
如何將深度學習訓練速度提升一百倍?PAISoar 來了
阿里妹導讀:得力於資料規模增長、神經網路結構的演進和計算能力的增強,深度學習的影象處理、語音識別等領域取得了飛速發展。隨著訓練資料規模和模型複雜度的不斷增大,如何充分利用分散式叢集的計算資源加快訓練速度,提升業務支援能力成為使用者非常關注的問題。今天,我們就來分享阿里工程師的實踐成果:將深度學習模型的大規模分散式訓練框架 PAISoar應用於綠網模型(多層CNN網路)後,綠網模型在128 GPU卡上取得101倍的計算加速比,效果顯著。
1. 概述
近幾年來深度學習發展迅速,影象處理、語音識別等領域都取得了飛速發展。例如在圖片識別上,神經網路結構快速演進,分類的網路結構從 AlexNet、VGG、Inception V1 發展到了 Inception V4、Inception-ResNet、SENet。隨著模型層次越來越深,引數越來越多,模型能力也越來越強,ImageNet 資料集 Top-5 的錯誤率越來越低,目前降到了2.25%(人眼5.1%)。
隨著模型複雜度不斷增長、訓練樣本的指數級增長,分散式進行高效並行的神經網路訓練已經變得越發重要。在社群版 Tensorflow 中,分散式訓練是基於 Parameter Server 模式進行多機訓練的。在這種訓練方式下訓練任務通常會遇到以下挑戰:
- Variable placement 策略,常用的 replica_device_setter 的策略是 round-robin over all ps tasks,這種策略並沒有考慮 Variable 大小,會導致引數分配不均衡,某些 ps 上分配的 Variable size 大就會成為通訊瓶頸;
- 多個 Worker 訪問同一個 PS 節點時,受 PS 節點頻寬限制和 TCP 的擁塞視窗控制,會導致通訊效率大幅降低,並且規模越大,效率越差;
- 分散式擴充套件後,模型需要精細調參才能收斂,需要使用者有豐富的調參經驗。
對此,我們基於 PAI Tensorflow 研發了針對於深度學習模型的高速分散式訓練框架 PAISoar,從硬體到軟體打造一套分散式訓練場景 E2E 的解決方案:
- 在硬體上,我們和 AIS 網路團隊一起搭建了集團內部第一套基於 RoCE 的大規模 RDMA 叢集,並針對於深度學習場景進行了相應的引數調優,支援低延遲、高吞吐的無損傳輸網路;
- 在軟體上,我們基於 Ring AllReduce 演算法在 RDMA 網路上實現了高度優化的 PAISoar 分散式訓練框架,通過軟硬體一體的深度優化大大提高了多機的計算加速比;
- 在 API 層面,我們提供了簡化使用者構建分散式 TF 模型訓練的ReplicatedVarsOptimizer,極大地方便了將單機模型擴充套件成分散式模型,降低了使用者構建分散式TF訓練程式碼的難度,同時提供支援 warm up 的 learning rate 動態調節方法,幫助模型訓練更容易的收斂。
PAISoar 在 Tensorflow 官方 benchmarks 模型上取得了非常不錯的加速效果。同時我們還和安全部團隊合作,將該研發成果成功的在安全部影象模型業務上落地。安全部的綠網模型訓練樣本280萬張圖片,單機兩卡訓練需要12天才能收斂,因此有著非常強的分散式訓練需求,希望能達到一天內完成訓練,提升模型迭代能力。藉助於 PAISoar,綠網模型分散式訓練取得非常明顯的加速效果,模型收斂時間從原先的12天降低到目前的一天以內,大大加速了業務的快速迭代。
我們用 images/sec (每秒處理的圖片數或樣本數)來統計分散式模型的計算能力。
假設單 GPU 卡下計算能力為1,綠網模型在 PAISoar 中計算加速比如下圖所示:
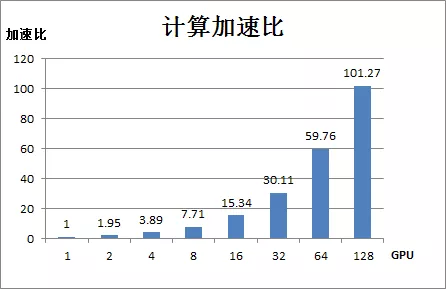
在 PAISoar 上,綠網模型在128 GPU卡上取得了101倍的計算加速比,效果非常明顯。
2. PAISoar:基於 PAI Tensorflow 的分散式訓練框架
2.1 PAISoar簡介
PAISoar 是基於 PAI Tensorflow 實現的分散式訓練框架。通過 PAISoar,我們提供了一個從硬體到軟體、易用的分散式訓練的效能優異框架。
2.1.1 網路層
我們和 AIS 網路團隊、RDMA 專案團隊一起搭建了集團內部第一套基於 RoCE 的大規模 RDMA 叢集,並針對於深度學習場景進行了相應的引數調優,包括:
- 機器上搭載 Mellanox 25G 網絡卡支援基於 RoCE v2的 RDMA,打造低延遲高吞吐通訊網路;
- ASW(接入層交換機,32口)和 PSW(聚合層交換機)間採用 8*100Gb 高速傳輸光纖,支援交換機 1:1 收斂比,搭建無損傳輸網路;
- 構建 TCP 和 RDMA 多級混合流控策略,解決各種混跑場景的流量干擾;
2.1.2 軟體層
- 在 PAI Tensorflow 中接入 RDMA 驅動,使用 verbs 庫進行 RDMA 通訊,並和思科交換機進行適配調參;
- 對 RDMA 通訊的關鍵路徑進行梳理,加速記憶體拷貝,非同步化資料傳送,優化通訊狀態機,提高 RDMA 通訊的效率和穩定性;
- 自研了深度優化的 Ring AllReduce 同步演算法,通過針對 RDMA 網路的深度適配、多路通訊融合等關鍵點優化,大大提升了多機的分散式訓練效能。
2.1.3 API 層
- 我們同時提供了簡化使用者構建分散式TF模型訓練的ReplicatedVarsOptimizer,極大的方便了將單機模型擴充套件成分散式模型,降低了使用者構建分散式TF訓練程式碼的難度和學習成本;
- 為方便使用者在分散式訓練中調參,我們提供 lr(learning rate) 的動態調節演算法smooth_exponential_decay,演算法中,lr 經過一定輪數的 warm up,從一個較小的 lr 平滑增加到目標 lr,再採用指數衰退,每隔固定 epoch 衰退一次,動態調節的 lr 可以加速使用者調參過程。
2.2 效能指標
基於 PAISoar,深度神經網路模型的分散式訓練效能提升明顯。
我們使用 Tensorflow 官方 Benchmarks 進行效能測試。Tensorflow Benchmarks 是一套 CNN 模型的基準測試集合,包括 Inception v3、ResNet-50、ResNet-152、VGG16、Alexnet 等經典 CNN 模型。下面是我們分別在1、2、4、8、16、32、64GPU卡規模下測試了 Inception v3、ResNet-50、ResNet-152、VGG16 這4個模型的效能:
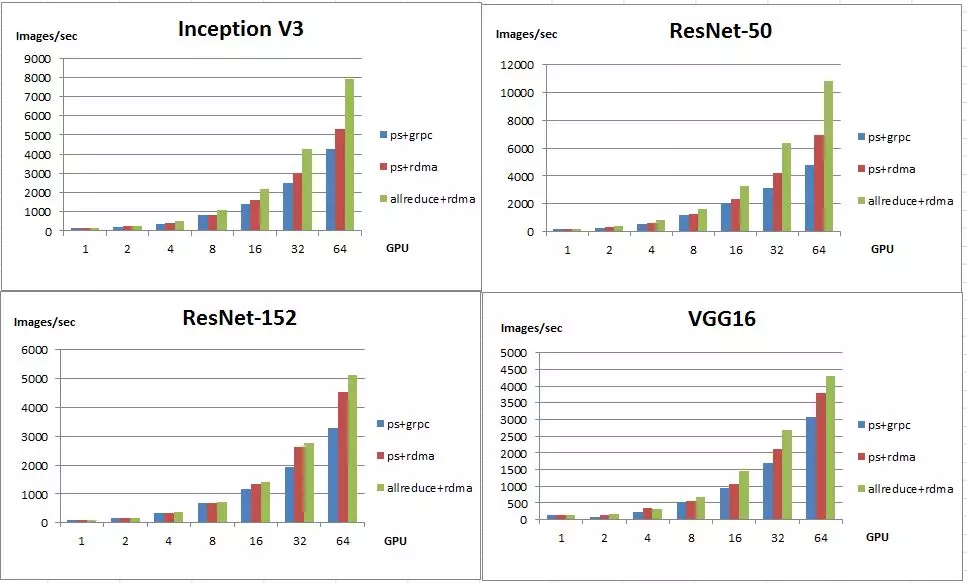
圖中引數說明:
- 上面4個圖分別是 Inception v3、ResNet-50、ResNet-152、VGG16 這四個模型的效能測試資料;
- 橫座標是 GPU 卡數,縱座標是模型訓練總的 Images/sec;
- ps、allreduce 分別表示模型引數同步的模式是 worker+ps 模式或 Ring AllReduce 模式;
- grpc、rdma 分別表示通訊底層使用的是 grpc 協議還是 rdma 協議。
Tensorflow 預設的分散式方法是 worker+ps 模式,variable 定義在 ps 上,worker 會訓練並更新 ps 上的引數。我們將底層通訊協議替換成 RDMA 後,各模型效能都有提升,在 64GPU 卡下,Inception v3、ResNet-50、ResNet-152、VGG16 四個模型效能分別提升:24.94%、44.83%、38.80%、23.38%。
相較於 worker+ps 模式,PAISoar 中提供的 Ring AllReduce 通訊模式對網路頻寬利用率更高,延遲更小。與 worker+ps (使用 grpc 通訊)相比,各模型效能提升非常明顯,在64 GPU 卡下,Inception v3、ResNet-50、ResNet-152、VGG16四個模型效能分別提升:84.77%、125.43%、56.40%、40.04%。
同時,我們也和開源的 horovod 進行對比,在64 GPU卡下,Inception v3、ResNet-50、ResNet-152、VGG16四個模型效能分別提升:-6.4%、2%、21%、36%,整體效能要好於 horovod。
接下來將會介紹 PAISoar 中的關鍵技術:RDMA 和 Ring AllReduce 的技術細節。
2.3 RDMA技術
RDMA(Remote Direct Memory Access) 是一種硬體IO技術,通過將傳輸協議固化在網絡卡硬體中,網絡卡就可以實現核心旁路(kernel bypass)和零拷貝操作,從而大幅降低網路 IO 的延遲時間,大幅提高網路吞吐,同時不影響 CPU 的負載。RDMA 在乙太網上有2個標準,2002年,ITEF 制定了 iWARP(Internet Wide Area RDMA Protocol),2010年,IBTA 制定了 RoCE(RDMA over Converged Ethernet)規範。阿里資料中心網路裡採用 RoCE(v2) 方案。在時延測試中,RoCE 可以達到單向為2 - 3us左右,而與之對應的 TCP 時延為10 - 15us 左右。
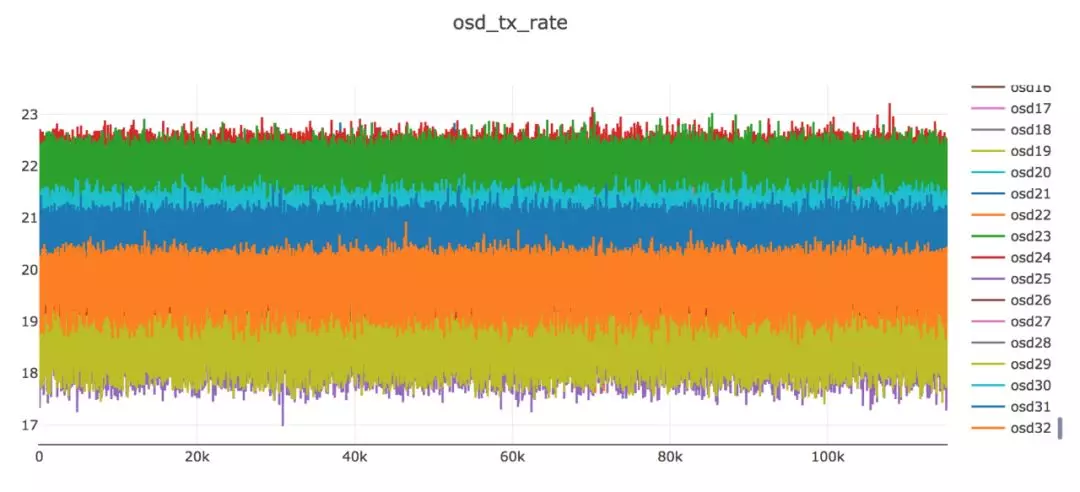
為了實現 RoCE 的效能優勢,乙太網需要提供一個無損網路做為基礎,否則對效能的負面影響非常大。乙太網的無損機制主要通過端到端的 QoS 來實現,即所有的QoS 機制需要在伺服器和交換機上做統一的設定,包括 DSCP、佇列、DCQCN、ECN、PFC 等。通過使用這些技術,能夠保證在 burst,incast 等 IO 場景下 RDMA也有穩定的表現。下圖是在一個32個節點的叢集中做長時間壓測時採集到的傳送頻寬,可以看到各個節點的頻寬非常穩定。
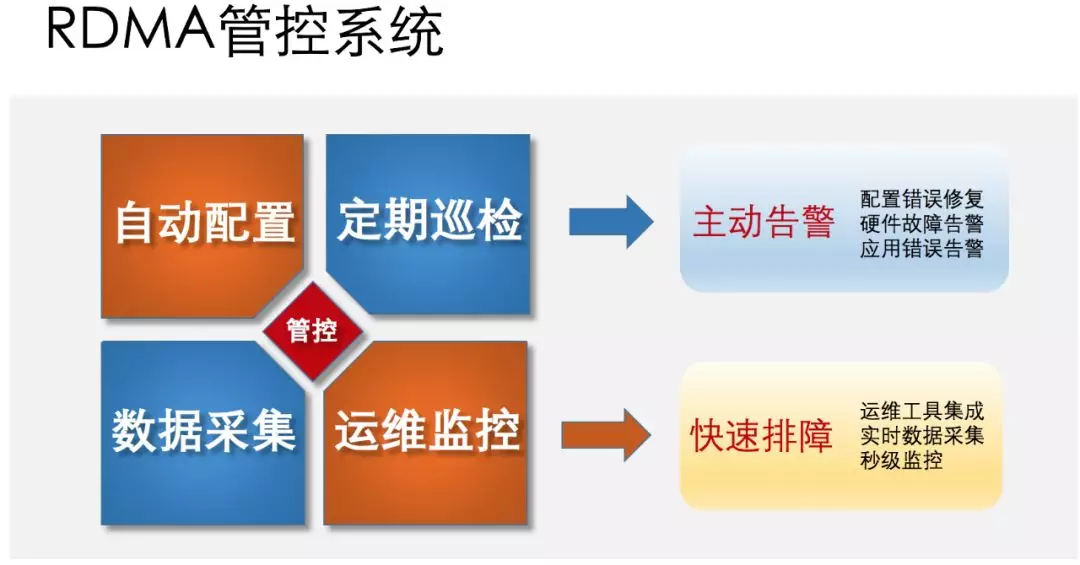
RoCE 技術雖然有很多技術優勢,但是它對無損網路的要求也導致網路配置非常複雜,除了新增很多網路裝置的管控配置,同時也把之前相對獨立的網絡卡裝置納入了網路運營的範圍,大大增加了運營的內容和難度。與此相適應,在主機上需要安裝專門的 RDMA 軟體平臺包,包括網絡卡驅動、使用者庫和管控軟體等部件。這些軟體可以做到一鍵部署、自動配置和定期巡檢,並且與相應的監控系統都有資料對接。通過安裝這些軟體包,就可以做到及時發現物理網路的配置錯誤,硬體故障,讓應用遠離複雜的網路管理,順利享受 RDMA 帶來的技術紅利。
2.3 Ring AllReduce 技術
對於許多在大型資料集上訓練的現代深度學習模型來說,基於資料並行(Data Parallelism)的同步分散式訓練是最合適的訓練方法。資料並行的同步分散式訓練在每個 worker 上都有一份完整的模型,每個 worker 讀取訓練集的不同部分計算出不同的梯度,然後同步各個 worker 上的梯度並求平均值,再用平均梯度來更新每個 worker 上的模型。在社群版 Tensorflow 中,梯度平均通過將 Variable 分配到公共的 ps (parameter server)節點上實現,通訊代價受 worker 數量和 Variable 分配策略影響很大。在 PAISoar 中我們使用 Ring AllReduce 技術實現梯度平均,通訊代價的上限與 worker 數量無關,且不再需要額外的 ps 節點。
Ring Allreduce 演算法的原理與核心功能如下:
Ring AllReduce 演算法將 device 放置在一個邏輯環路(logical ring)中。每個 device 從上行的 device 接收資料,並向下行的 deivce 傳送資料,因此可以充分利用每個 device 的上下行頻寬。
使用 Ring Allreduce 演算法進行某個稠密梯度的平均值的基本過程如下:
將每個裝置上的梯度 tensor 切分成長度大致相等的 num_devices 個分片;
ScatterReduce 階段:通過 num_devices - 1 輪通訊和相加,在每個 device 上都計算出一個 tensor 分片的和;
AllGather 階段:通過 num_devices - 1 輪通訊和覆蓋,將上個階段計算出的每個 tensor 分片的和廣播到其他 device;
在每個裝置上合併分片,得到梯度和,然後除以 num_devices,得到平均梯度;
以 4 個 device上的梯度求和過程為例:
ScatterReduce 階段:
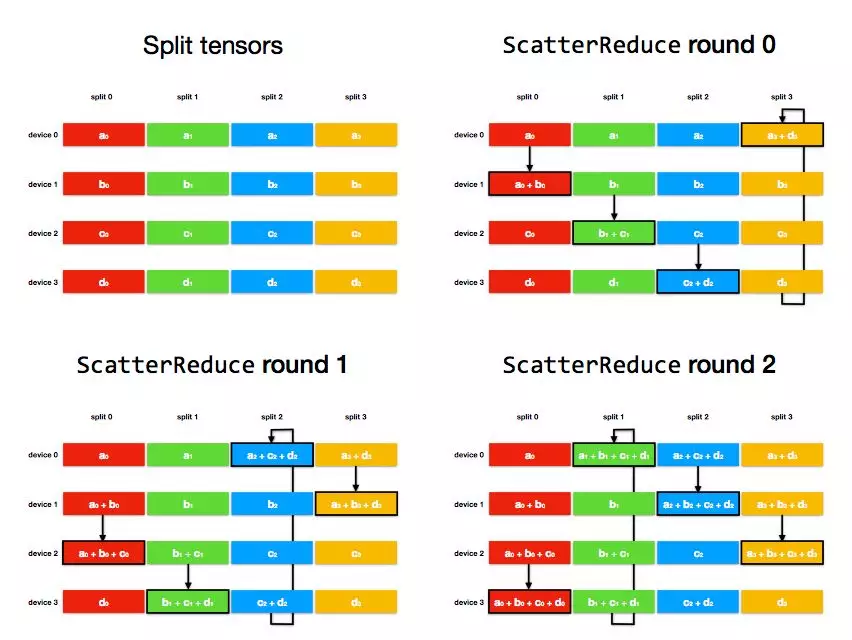
經過 num_devices - 1 輪後,每個 device 上都有一個 tensor 分片進得到了這個分片各個 device 上的和。
AllGather 階段:
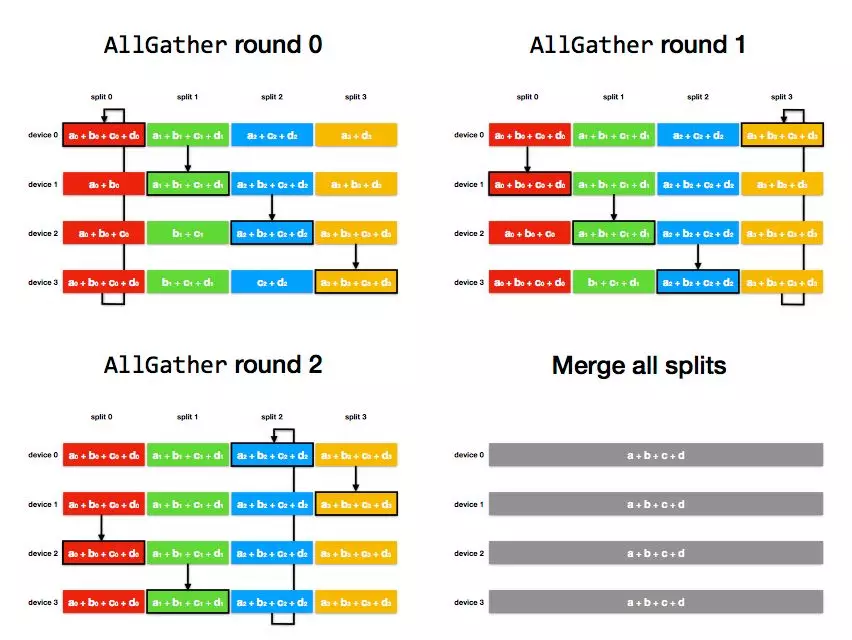
經過 num_devices - 1 輪後,每個 device 上都每個 tensor 分片都得到了這個分片各個 device 上的和;由上例可以看出,一次 Ring Allreduce 中單個節點總的通訊資料量是

每個節點上通訊資料量的上限不會隨分散式規模變大而變大。
在 PaiSoar 中,我們基於 Tensorflow 原生的通訊原語 Rendezvous 實現 Ring AllReduce 演算法,並提供簡化使用者構建分散式 TF 模型訓練的
ReplicatedVarsOptimizer 介面(使用者文件),核心功能如下:
- 簡單的使用者介面:只需開啟 PAISoar 之後將原有的 Optimizer 包裝為 ReplicatedVarsOptimizer,即可將單機模型改成分散式模型,不需要修改太多的程式碼;
- 支援多種通訊協議:支援 gRPC、RDMA 等多種通訊協議;
- 優化的通訊策略:根據計算圖的資訊,平衡計算通訊重疊度和通訊效率,合併計算時間相近的梯度一起傳輸。
3. 安全部綠網模型
3.1 模型介紹
綠網模型開始於2013年,在安全部成立初期就已經存在,用於電商場景中的色情內容的識別。綠網模型最初基於 BOW(Bag of Word)型別的影象分類模型,這是在深度學習(Deep Learning)出現之前學術界以及工業界普遍使用的建模方式,在影象檢索以及分類上都得到了廣範的使用。

綠網模型分為網際網路場景與電商場景兩個模型。本文中主要集中介紹網際網路場景的模型。網際網路場景是絕大多數網站/ App 的需求,特點是隻檢出有明確證據判斷為色情內容的圖片/視訊,標準較寬鬆,可以容忍一些大尺度性感照、不雅姿勢、猥瑣動作等。
目前綠網模型網際網路場景主要是在阿里雲的阿里綠網(內容安全),綠網的付費客戶數量隨著網際網路內容管控的需求加大呈現了指數級增長。目前已經為集團內和集團外的大量客戶提供了安全穩定的內容保障。
目前綠網模型網際網路場景每天呼叫量已經達到億級別,平均的 RT 為80ms左右。
由於影象計算量複雜以及影象資料量大,GPU 單機訓練已經無法滿足目前模型迭代的速度,單機2卡訓練一個模型需要長達12天之久,因此分散式訓練勢在必行:
3.2 分散式調參
如上文,使用 PAISoar 進行分散式訓練後,綠網模型取得了非常明顯的計算加速效果,在128 GPU卡上,計算加速比能達到101倍。
分散式訓練另一個重要的工作就是調參,分散式規模擴大相當於增加 batch size,如果沿用以前的學習策略和引數(learning Rate等)會導致模型收斂慢或不收斂,達不到單機訓練的精度。我們需要進行調參來讓模型訓練收斂。
我們調參所用的方法:
1.訓練資料分片,在分散式訓練時,需要對資料進行分片,確保每個 worker 讀到的資料不一樣,最好是每幾個 epoch 後整體資料 shuffle 一次,避免模型對輸入資料順序的依賴。
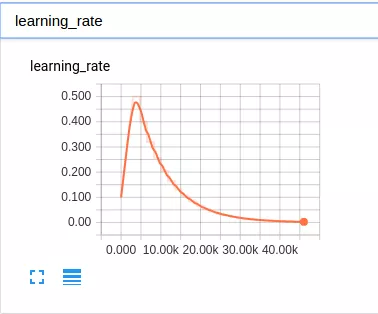
2.使用 PaiSoar 中的 learning rate 動態調節方法smooth_exponential_decay,在訓練初期採用 lr(learning rate) 平滑上升的策略,訓練剛開始時,使用一個較小的 lr,儘量避免一開始由於 lr 太大導致收斂不穩定。後面再平滑增大 lr,儘量讓 weights 更新到離初始的 init weight 比較遠的地方。lr 增長到目標值後再採用指數衰退的方式,每個幾個 epoch 衰退一次,逐步減少 lr,避免訓練後期過大的 lr 導致訓練波動,不收斂,learning rate 變化趨勢如下圖所示:
3.分散式 N 個 worker 訓練,相當於單機 batch size 增大N倍,此時需要調大 learning rate,一般調大 sqrt(N)~N倍,可以結合 Tensorboard 來觀察 loss 和 lr 的變化趨勢來決定調大還是調小 lr.
經過調參在不同 GPU 卡下綠網模型都除錯收斂,不同 GPU 卡下訓練輪數如下表所示:
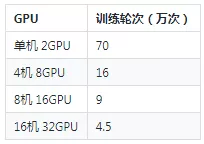
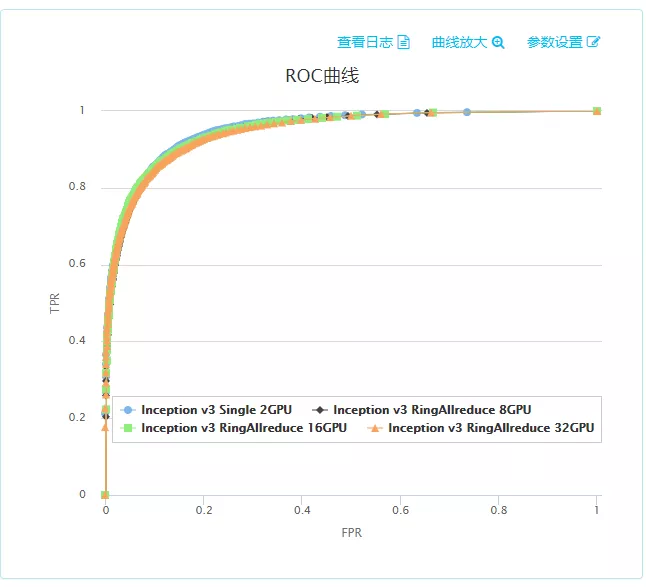
在16機(32 GPU卡)下綠網模型在20個小時收斂,比單機(2 GPU卡)快了14.4倍,完成一天內訓練收斂的目標。同時對所有分散式訓練的模型使用了安全部的的火眼平臺進行 ROC 測試,測試集有4萬多條資料。經測試,分散式模型效果和單機2 GPU卡效果一致:
3.3 模型迭代
我們通過分散式訓練加快了綠網模型的收斂,這時就可以嘗試採用更復雜的神經網路結構來提高 AUC,之前綠網模型內使用的是 Inception v3 結構,我們升級到 Inception v4 進行測試,發現 ROC 曲線提升明顯:
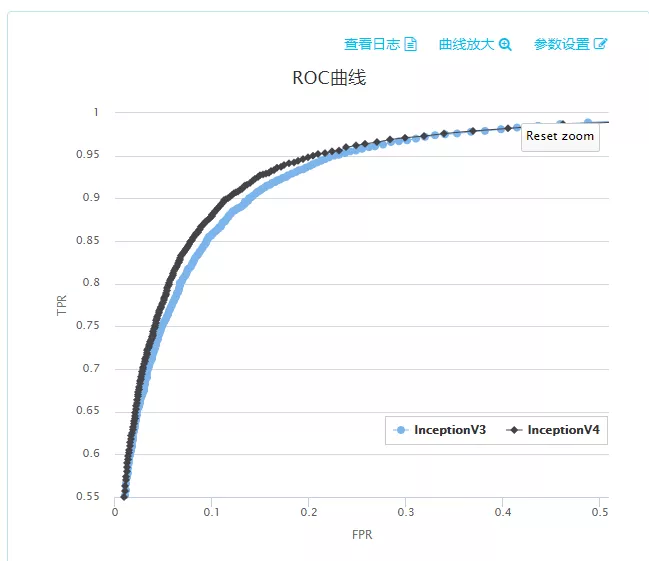
PAISoar 的分散式加速能力讓我們可以嘗試使用更復雜的模型結構來提高模型效果。
4. 總結和展望
通過與 AIS 網路團隊、RDMA 專案團隊的協同合作,PAI Tensorflow 的分散式訓練框架 PAISoar 成功上線,並和安全部在綠網模型上進行合作落地,取得非常好的效果,128 GPU卡上計算加速比達到101倍。期望後續能服務更多的使用者,併為使用者提供簡單、高效、可靠的分散式服務。
接下來我們會繼續優化分散式訓練框架 PAISoar:
- 嘗試不同的網路拓撲結構和通訊架構,進一步充分利用網路頻寬;
- 引數稀疏化通訊,嘗試發現高頻變化特徵從而達到進一步提高通訊效率並且將模型精度衰減在一定範圍之內;
- 提供便捷的使用方法,方便使用者快速接入,降低學習成本。
作者: 王林
原文連結
本文為雲棲社群原創內容,未經