
用Python寫了個檢測文章抄襲,詳談去重演算法原理
在網際網路出現之前,“抄”很不方便,一是“源”少,而是釋出渠道少;而在網際網路出現之後,“抄”變得很簡單,鋪天蓋地的“源”源源不斷,釋出渠道也數不勝數,部落格論壇甚至是自建網站,而爬蟲還可以讓“抄”完全自動化不費勁。這就導致了網際網路上的“文章”重複性很高。這裡的“文章”只新聞、部落格等文字佔據絕大部分內容的網頁。
中文新聞網站的“轉載”(其實就是抄)現象非常嚴重,這種“轉載”幾乎是全文照抄,或改下標題,或是改下編輯姓名,或是文字個別字修改。所以,對新聞網頁的去重很有必要。
一、去重演算法原理
文章去重(或叫網頁去重)是根據文章(或網頁)的文字內容來判斷多個文章之間是否重複。這是爬蟲爬取大量的文字行網頁(新聞網頁、部落格網頁等)後要進行的非常重要的一項操作,也是搜尋引擎非常關心的一個問題。搜尋引擎中抓取的網頁是海量的,海量文字的去重演算法也出現了很多,比如minihash, simhash等等。
在工程實踐中,對simhash使用了很長一段時間,有些缺點,一是演算法比較複雜、效率較差;二是準確率一般。
網上也流傳著百度採用的一種方法,用文章最長句子的hash值作為文章的標識,hash相同的文章(網頁)就認為其內容一樣,是重複的文章(網頁)。
這個所謂的“百度演算法”對工程很友好,但是實際中還是會有很多問題。中文網頁的一大特點就是“天下文章一大抄”,各種博文、新聞幾乎一字不改或稍作修改就被網站發表了。這個特點,很適合這個“百度演算法”。但是,實際中個別字的修改,會導致被轉載的最長的那句話不一樣,從而其hash值也不一樣了,最終結果是,準確率很高,召回率較低。
為了解決這個問題,我提出了nshash(top-n longest sentences hash)演算法,即:取文章的最長n句話(實踐下來,n=5效果不錯)分別做hash值,這n個hash值作為文章的指紋,就像是人的5個手指的指紋,每個指紋都可以唯一確認文章的唯一性。這是對“百度演算法”的延伸,準確率還是很高,但是召回率大大提高,原先一個指紋來確定,現在有n個指紋來招回了。
大家在學python的時候肯定會遇到很多難題,以及對於新技術的追求,這裡推薦一下我們的Python學習扣qun:784,758,214,這裡是python學習者聚集地!!同時,自己是一名高階python開發工程師,從基礎的python指令碼到web開發、爬蟲、django、資料探勘等,零基礎到專案實戰的資料都有整理。送給每一位python的小夥伴!每日分享一些學習的方法和需要注意的小細節
點選:python技術分享交流
二、演算法實現
該演算法的原理簡單,實現起來也不難。比較複雜一點的是對於一篇文章(網頁)返回一個similar_id,只要該ID相同則文章相似,通過groupby similar_id即可達到去重目的。
為了記錄文章指紋和similar_id的關係,我們需要一個key-value資料庫,本演算法實現了記憶體和硬碟兩種key-value資料庫類來記錄這種關係:
HashDBLeveldb 類:基於leveldb實現, 可用於海量文字的去重;
HashDBMemory 類:基於Python的dict實現,可用於中等數量(只要Python的dict不報記憶體錯誤)的文字去重。
這兩個類都具有get()和put()兩個方法,如果你想用Redis或MySQL等其它資料庫來實現HashDB,可以參照這兩個類的實現進行實現。
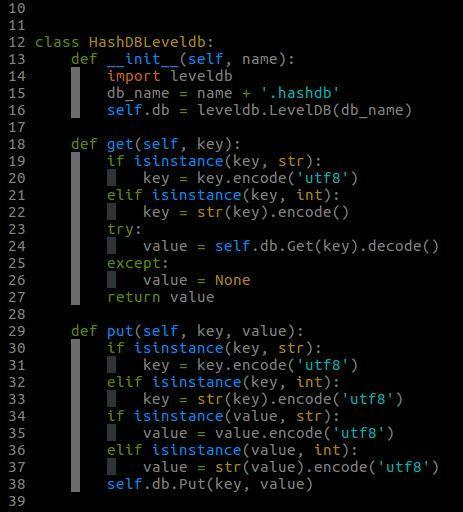
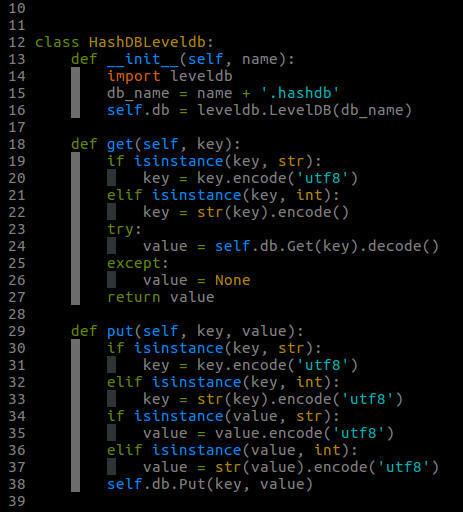
HashDBLeveldb類的實現
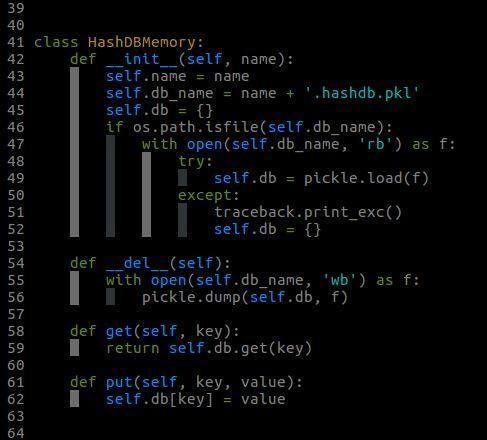
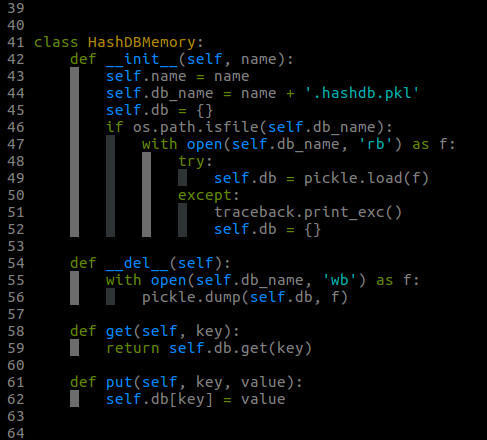
HashDBMemory類的實現
從效率上看,肯定是HashDBMemory速度更快。利用nshash對17400篇新聞網頁內容的測試結果如下:
HashDBLeveldb: 耗時2.47秒;
HashDBMemory: 耗時1.6秒;
具體測試程式碼請看 example/test.py。
有了這兩個類,就可以實現nshash的核心演算法了。
首先,對文字進行分句,以句號、感嘆號、問號、換行符作為句子的結尾標識,一個正在表示式就可以分好句了。
其次,挑選最長的n句話,分別進行hash計算。hash函式可以用Python自帶模組hashlib中的md5, sha等等,也可以用我在爬蟲教程中多次提到的farmhash。
最後,我們需要根據這n個hash值給文字內容一個similar_id,通過上面兩種HashDB的類的任意一種都可以比較容易實現。其原理就是,similar_id從0開始,從HashDB中查詢這n個hash值是否有對應的similar_id,如果有就返回這個對應的similar_id;如果沒有,就讓當前similar_id加1作為這n個hash值對應的similar_id,將這種對應關係存入HashDB,並返回該similar_id即可。
這個演算法實現為NSHash類:
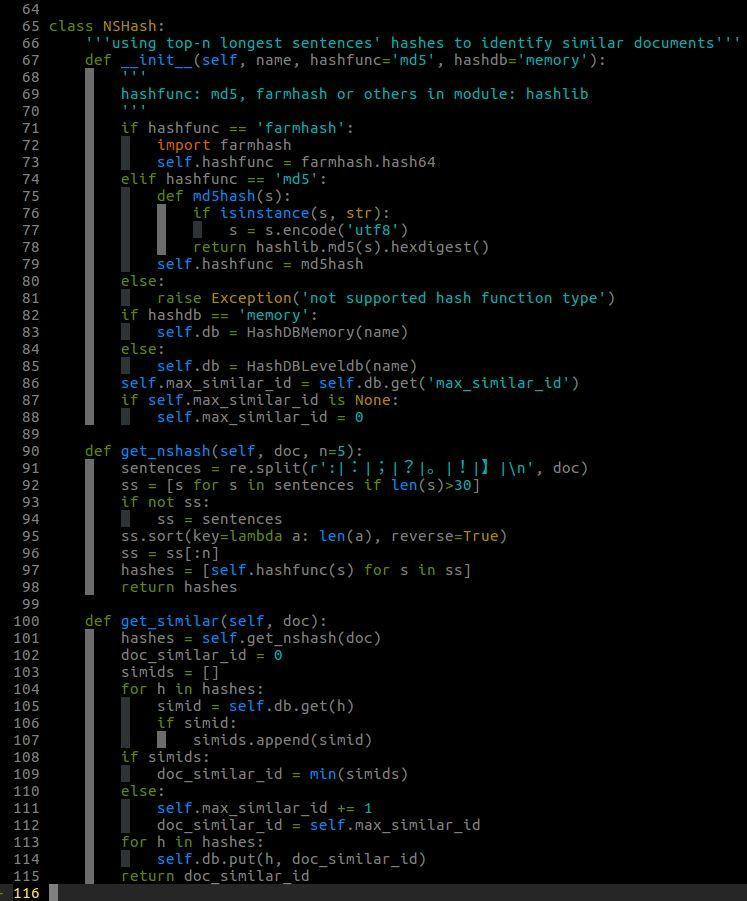
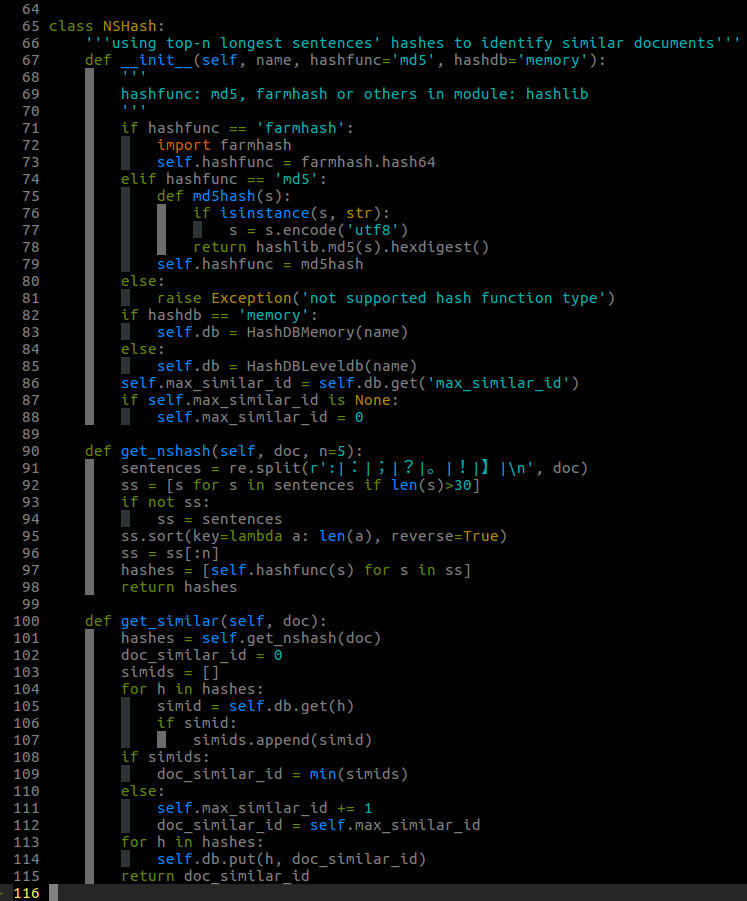
NSHash類的實現
三、使用方法
import nshash
nsh = nshash.NSHash(name='test', hashfunc='farmhash', hashdb='memory')
similar_id = nsh.get_similar(doc_text)
NSHash類有三個引數:
name: 用於hashdb儲存到硬碟的檔名,如果hashdb是HashDBMemory, 則用pickle序列化到硬碟;如果是HashDBLeveldb,則leveldb目錄名為:name+’.hashdb’。name按需隨便起即可。hashfunc: 計算hash值的具體函式類別,目前實現兩種型別:md5和farmhash。預設是md5,方便Windows上安裝farmhash不方便。hashdb:預設是memory即選擇HashDBMemory,否則是HashDBLeveldb。
至於如何利用similar_id進行海量文字的去重,這要結合你如何儲存、索引這些海量文字。可參考example/test.py檔案。這個test是對excel中儲存的新聞網頁進