
解讀 Kylin 3.0.0 | 更敏捷、更高效的 OLAP 引擎
在近期的 Apache Kylin Meetup 成都站上,我們邀請到 Kyligence 架構師 & Apache Kylin Committer 倪春恩對 Kylin 3.0.0 版本的一些重要功能及改進從使用到原理進行了介紹:
Apache Kylin 在今年 4 月 18 日釋出了 3.0.0 Alpha 版本,我今天的分享也圍繞 Release notes 內提到的三個功能,即:基於 Curator 的作業排程器,使用 Apache Livy 提交 Spark 任務,實時 OLAP。
基於 Curator 的作業排程器
首先講一下作業排程器。Kylin 支援叢集部署, Kylin 例項主要有三種模式。一種是 Job 模式(用作任務構建),一種是 Query 模式(用作 Query 查詢),配置成all模式的節點既做 Query 節點又做 Job節點。之前,我們需要先設定配置項,配置 kylin.server.cluster-servers 為叢集中所有節點,這樣各節點便可互相通訊,比如元資料的同步。

我們可以通過 Ngnix 等工具配一個對 Kylin 叢集查詢的多活,即便有某個節點掛掉了,也不會影響 Kylin 的查詢使用。但在原有的預設模式下,是不支援任務構建的高可用的。在預設的任務排程模式下,Job 節點會在 ZooKeeper 的一個路徑下生成一個臨時節點作為併發鎖,只有持有鎖的節點才會啟動任務排程器。但如果發生一些情況,這個任務節點退出了,或者是 ZooKeeper 服務異常,都會導致所有的構建任務、merge 任務無法執行,別的任務節點也沒有辦法把這些任務 takeover 起來。

另外,所有的 Kylin 節點都需要配置叢集節點列表的配置項 kylin.server.cluster-servers,一旦需要往叢集新增節點,所有的節點配置項都必須改,非常不利於叢集的擴充套件,一旦某個節點沒有配正確,就會發生很多異常情況。
接下來介紹 Curator。Curator 是一個 Apache 的孵化專案,Curator 框架提供了一套高階的 API, 簡化了 ZooKeeper 的操作。它增加了很多使用 ZooKeeper 開發的特性,可以處理 ZooKeeper 叢集複雜的連線管理和重試機制。Service Discovery 是 Curator 的一個模組,他提供了 Service 的註冊機制,對一個新 Service的註冊,Service 的狀態變更事件,別的 Service 能夠立即得到相應。
基於 Curator 的作業排程器的配置方法很簡單,把配置項 kylin.job.scheduler.default 配置成 100 即可。啟動後,所有節點都會往 ZK 裡面去註冊臨時節點,每個臨時節點寫有節點 url,模式等基本資訊。
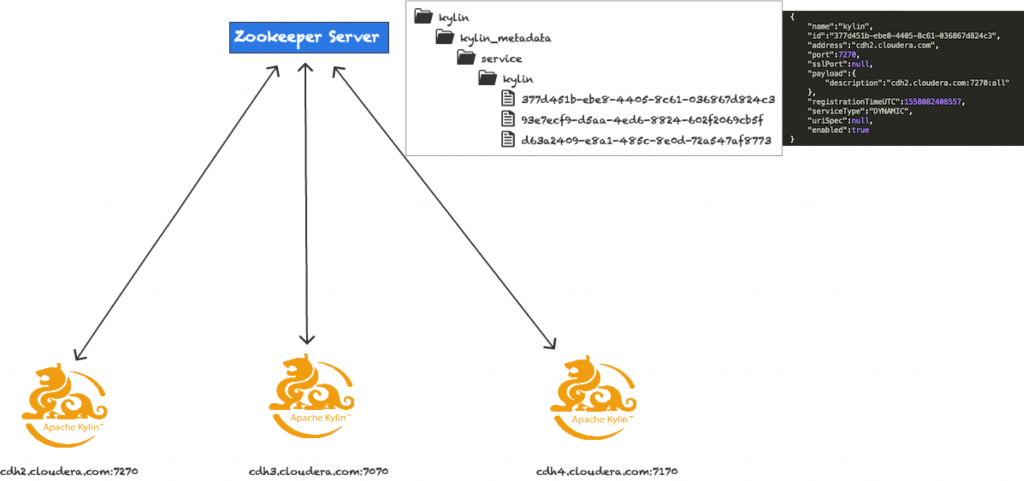
在此模式下的任務排程,只會有一個被選舉出來的任務節點,來執行任務排程。多節點的 Leader 選舉,是基於 Curator 的 Leader 選舉。它具有這樣的特點:
- 每個例項都能公平獲取領導權
- 獲取領導權的例項在釋放領導權之後,該例項還有機會再次獲取領導權
每個 Job 或 All 節點會往 leader 路徑下建立節點,獲得領導權的任務節點會啟動任務排程器。失去了領導權後,該節點會中斷所有的構建任務,另一臺節點會緊接著獲取新的領導權,把所有的任務給恢復起來。

另外在系統頁面會有一個節點監控頁面,使用者可以看到各節點的型別與狀態。

該任務排程模式的優點有:
- 實現了 HA,保證構建任務的持續執行
- 方便進行節點擴充套件
- 配置方便,減少運維成本
- 便於監控
使用 Apache Livy 提交 Spark 任務
第二個 Feature 是支援使用 Apache Livy 提交 Spark 任務,Livy 是一個基於 Spark 的開源 REST 服務,它能夠通過 REST 的方式將程式碼片段或是序列化的二進位制程式碼提交到 Spark 叢集中去執行。它提供了以下這些基本功能:
- 提交 Scala、Python 或是 R 程式碼片段到遠端的 Spark 叢集上執行
- 提交 Java、Scala、Python 所編寫的 Spark 作業到遠端的 Spark 叢集上執行
- 提交批處理應用在叢集中執行

對應到 Kylin,需要作如下配置:
- kylin.engine.livy-conf.livy-enabled=true
- kylin.engine.livy-conf.livy-url={url of Livy server}
- kylin.engine.livy-conf.livy-key.file={path for kylin job jar}
- kylin.engine.livy-conf.livy-arr.jars={paths for dependencies}
首先開關 kylin.engine.livy-conf.livy-enabled 需要開啟,預設是關閉的。其次是配上 Livy rest server 的 url 到 kylin.engine.livy-conf.livy-url,另外需要配上任務 jar 包的路徑到 kylin.engine.livy-conf.livy-key.file,最後是 kylin.engine.livy-conf.livy-arr.jars 需配置為任務依賴的 jar 包。下圖為使用 Livy 服務進行 Spark 構建傳送的請求日誌,從中可以看到相應的引數。

預設情況下,每個 Kylin 節點都要配置自己的 Spark home,有了此功能,所有的任務節點都需要往一個 Spark Uil 去提交任務,這樣就比較方便管理和監控。
實時 OLAP
Kylin 在 2014 年由 eBay 開發完成,初衷是解決海量資料快速互動式分析的問題,資料來源只支援 Hive。Kylin 在 v1.6 引入的準實時資料攝入,但是還是需要觸發構建,至少會有數分鐘的延遲。eBay 開發團隊基於 Kylin 開發了 Real-time OLAP 的特性,實現了 Kylin 對 Kafka 流式資料的實時查詢。eBay 內部已將此功能用於生產,並穩定執行超過一年時間。該 feature 於 2018 年下半年開源,並在 v3.0-alpha 里正式釋出。
Ø 實時 OLAP 基本架構
在新的架構下,資料查詢請求根據時間分割槽列(Timestamp Partition Column)分為兩部分, 歷史資料的查詢請求仍將傳送給 HBase Region Server,最新時間段的查詢請求將傳送到實時計算節點,Query Server 需要將兩者的結果整合後返回給查詢客戶端。
與此同時,實時計算節點會不斷將本地資料上傳到 HDFS,在滿足一定條件時會通過 Hadoop 來構建 segment,從而完成實時資料向歷史資料的轉化,並且實現了降低實時計算節點壓力的目的。

Ø Real-time OLAP 的概念和角色
為實現 Real-time OLAP, Kylin 引入了一些新的概念。
1. Streaming Receiver
Streaming Receiver 的角色是 worker,每個 receiver 是一個 Java 程序,受 Coordinator 的管理,它的主要職責包含:
- 實時攝入資料
- 在記憶體構建 cuboid,定時將儲存在記憶體的 cuboid 資料 flush 到磁碟,形成 Fragment 檔案
- 定時 checkpoint 和合並 Fragment 檔案
- 接受對它所負責的 Partition 的查詢請求
- 當 segment 變為不可變後,上傳到 HDFS 或者從本地刪除(依據配置)
2. Receiver Cluster
Streaming Receiver 組成的集合稱為 Receiver 叢集。
3. Streaming Coordinator
Streaming Coordinator 作為 Receiver 叢集的 Master 節點,主要職責是管理 Receiver,包括將 Kafka topic 的 partition 分配/解除分配到指定的 Replica set、 暫停或者恢復消費、收集和展示各項統計指標(例如 message per second)。當 kylin.server.mode 被設定為 all 或者 stream_coordinator,這個程序就成為一個Streaming Coordinator。Coordinator 只處理元資料和叢集排程,不攝入訊息。
4. Coordinator Cluster
多個Coordinator 可以同時存在,組成一個 Coordinator 叢集。在多個 Coordinator 中,同一時刻只存在一個 Leader,只有 Leader 才可以響應請求,其餘程序作為 standby/backup。
5. Replica Set
Replica Set 是一組 Streaming Receiver,它們動作一致。Replica Set 作為任務分配的最小單位,Replica Set 下的所有 Receiver 做相同的工作(即攝入相同的一組 partition),互為 backup。當叢集中存在一些 Receiver 程序無法訪問,能保證每一個 Replica Set 至少存在一個健康的 Receiver,那麼叢集仍能正常工作並且返回合理的查詢結果。在一個 Replica Set 中,將存在一個 Leader Receiver 來做額外的工作,其餘的 Receiver 作為 Follower。
Ø Real-time OLAP 的整體架構
下圖為 Kylin 實時 OLAP 的整體架構,資料流向方面,是從 Kafka 到 Receiver,再由 Receiver 上傳到 HDFS,最後由 MapReduce 程式合併和重新加工 Segment 進入 HBase。

查詢方面,查詢請求由 Query Server 發出,根據查詢條件中出現的時間分割槽列,分發請求到 Receiver 和 HBase Region Server 兩端。
Topic Partition 的分配和 Rebalance、Segment 狀態管理和作業提交由 Coordinator 負 責。
另外在實時構建中,Kylin 使用 ZooKeeper 進行元資料的儲存。
Q & A
提問:Kylin 實時 OLAP 的資料消費都是針對 Kafka,我最近也在去做 POC,就是針對 Kylin v3.0。我發現了在消費 Kafka 資料的時候,3 個 Server 裡,有的 Server 攝取了全量資料,有的不是,這個我不太清楚具體是什麼一個情況。
回答:你可以點選某一個 Receiver,可以看到這個 Receiver 對這個 Cube 的消費統計資料。
提問:還有消費延遲,這個怎麼去解決這個問題呢?
回答:資料消費延遲在我們的測試環境也有,目前來講處理的方法是通過 Server 的擴容。
提問:剛才也聽您說了很多 Kylin 實時的一些原理,同 Spark Streaming 和 Flink 相比,有什麼優點?
回答:Kylin 和他們不是在一個層面的,Spark Streaming 和 Flink 是更加通用的計算框架,而 Kylin 是一個 OLAP 的應用,通過預計算,對於一個查詢,它的目標是直接去拿到一個結果。
提問:我想問的就是剛才那個保留狀態,他能保證比如說資料沒處理到的,可以實現端到端一次性不丟失嗎?就是在消費過來的資料時服務掛掉了,這時候進來的那部分資料會丟失嗎,就是從 Kafka 資料去消費的時候?
回答:這個還是得看時間視窗的配置,Kylin Realtime 會按配置接受一定時間延遲的資料進來。但如果過了這個配置的最大時間,是沒辦法被構建的,因為對應的 Segment 已經變成一個本地的只可讀不可寫的狀態。