
談談機器學習模型的可解釋性
隨著AI和機器學習的發展,越來越多的決策會交給自動化的機器學習演算法來做。但是當我們把一些非常重要的決定交給機器的時候,我們真的放心麼?當波音飛機忽略駕駛員的指令,決定義無反顧的衝向大地;當銀行系統莫名其妙否決你的貸款申請的時候;當自動化敵我識別武器系統決定向無辜平民開火的時候;人類的內心應該是一萬個草泥馬飛過,大聲的質問,“為什麼?”
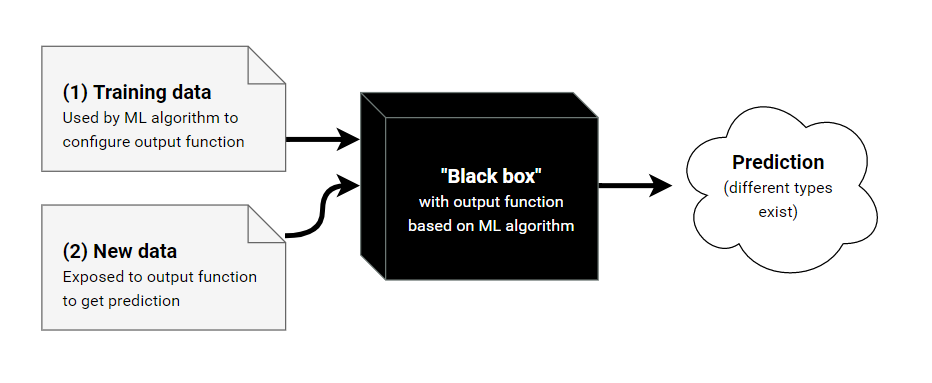
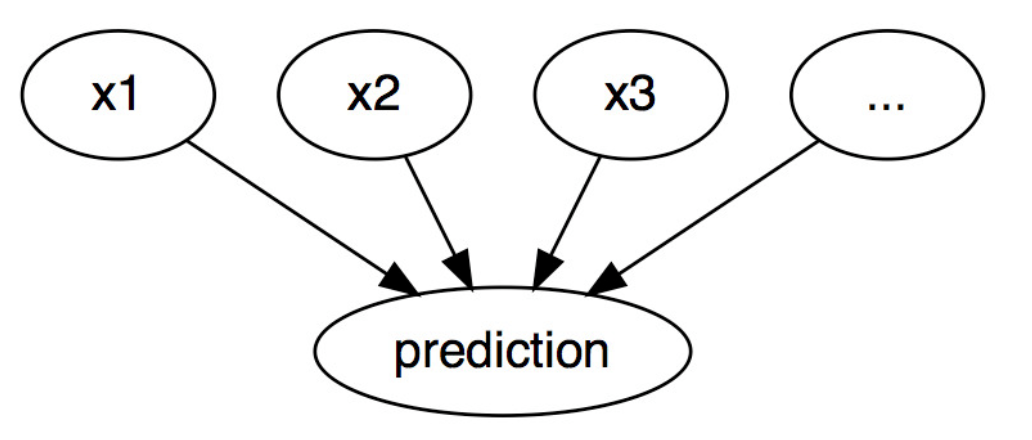
機器學習演算法可以看成是如上圖所示的黑盒子模型,訓練資料流入黑盒子,訓練出一個函式(這個函式也可以稱之為模型),輸入新的資料到該函式得出預測結果。關於模型的可解釋性,就是要回答為什麼的問題,如何解釋該函式,它是如何預測的?
可解釋的模型
在機器學習的眾多演算法中,有的模型很難解釋,例如深度神經網路。深度神經網路可以擬合高度複雜的資料,擁有海量的引數,但是如何解釋這些非常困難。但是還是有相當一部分演算法是可以比較容易的解釋的。
例如線性迴歸:
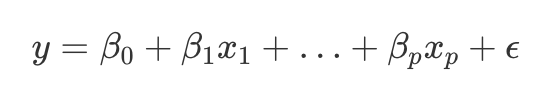
線性迴歸目標Y和特徵X之間的關係如上圖的公式所示。那麼對於線性迴歸模型的解釋就很簡單,對於一個特定的特徵Xi,每增加一個單位,目標Y增加βi。
線性迴歸簡單易用,也能保證找到最優解。但是畢竟不是所有的問題都是線性的。
另外一個可解釋的模型的例子是決策樹。

如上圖的決策樹的例子所示,決策樹明確給出了預測的依據。要解釋決策樹如何預測非常簡單,從根結點開始,依照所有的特徵開始分支,一直到到達葉子節點,找到最終的預測。
決策樹可以很好的捕捉特徵之間的互動和依賴。樹形結構也可以很好的視覺化。但是決策樹對於線性關係的處理比較困難,他不夠平滑,也不穩定,一個小的特徵資料變化就可能改變整個樹的構建。當樹的節點和層級變大的時候,要解釋整個決策過程也就相應的變得困難了。
其它還有一些可解釋的模型,例如邏輯迴歸,通用的線性模型,樸素貝葉斯,K緊鄰,等。
模型無關的方法
可解釋的模型的種類畢竟有限,我們希望能夠找到一些方法,對任何的黑盒子機器學習模型提供解釋。這裡就需要和模型無關的方法了。
Partial Dependence Plot ( PDP )
PDP用於表示一個模型中一個或者兩個特徵對於預測結果的影響。
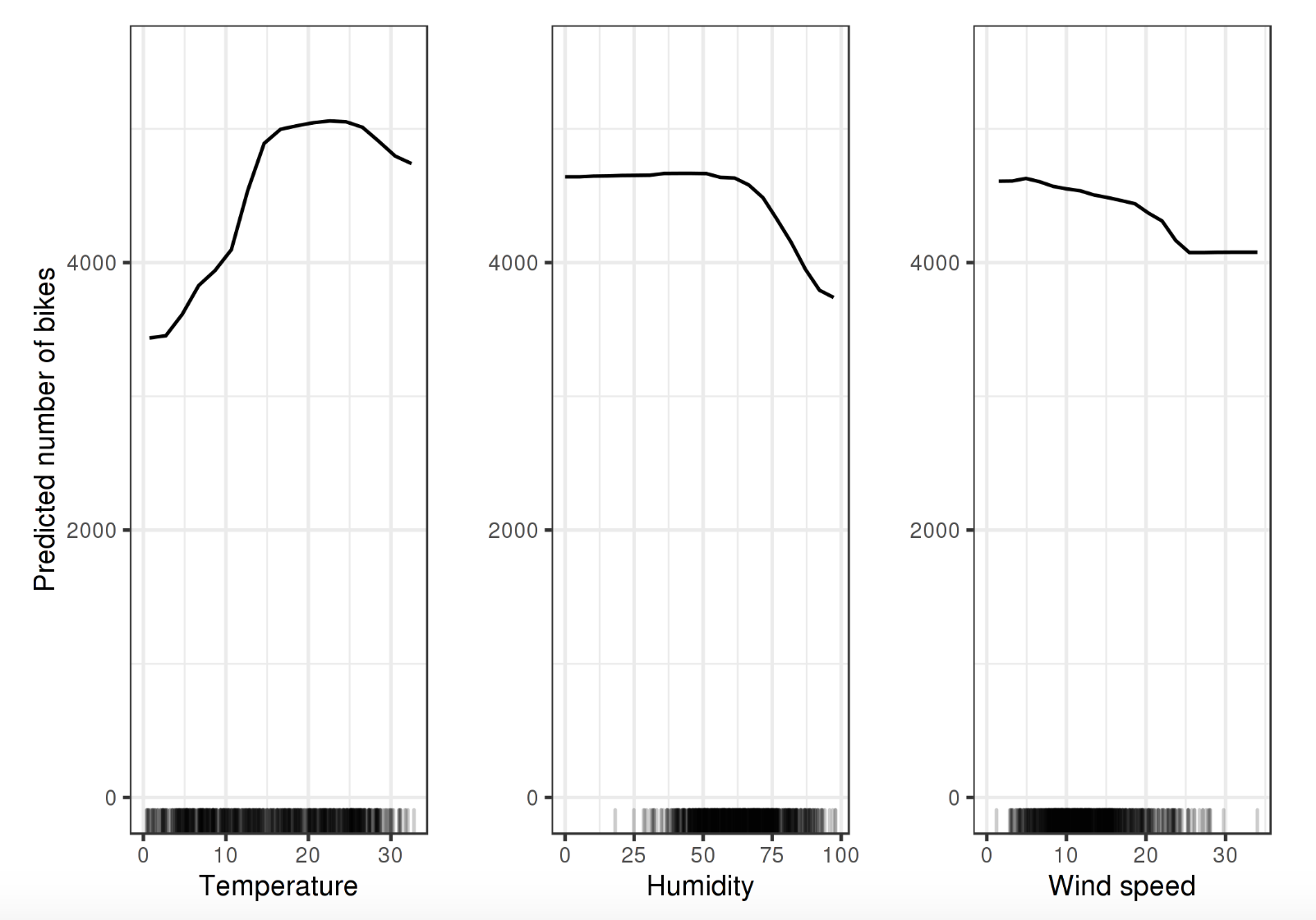
如上圖的PDP圖反應了三個特徵溫度(注意這裡是3個PDP,PDP假定每一個特徵都是獨立的),溼度和風速對於騎車出行人數的影響。每一個圖都是假定其它特徵不變的情況下的趨勢。
PDP圖非常直觀和容易理解,也很容易計算生成。但是PDP圖最多隻能反應兩個特徵,因為超過三維的圖無法用當前的技術來表示。同時獨立性假設是PDP的最大問題。
Individual Conditional Expectation (ICE)
ICE顯示了對於每一個樣本例項,當改變某一個特徵的值得時候,預測結果是如何改變的。

如上圖所示,這個和PDP的圖反映了一致的趨勢,但是包含了所有的樣本。
和PDP類似,ICE的獨立性假設和不能表徵超過兩個特徵都是他的限制。同時隨著樣本數量的增大,圖會變得相當的擁擠。
特徵互動 (feature interaction)
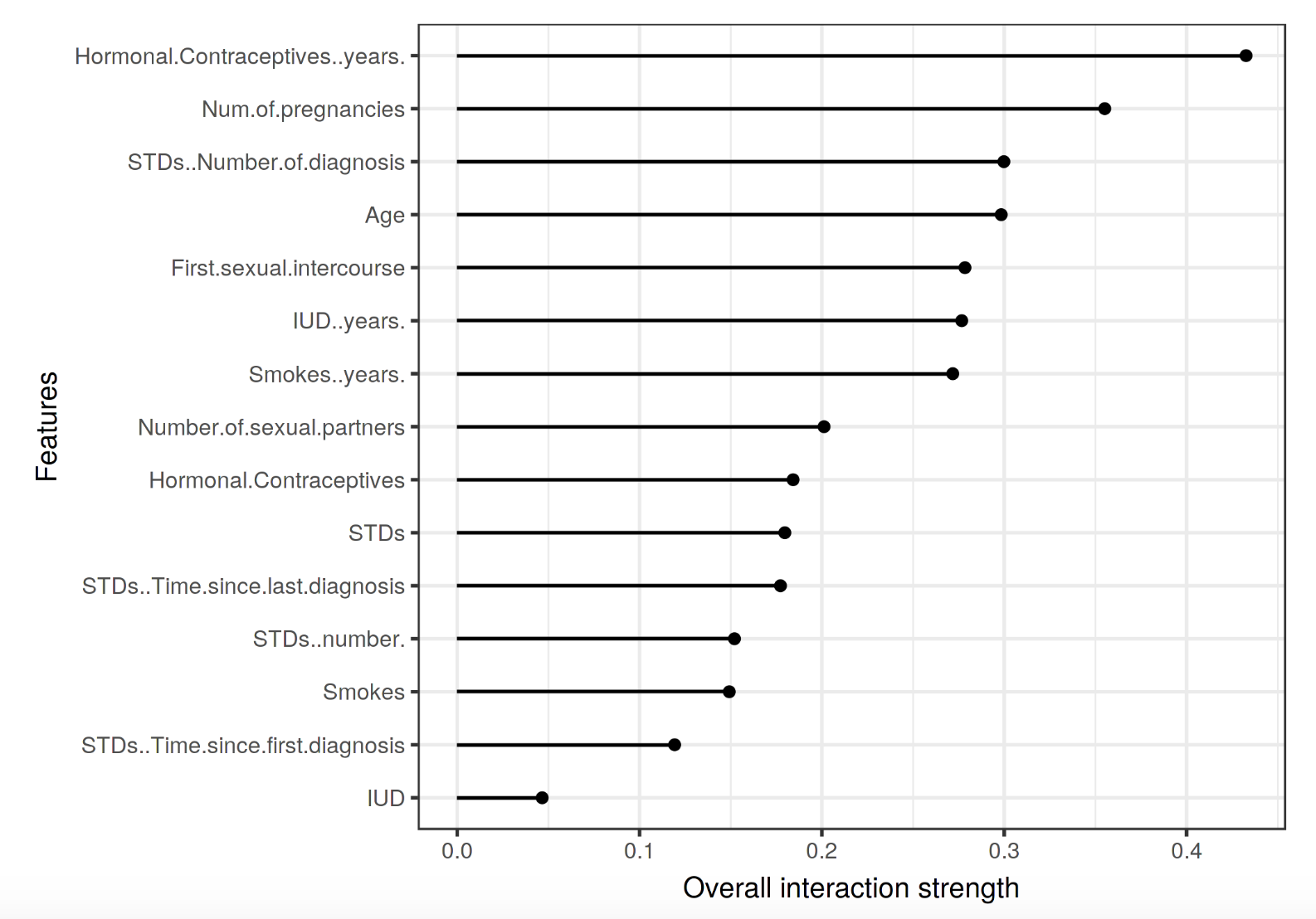
如上圖所示的特徵互動圖反映了,例如一個模型有兩個特徵,那麼模型可以是一個常量 + 只包含第一個特徵的項 + 只包含第二個特徵的項 + 兩個特徵的互動項。利用Friedman’s H-statistic的理論,我們可以計算特徵互動。
利用H-statistic計算是很耗資源的,結果也不是很穩定。
特徵重要性 Feature Importance
特徵重要性的定義是當改變一個特徵的值的時候,對於預測誤差帶來的變化。怎麼理解呢?當我們改變一個特徵,預測誤差發生了很大的變化,說明該特徵又很大的影響力,而相反的,如果改變另一個特徵的值,對於預測結果的誤差沒有什麼影響,那說明這個特徵無關緊要。
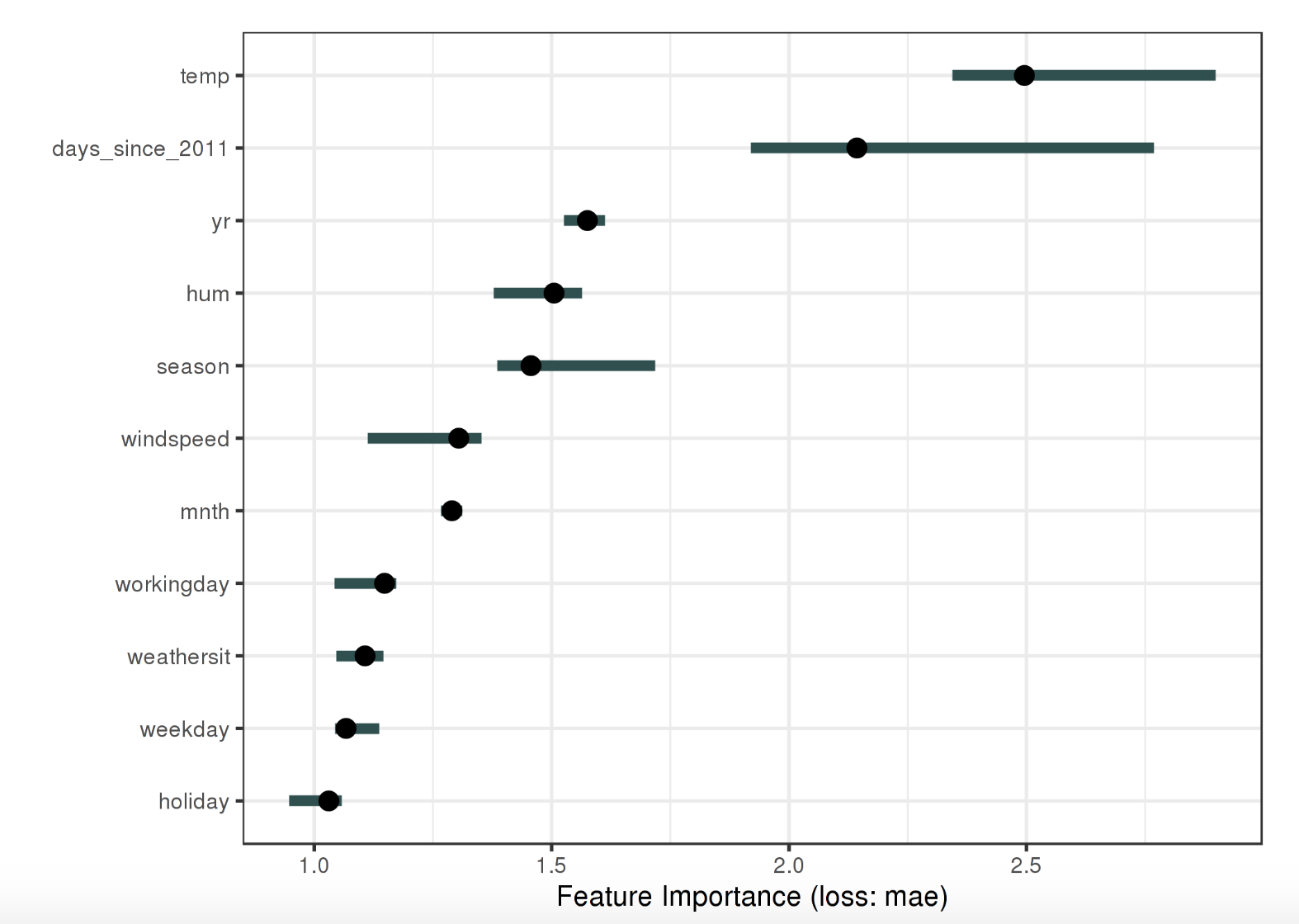
上圖是一個特徵重要性的圖示。
特徵重要性提供了一個高度概括的對模型的洞察,它包含了所有特徵的互動,計算特徵重要性不需要重新訓練模型。計算這個值需要資料包含真實結果。
Shapley Values
Shapley值是一個很有趣的工具,他假定每一個特徵就好像遊戲中的一個玩家,每個玩家對於預測的結果都有一定的貢獻。對於每一個預測結果,Shapley值給出每一個特徵對於這個預測結果的貢獻度。

下圖是一個Shapley Value的例子。
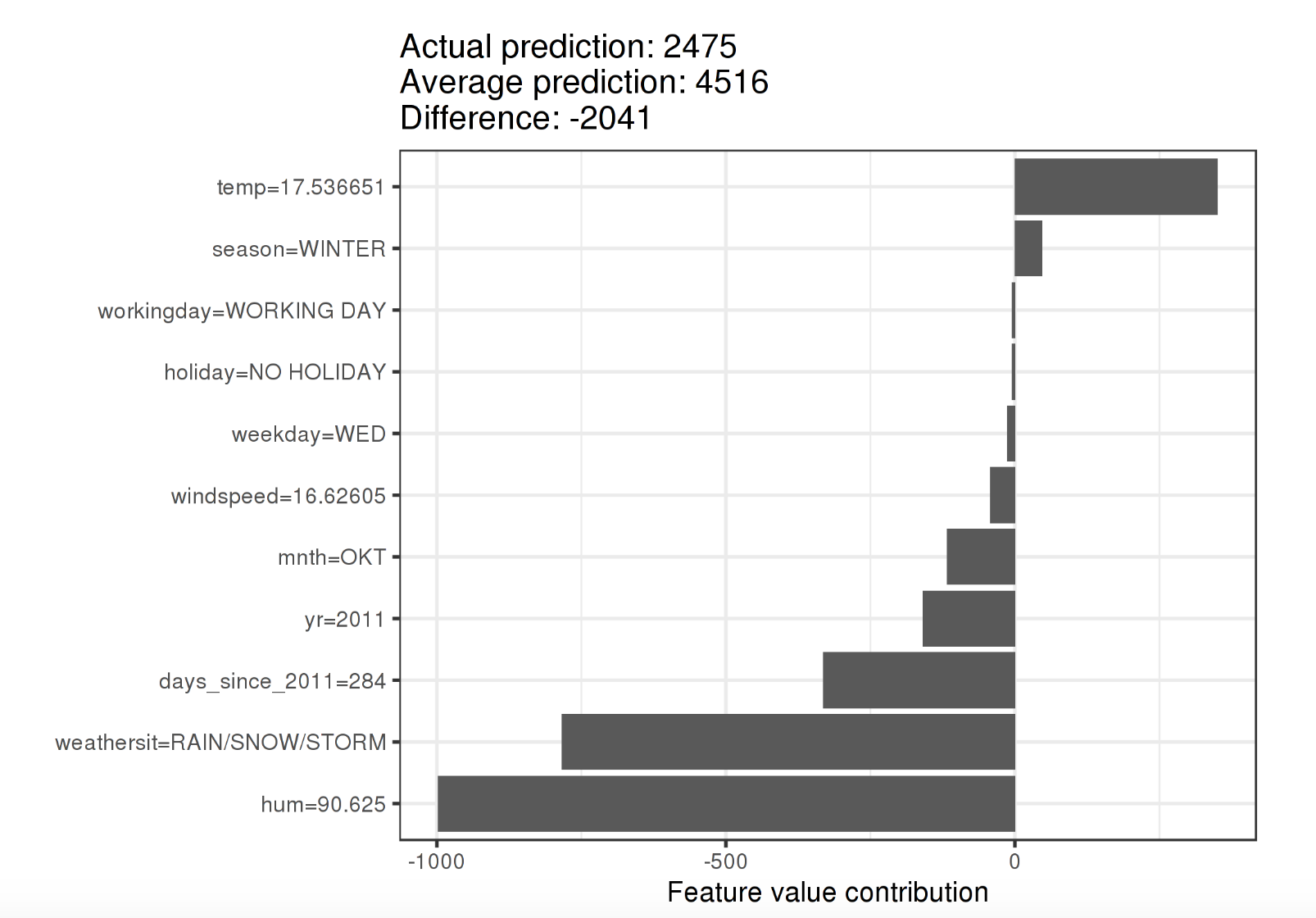
Shapley提供了對於每一個特徵的完整的解釋。但是同樣很耗計算資源,而且要求使用所有的特徵。
替代模型(Surrogate Model)
替代模型就是用一個可解釋的更簡單的模型,對於黑盒模型的輸入和預測訓練出一個替代品,用這個模型來解釋複雜的黑盒模型。
替代模型的訓練過程如下:
- 選擇一個數據集X(可以和訓練集相同或者不同,無所謂)
- 用訓練好的黑盒模型預測出Y
- 選擇一個可解釋的模型,如線性迴歸或者決策樹
- 用之前的資料集X和預測Y訓練這個可解釋模型
- 驗證可解釋模型和黑盒模型的差異
替代模型很靈活,很直觀也很容易實現。但是替代模型是對黑盒模型的解釋,而不是對於資料的解釋。
基於樣本的解釋
反事實解釋 (Counterfactual)
反事實解釋就像是說“如果X沒有發生,Y也就不會發生”
反事實的解釋在特徵和預測結果中建立一個因果關係。如上圖所示。
我們通過改變一個樣本的一個特徵,然後觀察預測結果的變化。google的what if 工具,可以幫助我們做這樣的分析。
另外推薦這本書:The Book of Why : The New Science of Cause and Effect

對抗樣本 (Adversarial)
對抗樣本是指當對一個樣本的某一個特徵值作出一個微小的變化而使得整個模型作出一個錯誤的預測。對抗樣本的目標是欺騙模型,黑客攻擊機器學習模型的手段往往就是找到這些對抗樣本。

原型和批評 (Prototypes and Criticisms)
原型是一個數據點,它可以代表所有的其它點。而一個批評點是指不能被一組原型有效代表的資料點。
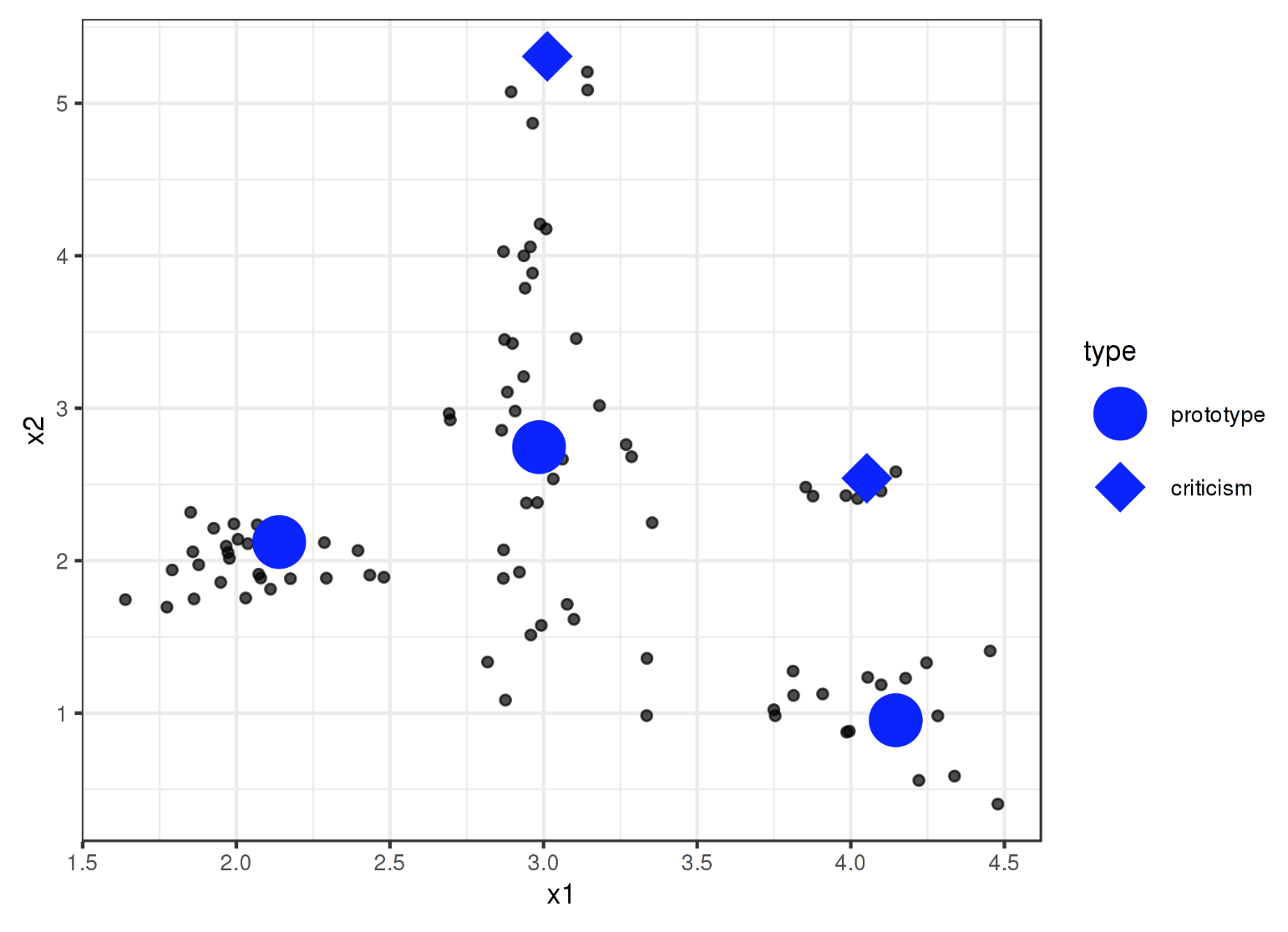
有影響力的例項(Influential Instances)
機器學習的模型是訓練資料的產出,刪除任何一個訓練資料都往往會影響訓練結果。如果刪除某一個訓練資料對模型產生餓巨大的影響,那麼我們稱這個點為有影響力的點。對有影響力的點的分析也往往可以幫助我們解釋模型。
總結
本文介紹了可解釋機器學習的基本概念和方法,希望對小夥伴們有所幫助。