令來檢視自定義的api提供了哪些metrics,curl http://127.0.0.1:8080/apis/custom.metrics.k8s.io/v1beta1
按照網上的測試方法會得到這樣的錯誤提示"message": "the server could not find the metric http_requests for pods",如下圖:
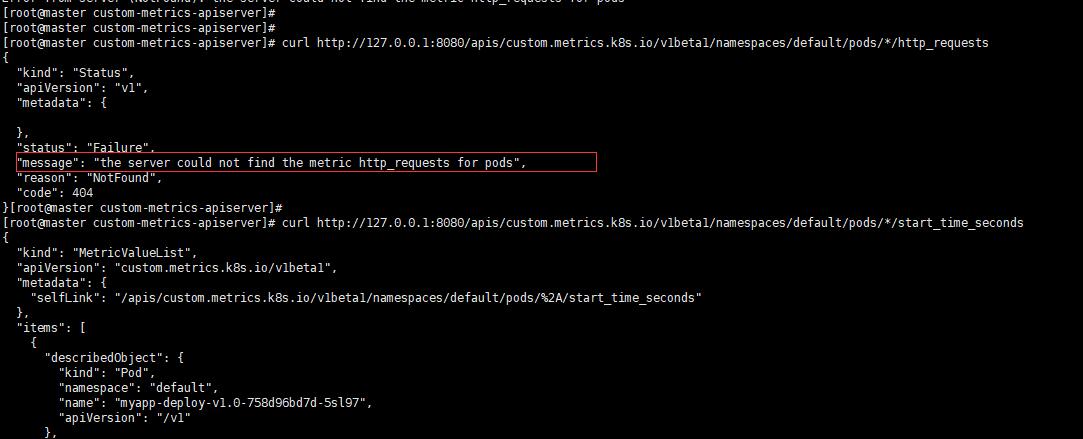
如果這裡的指標找不到,那你將無法通過這個指標來實現HPA,這是怎麼回事呢?這個就跟你部署的那個deployment的具體映象k8s-prometheus-adapter-amd64它使用的配置檔案有關,也就是custom-metrics-config-map.yaml裡面定義的rules,檔案中所有的seriesQuery項在prometheus中查詢後的結果都沒有http_request_totals指標,所以也就肯定找不到。
這裡的原理就是adapter通過使用prometheus的查詢語句來獲取指標然後做一下修改最終把重新組裝的指標和值通過自己的介面暴露,然後由自定義api代理到adapter的service上來獲取這些指標。
既然樣例中的規則缺少了,那麼我們就自己拼湊一個(需要首先保障你的prometheus中可以搜尋到http_requests_total這個指標),內容如下:
- seriesQuery: '{__name__=~"^http_requests_.*",kubernetes_pod_name!="",kubernetes_namespace!=""}'
seriesFilters: []
resources:
overrides:
kubernetes_namespace:
resource: namespace
kubernetes_pod_name:
resource: pod
name:
matches: ^(.*)_(total)$
as: "${1}"
metricsQuery: sum(rate(<<.Series>>{<<.LabelMatchers>>}[1m])) by (<<.GroupBy>>)最終的custom-metrics-config-map.yaml就是下面這個
apiVersion: v1
kind: ConfigMap
metadata:
name: adapter-config
namespace: custom-metrics
data:
config.yaml: |
rules:
- seriesQuery: '{__name__=~"^container_.*",container_name!="POD",namespace!="",pod_name!=""}'
seriesFilters: []
resources:
overrides:
namespace:
resource: namespace
pod_name:
resource: pod
name:
matches: ^container_(.*)_seconds_total$
as: ""
metricsQuery: sum(rate(<<.Series>>{<<.LabelMatchers>>,container_name!="POD"}[1m])) by (<<.GroupBy>>)
- seriesQuery: '{__name__=~"^container_.*",container_name!="POD",namespace!="",pod_name!=""}'
seriesFilters:
- isNot: ^container_.*_seconds_total$
resources:
overrides:
namespace:
resource: namespace
pod_name:
resource: pod
name:
matches: ^container_(.*)_total$
as: ""
metricsQuery: sum(rate(<<.Series>>{<<.LabelMatchers>>,container_name!="POD"}[1m])) by (<<.GroupBy>>)
- seriesQuery: '{__name__=~"^container_.*",container_name!="POD",namespace!="",pod_name!=""}'
seriesFilters:
- isNot: ^container_.*_total$
resources:
overrides:
namespace:
resource: namespace
pod_name:
resource: pod
name:
matches: ^container_(.*)$
as: ""
metricsQuery: sum(<<.Series>>{<<.LabelMatchers>>,container_name!="POD"}) by (<<.GroupBy>>)
- seriesQuery: '{namespace!="",__name__!~"^container_.*"}'
seriesFilters:
- isNot: .*_total$
resources:
template: <<.Resource>>
name:
matches: ""
as: ""
metricsQuery: sum(<<.Series>>{<<.LabelMatchers>>}) by (<<.GroupBy>>)
- seriesQuery: '{namespace!="",__name__!~"^container_.*"}'
seriesFilters:
- isNot: .*_seconds_total
resources:
template: <<.Resource>>
name:
matches: ^(.*)_total$
as: ""
metricsQuery: sum(rate(<<.Series>>{<<.LabelMatchers>>}[1m])) by (<<.GroupBy>>)
- seriesQuery: '{__name__=~"^http_requests_.*",kubernetes_pod_name!="",kubernetes_namespace!=""}'
seriesFilters: []
resources:
overrides:
kubernetes_namespace:
resource: namespace
kubernetes_pod_name:
resource: pod
name:
matches: ^(.*)_(total)$
as: "${1}"
metricsQuery: sum(rate(<<.Series>>{<<.LabelMatchers>>}[1m])) by (<<.GroupBy>>)
- seriesQuery: '{namespace!="",__name__!~"^container_.*"}'
seriesFilters: []
resources:
template: <<.Resource>>
name:
matches: ^(.*)_seconds_total$
as: ""
metricsQuery: sum(rate(<<.Series>>{<<.LabelMatchers>>}[1m])) by (<<.GroupBy>>)
resourceRules:
cpu:
containerQuery: sum(rate(container_cpu_usage_seconds_total{<<.LabelMatchers>>}[1m])) by (<<.GroupBy>>)
nodeQuery: sum(rate(container_cpu_usage_seconds_total{<<.LabelMatchers>>, id='/'}[1m])) by (<<.GroupBy>>)
resources:
overrides:
instance:
resource: node
namespace:
resource: namespace
pod_name:
resource: pod
containerLabel: container_name
memory:
containerQuery: sum(container_memory_working_set_bytes{<<.LabelMatchers>>}) by (<<.GroupBy>>)
nodeQuery: sum(container_memory_working_set_bytes{<<.LabelMatchers>>,id='/'}) by (<<.GroupBy>>)
resources:
overrides:
instance:
resource: node
namespace:
resource: namespace
pod_name:
resource: pod
containerLabel: container_name
window: 1m刪除之前的config然後重新建立adapter再進行測試。

下面測試一下看看,發現已經有了。
curl http://127.0.0.1:8080/apis/custom.metrics.k8s.io/v1beta1/namespaces/default/pods/*/http_requests
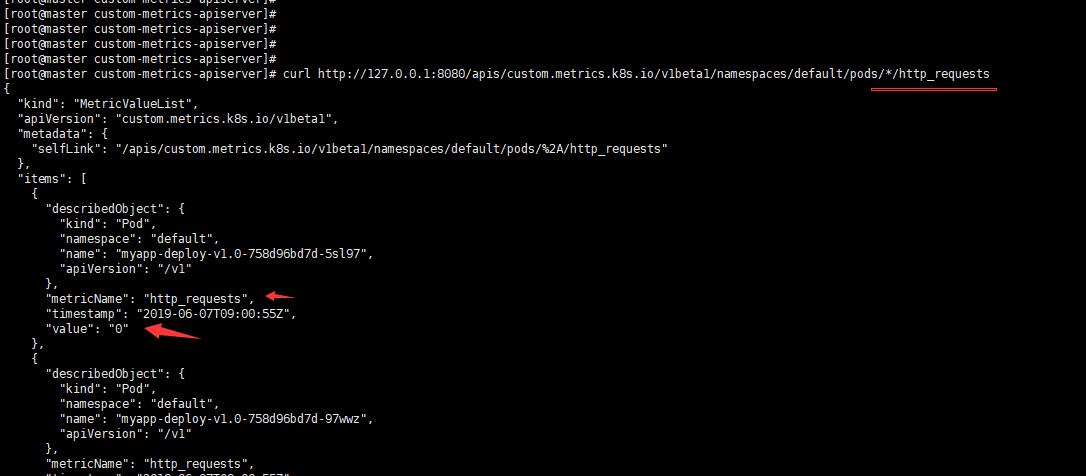
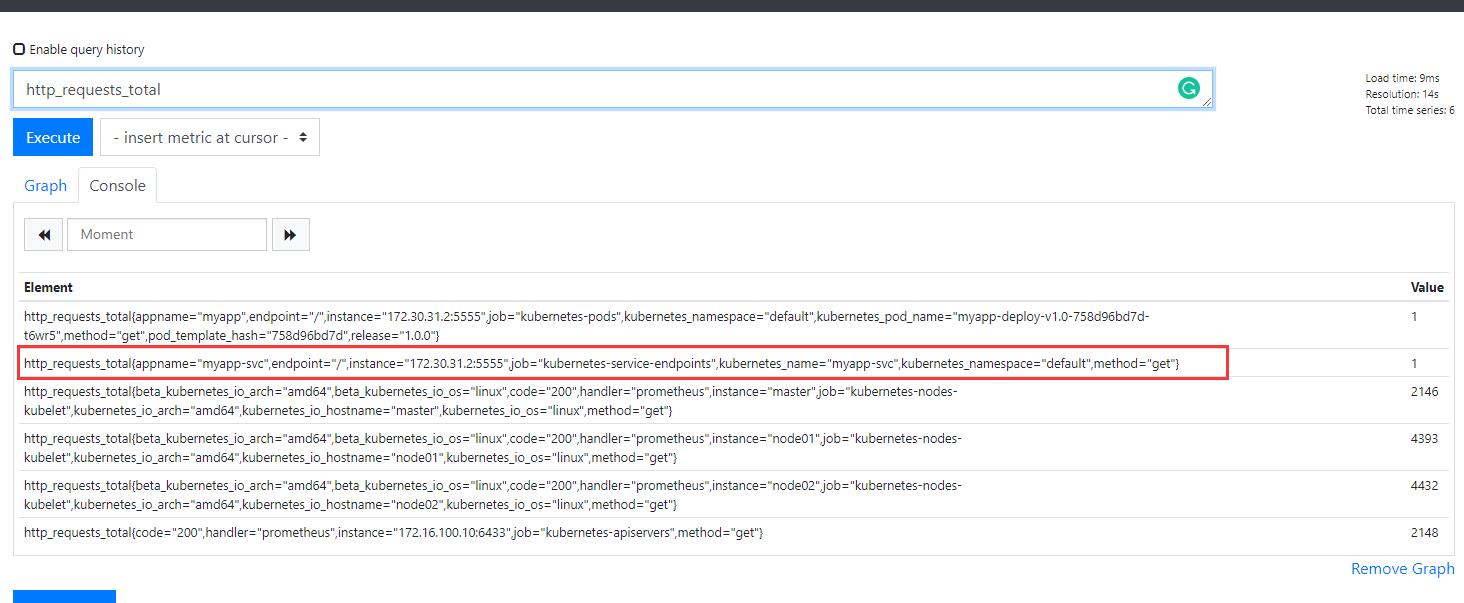
當你訪問這個註冊的URL時候會被代理到後端adaptor上,然後這個adaptor會去prometheus裡面查詢具體的資源,比如上面/pods/*/http_requests,其資源就是pod,星號這是所有pod,的http_requests。然後按照k8s的格式進行返回。這也就是說你要訪問的資源首先要在Prometheus中存在,並且該資源還需要被體現在http_requests_total指標中。所以我們上面自己加的那段就是為了讓adaptor可以去獲取Prometheus的http_requests_total指標,然後這個指標中包含POD名稱,如下圖:
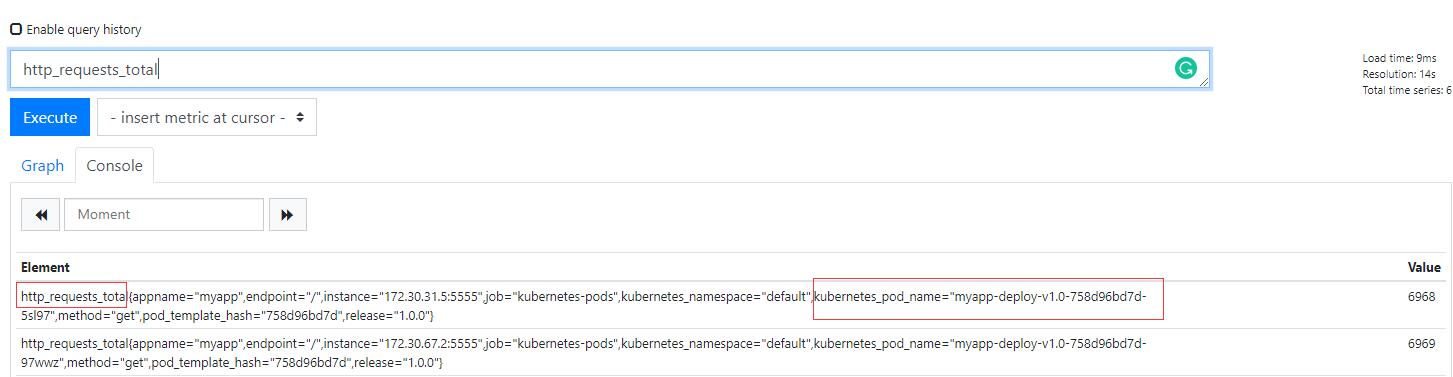
也就是說在prometheus中有指標是基礎,然後adaptor才會按照它自己的配置規則去過濾,我們上面新增的規則其實就是過濾規則。
部署APP和Service
這個app我們用自己建立的景象
apiVersion: v1
kind: Service
metadata:
name: myapp-svc
labels:
appname: myapp-svc
spec:
type: ClusterIP
ports:
- name: http
port: 5555
targetPort: 5555
selector:
appname: myapp
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: myapp-deploy-v1.0
labels:
appname: myapp
spec:
replicas: 2
selector:
matchLabels:
appname: myapp
release: 1.0.0
template:
metadata:
name: myapp
labels:
appname: myapp
release: 1.0.0
annotations:
prometheus.io/scrape: "true"
prometheus.io/port: "5555"
spec:
containers:
- name: myapp
image: myapp:v1.0
imagePullPolicy: IfNotPresent
resources:
requests:
cpu: "250m"
memory: "128Mi"
limits:
cpu: "500m"
memory: "256Mi"
ports:
- name: http
containerPort: 5555
protocol: TCP
livenessProbe:
httpGet:
path: /healthy
port: http
initialDelaySeconds: 20
periodSeconds: 10
timeoutSeconds: 2
readinessProbe:
httpGet:
path: /healthy
port: http
initialDelaySeconds: 20
periodSeconds: 10
revisionHistoryLimit: 10
strategy:
rollingUpdate:
maxSurge: 1
maxUnavailable: 1
type: RollingUpdate具體映象製作過程參見使用Kubernetes演示金絲雀釋出
建立HPA
基於POD
apiVersion: autoscaling/v2beta1
kind: HorizontalPodAutoscaler
metadata:
name: myapp-custom-metrics-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: myapp-deploy-v1.0
minReplicas: 2
maxReplicas: 10
metrics:
- type: Pods
pods:
metricName: http_requests
targetAverageValue: 5000m自定義資源指標含義是基於myapp-deploy-v1.0這個deployment的全部pod來計算http_requests的平局值,如果達到5000m就進行擴容。
scaleTargetRef:這裡定義的是自動擴容縮容的物件,可以是Deployment或者ReplicaSet,這裡寫具體的Deployment的名稱。
metrics:這裡是指標的目標值。在type中定義型別;通過target來定義指標的閾值,系統將在指標達到閾值的時候出發擴縮容操作。
metrics中的type有如下型別:
Resource:基於資源的指標,可以是CPU或者是記憶體,如果基於這個型別的指標來做只需要部署Metric-server即可,不需要部署自定義APISERVER。
Pods:基於Pod的指標,系統將對Deployment中的全部Pod副本指標進行平均值計算,如果是Pod則該指標必須來源於Pod本身。
Object:基於Ingress或者其他自定義指標,比如ServiceMonitor。它的target型別可以是Value或者AverageValue(根據Pod副本數計算平均值)。
這裡說一下5000m是什麼意思。自定義API SERVER收到請求後會從Prometheus裡面查詢http_requests_total的值,然後把這個值換算成一個以時間為單位的請求率。500m的m就是milli-requests,按照定義的規則metricsQuery中的時間範圍1分鐘,這就意味著過去1分鐘內每秒如果達到500個請求則會進行擴容。
在一個HPA中可以定義了多種指標,如果定義多個系統將針對每種型別指標都計算Pod副本數量,取最大的進行擴縮容。換句話說,系統會根據CPU和pod的自定義指標計算,任何一個達到了都進行擴容。應用上面的HPA配置清單檔案:

使用下面的命令進行測試:
ab -c 10 -n 10000 http://10.254.101.238:5555 10個使用者,總共發10000個請求,平均到2個POD,每個POD承受500,顯然不會達到我們設定的閾值。
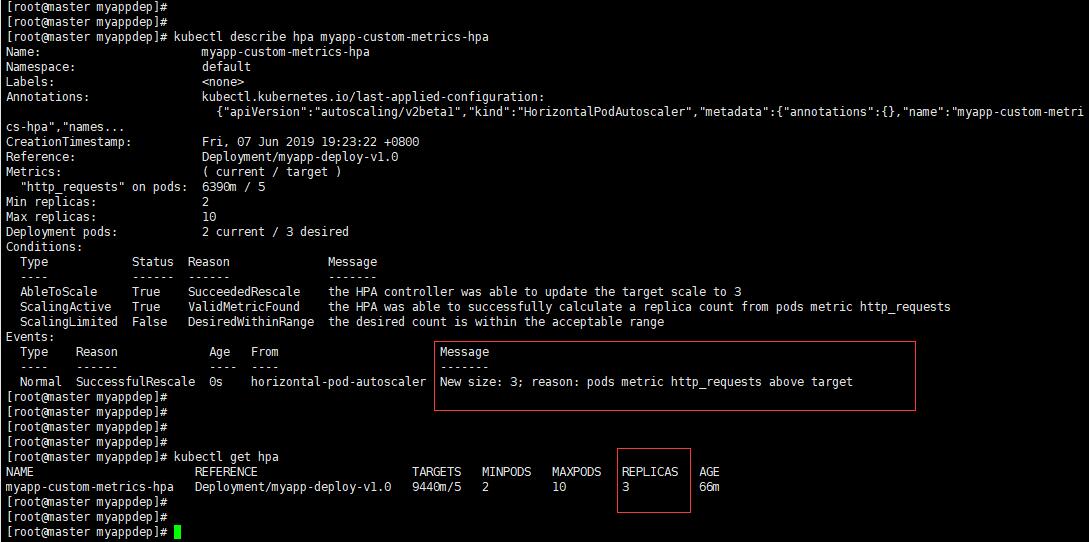
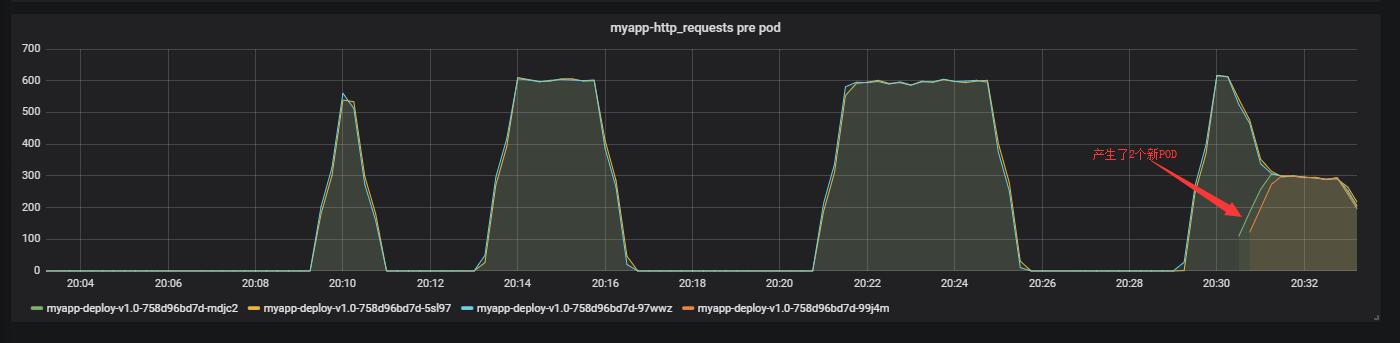
可以看到已經擴容到3個了。從監控上也可以看到,如下圖:
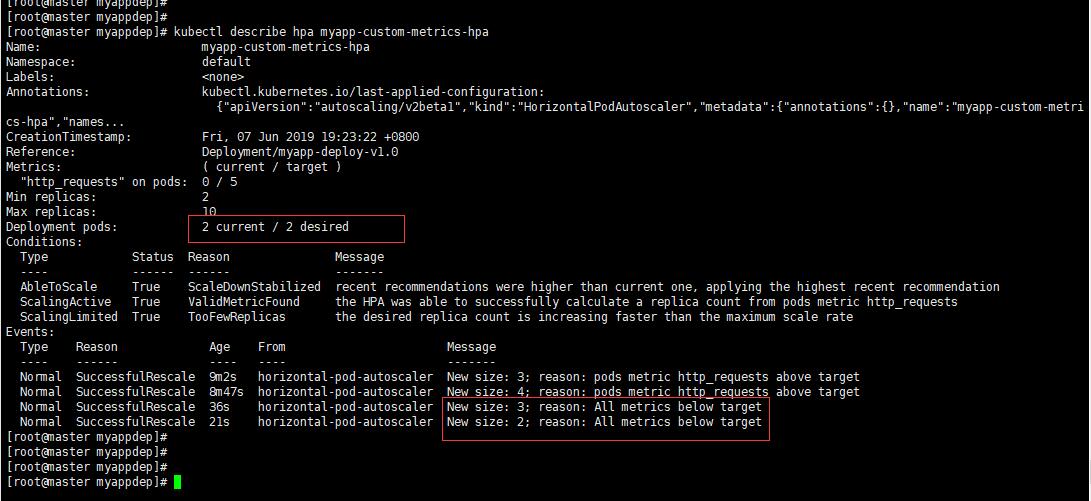
過了一會流量沒有了它會自動縮容,如下圖:
基於Service
如果基於Service的話你可以改成service,如下:
apiVersion: autoscaling/v2beta1
kind: HorizontalPodAutoscaler
metadata:
name: myapp-custom-metrics-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: myapp-deploy-v1.0
minReplicas: 2
maxReplicas: 10
metrics:
- type: Object
object:
target:
kind: Service
# 這裡是你自己的APP的service
name: myapp-svc
metricName: http_requests
targetValue: 100不過這個配置在我的環境中無法訪問,curl http://127.0.0.1:8080/apis/custom.metrics.k8s.io/v1beta1/namespaces/default/services/myapp-svc/http_requests 結果如下圖:

因為上面的APP中的service沒有配置被監控,另外在adaptor中的規則是針對pod名字的,所以這裡要做一下修改。
說明,所有修改都是基於你的Prometheus中的k8s動態發現規則的配置。
首先修改myapp的service配置,然後就可以在k8s自動發現的角色endpoints裡被發現:
apiVersion: v1
kind: Service
metadata:
name: myapp-svc
labels:
appname: myapp-svc
annotations:
prometheus.io/scrape: "true" # 新增內容
prometheus.io/port: "5555" # 新增內容
spec:
type: ClusterIP
ports:
- name: http
port: 5555
targetPort: 5555
selector:
appname: myapp重啟應用,在Prometheus中檢視

指標內容就比之前多一條:
然後配置介面卡規則,增加如下內容:
- seriesQuery: '{__name__=~"^http_requests_.*",kubernetes_name!="",kubernetes_namespace!=""}'
seriesFilters: []
resources:
overrides:
kubernetes_namespace:
resource: namespace
kubernetes_name:
resource: service
name:
matches: ^(.*)_(total)$
as: "${1}"
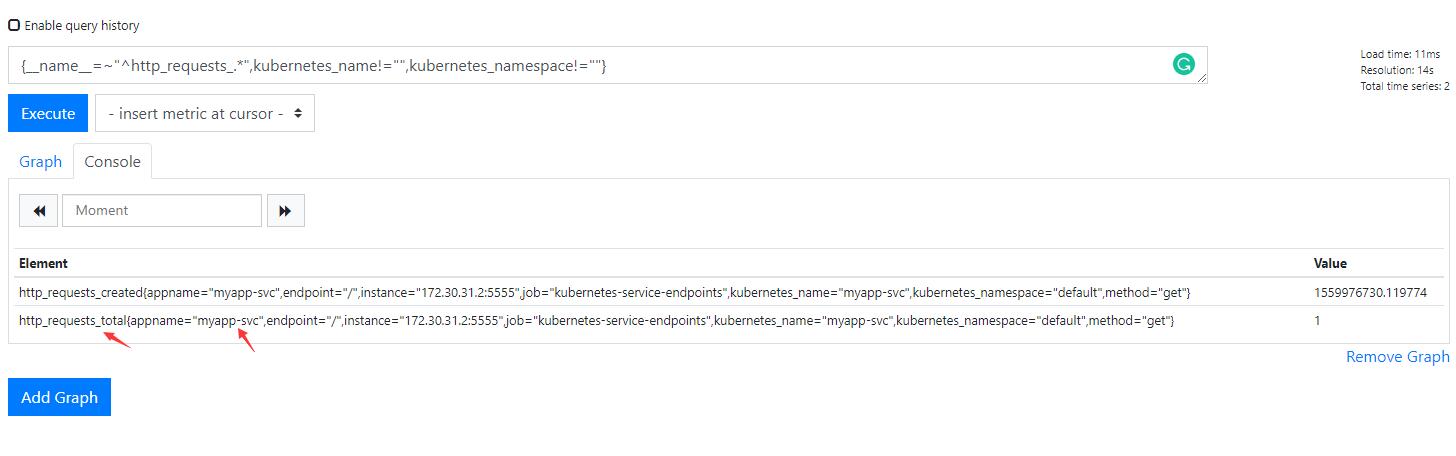
metricsQuery: sum(rate(<<.Series>>{<<.LabelMatchers>>}[1m])) by (<<.GroupBy>>)kubernetes_name在prometheus中就是service的名稱,這個是k8s中動態發現裡面的relable修改的,我們來測試一下新的條件是否可以找到:
應用這個配置,然後重建介面卡。
再次通過該URL進行訪問curl http://127.0.0.1:8080/apis/custom.metrics.k8s.io/v1beta1/namespaces/default/services/myapp-svc/http_requests,結果如下圖:

關於這裡的拍錯需要說一下,就是你可以訪問curl http://127.0.0.1:8080/apis/custom.metrics.k8s.io/v1beta1 > /tmp/metrics.txt 把它能使用資源列出來,如果沒有service/http_requests則說明你無法訪問那個URL,也就是說沒有什麼你就加什麼就好了。
我這裡就不做演示了,因為只要這個URL可以出來內容,那麼針對Service的HPA就可以做。
參考:
stefanprodan/k8s-prom-