
你需要精通一種監控-CPU資源監控例項
知識點回顧
CPU的使用率是如何計算的?
1)CPU相關概念
CPU利用率:CPU的使用情況。
使用者時間(User time) :表示CPU執行使用者程序的時間,包括nices時間。通常期望使用者空間CPU越高越好。
系統時間(System time) :表示CPU在核心執行時間,包括IRQ和softirq時間。系統CPU佔用率高,表明系統某部分存在瓶頸。通常值越低越好。
等待時間(Waiting time) :CPU在等待I/O操作完成所花費的時間。系統不應該花費大量時間來等待I/O操作,否則就說明I/O存在瓶頸。
空閒時間(Idle time) :系統處於空閒期,等待程序執行。
Nice時間(Nice time) :系統調整程序優先順序所花費的時間。
硬中斷處理時間(Hard Irq time) :系統處理硬中斷所花費的時間。
軟中斷處理時間(SoftIrq time) :系統處理軟中斷中斷所花費的時間。
丟失時間(Steal time) :被強制等待(involuntary wait)虛擬CPU的時間,此時hypervisor在為另一個虛擬處理器服務。
2)我們檢視下一臺安裝了Prometheus node_exporter主機都採集了那些cpu相關資料
curl localhost:9100/metrics | grep cpu node_cpu_seconds_total{cpu="0",mode="idle"} 1.12742968e+06 node_cpu_seconds_total{cpu="0",mode="iowait"} 15314.29 node_cpu_seconds_total{cpu="0",mode="irq"} 0 node_cpu_seconds_total{cpu="0",mode="nice"} 2851.94 node_cpu_seconds_total{cpu="0",mode="softirq"} 826.97 node_cpu_seconds_total{cpu="0",mode="steal"} 0 node_cpu_seconds_total{cpu="0",mode="system"} 8983.57 node_cpu_seconds_total{cpu="0",mode="user"} 29765.21 後面的數字是cpu的使用時間
3)CPU的使用率是怎麼計算的呢?
CPU佔用率計算公式
CPU時間=user+system+nice+idle+iowait+irq+softirq+Stl +guest
%us=(User time + Nice time)/CPU時間*100%
%sy=(System time + Hard Irq time +SoftIRQ time)/CPU時間*100%
%id=(Idle time)/CPU時間*100%
%ni=(Nice time)/CPU時間*100% %wa=(Waiting time)/CPU時間*100%
%hi=(Hard Irq time)/CPU時間*100%
%si=(SoftIRQ time)/CPU時間*100%
%st=(Steal time)/CPU時間*100%
Prometheus的演示
通過 curl localhost:9100/metrics 我們可以看到cpu的總量在prometheus中的key是node_cpu_seconds_total
1)node_cpu_seconds_total 檢視
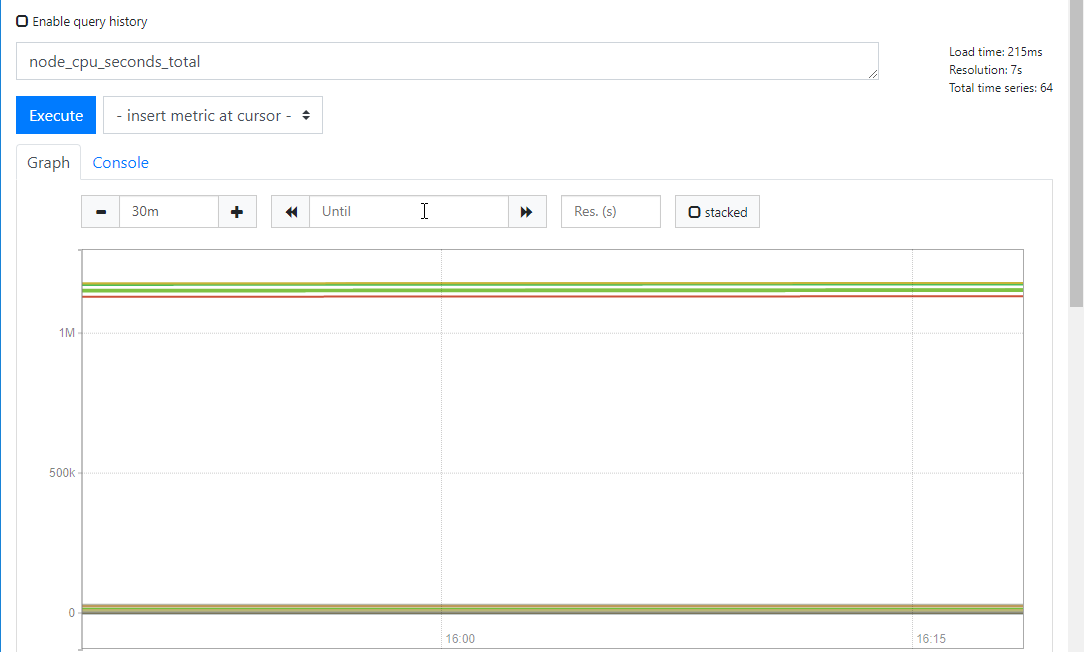
2)如何獲取cpu眾多值中的一個?例如idle(空閒cpu)
表示式 (key的過濾是通過 { } 實現的 )
node_cpu_seconds_total{mode="idle"}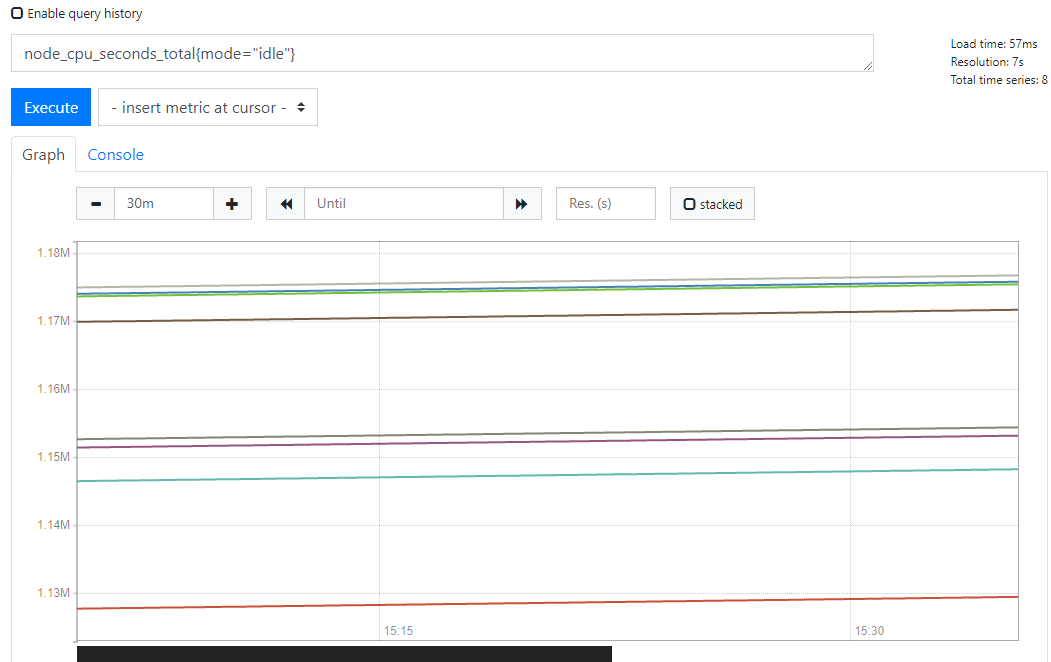
3)獲取1m中內的資料變化通過increase()
表示式
increase(node_cpu_seconds_total{mode="idle"}[1m])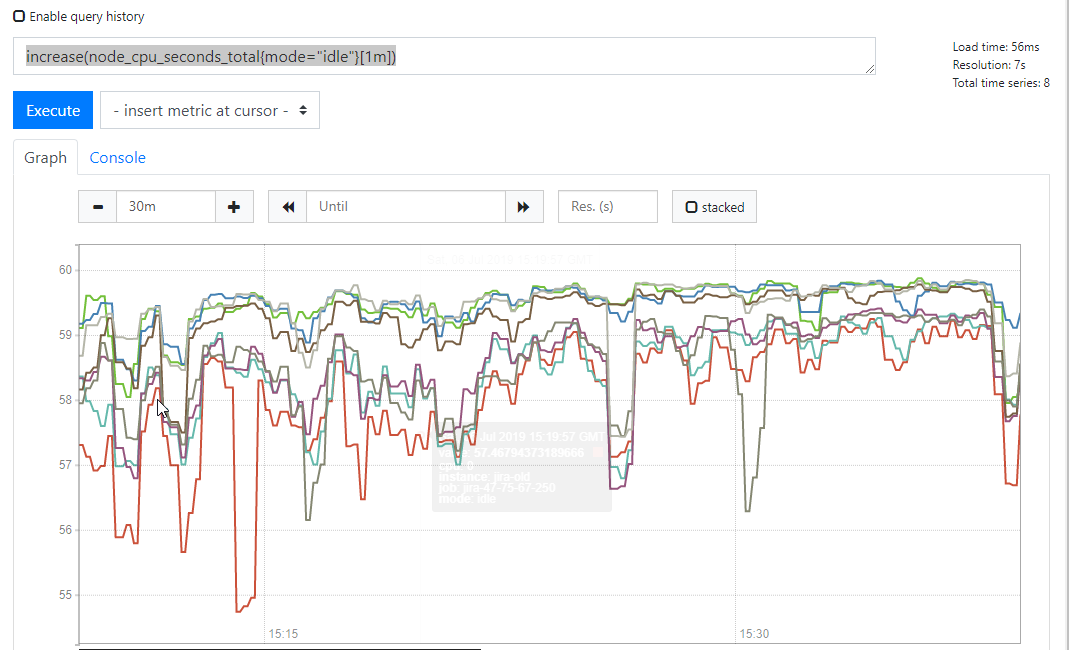
4) 獲取1m中內的資料變化和
表示式
sum(increase(node_cpu_seconds_total{mode="idle"}[1m]))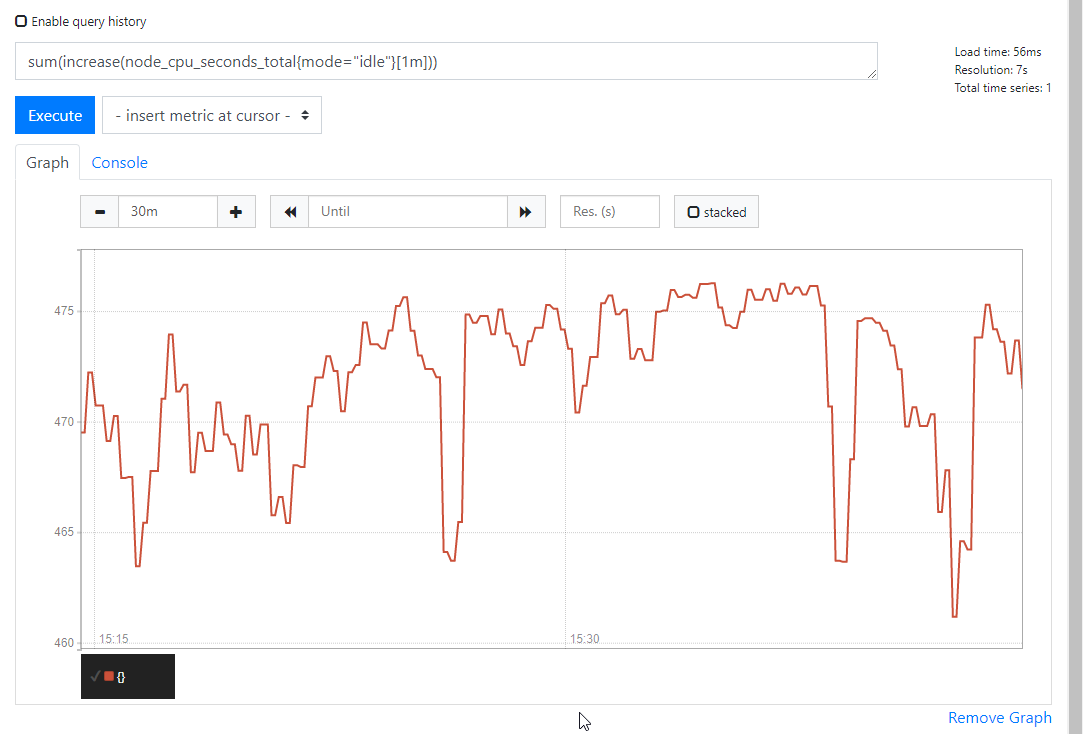
當然這裡有個問題,當你使用了sum像是上面的方式,我們求的和是包含了所有伺服器的所有cpu的平均值和。意思就是說假如監控上面監控了100伺服器其中各個伺服器的cpu數量都不盡相同,那麼我們的求和就是將這100伺服器中的所有cpu求和求平均。
5) 如何解決上面的問題呢?
這裡就引進一個方法 by(instance),將sum加和一起的數值按照指定的方式進行一層拆分,instance代表的是機器名.
表示式
sum(increase(node_cpu_seconds_total{mode="idle"}[1m])) by(instance)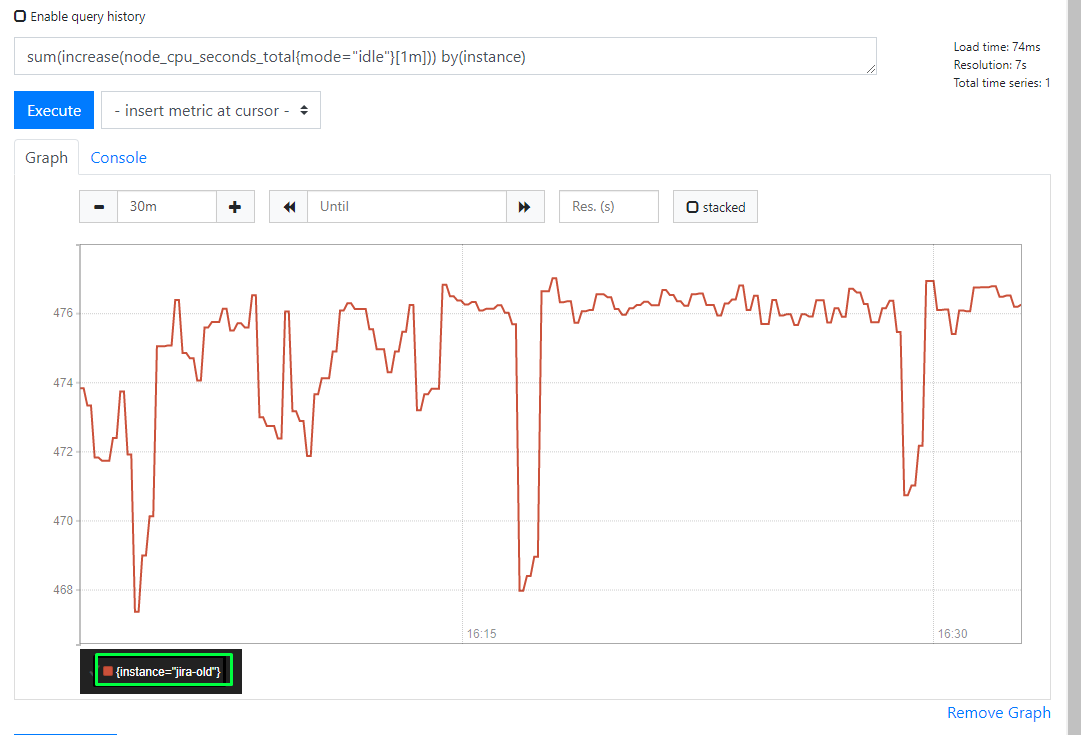
6) 獲取空閒cpu的百分比
表示式(開始使用預算符)
sum(increase(node_cpu_seconds_total{mode="idle"}[1m])) by(instance) /sum(increase(node_cpu_seconds_total[1m])) by(instance)
or
(sum(increase(node_cpu_seconds_total{mode="idle"}[1m])) by(instance)) / (sum(increase(node_cpu_seconds_total[1m])) by(instance))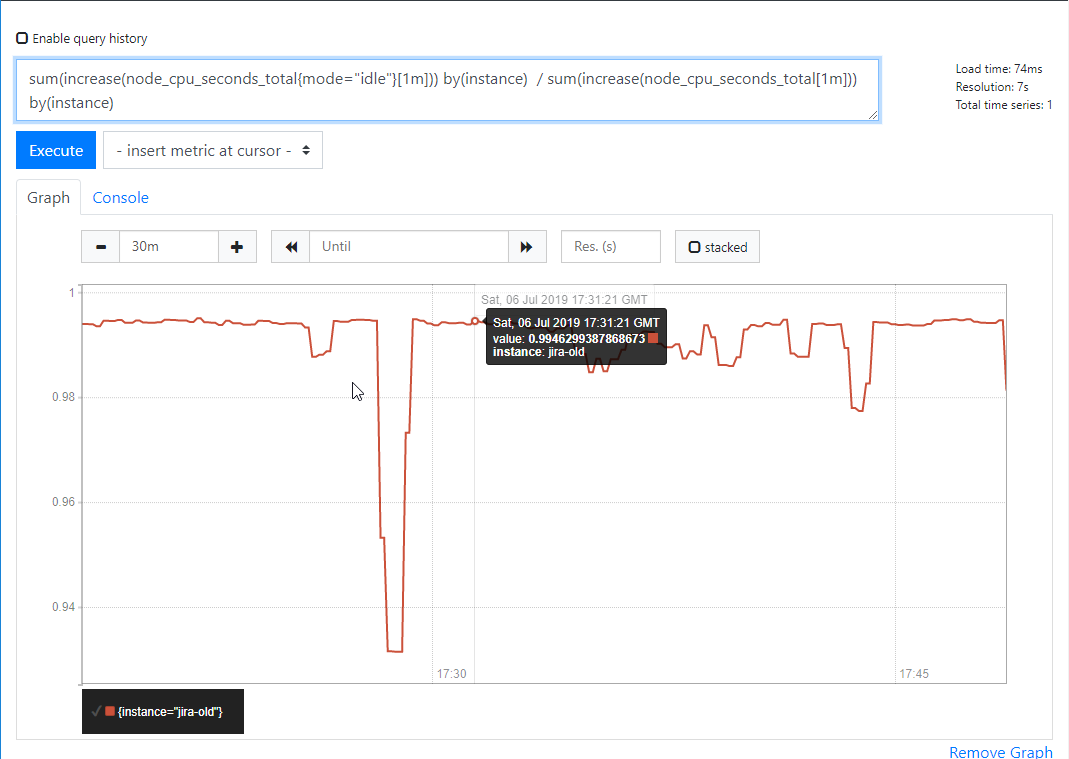
7)非空閒cpu1m使用百分比
表示式
(1- ((sum(increase(node_cpu_seconds_total{mode="idle"}[1m])) by(instance)) / (sum(increase(node_cpu_seconds_total[1m])) by(instance))))*100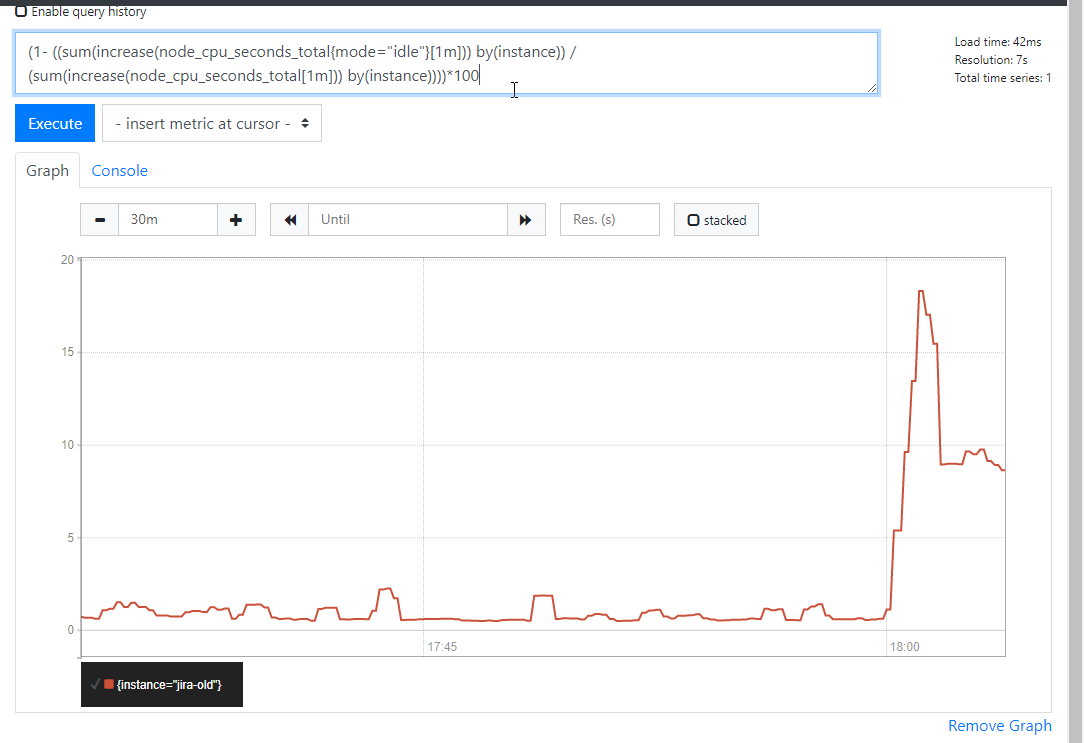
相關推薦
你需要精通一種監控-CPU資源監控例項
知識點回顧 CPU的使用率是如何計算的? 1)CPU相關概念 CPU利用率:CPU的使用情況。 使用者時間(User time) :表示CPU執行使用者程序的時間,包括nices時間。通常期望使用者空間
你需要精通一種監控-Prometheus資料型別
1 Counter:只增不減的計數器 Counter型別的指標其工作方式和計數器一樣,只增不減(除非系統發生重置)。常見的監控指標,如http_requests_total,node_cpu都是Counter型別的監控指標。 一般在定義Counter型別指標的名稱時推薦使用_total作為
你需要精通一種監控系列
在我們的工作中,尤其是運維行業,監控無疑必不可少,監控是我們的第三隻眼睛,面對眾多的伺服器和應用,我們作為運維人員不可能每天去巡查每臺伺服器的每個應用程式和系統狀態,而監控系統則能供幫我們完成這一項任務,當應用與系統出現一些不好的狀況,監控系統可以通過郵件,微信或者簡訊的多種方式及時傳遞給我們,使得我們可
你需要精通一種監控-Prometheus核心元件
下圖展示Prometheus的基本架構: Prometheus Server Prometheus Server是Prometheus元件中的核心部分,負責實現對監控資料的獲取,儲存以及查詢。 Prometheus Server可以通過靜態配置管理監控目標,也可以配合使用Service Disc
你需要精通一種監控-時間序列資料庫
時間序列資料就是歷史烙印,具有不變性,、唯一性、時間排序性 時間序列資料跟關係型資料庫有太多不同,但是很多公司並不想放棄關係型資料庫。 於是就產生了一些特殊的用法,比如用 MySQL 的 VividCortex, 用 Postgres 的 Timescale。 很多人覺得特
你需要精通一種監控-初識PromQL
PromQL是Prometheus內建的資料查詢語言,其提供對時間序列資料豐富的查詢,聚合以及邏輯運算能力的支援。並且被廣泛應用在Prometheus的日常應用當中,包括對資料查詢、視覺化、告警處理當中。可以這麼說,PromQL是Prometheus所有應用場景的基礎,理解和掌握PromQL是Promet
你需要精通一種監控-PromQL聚合操作
sum (求和) min (最小值) max (最大值) avg (平均值) stddev (標準差) stdvar (標準差異) count (計數) count_values (對value進行計數) bottomk (後n條時序
你需要精通一種監控-標籤的使用和基於數值的過濾
1 標籤的精確匹配 node_netstat_Tcp_PassiveOpens{instance="jira-old"} node_netstat_Tcp_PassiveOpens 為TCP連線數 jira-old 為標籤名字 2 模糊匹配 no
你需要精通一種監控-常用行數詳解
1 獲取網絡卡1m每秒流量平均(此時是有多少網絡卡將會顯示多少網絡卡的流量) 表示式 rate(node_network_receive_bytes_total[1m]) 2)只看eth0網絡卡1m每秒流量平均(即所有伺服器eth0) 表示式 rate(node_network_receiv
你需要精通一種監控-prometheus服務端相關內容
[root@aliyun-hk-yabo-prod-jiranew prometheus210]# ll total 117924 drwxr-xr-x 2 3434 3434 4096 May 25 21:54 console_libraries drwxr-xr-x 2 3434 3
23 種 Pandas 核心操作,你需要過一遍嗎?
Pandas 是一個 Python 軟體庫,它提供了大量能使我們快速便捷地處理資料的函式和方法。一般而言,Pandas 是使 Python 成為強大而高效的 資料分析 環境的重要因素之一。在本文中,作者從基本資料集讀寫、 資料處理 和 Da
程序員的十種級別,看看你屬於哪一種?
時間 中國 利用 其中 二級 獲取 自己的 十種 -s 第一級:神人,天資過人而又是技術狂熱者同時還擁有過人的商業頭腦,高瞻遠矚,技術過人,大器也。 第二級:高人,有天賦,技術過人但沒有過人的商業頭腦,通常此類人不是頂尖黑客就是技術總監之流。 第
跨境電商賣家你需要的一款跨境電商ERP在這裏?
內部 而且 應該 優化 折扣 前端 降低成本 個人 自然 跨境電商發展在這幾年發展異常迅猛,連續多年高增長,除了國內淘寶賣家轉型和傳統外貿賣家之外,老賣家發展到一定階段必然會出現管理和運營的瓶頸,瓶頸不攻破,勢必會影響企業的發展。 所以跨境電商運營在電商企業至關
四種人“cai”在兄弟連戰狼班Java培訓,你屬於哪一種?
心態 而且 心理 一點 四種 熱血 沒有 喜歡 這樣的 四種人“cai”在兄弟連戰狼班Java培訓,你屬於哪一種? 大家好, 俺叫劉小財,這個名字的是父母起的,俺覺得父母是這個意思,無論做什麽要給自己留一個後路。 俺來到兄弟連二個月,也慢慢適應了這裏的生活,每天都過
一種對共享資源和獨享資源的檢查方法
技巧 參考 fine 數量 代碼檢測 void linker 移除 基本 一種對共享資源和獨享資源的檢查方法 1. 背景 當程序的子模塊數量和規模擴大之後,在開發階段,系統長時間允許後經常會碰到下面一些bug: 內存泄漏。隨著時間允許,系統可用的內存越來越少,最後kern
做成一件事一定需要具備一種匠心精神
做成一件事一定需要具備一種匠心精神首先,敞開心扉的自問一下,我是一個什麽樣的?這個非常的關鍵,什麽樣的人適合做什麽樣的事,這個之間不存在必然關系,但是隨著時間的推移,如果不去改變的話,就會成為這樣的人。我知道,人的命是很奇特,你的性格是你的父親給的,你的聰明來源於你的母親。我們能不能夠比別人更加的優秀,就看我
創建線程有幾種不同的方式?你喜歡哪一種?為什麽?
什麽 all HR thread 同時 應用設計 創建線程 callable 應用程序 創建線程有四種不同的方式: 1、繼承Thread類 2、實現Runnable接口 3、應用程序可以使用Executor框架來創建線程池 4、實現Callable接口 我更喜歡實現Ru
2分鐘精準鑒別初級、中級、高級程序員,你是哪一種?
為什麽 tinyproxy har bug 高級 業務 我會 sgx 是什麽 源 / 頂級程序員 文 / An先生 @jonde初級:產品是大爺中級:懟過產品高級:打過產品 初級:加班中級:不加班高級:你們加班 @sunsulei初級:嗯?中級:嗯。高級:嗯? @ti
五種型別的程式設計師,你屬於哪一種?
在我的程式設計生涯中,我碰到過很多奇奇怪怪的對手和同盟。我把這些編碼戰士們分成五類,有些人是你隊伍中的好夥伴,有些人則是搗蛋者,讓你的每一個計劃都完不成。 不管怎麼說,他們在軟體開發的諸神殿上都佔有一席之地。如果你的團隊中沒有一個合適健康的比例,混合這些不同型別的程式設計師,要麼你會發現你的專案跌跌
閱讀《認識天性》有感-----你應該換一種學習方式了!(第一次閱讀部分)
與其漫無目的的記所謂的必考單詞,不如去思考怎麼記的牢固(就算花的時間多)。學習一個概念,花越多的時間,嘗試用自己的話語去重新演繹他,或者嘗試理解這個感念在不同語境下的不同意義,就越能牢固地掌握這個概念。 1 如果你習慣的學習風格與你正教你上課的老師教學形式相符合,你的學習效果就會更好。 2與反覆閱讀這種複