
flume1.9 使用者指南(中文版)
概述
Apache Flume是一個分散式,可靠且可用的系統,用於有效地從許多不同的source收集,聚合和移動大量日誌資料到集中式資料儲存。
Apache Flume的使用不僅限於日誌資料聚合。由於資料source是可定製的,因此Flume可用於傳輸大量event 資料,包括但不限於網路流量資料,社交媒體生成的資料,電子郵件訊息以及幾乎任何可能的資料source。
Apache Flume是Apache Software Foundation的頂級專案。
系統要求
- Java執行時環境 - Java 1.8或更高版本
- 記憶體 - 為source,channel或 sink 配置的記憶體
- 磁碟空間 - channel或sink配置的磁碟空間
- 目錄許可權 - agent使用的目錄的讀/寫許可權
架構
資料流模型
Flume event 被定義為具有位元組有效負載和可選字串屬性集的資料流單元。Flume agent 是一個(JVM)程序,它承載event 從外部source流向下一個目標(躍點)的元件。
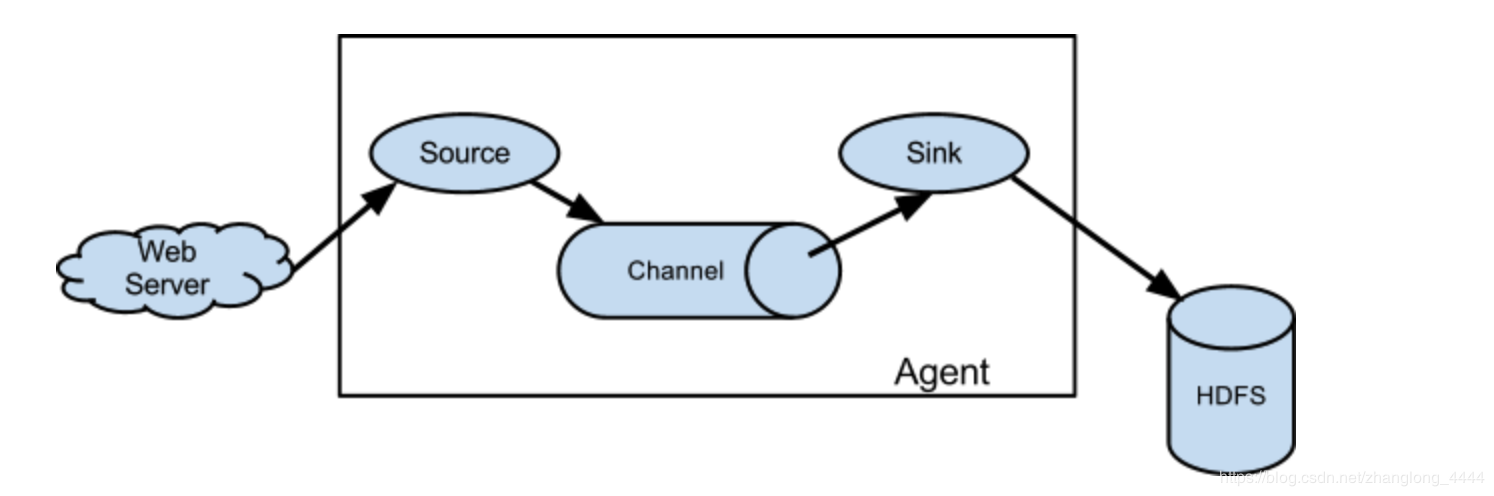 

Flume source消耗由外部 source(如Web伺服器)傳遞給它的 event 。外部source以目標Flume source識別的格式向Flume傳送event 。例如,Avro Flume source可用於從Avro客戶端或從Avrosink傳送event 的流中的其他Flume agent 接收Avroevent 。可以使用Thrift Flume Source定義類似的流程,以接收來自Thrift Sink或Flume Thrift Rpc客戶端或Thrift客戶端的event ,這些客戶端使用Flume thrift協議生成的任何語言編寫。當Flume source接收event 時,它將其儲存到一個或多個channels 。該channel是一個被動儲存器,可以保持event 直到它被Flume sink消耗。檔案channel就是一個例子 - 它由本地檔案系統支援。sink從channel中移除event 並將其放入外部儲存庫(如HDFS(通過Flume HDFS sink))或將其轉發到流中下一個Flume agent (下一跳)的Flume source。給定 agent 中的source和sink與channel中暫存的event 非同步執行。
複雜的流程
Flume允許使用者構建多跳流,其中event 在到達最終目的地之前經過多個 agent 。它還允許fan-in 和fan-out,上下文路由和故障跳躍的備份路由(故障轉移)。
可靠性
event 在每個 agent 的channel中進行。然後將event 傳遞到流中的下一個 agent 或終端儲存庫(如HDFS)。只有將event 儲存在下一個 agent 的channel或終端儲存庫中後,才會從channel中刪除這些event 。這就是Flume中的單跳訊息傳遞語義如何提供流的端到端可靠性。
Flume使用事務方法來保證event 的可靠傳遞。source和sink分別在事務中封裝由channel 提供的事務中放置或提供的event 的儲存/檢索。這可確保event 集在流中從一個點到另一個點可靠地傳遞。在多跳流的情況下,來自前一跳的sink和來自下一跳的source都執行其事務以確保資料安全地儲存在下一跳的channel 中。
可恢復性
event 在channel中進行,該channel管理從故障中恢復。Flume支援由本地檔案系統支援的持久檔案channel。還有一個記憶體channel,它只是將event 儲存在記憶體中的佇列中,這更快,但是當 agent 程序死亡時仍然留在記憶體channel中的任何event 都無法恢復。
設定
設定 agent
Flume agent 配置儲存在本地配置檔案中。這是一個遵循Java屬性檔案格式的文字檔案。可以在同一配置檔案中指定一個或多個 agent 的配置。配置檔案包括 agent 中每個source,sink和channel的屬性以及它們如何連線在一起以形成資料流。
配置單個元件
流中的每個元件(source,sink或channel)都具有特定於型別和例項化的名稱,型別和屬性集。例如,Avrosource需要主機名(或IP地址)和埠號來接收資料。記憶體channel可以具有最大佇列大小(“容量”),HDFS sink需要知道檔案系統URI,建立檔案的路徑,檔案輪換頻率(“hdfs.rollInterval”)等。元件的所有此類屬性需要在託管Flume agent 的屬性檔案中設定。
將各個部分連線在一起
agent 需要知道要載入哪些元件以及它們如何連線以構成流程。這是通過列出 agent 中每個source,sink和channel的名稱,然後為每個sink和source指定連線channel來完成的。例如, agent 通過名為file-channel的檔案channel將event 從名為avroWeb的Avrosource流向HDFS sink hdfs-cluster1。配置檔案將包含這些元件的名稱和檔案channel,作為avroWebsource和hdfs-cluster1 sink的共享channel。
啟動 agent
使用名為flume-ng的shell指令碼啟動 agent 程式,該指令碼位於Flume發行版的bin目錄中。您需要在命令列上指定 agent 名稱,config目錄和配置檔案:
$ bin/flume-ng agent -n $agent_name -c conf -f conf/flume-conf.properties.template
現在, agent 將開始執行在給定屬性檔案中配置的source和sink。
一個簡單的例子
在這裡,我們給出一個示例配置檔案,描述單節點Flume部署。此配置允許使用者生成event ,然後將其記錄到控制檯。
# example.conf: A single-node Flume configuration
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost
a1.sources.r1.port = 44444
# Describe the sink
a1.sinks.k1.type = logger
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
此配置定義名為a1的單個 agent 。a1有一個監聽埠44444上的資料的source,一個緩衝記憶體中event 資料的channel,以及一個將event 資料記錄到控制檯的sink。配置檔案命名各種元件,然後描述其型別和配置引數。給定的配置檔案可能會定義幾個命名的 agent 當一個給定的Flume程序啟動時,會傳遞一個標誌,告訴它要顯示哪個命名 agent。
鑑於此配置檔案,我們可以按如下方式啟動Flume:
$ bin/flume-ng agent --conf conf --conf-file example.conf --name a1 -Dflume.root.logger=INFO,console
請注意,在完整部署中,我們通常會包含一個選項: --conf=<conf-dir> 。所述 <conf-dir> 目錄將包括一個shell 指令碼f lume-env.sh 和潛在的一個log4j的屬性檔案。在這個例子中,我們傳遞一個Java選項來強制Flume登入到控制檯,我們沒有自定義環境指令碼。
從一個單獨的終端,我們可以telnet埠44444並向Flume傳送一個event :
$ telnet localhost 44444
Trying 127.0.0.1...
Connected to localhost.localdomain (127.0.0.1).
Escape character is '^]'.
Hello world! <ENTER>
OK
原始的Flume終端將在日誌訊息中輸出event 。
12/06/19 15:32:19 INFO source.NetcatSource: Source starting
12/06/19 15:32:19 INFO source.NetcatSource: Created serverSocket:sun.nio.ch.ServerSocketChannelImpl[/127.0.0.1:44444]
12/06/19 15:32:34 INFO sink.LoggerSink: Event: { headers:{} body: 48 65 6C 6C 6F 20 77 6F 72 6C 64 21 0D Hello world!. }
恭喜 - 您已成功配置並部署了Flume agent !後續部分更詳細地介紹了 agent 配置。
在配置檔案中使用環境變數
Flume能夠替換配置中的環境變數。例如:
a1.sources = r1
a1.sources.r1.type = netcat
a1.sources.r1.bind = 0.0.0.0
a1.sources.r1.port = ${NC_PORT}
a1.sources.r1.channels = c1
注意:它目前僅適用於values ,不適用於 keys 。 (Ie. only on the “right side” of the = mark of the config lines.)
通過設定propertiesImplementation = org.apache.flume.node.EnvVarResolverProperties,可以通過 agent 程式呼叫上的Java系統屬性啟用此功能。
例如:
$ NC_PORT=44444 bin/flume-ng agent –conf conf –conf-file example.conf –name a1 -Dflume.root.logger=INFO,console -DpropertiesImplementation=org.apache.flume.node.EnvVarResolverProperties
請注意,上面只是一個示例,可以通過其他方式配置環境變數,包括在 conf/flume-env.sh.
記錄原始資料
在許多生產環境中記錄流經攝取 pipeline 的原始資料流不是所希望的行為,因為這可能導致洩漏敏感資料或安全相關配置(例如金鑰)洩漏到Flume日誌檔案。預設情況下,Flume不會記錄此類資訊。另一方面,如果資料管道被破壞,Flume將嘗試提供除錯DEBUG的線索。
除錯event 管道問題的一種方法是設定 連線到Logger Sink的附加記憶體channel,它將所有event 資料輸出到Flume日誌。但是,在某些情況下,這種方法是不夠的。
為了能夠記錄event 和配置相關的資料,除了log4j屬性外,還必須設定一些Java系統屬性。
要啟用與配置相關的日誌記錄,請設定Java系統屬性-Dorg.apache.flume.log.printconfig=true 。這可以在命令列上傳遞,也可以在flume-env.sh中的JAVA_OPTS變數中設定。
要啟用資料記錄,請 按照上述相同方式設定Java系統屬性 -Dorg.apache.flume.log.rawdata=true 。對於大多陣列件,還必須將log4j日誌記錄級別設定為DEBUG或TRACE,以使特定於event 的日誌記錄顯示在Flume日誌中。
下面是啟用配置日誌記錄和原始資料日誌記錄的示例,同時還將Log4j日誌級別設定為DEBUG以用於控制檯輸出:
$ bin/flume-ng agent --conf conf --conf-file example.conf --name a1 -Dflume.root.logger=DEBUG,console -Dorg.apache.flume.log.printconfig=true -Dorg.apache.flume.log.rawdata=true
基於Zookeeper的配置
Flume通過Zookeeper支援 agent 配置。這是一個實驗性功能。配置檔案需要在可配置字首下的Zookeeper中上傳。配置檔案儲存在Zookeeper節點資料中。以下是 agent 商a1和a2的Zookeeper節點樹的外觀
- /flume
|- /a1 [Agent config file]
|- /a2 [Agent config file]
上載配置檔案後,使用以下選項啟動 agent
$ bin/flume-ng agent –conf conf -z zkhost:2181,zkhost1:2181 -p /flume –name a1 -Dflume.root.logger=INFO,console
| Argument Name | Default | Description |
|---|---|---|
| z | – | Zookeeper連線字串。以逗號分隔的主機名列表:port |
| p | /flume | Zookeeper中的基本路徑,用於儲存 agent 配置 |
Flume擁有完全基於外掛的架構。雖然Flume附帶了許多開箱即用的 source,channels,sink,serializers 等,但許多實現都與Flume分開執行。安裝第三方外掛
雖然通過將自己的jar包新增到flume-env.sh檔案中的FLUME_CLASSPATH變數中,始終可以包含自定義Flume元件,但Flume現在支援一個名為plugins.d的特殊目錄,該目錄會自動獲取以特定格式打包的外掛。這樣可以更輕鬆地管理外掛打包問題,以及更簡單的除錯和幾類問題的故障排除,尤其是庫依賴性衝突。
目錄
該plugins.d 目錄位於 $FLUME_HOME/plugins.d 。在啟動時,flume-ng 啟動指令碼在plugins.d目錄中查詢符合以下格式的外掛,並在啟動java時將它們包含在正確的路徑中。
外掛的目錄佈局
plugins.d 中的每個外掛(子目錄)最多可以有三個子目錄:
- lib - the plugin’s jar(s)
- libext - the plugin’s dependency jar(s)
- native - any required native libraries, such as .so files
plugins.d目錄中的兩個外掛示例:
plugins.d/
plugins.d/custom-source-1/
plugins.d/custom-source-1/lib/my-source.jar
plugins.d/custom-source-1/libext/spring-core-2.5.6.jar
plugins.d/custom-source-2/
plugins.d/custom-source-2/lib/custom.jar
plugins.d/custom-source-2/native/gettext.so
資料攝取
Flume支援許多從外部來source攝取資料的機制。
RPC
Flume發行版中包含的Avro客戶端可以使用avro RPC機制將給定檔案傳送到Flume Avrosource:
$ bin/flume-ng avro-client -H localhost -p 41414 -F /usr/logs/log.10
上面的命令會將 /usr/logs/log.10 的內容傳送到監聽該埠的Flume source。
執行命令
有一個exec source執行給定的命令並消耗輸出。輸出的單“行” 即。文字後跟回車符('\ r')或換行符('\ n')或兩者一起。
網路流
Flume支援以下機制從常用日誌流型別中讀取資料,例如:
- Avro
- Thrift
- Syslog
- Netcat
設定多 agent 流程
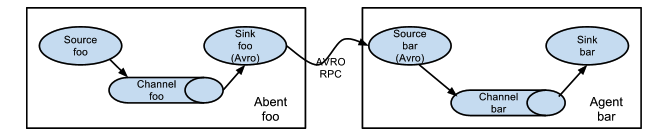 

為了跨多個 agent 或跳資料流,先前 agent 的sink和當前跳的source需要是avro型別,sink指向source的主機名(或IP地址)和埠。
合併
日誌收集中非常常見的情況是大量日誌生成客戶端將資料傳送到連線到儲存子系統的少數消費者 agent 。例如,從數百個Web伺服器收集的日誌傳送給寫入HDFS叢集的十幾個 agent 。
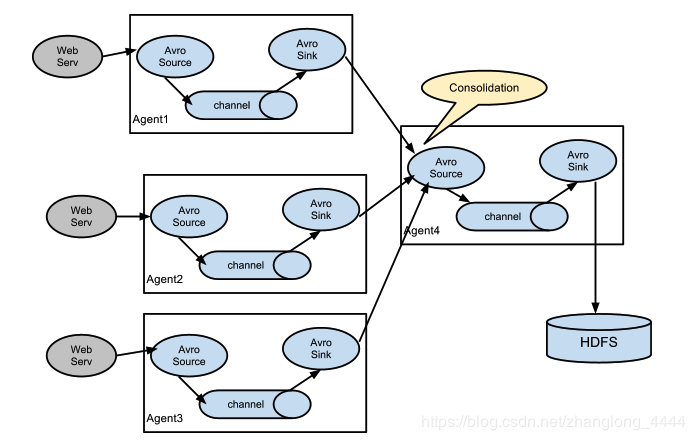 

這可以通過使用avrosink配置多個第一層 agent 在Flume中實現,所有這些 agent 都指向單個 agent 的avrosource(同樣,您可以在這種情況下使用thriftsource/sink/客戶端)。第二層 agent 上的此source將接收的event 合併到單個通道中,該通道由信宿器消耗到其最終目的地。
多路複用流程
Flume支援將event 流多路複用到一個或多個目的地。這是通過定義可以複製或選擇性地將event 路由到一個或多個通道的流複用器來實現的。
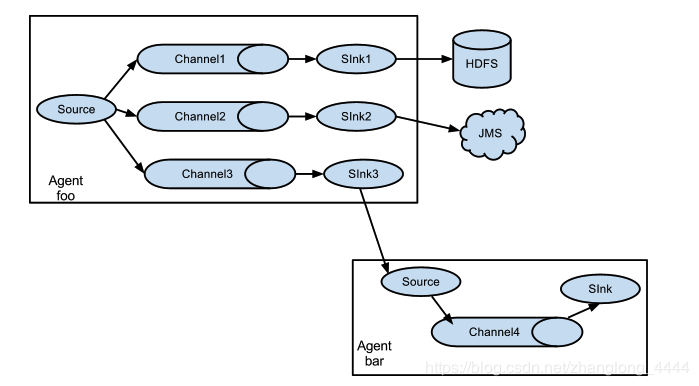 

上面的例子顯示了來自 agent “foo”的source程式碼將流程擴充套件到三個不同的channel。扇出可以複製或多路複用。在複製流的情況下,每個event 被髮送到所有三個channel。對於多路複用情況,當event 的屬性與預配置的值匹配時,event 將被傳遞到可用channel的子集。例如,如果一個名為“txnType”的event 屬性設定為“customer”,那麼它應該轉到channel1和channel3,如果它是“vendor”,那麼它應該轉到channel2,否則轉到channel3。可以在 agent 的配置檔案中設定對映。
配置
如前面部分所述,Flume agent 程式配置是從類似於具有分層屬性設定的Java屬性檔案格式的檔案中讀取的.
定義流程
要在單個 agent 中定義流,您需要通過channel連結source和sink。您需要列出給定 agent 的source,sink和channel,然後將source和sink指向channel。source例項可以指定多個channel,但sink例項只能指定一個channel。格式如下:
# list the sources, sinks and channels for the agent
<Agent>.sources = <Source>
<Agent>.sinks = <Sink>
<Agent>.channels = <Channel1> <Channel2>
# set channel for source
<Agent>.sources.<Source>.channels = <Channel1> <Channel2> ...
# set channel for sink
<Agent>.sinks.<Sink>.channel = <Channel1>
例如,名為agent_foo的 agent 正在從外部avro客戶端讀取資料並通過記憶體channel將其傳送到HDFS。
配置檔案weblog.config可能如下所示:
# list the sources, sinks and channels for the agent
agent_foo.sources = avro-appserver-src-1
agent_foo.sinks = hdfs-sink-1
agent_foo.channels = mem-channel-1
# set channel for source
agent_foo.sources.avro-appserver-src-1.channels = mem-channel-1
# set channel for sink
agent_foo.sinks.hdfs-sink-1.channel = mem-channel-1
這將使event 從avro-AppSrv-source流向hdfs-Cluster1-sink,通過記憶體channelmem-channel-1。
當使用weblog.config作為其配置檔案啟動 agent 程式時,它將例項化該流程。
配置單個元件
定義流後,您需要設定每個source,sink和channel的屬性。這是以相同的分層名稱空間方式完成的,您可以在其中設定元件型別以及特定於每個元件的屬性的其他值:
# properties for sources
<Agent>.sources.<Source>.<someProperty> = <someValue>
# properties for channels
<Agent>.channel.<Channel>.<someProperty> = <someValue>
# properties for sinks
<Agent>.sources.<Sink>.<someProperty> = <someValue>
需要為Flume的每個元件設定屬性“type”,以瞭解它需要什麼型別的物件。每個source,sink和channel型別都有自己的一組屬性,使其能夠按預期執行。所有這些都需要根據需要進行設定。在前面的示例中,我們有一個從avro-AppSrv-source到hdfs-Cluster1-sink的流程通過記憶體channelmem-channel-1。這是一個顯示每個元件配置的示例:
agent_foo.sources = avro-AppSrv-source
agent_foo.sinks = hdfs-Cluster1-sink
agent_foo.channels = mem-channel-1
# set channel for sources, sinks
# properties of avro-AppSrv-source
agent_foo.sources.avro-AppSrv-source.type = avro
agent_foo.sources.avro-AppSrv-source.bind = localhost
agent_foo.sources.avro-AppSrv-source.port = 10000
# properties of mem-channel-1
agent_foo.channels.mem-channel-1.type = memory
agent_foo.channels.mem-channel-1.capacity = 1000
agent_foo.channels.mem-channel-1.transactionCapacity = 100
# properties of hdfs-Cluster1-sink
agent_foo.sinks.hdfs-Cluster1-sink.type = hdfs
agent_foo.sinks.hdfs-Cluster1-sink.hdfs.path = hdfs://namenode/flume/webdata
#...
在 agent 中新增多個流
單個Flume agent 可以包含多個獨立流。您可以在配置中列出多個source,sink和channel。可以連結這些元件以形成多個流:
# list the sources, sinks and channels for the agent
<Agent>.sources = <Source1> <Source2>
<Agent>.sinks = <Sink1> <Sink2>
<Agent>.channels = <Channel1> <Channel2>
然後,您可以將source和sink連結到channel(用於sink)的相應channel(用於source),以設定兩個不同的流。例如,如果您需要在 agent 中設定兩個流,一個從外部avro客戶端到外部HDFS,另一個從尾部輸出到avrosink,那麼這是一個配置來執行此操作:
# list the sources, sinks and channels in the agent
agent_foo.sources = avro-AppSrv-source1 exec-tail-source2
agent_foo.sinks = hdfs-Cluster1-sink1 avro-forward-sink2
agent_foo.channels = mem-channel-1 file-channel-2
# flow #1 configuration
agent_foo.sources.avro-AppSrv-source1.channels = mem-channel-1
agent_foo.sinks.hdfs-Cluster1-sink1.channel = mem-channel-1
# flow #2 configuration
agent_foo.sources.exec-tail-source2.channels = file-channel-2
agent_foo.sinks.avro-forward-sink2.channel = file-channel-2
配置多 agent 流程
要設定多層流,您需要有 sink 指向下一跳的 avro/thrift source。這將導致第一個Flume agent 將event 轉發到下一個Flume agent 。例如,如果您使用avro客戶端定期向本地Flume agent 傳送檔案(每個event 1個檔案),則此本地 agent 可以將其轉發到另一個已安裝儲存的 agent
Weblog agent 配置:
# list sources, sinks and channels in the agent
agent_foo.sources = avro-AppSrv-source
agent_foo.sinks = avro-forward-sink
agent_foo.channels = file-channel
# define the flow
agent_foo.sources.avro-AppSrv-source.channels = file-channel
agent_foo.sinks.avro-forward-sink.channel = file-channel
# avro sink properties
agent_foo.sinks.avro-forward-sink.type = avro
agent_foo.sinks.avro-forward-sink.hostname = 10.1.1.100
agent_foo.sinks.avro-forward-sink.port = 10000
# configure other pieces
#...
HDFS agent 配置:
# list sources, sinks and channels in the agent
agent_foo.sources = avro-collection-source
agent_foo.sinks = hdfs-sink
agent_foo.channels = mem-channel
# define the flow
agent_foo.sources.avro-collection-source.channels = mem-channel
agent_foo.sinks.hdfs-sink.channel = mem-channel
# avro source properties
agent_foo.sources.avro-collection-source.type = avro
agent_foo.sources.avro-collection-source.bind = 10.1.1.100
agent_foo.sources.avro-collection-source.port = 10000
# configure other pieces
#...
在這裡,我們將weblog agent 的avro-forward-sink連結到hdfs agent 的avro-collection-source。這將導致來自外部應用程式伺服器source的event 最終儲存在HDFS中。
扇出流量
如前一節所述,Flume支援扇出從一個source到多個channel的流量。扇出有兩種模式 : 複製和多路複用。在複製流程中,event 將傳送到所有已配置的channel。在多路複用的情況下,event 僅被髮送到合格 channels 的子集。為了散開流量,需要指定source的channel列表以及扇出它的策略。這是通過新增可以複製或多路複用的channel“選擇器”來完成的。如果它是多路複用器,則進一步指定選擇規則。如果您沒有指定選擇器,那麼預設情況下它會複製:
# List the sources, sinks and channels for the agent
<Agent>.sources = <Source1>
<Agent>.sinks = <Sink1> <Sink2>
<Agent>.channels = <Channel1> <Channel2>
# set list of channels for source (separated by space)
<Agent>.sources.<Source1>.channels = <Channel1> <Channel2>
# set channel for sinks
<Agent>.sinks.<Sink1>.channel = <Channel1>
<Agent>.sinks.<Sink2>.channel = <Channel2>
<Agent>.sources.<Source1>.selector.type = replicating
多路複用選擇具有另一組屬性以分流流。這需要指定event 屬性到channel集的對映。選擇器檢查event 頭中的每個已配置屬性。如果它與指定的值匹配,則該event 將傳送到對映到該值的所有channel。如果沒有匹配項,則將event 傳送到配置為預設值的channel集:
# Mapping for multiplexing selector
<Agent>.sources.<Source1>.selector.type = multiplexing
<Agent>.sources.<Source1>.selector.header = <someHeader>
<Agent>.sources.<Source1>.selector.mapping.<Value1> = <Channel1>
<Agent>.sources.<Source1>.selector.mapping.<Value2> = <Channel1> <Channel2>
<Agent>.sources.<Source1>.selector.mapping.<Value3> = <Channel2>
#...
<Agent>.sources.<Source1>.selector.default = <Channel2>
對映允許為每個值重疊channel。
以下示例具有多路複用到兩個路徑的單個流。名為agent_foo的 agent 具有單個avrosource和兩個連結到兩個sink的channel:
# list the sources, sinks and channels in the agent
agent_foo.sources = avro-AppSrv-source1
agent_foo.sinks = hdfs-Cluster1-sink1 avro-forward-sink2
agent_foo.channels = mem-channel-1 file-channel-2
# set channels for source
agent_foo.sources.avro-AppSrv-source1.channels = mem-channel-1 file-channel-2
# set channel for sinks
agent_foo.sinks.hdfs-Cluster1-sink1.channel = mem-channel-1
agent_foo.sinks.avro-forward-sink2.channel = file-channel-2
# channel selector configuration
agent_foo.sources.avro-AppSrv-source1.selector.type = multiplexing
agent_foo.sources.avro-AppSrv-source1.selector.header = State
agent_foo.sources.avro-AppSrv-source1.selector.mapping.CA = mem-channel-1
agent_foo.sources.avro-AppSrv-source1.selector.mapping.AZ = file-channel-2
agent_foo.sources.avro-AppSrv-source1.selector.mapping.NY = mem-channel-1 file-channel-2
agent_foo.sources.avro-AppSrv-source1.selector.default = mem-channel-1
選擇器檢查名為“State”的標頭。如果該值為“CA”,則將其傳送到mem-channel-1,如果其為“AZ”,則將其傳送到檔案channel-2,或者如果其為“NY”則為兩者。如果“狀態”標題未設定或與三者中的任何一個都不匹配,則它將轉到mem-channel-1,其被指定為“default”。
選擇器還支援可選channel。要為標頭指定可選channel,可通過以下方式使用config引數“optional”:
# channel selector configuration
agent_foo.sources.avro-AppSrv-source1.selector.type = multiplexing
agent_foo.sources.avro-AppSrv-source1.selector.header = State
agent_foo.sources.avro-AppSrv-source1.selector.mapping.CA = mem-channel-1
agent_foo.sources.avro-AppSrv-source1.selector.mapping.AZ = file-channel-2
agent_foo.sources.avro-AppSrv-source1.selector.mapping.NY = mem-channel-1 file-channel-2
agent_foo.sources.avro-AppSrv-source1.selector.optional.CA = mem-channel-1 file-channel-2
agent_foo.sources.avro-AppSrv-source1.selector.mapping.AZ = file-channel-2
agent_foo.sources.avro-AppSrv-source1.selector.default = mem-channel-1
選擇器將首先嚐試寫入所需的channel,如果其中一個channel無法使用event ,則會使事務失敗。在所有渠道上重新嘗試交易。一旦所有必需的channel消耗了event ,則選擇器將嘗試寫入可選channel。任何可選channel使用該event 的失敗都會被忽略而不會重試。
如果可選通道與特定報頭的所需通道之間存在重疊,則認為該通道是必需的,並且通道中的故障將導致重試所有必需通道集。例如,在上面的示例中,對於標題“CA”,mem-channel-1被認為是必需的channel,即使它被標記為必需和可選,並且寫入此channel的失敗將導致該event 在為選擇器配置的所有channel上重試。
請注意,如果標頭沒有任何所需的channel,則該event 將被寫入預設channel,並將嘗試寫入該標頭的可選channel。如果未指定所需的channel,則指定可選channel仍會將event 寫入預設channel。如果沒有將channel指定為預設channel且沒有必需channel,則選擇器將嘗試將event 寫入可選channel。在這種情況下,任何失敗都會被忽略。
支援
多個Flume元件支援SSL / TLS協議,以便安全地與其他系統通訊。
| Component | SSL server or client |
|---|---|
| Avro Source | server |
| Avro Sink | client |
| Thrift Source | server |
| Thrift Sink | client |
| Kafka Source | client |
| Kafka Channel | client |
| Kafka Sink | client |
| HTTP Source | server |
| JMS Source | client |
| Syslog TCP Source | server |
| Multiport Syslog TCP Source | server |
SSL相容元件具有若干配置引數來設定SSL,例如啟用SSL標誌,金鑰庫/信任庫引數(位置,密碼,型別)和其他SSL引數(例如禁用的協議)
始終在 agent 配置檔案的元件級別指定為元件啟用SSL。因此,某些元件可能配置為使用SSL,而其他元件則不配置(即使具有相同的元件型別)
金鑰庫/信任庫設定可以在元件級別或全域性指定。
在元件級別設定的情況下,通過元件特定引數在 agent 配置檔案中配置金鑰庫/信任庫。此方法的優點是元件可以使用不同的金鑰庫(如果需要)。缺點是必須為 agent 配置檔案中的每個元件複製金鑰庫引數。元件級別設定是可選的,但如果已定義,則其優先順序高於全域性引數。
使用全域性設定,只需定義一次金鑰庫/信任庫引數,並對所有元件使用相同的設定,這意味著更少和更集中的配置。
可以通過系統屬性或通過環境變數來配置全域性設定。
| 系統屬性 | 環境變數 | 描述 |
|---|---|---|
| javax.net.ssl.keyStore | FLUME_SSL_KEYSTORE_PATH | 金鑰庫位置 |
| javax.net.ssl.keyStorePassword | FLUME_SSL_KEYSTORE_PASSWORD | 金鑰庫密碼 |
| javax.net.ssl.keyStoreType | FLUME_SSL_KEYSTORE_TYPE | 金鑰庫型別(預設為JKS) |
| javax.net.ssl.trustStore | FLUME_SSL_TRUSTSTORE_PATH | 信任庫位置 |
| javax.net.ssl.trustStorePassword | FLUME_SSL_TRUSTSTORE_PASSWORD | 信任庫密碼 |
| javax.net.ssl.trustStoreType | FLUME_SSL_TRUSTSTORE_TYPE | 信任庫型別(預設為JKS) |
| flume.ssl.include.protocols | FLUME_SSL_INCLUDE_PROTOCOLS | 計算啟用的協議時要包括的協議。逗號(,)分隔列表。如果提供,排除的協議將從此列表中排除。 |
| flume.ssl.exclude.protocols | FLUME_SSL_EXCLUDE_PROTOCOLS | 計算啟用的協議時要排除的協議。逗號(,)分隔列表。 |
| flume.ssl.include.cipherSuites | FLUME_SSL_INCLUDE_CIPHERSUITES | 在計算啟用的密碼套件時包含的密碼套件。逗號(,)分隔列表。如果提供,排除的密碼套件將被排除在此列表之外。 |
| flume.ssl.exclude.cipherSuites | FLUME_SSL_EXCLUDE_CIPHERSUITES | 在計算啟用的密碼套件時要排除的密碼套件。逗號(,)分隔列表。 |
可以在命令列上傳遞SSL系統屬性,也可以在conf / flume-env.sh中設定JAVA_OPTS環境變數(儘管使用命令列是不可取的,因為包含密碼的命令將儲存到命令歷史記錄中。)
export JAVA_OPTS="$JAVA_OPTS -Djavax.net.ssl.keyStore=/path/to/keystore.jks"
export JAVA_OPTS="$JAVA_OPTS -Djavax.net.ssl.keyStorePassword=password"
Flume使用JSSE(Java安全套接字擴充套件)中定義的系統屬性,因此這是設定SSL的標準方法。另一方面,在系統屬性中指定密碼意味著可以在程序列表中看到密碼。對於不可接受的情況,也可以在環境變數中定義引數。在這種情況下,Flume在內部從相應的環境變數初始化JSSE系統屬性。
SSL環境變數可以在啟動Flume之前在shell環境中設定,也可以在conf / flume-env.sh中設定(儘管使用命令列是不可取的,因為包含密碼的命令將儲存到命令歷史記錄中。)
export FLUME_SSL_KEYSTORE_PATH=/path/to/keystore.jks
export FLUME_SSL_KEYSTORE_PASSWORD=password
** 請注意:**
- 必須在元件級別啟用SSL。僅指定全域性SSL引數不會產生任何影響。
- 如果在多個級別指定全域性SSL引數,則優先順序如下(從高到低):
- agent 配置中的元件引數
- 系統屬性
- 環境變數
- 如果為元件啟用了SSL,但未以上述任何方式指定SSL引數,則
- 在金鑰庫的情況下:配置錯誤
- 在truststores的情況下:將使用預設信任庫(Oracle JDK中的jssecacerts / cacerts)
- 在所有情況下,可信任密碼都是可選的。如果未指定,則在JDK開啟信任庫時,不會對信任庫執行完整性檢查。
source 和接收批量大小和channel事務容量
source和sink可以具有批量大小引數,該引數確定它們在一個批次中處理的最大event 數。這發生在具有稱為事務容量的上限的channel事務中。批量大小必須小於渠道的交易容量。有一個明確的檢查,以防止不相容的設定。只要讀取配置,就會進行此檢查。
Flume Source
Avro Source
監聽Avro埠並從外部Avro客戶端流接收event 。當與另一個(上一跳)Flume agent 上的內建Avro Sink配對時,它可以建立分層集合拓撲。必需屬性以粗體顯示
| 屬性名稱 | 預設 | 描述 |
|---|---|---|
| channels | - | |
| type | - | 元件型別名稱,需要是avro |
| bind | - | 要偵聽的主機名或IP地址 |
| port | - | 要繫結的埠號 |
| threads | - | 生成的最大工作執行緒數 |
| selector.type | ||
| selector.* | ||
| interceptors | - | 以空格分隔的攔截器列表 |
| interceptors.* | ||
| compression-type | none | 這可以是“none”或“deflate”。壓縮型別必須與匹配AvroSource的壓縮型別匹配 |
| SSL | false | 將其設定為true以啟用SSL加密。如果啟用了SSL,則還必須通過元件級引數(請參閱下文)或全域性SSL引數(請參閱SSL / TLS支援部分)指定“金鑰庫”和“金鑰庫密碼” 。 |
| keysore | - | 這是Java金鑰庫檔案的路徑。如果未在此處指定,則將使用全域性金鑰庫(如果已定義,則配置錯誤)。 |
| keystore-password | - | Java金鑰庫的密碼。如果未在此處指定,則將使用全域性金鑰庫密碼(如果已定義,則配置錯誤)。 |
| keystore-type | JKS | Java金鑰庫的型別。這可以是“JKS”或“PKCS12”。如果未在此處指定,則將使用全域性金鑰庫型別(如果已定義,則預設為JKS)。 |
| exclude-protocols | SSLv3 | 要排除的以空格分隔的SSL / TLS協議列表。除指定的協議外,將始終排除SSLv3。 |
| include-protocols | - | 要包含的以空格分隔的SSL / TLS協議列表。啟用的協議將是包含的協議,沒有排除的協議。如果包含協議為空,則它包括每個支援的協議。 |
| exclude-cipher-suites | - | 要排除的以空格分隔的密碼套件列表。 |
| include-cipher-suites | - | 以空格分隔的密碼套件列表。啟用的密碼套件將是包含的密碼套件,不包括排除的密碼套件。如果included-cipher-suites為空,則包含每個支援的密碼套件。 |
| ipFilter | false | 將此設定為true以啟用ipFiltering for netty |
| ipFilterRules | - | 使用此配置定義N netty ipFilter模式規則。 |
agent 名為a1的示例:
a1.sources = r1
a1.channels = c1
a1.sources.r1.type = avro
a1.sources.r1.channels = c1
a1.sources.r1.bind = 0.0.0.0
a1.sources.r1.port = 4141
ipFilterRules的示例
ipFilterRules定義由逗號分隔的N個netty ipFilters模式規則必須採用此格式。
<’allow’ or deny>:<’ip’ or ‘name’ for computer name>:<pattern> or allow/deny:ip/name:pattern
example: ipFilterRules=allow:ip:127.*,allow:name:localhost,deny:ip:*
請注意,匹配的第一個規則將適用,如下例所示,來自localhost上的客戶端
這將允許localhost上的客戶端拒絕來自任何其他ip的客戶端“allow:name:localhost,deny:ip:這將拒絕localhost上的客戶端允許來自任何其他ip的客戶端“deny:name:localhost,allow:ip:
Thrift Source
偵聽Thrift埠並從外部Thrift客戶端流接收event 。當與另一個(上一跳)Flume agent 上的內建ThriftSink配對時,它可以建立分層集合拓撲。可以通過啟用kerberos身份驗證將Thriftsource配置為以安全模式啟動。agent-principal和agent-keytab是Thriftsource用於向kerberos KDC進行身份驗證的屬性。必需屬性以粗體顯示
| 屬性名稱 | 預設 | 描述 |
|---|---|---|
| channels | - | |
| type | - | 元件型別名稱,需要節儉 |
| bind | - | 要偵聽的主機名或IP地址 |
| port | - | 要繫結的埠號 |
| threads | - | 生成的最大工作執行緒數 |
| selector.type | ||
| selector.* | ||
| interceptors | - | 空格分隔的攔截器列表 |
| interceptors.* | ||
| SSL | false | 將其設定為true以啟用SSL加密。如果啟用了SSL,則還必須通過元件級引數(請參閱下文)或全域性SSL引數(請參閱SSL / TLS支援部分)指定“金鑰庫”和“金鑰庫密碼”。 |
| keystore | - | 這是Java金鑰庫檔案的路徑。如果未在此處指定,則將使用全域性金鑰庫(如果已定義,則配置錯誤)。 |
| keystore-password | - | Java金鑰庫的密碼。如果未在此處指定,則將使用全域性金鑰庫密碼(如果已定義,則配置錯誤)。 |
| keystore-type | JKS | Java金鑰庫的型別。這可以是“JKS”或“PKCS12”。如果未在此處指定,則將使用全域性金鑰庫型別(如果已定義,則預設為JKS)。 |
| exclude-protocols | 要排除的以空格分隔的SSL / TLS協議列表。除指定的協議外,將始終排除SSLv3。 | |
| include-protocols | - | 要包含的以空格分隔的SSL / TLS協議列表。啟用的協議將是包含的協議,沒有排除的協議。如果包含協議為空,則它包括每個支援的協議。 |
| exclude-cipher-suites | - | 要排除的以空格分隔的密碼套件列表。 |
| include-cipher-suites | - | 以空格分隔的密碼套件列表。啟用的密碼套件將是包含的密碼套件,不包括排除的密碼套件。 |
| kerberos | 設定為true以啟用kerberos身份驗證。在kerberos模式下,成功進行身份驗證需要agent-principal和agent-keytab。安全模式下的Thriftsource僅接受來自已啟用kerberos且已成功通過kerberos KDC驗證的Thrift客戶端的連線。 | |
| agent-principal | - | Thrift Source使用的kerberos主體對kerberos KDC進行身份驗證。 |
| agent-keytab | - | Thrift Source與 agent 主體結合使用的keytab位置,用於對kerberos KDC進行身份驗證。 |
agent 名為a1的示例:
a1.sources = r1
a1.channels = c1
a1.sources.r1.type = thrift
a1.sources.r1.channels = c1
a1.sources.r1.bind = 0.0.0.0
a1.sources.r1.port = 4141
Exec Source
Exec source在啟動時執行給定的Unix命令,並期望該程序在標準輸出上連續生成資料(stderr被簡單地丟棄,除非屬性logStdErr設定為true)。如果程序因任何原因退出,則source也會退出並且不會生成其他資料。這意味著cat [named pipe] 或tail -F [file]等配置將產生所需的結果,而日期 可能不會 - 前兩個命令產生資料流,而後者產生單個event 並退出。必需屬性以粗體顯示
| 屬性名稱 | 預設 | 描述 |
|---|---|---|
| channels | - | |
| type | - | 元件型別名稱,需要是exec |
| command | - | 要執行的命令 |
| shell | - | 用於執行命令的shell呼叫。例如 /bin/sh -c 。僅適用於依賴shell功能的命令,如萬用字元,後退標記,管道等。 |
| restartThrottle | 10000 | 嘗試重新啟動之前等待的時間(以毫秒為單位) |
| restart | false | 是否應該重新執行已執行的cmd |
| logStdErr | false | 是否應記錄命令的stderr |
| BATCHSIZE | 20 | 一次讀取和傳送到channel的最大行數 |
| batchTimeout | 3000 | 在向下遊推送資料之前,如果未達到緩衝區大小,則等待的時間(以毫秒為單位) |
| selector.type | replication | 複製或多路複用 |
| selector.* | 取決於selector.type值 | |
| interceptors | - | 以空格分隔的攔截器列表 |
| interceptors.* |
警告
Exec Source和其他非同步source的問題在於,如果無法將event 放入Channel中,則source無法保證客戶端知道它。在這種情況下,資料將丟失。例如,最常請求的功能之一是 tail -F [file] 類似用例,其中應用程式寫入磁碟上的日誌檔案,Flume將檔案作為尾部發送,將每一行作為event 傳送。雖然這是可能的,但是有一個明顯的問題; 如果channel 填滿並且Flume無法傳送event ,會發生什麼?由於某種原因,Flume無法向編寫日誌檔案的應用程式指示它需要保留日誌或event 尚未傳送。如果這沒有意義,您只需要知道:當使用Exec Source等單向非同步介面時,您的應用程式永遠無法保證已收到資料!
作為此警告的延伸 - 並且完全清楚 - 使用此source時,event 傳遞絕對沒有保證。
為了獲得更強的可靠性保證,請考慮Spooling Directory Source,Taildir Source或通過SDK直接與Flume整合。
agent 名為a1的示例:
a1.sources = r1
a1.channels = c1
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /var/log/secure
a1.sources.r1.channels = c1
'shell'配置用於通過命令shell(例如Bash或Powershell)呼叫'命令'。'command'作為引數傳遞給'shell'執行。這允許'命令'使用shell中的功能,例如萬用字元,後退標記,管道,迴圈,條件等。如果沒有'shell'配置,將直接呼叫'command'。'shell'的常用值: ‘/bin/sh -c’, ‘/bin/ksh -c’, ‘cmd /c’, ‘powershell -Command’, etc.
a1.sources.tailsource-1.type = exec
a1.sources.tailsource-1.shell = /bin/bash -c
a1.sources.tailsource-1.command = for i in /path/*.txt; do cat $i; done
JMS Source
JMS Source從JMS目標(例如佇列或主題)讀取訊息。作為JMS應用程式,它應該與任何JMS提供程式一起使用,但僅使用ActiveMQ進行測試。JMSsource提供可配置的批量大小,訊息選擇器,使用者/傳遞和訊息到水槽event 轉換器。請注意,供應商提供的JMS jar應該包含在Flume類路徑中,使用plugins.d目錄(首選),命令列上的-classpath或flume-env.sh中的FLUME_CLASSPATH變數。必需屬性以粗體顯示
| 屬性名稱 | 預設 | 描述 |
|---|---|---|
| channels | - | |
| type | - | 元件型別名稱,需要是jms |
| initialContextFactory | - | Inital Context Factory,例如:org.apache.activemq.jndi.ActiveMQInitialContextFactory |
| connectionFactory | - | 連線工廠應顯示為的JNDI名稱 |
| providerURL | - | JMS提供程式URL |
| destinationName | - | 目的地名稱 |
| destinationType | - | 目的地型別(佇列或主題) |
| messageSelector | - | 建立使用者時使用的訊息選擇器 |
| userName | - | 目標/提供商的使用者名稱 |
| PASSWORDFILE | - | 包含目標/提供程式密碼的檔案 |
| BATCHSIZE | 100 | 一批中要使用的訊息數 |
| converter.type | DEFAULT | 用於將訊息轉換為水槽event 的類。見下文。 |
| converter.* | - | 轉換器屬性。 |
| converter.charset | UTF-8 | 僅限預設轉換器。在將JMS TextMessages轉換為位元組陣列時使用的字符集。 |
| createDurableSubscription | false | 是否建立持久訂閱。持久訂閱只能與destinationType主題一起使用。如果為true,則必須指定“clientId”和“durableSubscriptionName”。 |
| clientId | - | JMS客戶端識別符號在建立後立即在Connection上設定。持久訂閱必需。 |
| durableSubscriptionName | - | 用於標識持久訂閱的名稱。持久訂閱必需。 |
訊息轉換器
JMSsource允許可插拔轉換器,儘管預設轉換器可能適用於大多數用途。預設轉換器能夠將位元組,文字和物件訊息轉換為FlumeEvents。在所有情況下,訊息中的屬性都將作為標題新增到FlumeEvent中。
BytesMessage:
訊息的位元組被複制到FlumeEvent的主體。每封郵件無法轉換超過2GB的資料。
TextMessage的:
訊息文字轉換為位元組陣列並複製到FlumeEvent的主體。預設轉換器預設使用UTF-8,但這是可配置的。
ObjectMessage:
Object被寫入包含在ObjectOutputStream中的ByteArrayOutputStream,並將生成的陣列複製到FlumeEvent的主體。
agent 名為a1的示例:
a1.sources = r1
a1.channels = c1
a1.sources.r1.type = jms
a1.sources.r1.channels = c1
a1.sources.r1.initialContextFactory = org.apache.activemq.jndi.ActiveMQInitialContextFactory
a1.sources.r1.connectionFactory = GenericConnectionFactory
a1.sources.r1.providerURL = tcp://mqserver:61616
a1.sources.r1.destinationName = BUSINESS_DATA
a1.sources.r1.destinationType = QUEUE
SSL 和 JMS Source
JMS客戶端實現通常支援通過JSSE(Java安全套接字擴充套件)定義的某些Java系統屬性來配置SSL / TLS。為Flume的JVM指定這些系統屬性,JMSsource(或更準確地說是JMSsource使用的JMS客戶端實現)可以通過SSL連線到JMS伺服器(當然,僅當JMS伺服器也已設定為使用SSL時)。它應該可以與任何JMS提供程式一起使用,並且已經過ActiveMQ,IBM MQ和Oracle WebLogic的測試。
以下部分僅介紹Flume方面所需的SSL配置步驟。您可以在Flume Wiki上找到有關不同JMS提供程式的伺服器端設定以及完整工作配置示例的更詳細說明。
** SSL 傳輸/伺服器身份驗證:**
如果JMS伺服器使用自簽名證書或其證書由不受信任的CA(例如公司自己的CA)簽名,則需要設定信任庫(包含正確的證書)並傳遞給Flume。它可以通過全域性SSL引數完成。有關全域性SSL設定的更多詳細資訊,請參閱SSL / TLS支援部分。
使用SSL時,某些JMS提供程式需要SSL特定的JNDI初始上下文工廠和/或提供程式URL設定(例如,ActiveMQ使用ssl:// URL字首而不是tcp://)。在這種情況下,必須在 agent 配置檔案中調整source屬性(initialContextFactory和/或providerURL)
客戶端證書身份驗證(雙向SSL):
JMS Source可以通過客戶端證書身份驗證而不是通常的使用者/密碼登入來對JMS伺服器進行身份驗證(使用SSL並且JMS伺服器配置為接受此類身份驗證時)。
包含用於身份驗證的Flume金鑰的金鑰庫需要再次通過全域性SSL引數進行配置。有關全域性SSL設定的更多詳細資訊,請參閱SSL / TLS支援部分。
金鑰庫應該只包含一個金鑰(如果存在多個金鑰,則將使用第一個金鑰)。金鑰密碼必須與金鑰庫密碼相同。
在客戶端證書身份驗證的情況下,不需要在Flume agent 配置檔案中為JMSsource指定userName / passwordFile屬性。
請注意:
與其他元件不同,JMS Source沒有元件級別的配置引數。也沒有啟用SSL標誌。SSL設定由JNDI / Provider URL設定(最終是JMS伺服器設定)以及truststore / keystore的存在/不存在控制。
Spooling Directory Source
此source允許您通過將要攝取的檔案放入磁碟上的“spooling ”目錄來攝取資料。此source將檢視新檔案的指定目錄,並將在新檔案出現時解析event 。event 解析邏輯是可插入的。在給定檔案完全讀入channel後,預設情況下通過重新命名檔案來指示完成,或者可以刪除它或使用trackerDir來跟蹤已處理的檔案。
與Exec source不同,即使Flume重新啟動或被殺死,此source也是可靠的並且不會遺漏資料。作為這種可靠性的交換,只有不可變的,唯一命名的檔案必須被放入spooling directory.中。Flume試圖檢測這些問題,如果違反則會宣告失敗:
- 如果在放入 spooling directory 後寫入檔案,Flume會將錯誤列印到其日誌檔案並停止處理。
- 如果稍後重複使用檔名,Flume將在其日誌檔案中輸出錯誤並停止處理。
為避免上述問題,在將檔名移動到 spooling directory 中時,新增唯一識別符號(例如時間戳)可能很有用。
儘管該source的可靠性保證,但仍存在如果發生某些下游故障則可能重複event 的情況。這與其他Flume元件提供的保證一致。
| 屬性名稱 | 預設 | 描述 |
|---|---|---|
| channels | - | |
| type | - | 元件型別名稱需要是spooldir。 |
| spoolDir | - | 從中讀取檔案的目錄。 |
| fileSuffix | .COMPLETED | 字尾附加到完全攝取的檔案 |
| deletePolicy | never | 何時刪除已完成的檔案:從never 或 immediate |
| FileHeader | false | 是否新增儲存絕對路徑檔名的標頭。 |
| fileHeaderKey | file | 將絕對路徑檔名附加到event 標題時使用的標題鍵。 |
| basenameHeader | false | 是否新增儲存檔案基本名稱的標頭。 |
| basenameHeaderKey | basename | 標題將檔案的基本名稱附加到event 標題時使用的標題。 |
| includePattern | .*$ | 正則表示式,指定要包含的檔案。它可以與ignorePattern一起使用。如果一個檔案同時匹配ignorePattern和includePattern正則表示式,該檔案將被忽略。 |
| ignorePattern | $ | 正則表示式,指定要忽略的檔案(跳過)。它可以與includePattern一起使用。如果一個檔案同時匹配ignorePattern和includePattern正則表示式,該檔案將被忽略。 |
| trackerDir | .flumespool | 用於儲存與檔案處理相關的元資料的目錄。如果此路徑不是絕對路徑,則將其解釋為相對於spoolDir。 |
| trackingPolicy | rename | 跟蹤策略定義如何跟蹤檔案處理。它可以是“重rename”或“tracker_dir”。此引數僅在deletePolicy為“never”時有效。“重rename” - 處理完檔案後,會根據fileSuffix引數重新命名。“tracker_dir” - 不重新命名檔案,但會在trackerDir中建立新的空檔案。新的跟蹤器檔名source自攝取的檔名和fileSuffix。 |
| consumeOrder | oldest | spooling directory 中的檔案將以 oldest, youngest和 random 的方式使用。如果是oldest和youngest的,檔案的最後修改時間將用於比較檔案。如果出現相同,將首先消耗具有最小字典順序的檔案。在 random的情況下,任何檔案將被隨機挑選。當使用oldest和youngest時,整個目錄將被掃描以選擇oldest/youngest的檔案,如果存在大量檔案,這可能會很慢,而使用random可能會導致舊檔案在新檔案不斷進入時很晚被消耗 spooling directory。 |
| pollDelay | 500 | 輪詢新檔案時使用的延遲(以毫秒為單位)。 |
| recursiveDirectorySearch | false | 是否監視子目錄以查詢要讀取的新檔案。 |
| maxBackoff | 4000 | 如果channel已滿,則在連續嘗試寫入channel之間等待的最長時間(以毫秒為單位)。source將以低退避開始,並在每次channel丟擲ChannelException時以指數方式增加,直到此引數指定的值。 |
| BATCHSIZE | 100 | 批量傳輸到channel的粒度 |
| inputCharset | UTF-8 | 反序列化器使用的字符集,將輸入檔案視為文字。 |
| decodeErrorPolicy | FAIL | 當我們在輸入檔案中看到不可解碼的字元時該怎麼辦。FAIL:丟擲異常並且無法解析檔案。 REPLACE:用“替換字元”char替換不可解析的字元,通常是Unicode U+FFFD 。 IGNORE:刪除不可解析的字元序列。 |
| deserializer | LINE | 指定用於將檔案解析為event 的反序列化程式。預設將每行解析為event 。指定的類必須實現EventDeserializer.Builder。 |
| deserializer.* | 每個event 反序列化器不同。 | |
| bufferMaxLines | - | (Obselete)此選項現在被忽略。 |
| bufferMaxLineLength | 5000 | (已棄用)提交緩衝區中行的最大長度。請改用deserializer.maxLineLength。 |
| selector.type | replicating | replicating or multiplexing |
| selector.* | 取決於selector.type值 | |
| interceptors | - | 以空格分隔的攔截器列表 |
| interceptors.* |
名為agent-1的 agent 示例:
a1.channels = ch-1
a1.sources = src-1
a1.sources.src-1.type = spooldir
a1.sources.src-1.channels = ch-1
a1.sources.src-1.spoolDir = /var/log/apache/flumeSpool
a1.sources.src-1.fileHeader = true
Event Deserializers
以下event 反序列化器隨Flume一起提供。
LINE
此解串器為每行文字輸入生成一個event
| 物業名稱 | 預設 | 描述 |
|---|---|---|
| deserializer.maxLineLength | 2048 | 單個event 中包含的最大字元數。如果一行超過此長度,則會被截斷,並且該行上的其餘字元將出現在後續event 中。 |
| deserializer.outputCharset | UTF-8 | 用於編碼放入channel的event 的字符集。 |
AVRO
此解串器能夠讀取Avro容器檔案,並在檔案中為每個Avro記錄生成一個event 。每個event 都使用標頭進行註釋,該標頭指示所使用的模式。event 的主體是二進位制Avro記錄資料,不包括模式或容器檔案元素的其餘部分。
請注意,如果假離線目錄source必須重試將其中一個event 放入channel(例如,因為channel已滿),則它將重置並從最新的Avro容器檔案同步點重試。為了減少此類故障情況下的潛在event 重複,請在Avro輸入檔案中更頻繁地寫入同步標記。
| 物業名稱 | 預設 | 描述 |
|---|---|---|
| deserializer.schemaType | HASH | 如何表示模式。預設情況下,或者 指定值HASH時,會對Avro架構進行雜湊處理,並將雜湊值儲存在event 頭“flume.avro.schema.hash”中的每個event 中。如果指定了LITERAL,則JSON編碼的模式本身儲存在event 頭“flume.avro.schema.literal”中的每個event 中。與HASH模式相比,使用LITERAL模式效率相對較低。 |
BlobDeserializer>
此反序列化器為每個event 讀取二進位制大物件(BLOB),通常每個檔案一個BLOB。例如PDF或JPG檔案。請注意,此方法不適用於非常大的物件,因為整個BLOB都快取在RAM中。
| 物業名稱 | 預設 | 描述 |
|---|---|---|
| 解串器 | - | 此類的FQCN:org.apache.flume.sink.solr.morphline.BlobDeserializer$Builder |
| deserializer.maxBlobLength | 100000000 | 要讀取的最大位元組數和給定請求的緩衝區 |
Taildir Source
注意: 此source作為預覽功能提供。它不適用於Windows。
觀察指定的檔案,並在檢測到新增到每個檔案的新行後幾乎實時地拖尾它們。如果正在寫入新行,則此source將重試讀取它們以等待寫入完成。
此source是可靠的,即使tail檔案旋轉也不會丟失資料。它定期以JSON格式寫入給定位置檔案上每個檔案的最後讀取位置。如果Flume由於某種原因停止或停止,它可以從寫在現有位置檔案上的位置重新開始tail。
在其他用例中,此source也可以使用給定的位置檔案從每個檔案的任意位置開始拖尾。當指定路徑上沒有位置檔案時,預設情況下它將從每個檔案的第一行開始拖尾。
檔案將按修改時間順序使用。將首先使用具有最早修改時間的檔案。
此source不會重新命名或刪除或對正在掛載的檔案執行任何修改。目前此source不支援tail二進位制檔案。它逐行讀取文字檔案。
| 屬性名稱 | 預設 | 描述 |
|---|---|---|
| channels | - | |
| type | - | 元件型別名稱,需要是TAILDIR。 |
| filegroups | - | 以空格分隔的檔案組列表。每個檔案組都指示一組要掛起的檔案。 |
| filegroups. |
- | 檔案組的絕對路徑。正則表示式(而不是檔案系統模式)只能用於檔名。 |
| positionFile | ~/.flume/taildir_position.json | 以JSON格式檔案以記錄每個尾部檔案的inode,絕對路徑和最後位置。 |
| headers. |
- | 標題值,使用標題鍵設定。可以為一個檔案組指定多個標頭。 |
| byteOffsetHeader | false | 是否將tailed line 的位元組偏移量新增到名為“byteoffset”的標頭中。 |
| skipToEnd | false | 在未寫入位置檔案的檔案的情況下是否跳過位置到EOF。 |
| idleTimeout | 120000 | 關閉非活動檔案的時間(毫秒)。如果關閉的檔案附加了新行,則此source將自動重新開啟它。 |
| writePosInterval | 3000 | 寫入位置檔案上每個檔案的最後位置的間隔時間(ms)。 |
| BATCHSIZE | 100 | 一次讀取和傳送到channel的最大行數。使用預設值通常很好。 |
| maxBatchCount | Long.MAX_VALUE | 控制從同一檔案連續讀取的批次數。如果source正在拖尾多個檔案,並且其中一個檔案以快速寫入,則可以防止處理其他檔案,因為繁忙檔案將在無限迴圈中讀取。在這種情況下,降低此值。 |
| backoffSleepIncrement | 1000 | 在最後一次嘗試未找到任何新資料時,重新嘗試輪詢新資料之前的時間延遲增量。 |
| maxBackoffSleep | 5000 | 每次重新嘗試輪詢新資料時的最大時間延遲,當最後一次嘗試未找到任何新資料時。 |
| cachePatternMatching | true | 對於包含數千個檔案的目錄,列出目錄並應用檔名正則表示式模式可能非常耗時。快取匹配檔案列表可以提高效能。消耗檔案的順序也將被快取。要求檔案系統以至少1秒的粒度跟蹤修改時間。 |
| FileHeader | false | 是否新增儲存絕對路徑檔名的標頭。 |
| fileHeaderKey | file | 將絕對路徑檔名附加到event 標題時使用的標題鍵。 |
agent 名為a1的示例:
a1.sources = r1
a1.channels = c1
a1.sources.r1.type = TAILDIR
a1.sources.r1.channels = c1
a1.sources.r1.positionFile = /var/log/flume/taildir_position.json
a1.sources.r1.filegroups = f1 f2
a1.sources.r1.filegroups.f1 = /var/log/test1/example.log
a1.sources.r1.headers.f1.headerKey1 = value1
a1.sources.r1.filegroups.f2 = /var/log/test2/.*log.*
a1.sources.r1.headers.f2.headerKey1 = value2
a1.sources.r1.headers.f2.headerKey2 = value2-2
a1.sources.r1.fileHeader = true
a1.sources.ri.maxBatchCount = 1000
Kafka Source
Kafka Source是一個Apache Kafka消費者,它從Kafka主題中讀取訊息。如果您運行了多個Kafka source,則可以使用相同的使用者組配置它們,以便每個source都讀取一組唯一的主題分割槽。這目前支援Kafka伺服器版本0.10.1.0或更高版本。測試完成了2.0.1,這是釋出時最高的可用版本。
| 屬性名稱 | 預設 | 描述 |
|---|