
Feed流系統設計-總綱
簡介
差不多十年前,隨著功能機的淘汰和智慧機的普及,網際網路開始進入移動網際網路時代,最具代表性的產品就是微博、微信,以及後來的今日頭條、快手等。這些移動化聯網時代的新產品在過去幾年間藉著智慧手機的風高速成長。
這些產品都是Feed流型別產品,由於Feed流一般是按照時間“從上往下流動”,非常適合在移動裝置端瀏覽,最終這一類應用就脫穎而出,迅速搶佔了上一代產品的市場空間。
Feed流是Feed + 流,Feed的本意是飼料,Feed流的本意就是有人一直在往一個地方投遞新鮮的飼料,如果需要飼料,只需要盯著投遞點就可以了,這樣就能源源不斷獲取到新鮮的飼料。 在資訊學裡面,Feed其實是一個資訊單元,比如一條朋友圈狀態、一條微博、一條諮詢或一條短視訊等,所以Feed流就是不停更新的資訊單元,只要關注某些釋出者就能獲取到源源不斷的新鮮資訊,我們的使用者也就可以在移動裝置上逐條去瀏覽這些資訊單元。
當前最流行的Feed流產品有微博、微信朋友圈、頭條的資訊推薦、快手抖音的視訊推薦等,還有一些變種,比如私信、通知等,這些系統都是Feed流系統,接下來我們會介紹如何設計一個Feed流系統架構。
Feed流系統特點
Feed流本質上是一個數據流,是將 “N個釋出者的資訊單元” 通過 “關注關係” 傳送給 “M個接收者”。
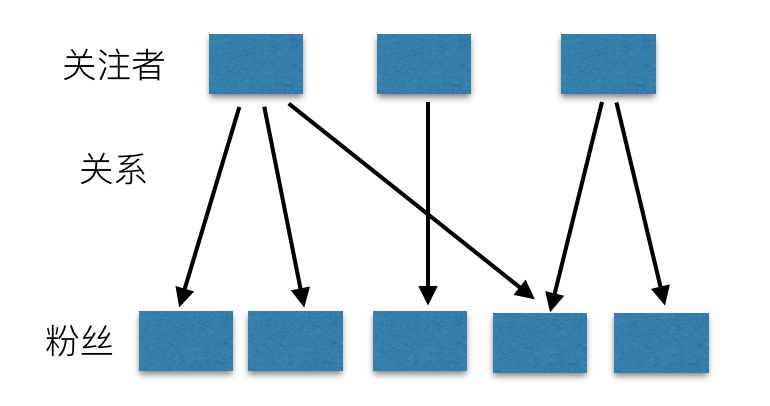
Feed流系統是一個數據流系統,所以我們核心要看資料。從資料層面看,資料分為三類,分別是:
- 釋出者的資料:釋出者產生資料,然後資料需要按照發布者組織,需要根據釋出者查到所有資料,比如微博的個人頁面、朋友圈的個人相簿等。
- 關注關係:系統中個體間的關係,微博中是關注,是單向流,朋友圈是好友,是雙向流。不管是單向還是雙向,當釋出者釋出一條資訊時,該條資訊的流動永遠是單向的。
- 接收者的資料:從不同釋出者那裡獲取到的資料,然後通過某種順序(一般為時間)組織在一起,比如微博的首頁、朋友圈首頁等。這些資料具有時間熱度屬性,越新的資料越有價值,越新的資料就要排在最前面。
針對這三類資料,我們可以有如下定義:
- 儲存庫:儲存釋出者的資料,永久儲存。
- 關注表:使用者關係表,永久儲存。
- 同步庫:儲存接收者的時間熱度資料,只需要保留最近一段時間的資料即可。
設計Feed流系統時最核心的是確定清楚產品層面的定義,需要考慮的因素包括:
- 產品使用者規模:使用者規模在十萬、千萬、十億級時,設計難度和側重點會不同。
- 關注關係(單向、雙寫):如果是雙向,那麼就不會有大V,否則會有大V存在。
上述是選擇資料儲存系統最核心的幾個考慮點,除此之外,還有一些需要考慮的: -
如何實現Meta和Feed內容搜尋?
- 雖然Feed流系統本身可以不需要搜尋,但是一個Feed流產品必須要有搜尋,否則資訊發現難度會加大,使用者留存率會大幅下降。
-
Feed流的順序是時間還是其他分數,比如個人的喜好程度?
- 雙向關係時由於關係很緊密,一定是按時間排序,就算一個關係很緊密的人發了一條空訊息或者低價值訊息,那我們也會需要關注瞭解的。
- 單向關係時,那麼可能就會存在大V,大V的粉絲數量理論極限就是整個系統的使用者數,有一些產品會讓所有使用者都預設關注產品負責人,這種產品中,該負責人就是最大的大V,粉絲數就是使用者規模。
接下來,我們看看整個Feed流系統如何設計。
Feed流系統設計
上一節,我們提前思考了Feed流系統的幾個關鍵點,接下來,在這一節,我們自頂向下來設計一個Feed流系統。
1. 產品定義
第一步,我們首先需要定義產品,我們要做的產品是哪一種型別,常見的型別有:
- 微博類
- 朋友圈類
- 抖音類
- 私信類
接著,再詳細看一下這幾類產品的異同:
| 型別 | 關注關係 | 是否有大V | 時效性 | 排序 |
|---|---|---|---|---|
| 微博類 | 單向 | 有 | 秒~分 | 時間 |
| 抖音類 | 單向/無 | 有 | 秒~分 | 推薦 |
| 朋友圈類 | 雙向 | 無 | 秒 | 時間 |
| 私信類 | 雙向 | 無 | 秒 | 時間 |
上述對比中,只對比各類產品最核心、或者最根本特點,其他次要的不考慮。比如微博中互相關注後就是雙向關注了,但是這個不是微博的立命之本,只是補充,無法撼動根本。
從上面表格可以看出來,主要分為兩種區分:
-
關注關係是單向還是雙向:
- 如果是單向,那麼可能就會存在大V效應,同時時效性可以低一些,比如到分鐘級別;
- 如果是雙向,那就是好友,好友的數量有限,那麼就不會有大V,因為每個人的精力有限,他不可能主動加幾千萬的好友,這時候因為關係更精密,時效性要求會更高,需要都秒級別。
-
排序是時間還是推薦:
- 使用者對feed流最容易接受的就是時間,目前大部分都是時間。
- 但是有一些場景,是從全網資料裡面根據使用者的喜好給使用者推薦和使用者喜好度最匹配的內容,這個時候就需要用推薦了,這種情況一般也會省略掉關注了,相對於關注了全網所有使用者,比如抖音、頭條等。
確定了產品型別後,還需要繼續確定的是系統設計目標:需要支援的最大使用者數是多少?十萬、百萬、千萬還是億?
使用者數很少的時候,就比較簡單,這裡我們主要考慮 億級使用者 的情況,因為如果系統能支援億級,那麼其他量級也能支援。為了支援億級規模的使用者,主要子系統選型時需要考慮水平擴充套件能力以及一些子系統的可用性和可靠性了,因為系統大了後,任何一個子系統的不穩定都很容易波及整個系統。
2. 儲存
我們先來看看最重要的儲存,不管是哪種同步模式,在儲存上都是一樣的,我們定義使用者訊息的儲存為儲存庫。儲存庫主要滿足三個需求:
- 可靠儲存使用者傳送的訊息,不能丟失。否則就找不到自己曾經發布到朋友圈狀態了。
- 讀取某個人釋出過的所有訊息,比如個人主頁等。
- 資料永久儲存。
所以,儲存庫最重要的特徵就是兩點:
- 資料可靠、不丟失。
- 由於資料要永久儲存,資料會一直增長,所以要易於水平擴充套件。
綜上,可以選為儲存庫的系統大概有兩類:
| 特點 | 分散式NoSQL | 關係型資料庫(分庫分表) |
|---|---|---|
| 可靠性 | 極高 | 高 |
| 水平擴充套件能力 | 線性 | 需要改造 |
| 水平擴充套件速度 | 毫秒 | 無 |
| 常見系統 | Tablestore、Bigtable | MySQL、PostgreSQL |
- 對於可靠性,分散式NoSQL的可靠性要高於關係型資料庫,這個可能有違很多人的認知。主要是關係型資料庫發展很長時間了,且很成熟了,資料放在上面大家放心,而分散式NoSQL資料庫發展晚,使用的並不多,不太信任。但是,分散式NoSQL需要儲存的資料量更多,對資料可靠性的要求也加嚴格,所以一般都是儲存三份,可靠性會更高。目前在一些雲廠商中的關係型資料庫因為採用了和分散式NoSQL類似的方式,所以可靠性也得到了大幅提高。
- 水平擴充套件能力:對於分散式NoSQL資料庫,資料天然是分佈在多臺機器上,當一臺機器上的資料量增大後,可以通過自動分裂兩部分,然後將其中一半的資料遷移到另一臺機器上去,這樣就做到了線性擴充套件。而關係型資料庫需要在擴容時再次分庫分表。
所以,結論是:
- 如果是自建系統,且不具備分散式NoSQL資料庫運維能力,且資料規模不大,那麼可以使用MySQL,這樣可以撐一段時間。
- 如果是基於雲服務,那麼就用分散式NoSQL,比如Tablestore或Bigtable。
- 如果資料規模很大,那麼也要用分散式NoSQL,否則就是走上一條不歸路。
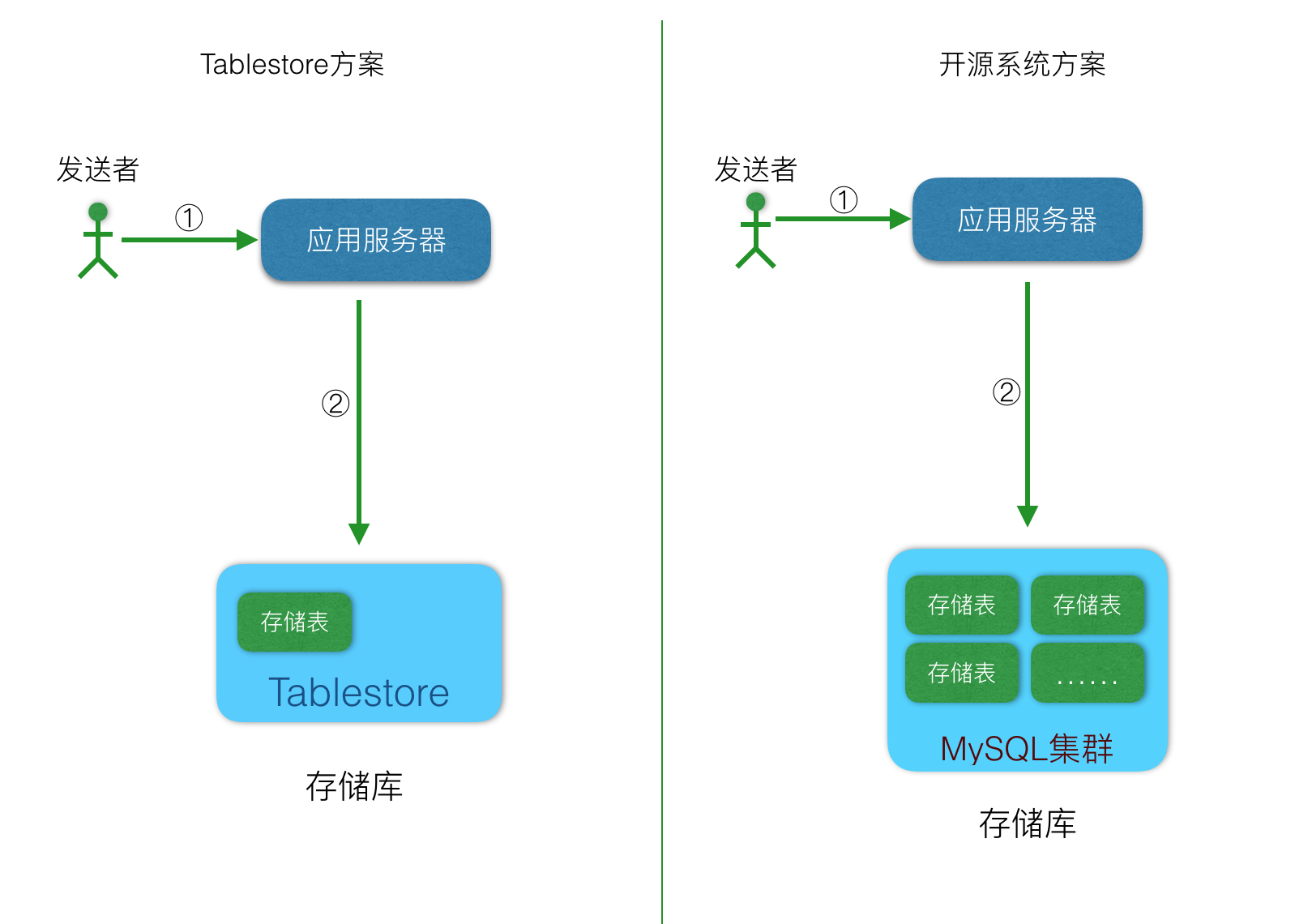
如果使用Tablestore,那麼儲存庫表設計結構如下:
| 主鍵列 | 第一列主鍵 | 第二列主鍵 | 屬性列 | 屬性列 |
|---|---|---|---|---|
| 列名 | user_id | message_id | content | other |
| 解釋 | 訊息傳送者使用者ID | 訊息順序ID,可以使用timestamp。 | 內容 | 其他內容 |
到此,我們確定了儲存庫的選型,那麼系統架構的輪廓有了:
3. 同步
系統規模和產品型別,以及儲存系統確定後,我們可以確定同步方式,常見的方式有三種:
- 推模式(也叫寫擴散):和名字一樣,就是一種推的方式,傳送者傳送了一個訊息後,立即將這個訊息推送給接收者,但是接收者此時不一定線上,那麼就需要有一個地方儲存這個資料,這個儲存的地方我們稱為:同步庫。推模式也叫寫擴散的原因是,一個訊息需要傳送個多個粉絲,那麼這條訊息就會複製多份,寫放大,所以也叫寫擴散。這種模式下,對同步庫的要求就是寫入能力極強和穩定。讀取的時候因為訊息已經發到接收者的收件箱了,只需要讀一次自己的收件箱即可,讀請求的量極小,所以對讀的QPS需求不大。歸納下,推模式中對同步庫的要求只有一個:寫入能力強。
- 拉模式(也叫讀擴散):這種是一種拉的方式,傳送者傳送了一條訊息後,這條訊息不會立即推送給粉絲,而是寫入自己的發件箱,當粉絲上線後再去自己關注者的發件箱裡面去讀取,一條訊息的寫入只有一次,但是讀取最多會和粉絲數一樣,讀會放大,所以也叫讀擴散。拉模式的讀寫比例剛好和寫擴散相反,那麼對系統的要求是:讀取能力強。另外這裡還有一個誤區,很多人在最開始設計feed流系統時,首先想到的是拉模式,因為這種和使用者的使用體感是一樣的,但是在系統設計上這種方式有不少痛點,最大的是每個粉絲需要記錄自己上次讀到了關注者的哪條訊息,如果有1000個關注者,那麼這個人需要記錄1000個位置資訊,這個量和關注量成正比的,遠比使用者數要大的多,這裡要特別注意,雖然在產品前期資料量少的時候這種方式可以應付,但是量大了後就會事倍功半,得不償失,切記切記。
- 推拉結合模式:推模式在單向關係中,因為存在大V,那麼一條訊息可能會擴散幾百萬次,但是這些使用者中可能有一半多是殭屍,永遠不會上線,那麼就存在資源浪費。而拉模式下,在系統架構上會很複雜,同時需要記錄的位置資訊是天量,不好解決,尤其是使用者量多了後會成為第一個故障點。基於此,所以有了推拉結合模式,大部分使用者的訊息都是寫擴散,只有大V是讀擴散,這樣既控制了資源浪費,又減少了系統設計複雜度。但是整體設計複雜度還是要比推模式複雜。
用圖表對比:
| 型別 | 推模式 | 拉模式 | 推拉結合模式 |
|---|---|---|---|
| 寫放大 | 高 | 無 | 中 |
| 讀放大 | 無 | 高 | 中 |
| 使用者讀取延時 | 毫秒 | 秒 | 秒 |
| 讀寫比例 | 1:99 | 99:1 | ~50:50 |
| 系統要求 | 寫能力強 | 讀能力強 | 讀寫都適中 |
| 常見系統 | Tablestore、Bigtable等LSM架構的分散式NoSQL | Redis、memcache等快取系統或搜尋系統(推薦排序場景) | 兩者結合 |
| 架構複雜度 | 簡單 | 複雜 | 更復雜 |
介紹完同步模式中所有場景和模式後,我們歸納下:
- 如果產品中是雙向關係,那麼就採用推模式。
- 如果產品中是單向關係,且使用者數少於1000萬,那麼也採用推模式,足夠了。
- 如果產品是單向關係,單使用者數大於1000萬,那麼採用推拉結合模式,這時候可以從推模式演進過來,不需要額外重新推翻重做。
- 永遠不要只用拉模式。
- 如果是一個初創企業,先用推模式,快速把系統設計出來,然後讓產品去驗證、迭代,等客戶數大幅上漲到1000萬後,再考慮升級為推拉集合模式。
- 如果是按推薦排序,那麼是另外的考慮了,架構會完全不一樣,這個後面專門文章介紹。
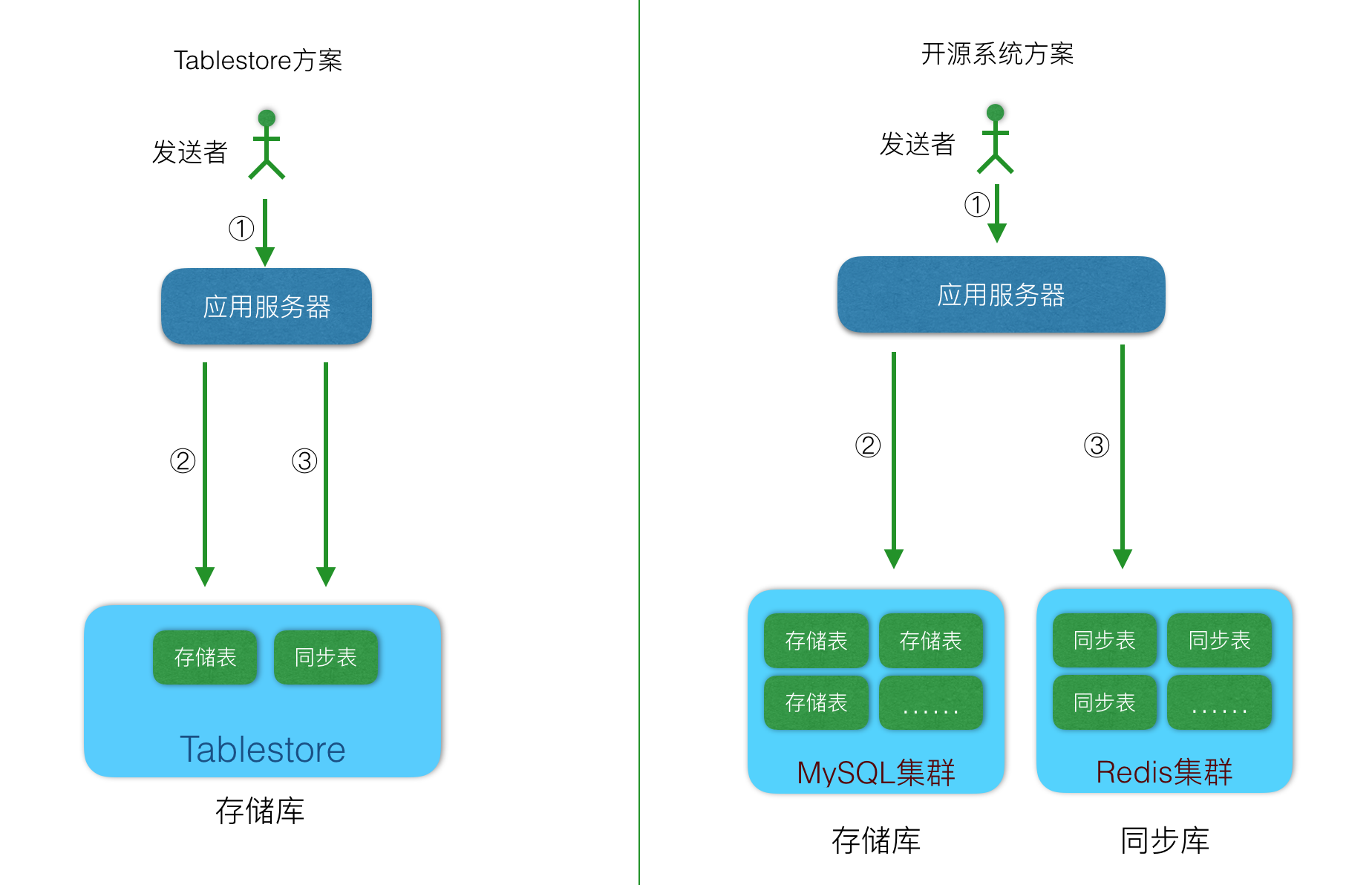
如果選擇了Tablestore,那麼同步庫表設計結構如下:
| 主鍵列 | 第一列主鍵 | 第二列主鍵 | 屬性列 | 屬性列 | 屬性列 |
|---|---|---|---|---|---|
| 列名 | user_id | sequence_id | sender_id | message_id | other |
| 解釋 | 訊息接收者使用者ID | 訊息順序ID,可以使用timestamp + send_user_id,也可以直接使用Tablestore的自增列。 | 傳送者的使用者ID | store_table中的message_id列的值,也就是訊息ID。通過sender_id和message_id可以到store_table中查詢到訊息內容 | 其他內容,同步庫中不需要包括訊息內容。 |
確定了同步庫的架構如下:
4. 元資料
前面介紹了同步和儲存後,整個Feed流系統的基礎功能完成了,但是對於一個完整Feed流產品而言,還缺元資料部分,接下來,我們看元資料如何處理:
Feed流系統中的元資料主要包括:
- 使用者詳情和列表。
- 關注或好友關係。
- 推送session池。
我們接下來逐一來看。
4.1 使用者詳情和列表
主要是使用者的詳情,包括使用者的各種自定義屬性和系統附加的屬性,這部分的要求只需要根據使用者ID查詢到就可以了。
可以採用的分散式NoSQL系統或者關係型資料庫都可以。
如果使用NoSQL資料庫Tablestore,那麼使用者詳情表設計結構如下:
| 主鍵順序 | 第一列主鍵 | 屬性列-1 | 屬性列-2 | ...... |
|---|---|---|---|---|
| 欄位名 | user_id | nick_name | gender | other |
| 備註 | 主鍵列,用於唯一確定一個使用者 | 使用者暱稱,使用者自定義屬性 | 使用者性別,使用者自定義屬性 | 其他屬性,包括使用者自定義屬性列和系統附加屬性列。Tablestore是FreeSchema型別的,可以隨時在任何一行增加新列而不影響原有資料。 |
4.2 關注或好友關係
這部分是儲存關係,查詢的時候需要支援查詢關注列表或者粉絲列表,或者直接好友列表,這裡就需要根據多個屬性列查詢需要索引能力,這裡,儲存系統也可以採用兩類,關係型、分散式NoSQL資料庫。
- 如果已經有了關係型資料庫了,且資料量較少,則選擇關係型資料庫,比如MySQL等。
-
如果資料量比較大,這個時候就有兩種選擇:
-
- 需要分散式事務,可以採用支援分散式事務的系統,比如分散式關係型資料庫。
-
- 使用具有索引的系統,比如雲上的Tablestore,更簡單,吞吐更高,擴容能力也一併解決了。
-
如果使用Tablestore,那麼關注關係表設計結構如下:
Table:user_relation_table
| 主鍵順序 | 第一列主鍵 | 第一列主鍵 | 屬性列 | 屬性列 |
|---|---|---|---|---|
| Table欄位名 | user_id | follow_user_id | timestamp | other |
| 備註 | 使用者ID | 粉絲使用者ID | 關注時間 | 其他屬性列 |
多元索引的索引結構:
| Table欄位名 | user_id | follow_user_id | timestamp |
|---|---|---|---|
| 是否Index | 是 | 是 | 是 |
| 是否enableSortAndAgg | 是 | 是 | 是 |
| 是否store | 是 | 是 | 是 |
查詢的時候:
- 如果需要查詢某個人的粉絲列表:使用TermQuery查詢固定user_id,且按照timestamp排序。
- 如果需要查詢某個人的關注列表:使用TermQuery查詢固定follow_user_id,且按照timestamp排序。
- 當前資料寫入Table後,需要5~10秒鐘延遲後會在多元索引中查詢到,未來會優化到2秒以內。
除了使用多元索引外,還可以使用GlobalIndex。
4.3 推送session池
思考一個問題,傳送者將訊息傳送後,接收者如何知道自己有新訊息來了?客戶端週期性去重新整理?如果是這樣子,那麼系統的讀請求壓力會隨著客戶端增長而增長,這時候就會有一個風險,比如平時的裝置線上率是20%~30%,突然某天平臺爆發了一個熱點訊息,大量休眠裝置登陸,這個時候就會出現“查詢風暴”,一下子就把系統打垮了,所有的使用者都不能用了。
解決這個問題的一個思路是,在服務端維護一個推送session池,這個裡面記錄哪些使用者線上,然後當用戶A傳送了一條訊息給使用者B後,服務端在寫入儲存庫和同步庫後,再通知一下session池中的使用者B的session,告訴他:你有新訊息了。然後session-B再去讀訊息,然後有訊息後將訊息推送給客戶端。或者有訊息後給客戶端推送一下有訊息了,客戶端再去拉。
這個session池使用在同步中,但是本質還是一個元資料,一般只需要存在於記憶體中即可,但是考慮到failover情況,那就需要持久化,這部分資料由於只需要指定單Key查詢,用分散式NoSQL或關係型資料庫都可以,一般複用當前的系統即可。
如果使用Tablestore,那麼session表設計結構如下:
| 主鍵列順序 | 第一列主鍵 | 第二列主鍵 | 屬性列 |
|---|---|---|---|
| 列名 | user_id | device_id | last_sequence_id |
| 備註 | 接收者使用者ID | 裝置ID,同一個使用者可能會有多個裝置,不同裝置的讀取位置可能不一致,所以這裡需要一個裝置ID。如果不需要支援多終端,則這一列可以省略。 | 該接收者已經推送給客戶端的最新的順序ID |
5. 評論
除了私信型別外,其他的feed流型別中,都有評論功能,評論的屬性和儲存庫差不多,但是多了一層關係:被評論的訊息,所以只要將評論按照被被評論訊息分組組織即可,然後查詢時也是一個範圍查詢就行。這種查詢方式很簡單,用不到關係型資料庫中複雜的事務、join等功能,很適合用分散式NoSQL資料庫來儲存。
所以,一般的選擇方式就是:
- 如果系統中已經有了分散式NoSQL資料庫,比如Tablestore、Bigtable等,那麼直接用這些即可。
- 如果沒有上述系統,那麼如果有MySQL等關係型資料庫,那就選關係型資料庫即可。
- 如果選擇了Tablestore,那麼“評論表”設計結構如下:
| 主鍵列順序 | 第一列主鍵 | 第二列主鍵 | 屬性列 | 屬性列 | 屬性列 |
|---|---|---|---|---|---|
| 欄位名 | message_id | comment_id | comment_content | reply_to | other |
| 備註 | 微博ID或朋友圈ID等訊息的ID | 這一條評論的ID | 評論內容 | 回覆給哪個使用者 | 其他 |
如果需要搜尋評論內容,那麼對這張表建立多元索引即可。
6. 贊
最近幾年,“贊”或“like”功能很流行,贊功能的實現和評論類似,只是比評論少了一個內容,所以選擇方式和評論一樣。
如果選擇了Tablestore,那麼“贊表”設計結構同評論表,這裡就不再贅述了。
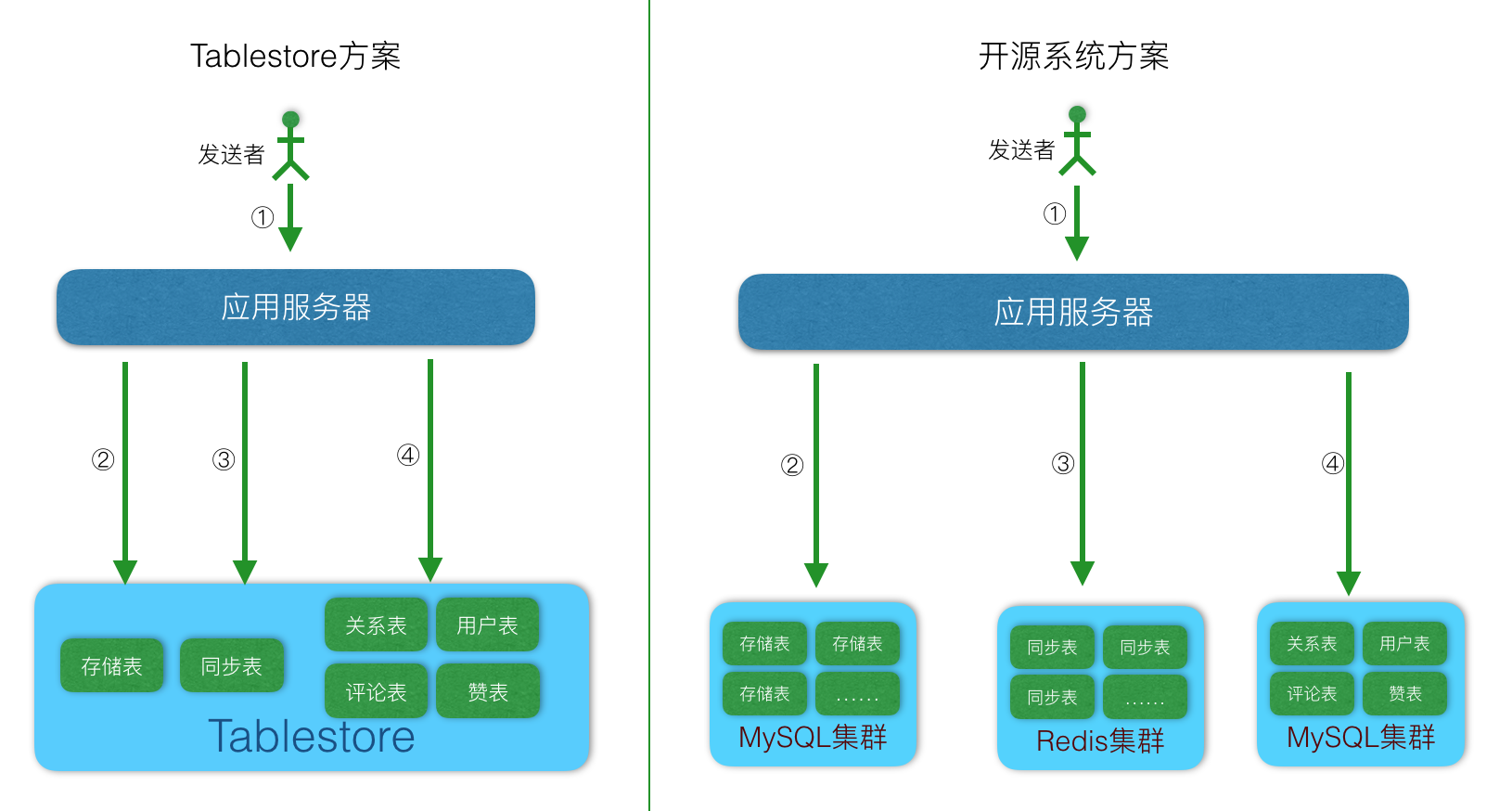
系統架構中加了元資料系統後的架構如下:
7. 搜尋
到此,我們已經介紹完了Feed流系統的主題架構,Feed流系統算是完成了。但是Feed流產品上還未結束,對於所有的feed流產品都需要有搜尋能力,比如下面場景:
- 微博中的搜尋使用者。
- 搜尋微博內容。
- 微信中搜索好友等。
這些內容搜尋只需要字元匹配到即可,不需要非常複雜的相關性演算法,所以只需要有能支援分詞的檢索功能即可,所以一般有兩種做法:
使用搜索引擎,將儲存庫的內容和使用者資訊表內容推送給搜尋系統,搜尋的時候直接訪問搜尋系統。
使用具備全文檢索能力的資料庫,比如最新版的MySQL、MongoDB或者Tablestore。
所以,選擇的原則如下:
- 如果儲存庫使用了MySQL或者Tablestore,那麼直接選擇這兩個系統就可以了。
- 如果整個系統都沒使用MySQL、Tablestore,且已經使用了搜尋系統,那麼可以直接複用搜尋系統,其他場景都不應該再額外加一個搜尋系統進來,徒添複雜度。
如果使用Tablestore,那麼只需要在相應表上建立多元索引即可:
- 如果需要對使用者名稱支援搜尋,那麼需要對user_table建立多元索引,其中的nick_name需要是Text型別,且單字分詞。
- 如果需要對Feed流內容支援搜尋,那麼需要對儲存庫表:store_table建立多元索引,這樣就能直接對Feed流內容進行各種複雜查詢了,包括多條件篩選、全文檢索等。
系統架構中加了搜尋功能後的架構如下:
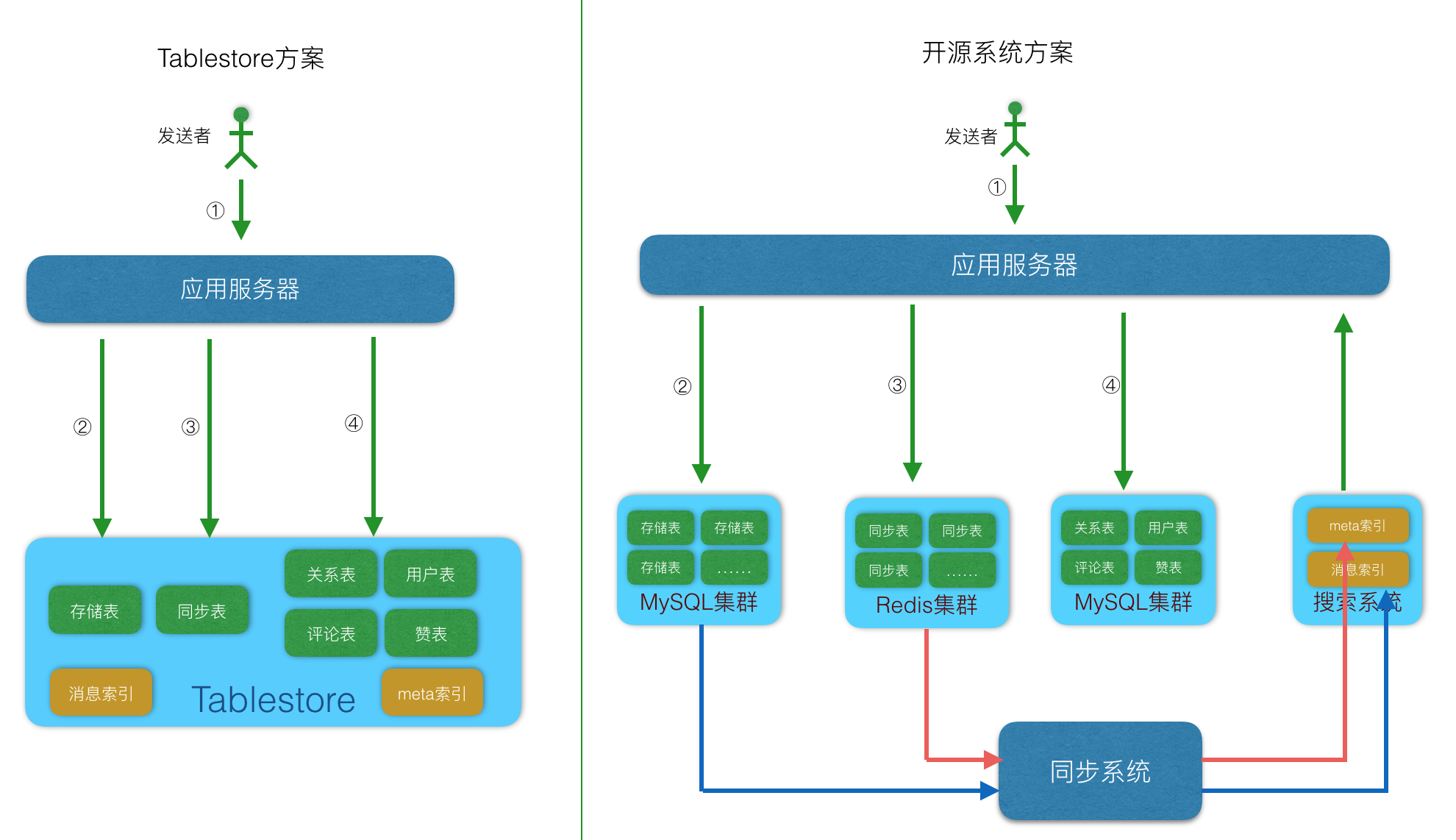
8. 排序
目前的Feed流系統中的排序方式有兩種,一種是時間,一種是分數。
我們常用的微博、朋友圈、私信這些都是時間線型別的,因為這些產品定義中,需要我們主動關注某些人後才會看到這些人發表的內容,這個時候,最重要的是實時性,而不是釋出質量,就算關注人釋出了一條垃圾資訊,我們也會被動看到。這種型別的產品適用於按照時間線排序。這一篇我們介紹的架構都是基於時間型別的。
另外一種是不需要關注任何人,我們能看到的都是系統希望我們看到的,系統在後臺會分析我們的每個人的愛好,然後給每個人推送差異化的、各自喜歡的內容,這一種的架構和基於時間的完全不一樣,我們在後續的推薦型別中專門介紹。
9. 刪除Feed內容
在Feed流應用中有一個問題,就是如果使用者刪除了之前發表的內容,系統該如何處理?因為系統裡面有寫擴散,那麼刪除的時候是不是也要寫擴散一遍?這樣的話,刪除就不及時了,很難應對法律法規要求的快速刪除。
針對這個問題,我們在之前設計的時候,同步表中只有訊息ID,沒有訊息內容,在使用者讀取的時候需要到儲存庫中去讀訊息內容,那麼我們可以直接刪除儲存庫中的這一條訊息,這樣使用者讀取的時候使用訊息ID是讀不到資料的,也就相當於刪除的內容,而且刪除速度會很快。除了直接刪除外,另外一種辦法是邏輯刪除,對於刪除的feed內容,只做標記,當查詢到帶有標記的資料時就認為刪除了。
10. 更新Feed內容
更新和刪除Feed處理邏輯一樣,如果使用了支援多版本的儲存系統,比如Tablestore,那麼也可以支援編輯版本,和現在的微博一樣。
11. 總結
上面介紹了不同子功能的特點和系統要求,能滿足需求的系統主要有兩類,一類是阿里雲的Tablestore單系統,一類是開源元件組成的組合系統。
- 開源元件組成的組合系統:包括MySQL、Redis、HBase等,這些系統單個都不能解決Feed流系統中遇到的問題,需要組合在一起,各司其職才能完成一個Feed流系統,適用於熱衷開源系統,人多且喜歡運維操作的團隊。
-
Tablestore單系統:只使用Tablestore單個系統就能解決上述的所有問題,這時候肯定有人要問?你是不是在吹牛? 這裡不是吹牛,Tablestore在三年前就已經開始重視Feed流型別業務,之前也發表過多篇文章介紹,功能上也在專門為Feed流系統特別定製設計,所以到今天,只使用Tablestore一款產品,是可以滿足上述需求的。選擇Tablestore做Feed流系統的使用者具有以下一些特徵:
- 產品設計目標規模大,千萬級或億級。
- 不喜歡運維,喜歡專注於開發。
- 高效率團隊,希望儘快將產品實現落地。
- 希望一勞永逸,未來系統隨著使用者規模增長可以自動擴容。
- 希望能按量付費,使用者少的時候費用低,等使用者增長起來後費用在跟隨使用者數增長。
如果具有上述四個特徵的任何一個,那麼都是適合於用Tablestore。
架構實踐
上面我們介紹了Feed流系統的設計理論,具體到不同的型別中,會有不同的側重點,下面會逐一介紹。
朋友圈
朋友圈是一種典型的Feed流系統,關係是雙寫關係,關係有上限,排序按照時間,如果有個人持續產生垃圾內容,那就只能遮蔽掉TA,這一種型別就是典型的寫擴散模型。
我們接下來會在文章《朋友圈類系統架構設計》中詳細介紹朋友圈型別Feed流系統的設計。
微博
微博也是一種非常典型的Feed流系統,但不同於朋友圈,關係是單向的,那麼也就會產生大V,這個時候就需要讀寫擴散模式,用讀擴散解決大V問題。同時,微博也是主動關注型別的產品,所以排序也只能是時間,如果按照推薦排序,那麼效果就會比較差。
接下里會在文章《微博類系統架構設計》中詳細介紹微博型別Feed流系統的設計。
頭條
頭條是最近幾年快速崛起的一款應用,在原有微博的Feed流系統上產生了進化,使用者不需要主動關注其他人,只要初始瀏覽一些內容後,系統就會自動判斷出你的喜好,然後後面再根據你的喜好給你推薦你可能會喜好的內容,訓練時間長了後,推送的內容都會是你最喜歡看的。
後面,我們會在文章《頭條類系統架構設計》中詳細介紹頭條型別Feed流系統的設計。
私信
私信也算是一種簡單的Feed流系統,或者也可以認為是一種變相的IM,都是單對單的,沒有群。我們後面也會有一篇文章《私信類系統架構設計》中做詳細介紹。
總結
上面我們介紹了Feed流系統的整體框架,主要是產品定義、同步、儲存、元資料、評論、贊、排序和搜尋等內容,由於篇幅有限,每一章節都介紹的比較簡單。讀者如果對某一部分看完後仍然有疑問,可以繼續再文後提問,我會繼續去完善這篇文章,希望未來讀者看完這篇文章後,就可以輕輕鬆鬆設計出一個億級規模的Feed流系統。
另外,我們也歡迎有興趣的讀者一起來完成這個系列,幫忙實現朋友圈、微博、頭條或者私信型別的文章,有任何問題都歡迎來討論。
延伸
Feed型別的系統架構和IM(即時聊天)型別的系統架構非常類似,自從Tablestore從2016年開始優化此類系統,我們研發了Feed流和IM的通用底層框架-Timeline,目前已經演進到了V2版本,一體化支援儲存、同步和搜尋功能,我們已經有文章做了介紹:
《億級訊息系統的核心儲存:Tablestore釋出Timeline 2.0模型》
《現代IM系統中的訊息系統架構 - 架構篇》
《現代IM系統中的訊息系統架構 - 模型篇》
《Tablestore權威指南》
本文作者:少強
本文為雲棲社群原創內容,未經