
同學,要不要來挑戰雙11零點流量洪峰?

阿里妹導讀:雙十一的零點,整個電商系統的請求速率到達峰值。如果將這些請求流量只分配給少部分 server,這些機器接收到的請求速率會遠超過處理速率,新來的任務來不及處理,就會產生請求任務堆積。
今年的中介軟體效能挑戰賽就圍繞“挑戰雙11零點流量洪峰”展開。自2015年開始,中介軟體效能挑戰賽已經成功舉辦了四屆,被歷年大賽選手稱為“中介軟體技術的風向標”。接下來,跟隨阿里巴巴中介軟體團隊的郭浩,一起來圍觀賽題,解讀賽題。
在現代分散式應用中,服務請求是由物理機或虛擬機器組成的 server 池進行處理的。 通常,server 池規模巨大且服務容量各不相同,受網路、記憶體、CPU、下游服務等各種因素影響,一個 server 的服務容量始終處於動態變動和趨於穩定的狀態,如何設計和實現這種系統的負載均衡演算法是一個極具挑戰的難題。
自適應負載均衡的需求背景
負載均衡有兩個主要目標:
- 保持較短的請求響應時間和較小的請求阻塞概率;
- 負載均衡演算法的 overhead 在可控級別,不佔用過多的 CPU 、網路等資源。
自適應負載均衡是指無論系統處於空閒、穩定還是繁忙狀態,負載均衡演算法都會自動評估系統的服務能力,進行合理的流量分配,使整個系統始終保持較好的效能,不產生飢餓或者過載、宕機。
這種演算法對於現在的電商系統、資料中心、雲端計算等領域都很有必要,使用自適應負載均衡能夠更合理的利用資源,提高效能。
對使用者而言,一旦產生任務堆積,請求會變慢甚至超時,體驗嚴重下降,甚至導致服務不可用。而處理請求的機器也會由於堆積的任務越來越多而發生嚴重過載,直到被打垮。剩餘的尚未宕機的其它機器會逐漸重複這個過程,直至整個應用不可用,發生系統故障。
為了避免這種情況發生,我們可能會想到一種常用的辦法:在服務上線前提前進行壓測,使用壓測的容量作為限流值,當線上服務的請求速率大於限流值的時候,服務拒絕新到的服務,從而保障服務始終可用。但是這種方式也存在問題:壓測時測試的容量進行限流通常會趨於保守,不能充分發揮異構系統的全部效能;也無法智慧地應對由於網路、下游服務變化而導致的容量下降等問題,系統仍然存在宕機風險。
因此,我們需要具備自適應能力的負載均衡演算法,來更好地進行流量分配排程以及穩定性保障,追求極致效能,挑戰大促等場景下的流量洪峰。
結合中介軟體效能挑戰賽的賽題
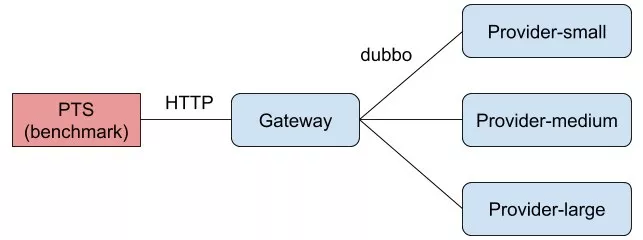
我們結合「第五屆中介軟體效能挑戰賽」中的初賽場景,來一起探討一下設計和實現一個自適應的負載均衡的基本思路。

本次挑戰賽的場景由施壓程式(阿里雲效能測試PTS)、服務呼叫方(Consumer)和三個規格不同的服務提供方(Provider) 組成。在評測過程中,每個程式都部署在不同的物理機上,以避免因 CPU、網路資源的競爭,導致評測程式抖動,影響最終評測成績。
Becnhmarker 負責請求 Consumer, Consumer 收到請求後,從三臺物理規格不同、服務響應時間和最大併發都不同的 Provider 中選擇一個進行呼叫並返回結果。選擇哪一個 Provider 進行呼叫的流程就是本次挑戰賽需要實現的負載均衡演算法。
為了簡化環境部署和提升效能,本次挑戰賽沒有使用服務註冊和發現機制。三個 Provider 對應的 URL 都已經被直接配置在了 Consumer 中,選手在開發和測試時可直接通過 Provider-small 等 hostname 訪問相應的 Provider。
賽題分析
題目描述很簡單,不考慮 Consumer 直接拒絕的情況下,場景可以簡化為 3 選 1 的問題,但如何進行這個決策則是本次挑戰賽考察的難點和重點。
官方題目組提供了 Random 演算法作為預設實現:從 3 個 Provider 中隨機取任意一個。對於單 dispatcher (在本次賽題中是 Consumer) 同構系統的場景,Random可以達到漸近負載均衡, 每個 Provider 接收到的總請求數接近。但是對於多 dispatcher 或異構系統而言,Random 演算法由於缺少全域性狀態,無法保證全域性隨機,極端條件下,多個 dispatcher 可能將請求同時分配到一臺 Provider 上,導致系統存在服務過載和宕機的風險;異構系統中,不同 Provider 服務容量實際是不同的,即使每個 Provider 請求速率相同也會產生空閒、穩定、過載等不同的服務狀態,無法實現最優流量分配,更不能做到響應時間最小。顯而易見,Random 並不是符合賽題要求的自適應演算法。
那麼,如何實現自適應負載均衡呢?接下來我們將利用題目給出的條件由淺入深的描述這個演算法的設計過程。
自適應演算法首先要解決如何對服務進行容量評估的問題。
本次比賽按照硬體規格不同,Provider 被分為 small、medium、和 large 三種,CPU 和記憶體對應的比例為 1:2:3 。在評測過程中,每個 Provider 的處理能力都會動態變化,主要體現在單次響應時間的變化和允許的最大的併發數上。來自 Consumer 的請求速率過快時, Provider 端新到的請求會排隊等待處理,當排隊執行緒數和工作執行緒數量之和達到最大執行緒數時,Provider 返回執行緒池用盡異常。在演算法的實現和調優過程中,應該儘量避免產生執行緒池異常,減少排隊。如何結合好程式和硬體的限制,區分出不同階段的瓶頸,做出符合實際的容量評估是賽題的第一個難點。對於本次題目所採用的引數和變化過程,僅憑現有的理論和實踐很難達到最優,所以需要選手充分理解題意和各引數配置,設計出更適合實際場景的演算法。
第二個需要考慮的問題是如何應用容量評估結果,即如何維護代表 Provider 服務能力的狀態,又如何在選擇 Provider 階段根據這些狀態進行決策?
傳統的單 Dispatcher 負載均衡模型由一個 Dispatcher 維護所有 Provider 的狀態,在同構系統中,這種方式能夠達到漸進最優負載均衡。但是它存在的問題也很明顯:單 Dispatcher 效能存在天然瓶頸,可擴容性較差,當 Provider 數量成倍上升時,Dispatcher 需要維護的狀態也在成倍上升,通訊成本也在上升。本次挑戰賽中為了降低難度,沒有基於多 Dispatcher 模型構建題目,但多 Dispatcher 、多 Provider 才是 Dubbo 等微服務框架在實際生產環境中最常見的情況。因此,若能實現高效能且可擴充套件性良好的均衡演算法,會是一個不錯的加分項。
第三點是輔助介面的使用。為了不限制演算法設計思路,賽題提供了多個可能用到的輔助介面,包括雙向通訊、Provider 限流等支援。但是這些介面都是非必選項,是否使用這些介面取決於演算法實現的需要。
在評測環境中,任意一個 Provider 服務處理速率都小於評測程式的請求速率。三個 Provider 總的處理速率會在請求速率上下浮動。最終成績由請求成功數和最大 TPS 組成,失敗的請求不計入成績。對於這個限制,可以有兩種解讀方式,一是為了保證服務不嚴重過載,可以適當拒絕請求。第二點是需要充分利用每個 Provider 的服務容量,保證效能最優的 Provider 請求數合理,適當的過載也是允許的。
以上僅作為一個主要的演算法設計思路,優秀的負載均衡演算法在工程上的實現也是很關鍵的一點,需要選取合適的資料結構,充分利用好記憶體和 CPU,壓榨出比賽環境的每一點效能。當然,評測成績並不代表一切,良好的程式碼結構、編碼風格以及通用性,也在最終初賽成績中佔據很大比例。
關注“阿里技術”官方公眾號,並在對話方塊內回覆“中介軟體”,即可獲得初賽賽題。
賽題評測
評測環境由 1 臺 4 核 8G 的施壓機,1 臺 4 核 8G 的閘道器機和 3 臺 4 核 8G 的 Provider組成。Consumer 和 Provider 程式都會限制 CPU 和記憶體使用,每個評測任務都會獨佔五臺機器。
- 準備跑分環境,建立並鎖定工作區;
- 根據提交的 Git 地址,從程式碼倉庫中拉取程式碼;
- 構建程式碼,生成最終執行的 fat JAR;
- 啟動三個 Provider ,並驗證服務可用性;
- 啟動 Consumer ,並驗證服務可用性;
- 對系統進行預熱,持續 30 秒;
- 正式評測 1 分鐘;
- 取正式評測的總成功請求數和最大 TPS 作為最終成績,上報天池系統;
- 按順序依次停止 Consumer、三個 Provider;
- 清理 Docker 例項及映象;
- 收集日誌並上傳到 OSS;
- 解鎖工作區,清理環境。
總結
本文結合第五屆中介軟體效能挑戰賽的賽題背景、題目場景、題目分析和評測環境與過程的角度,介紹了自適應負載均衡演算法的基本設計思路,希望對即將參加比賽的同學們能有所幫助,也歡迎更多的技術同學報名參加我們的挑戰賽,分享你在演算法方面的思考和實踐。
本文作者:郭浩,花名項升,阿里巴巴中介軟體高階開發工程師,專注於 Queueing Theory,RPC 框架和高效能分散式系統構建。
原文連結
本文為雲棲社群原創內容,未經