
《An Attentive Survey of Attention Models》閱讀筆記
本文是對文獻 《An Attentive Survey of Attention Models》 的總結,詳細內容請參照原文。
引言
注意力模型現在已經成為神經網路中的一個重要概念,並已經應用到多個應用領域。本文給出了注意力機制的主要思想,並對現有的一些注意力模型進行了分類,以及介紹了注意力機制與不同的神經結構的融合方法,並且還展示了注意力是如何提高神經網路模型的可解釋性的。最後,本文討論了一些具體應用程式中注意力機制的應用與建模過程。
Attention Model(AM)首次被 Bahdanau1 等人引用來解決機器翻譯等問題,並已經作為神經網路架構的重要組成部分來廣泛應用與自然語言處理,統計學習,語音和計算機視覺等多種領域。注意力機制的主要思想請參考資料:淺談 Attention 機制的理解。神經網路中的 attention model 的快速發展主要有三個原因:
- 注意力模型是最先進的模型,並且可以用於多種任務,如機器翻譯,問答系統,情感分析,部分語音標記,選區分析和對話系統等;
- 注意力模型可以用於改善神經網路的可解釋性。目前神經網路被認為是黑盒模型,而人們對影響人類生活的應用中的機器學習模型的公平性,責任性和透明度越來越感興趣。
- 注意力模型有助於克服 RNN 中存在的一些問題,例如隨著輸入序列長度的增加,模型效能下降的問題,以及輸入順序處理導致的計算效率低下的問題。
Attention Model
該文獻依然是從經典的 Encoder-Decoder 模型中來引入注意力模型,這有利於讀者對 Attention 機制有更直觀的理解,同樣可以參考淺談 Attention 機制的理解。
以 Sequence-to-sequence 模型為例,該模型包含了一個 Encoder-Decoder 架構。其中,Encoder 是一個 RNN 結構,將序列 \(\lbrace x_1,x_2,\dots,x_T \rbrace\) 作為其輸入,\(T\) 表示輸入序列的長度,並將該序列編碼成固定長度的向量集合 \(\lbrace h_1,h_2,\dots,h_T \rbrace\) 。Decoder 也是一個 RNN 結構,將一個單一的固定長度的向量 \(h_T\) 作為輸入,並且迭代地生成一個輸出序列 \(\lbrace y_1,y_2,\dots,y_{T'} \rbrace\),\(T^{'}\) 表示輸出序列的長度。在每個時刻 \(t\),\(h_t\) 和 \(s_t\) 分佈表示 Encoder 和 Decoder 的隱藏層狀態。
傳統 encoder-decoder 的挑戰
- Encoder 需要將所有的輸入資訊壓縮成傳遞給 Decoder 的單個固定長度的向量 \(h_T\),該向量可能無法表示輸入序列的詳細資訊,導致資訊丟失;
- 無法模擬輸入和輸出序列之間的對齊,而這在結構化輸出任務(如翻譯或摘要)中十分重要;
- Decoder 無法在生成輸出時重點關注與其相關的輸入的單詞,而是同權地考慮所有的輸入元素。
關鍵思想
Attention Model 旨在通過允許 Decoder 訪問整個編碼的輸入序列 \(\lbrace h_1,h_2,\dots,h_T \rbrace\) 來解決上述的問題。中心思想時在輸入序列上引入 attention 權重 \(\alpha\) ,從而在生成下一個輸出標記時優先考慮集合中存在相關資訊的位置集。
attention 使用
相應的具有注意力機制的 Encoder-Decoder 的架構如 Figure 2(b) 所示。架構中的 attention block 負責自動學習注意力權重 \(\alpha_{ij}\) ,該引數表示了 \(h_i\) 和 \(s_i\) 之間的相關性,其中 \(h_i\) 為 Encoder 隱藏狀態,也稱之為候選狀態,\(s_i\) 為 Decoder 隱藏層狀態,也稱之為查詢狀態。這些注意力權重然後被用來建立一個上下文向量 \(c\),該向量作為一個輸入傳遞給 Decoder。在每個解碼位置 \(j\),上下文向量 \(c_j\) 是所有 Encoder 的隱藏層狀態和他們對應的注意力權重的加權和,即 \(c_j=\sum_{i=1}^T{\alpha_{ij}h_i}\)。該機制的優勢是 Decoder 不僅考慮了整個輸入序列的資訊,而且集中關注了那些在輸入序列中相關的資訊。
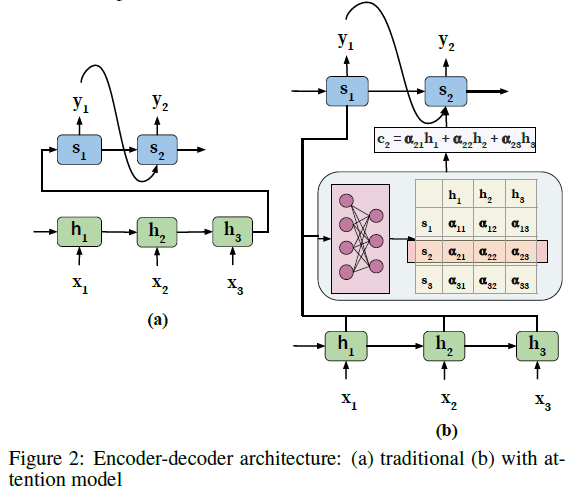
學習 attention 權重
注意力權重是通過在體系結構中併入一個額外的前饋神經網路來學習的。該前饋神經網路學習將候選狀態和查詢狀態作為神經網路的輸入,並學習一個關於這兩個隱藏層狀態 \(h_i\) 和 \(s_{j-1}\) 的特定注意力權重 \(\alpha_{ij}\)。注意,此前饋神經網路需要和架構中的 encoder-decoder 元件一起聯合訓練。
此處在計算注意力權重的時候使用的是 \(s_{j-1}\),這是因為我們當前在計算 \(y_j\) 時是不知道 \(s_j\) 狀態的,所以只能使用前一個狀態。
注意力分類
該文獻將注意力主要分為四大類,但是需要注意的是這些類別並不是互斥的,Attention 可以應用於多種型別的組合當中,例如 Yang2 等人將 multi-level 和 self and soft attention 進行組合使用。因此,我們可以將這些類別看作是將注意力用於感興趣的應用時可以考慮的維度。
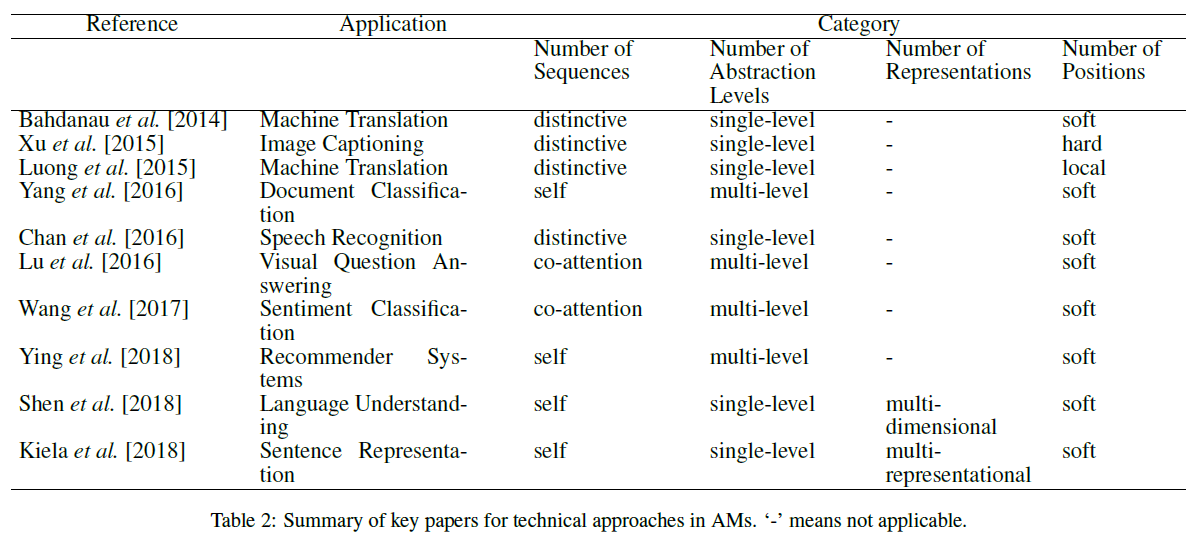
Number of sequences
到目前為止,我們只考慮了涉及到單個輸入和對應輸出序列的情況。當候選狀態和查詢狀態分佈屬於兩個不同的輸入序列和輸出序列時,就會使用這種型別的注意力,我們稱之為 distinctive 。
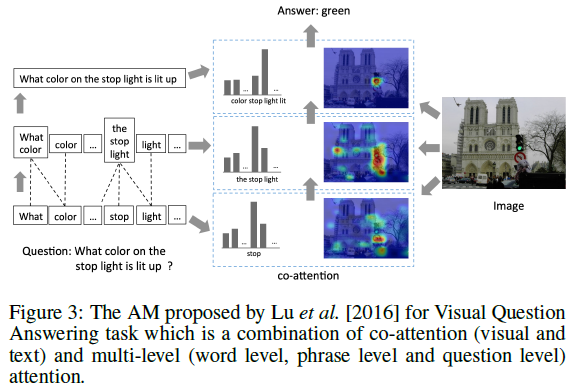
co-attention 模型同時對多個輸入序列進行操作,並共同學習它們的注意力,以捕獲這些輸入之間的相互作用。
相反,對於諸如文字分類和推薦之類的任務,輸入是序列,但輸出不是序列。在這種情況下,可以使用注意力來學習輸入序列中對應於相同輸入序列中的每個標記的相關標記。換句話說,查詢和候選狀態屬於這種型別的關注的相同序列,這種注意力模型稱為 self-attention。
Number of abstraction levels
在最一般的情況中,僅針對原始的輸入序列計算注意力權重,這種型別的注意力可以稱之為 single-level。另一方面,可以按照順序將注意力應用於輸入序列的多個抽象層次,較低抽象級別的輸出(上下文向量)成為較高抽象級別的查詢狀態。此外,使用 multi-level 注意力的模型可以進一步根據權重自上而下學習或者自下而上學習來進一步分類。多層注意力模型的最典型的示例就是文件的學習,文件是由句子組成的,而句子是由單片語成的,因此可以建立兩層的 attention 機制。
Number of positions
在該分類依據中,主要是根據在計算注意力函式時輸入序列的位置。Bahdanau3 等人提出的注意力也被稱為 soft-attention 。顧名思義,它使用輸入序列的所有隱藏狀態的加權平均值來構建上下文向量。這種軟加權方法的使用使得神經網路易於通過反向傳播進行有效學習,但也導致二次計算成本。
Xu4 等人提出了一種 hard-attention 模型,其中上下文向量是通過從輸入序列中隨機取樣隱藏層狀態來計算得到,這是通過一個由注意力權重引數化的多項式分佈來實現的。由於降低了計算成本,hard-attention 模型是有效的,但是在輸入的每個位置做出一個艱難的判決使得所得到的框架不可微並且難以優化。因此,為了克服這一侷限性,文獻中提出了變分學習方法和強化學習中的策略梯度方法。
Luong5等人提出了兩種注意力模型用於機器翻譯任務,分別命名為 local attention 和 global attention。其中,global attention 和 soft-attention 是相似的,而 local attention 介於 soft-attention 和 hard-attention 之間。關鍵思想是首先檢測輸入序列中的注意點或位置,並在該位置周圍選擇一個視窗以建立區域性軟注意(local soft attention)模型。輸入序列的位置可以直接設定(單調對齊)或通過預測函式(預測對齊)學習。因此,local attention 的優點是在 soft-attention 和 hard-attention 、計算效率和視窗內的可微性之間提供引數權衡。
Number of representations
通常,大多數應用程式都使用輸入序列的單一特徵表示。然後,在某些場景中,使用輸入的一個特徵表示可能無法滿足下游任務。在這種情況下,一般會通過多個特徵表示來捕獲輸入的不同方面。attention 機制可以用於將重要性權重分配給這些不同的表示,這些表示可以確定最相關的方面,而忽略輸入中的噪聲和冗餘。我們將這種模型稱為 multi representational AM,因此它可以確定下游應用的輸入的多個表示的相關性。最終表示形式是這些多個表示形式及其注意權重的加權組合。attention 機制的一個好處是通過檢查權重可以直接評估哪些嵌入更適合哪些特定的下游任務。例如,Kiela6等人通過學習相同輸入句子的不同單詞嵌入的注意權重,以改善句子表示。
基於相似的直覺,在 multi-dimensional 注意中,可以引入權重來確定輸入嵌入向量的每個維度的相關性。因為計算向量的每個特徵的得分可以選擇能夠在任何給定的上下文中最好地描述標記的特定含義的特徵。這對於自然語言應用程式來說尤其有用,因為在自然語言應用程式中,word 嵌入會存在一詞多義的問題。
注意力網路架構
文獻介紹了三個主要與 attention 機制進行結合的神經網路架構:(1)encoder-decoder 架構;(2)將注意力擴充套件到單個輸入序列之外的記憶體網路(memort networks);(3)利用注意力繞過遞迴模型的順序處理元件的體系結構。
Encoder-Decoder
注意力機制的早期使用是作為基於 RNN 的 encoder-decoder 架構的一部分來對長的輸入語句進行編碼。
一個有趣的事實是,Attention Model 可以採用任何輸入表示,並將其減少為一個固定長度的上下文向量,以應用於解碼步驟。因此,它允許將輸入表示與輸出解耦。人們可以利用這個好處來引入混合編碼器 - 解碼器,最流行的就是將卷積神經網路(CNN)作為編碼器,而把 RNN 或長短期儲存器(LSTM)作為解碼器。這種型別的架構特別適用於那些多模態任務,例如影象和視訊字幕,視覺問答和語音識別。
然而,並非所有輸入和輸出都是順序資料的問題都可以用上述模式解決,例如排序和旅行商問題。文獻給出了一個指標網路的示例,可以閱讀文獻進一步瞭解。
Memory Network
像問答和聊天機器人這樣的應用程式需要能夠從事實資料庫中的資訊進行學習。網路的輸入是一個知識資料庫和一個查詢,其中存在一些事實比其他事實更與查詢相關。端到端記憶體網路通過使用一組記憶體塊儲存事實資料庫來實現這一點,並使用 attention 機制在回答查詢時在記憶體中為每個事實建立關聯模型。attention 機制通過使目標連續,並支援端到端的訓練反向傳播模型來提高計算效率。端到端記憶體網路(End-to-End Memory Networks)可以看作是 AM 的一種泛化,它不是隻在單個序列上建模注意力,而是在一個包含大量序列 (事實) 的資料庫上建模注意力。
Networks without RNNs
迴圈體系結構依賴於在編碼步驟對輸入的順序處理,這導致計算效率低,因為處理不能並行化。為此,Vaswani7 等人提出了 Transformer 架構,其中 encoder 和 decoder 由一堆具有兩個子層的相同的層組成,兩個子層分別為位置定向前饋網路層(FFN)和多抽頭自注意層(multi-head self attention)。
Position-wise FFN:輸入是順序的,要求模型利用輸入的時間方面,但是不使用捕獲該位置資訊的元件(即 RNN/CNN)。為此,轉換器中的編碼階段使用 FFN 為輸入序列的每個標記生成內容嵌入和位置編碼。
Multi-head Self-Attention:在每個子層中使用 self-attention 來關聯標記及其在相同輸入序列中的位置。此外,注意力被稱為 multi-head ,因為幾個注意力層是並行堆疊的,具有相同輸入的不同線性變換。這有助於模型捕獲輸入的各個方面,並提高其表達能力。轉換結構實現了顯著的並行處理,訓練時間短,翻譯精度高,無需任何重複的元件,具有顯著的優勢。
注意力的可解釋性
受到模型的效能以及透明度和公平性的推動,人工智慧模型的可解釋性引起了人們的極大興趣。然而,神經網路,特別是深度學習架構因其缺乏可解釋性而受到廣泛的吐槽。
從可解釋性的角度來看,建模注意力機制特別有趣,因為它允許我們直接檢查深度學習架構的內部工作。假設注意力權重的重要性與序列中每個位置的輸出的預測和輸入的特定區域的相關程度高度相關。這可以通過視覺化一組輸入和輸出對的注意權重來輕鬆實現。

注意力機制的應用
注意力模型由於其直觀性、通用性和可解釋性,已成為研究的一個活躍領域。注意力模型的變體已經被用來處理不同應用領域的獨特特徵,如總結、閱讀理解、語言建模、解析等。主要包括:
- MT:機器翻譯,使用演算法將文字或語音從一種語言翻譯成另一種語言;
- QA:問答系統,根據問題給出相應的回答;
- MD:多媒體描述,根據多媒體輸入序列,如語音、圖片和視訊等,生成自然語言文字描述;
- 文字分類:主要是使用 self-attention 來構建更有效的文件表示;
- 情感分析:在情緒分析任務中,self-attention 有助於關注對確定輸入情緒很重要的詞;
- 推薦系統:將注意力權重分配給使用者的互動專案以更有效的方式捕獲長期和短期利益。
近年來,人們的注意力以新穎的方式被利用,為研究開闢了新的途徑。一些有趣的方向包括更平滑地整合外部知識庫、訓練前嵌入和多工學習、無監督的代表性學習、稀疏性學習和原型學習,即樣本選擇。
總結
該文獻討論了描述注意力的不同方法,並試圖通過討論注意力的分類、使用注意力的關鍵神經網路體系結構和已經看到顯著影響的應用領域來概述各種技術。文獻討論了在神經網路中加入注意力是如何帶來顯著的效能提高的,通過促進可解釋性提供了對神經網路內部工作的更深入的瞭解,並通過消除輸入的順序處理提高了計算效率。
參考文獻
Neural machine translation by jointly learning to align and translate↩
Hierarchical attention networks for document classification↩
Neural machine translation by jointly learning to align and translate↩
Show, Attend and Tell: Neural Image Caption Generation with Visual Attention↩
Effective approaches to attention-based neural machine translation↩
Dynamic meta-embeddings for improved sentence representations↩
Attention is all you need↩