
【Mysql】索引簡介
本文口味:番茄炒蛋,預計閱讀:10分鐘。
部落格又停更了兩個月,在這期間,對人生和世界多了許多思考。在人生的不同階段,會對生活和世界有著不一樣的認知,而認知的改變也會直接反應在行為模式之中。
對於生活的思考心得也會在之後的時間裡,慢慢分享給大家,一方面是對自己心路歷程的記錄和總結,另一方面也希望能給遇到同樣問題或疑惑的朋友以幫助。目前生活已經慢慢調整到我想要的樣子,部落格寫作也該繼續起航了。
一、說明
Mysql是最常用的關係型資料庫,而索引則是Mysql調優中最關心的部分,設計一個好的索引並寫出合適的sql,就能將查詢速度大大提升。從本篇開始,將會對Mysql中的索引進行深入淺出的介紹,從索引的簡介、類別、使用姿勢到索引的原理,最後到索引實戰。希望通過本系列的文章,能讓你對mysql中的索引有一個更深入的認識。
以下是本文大綱:
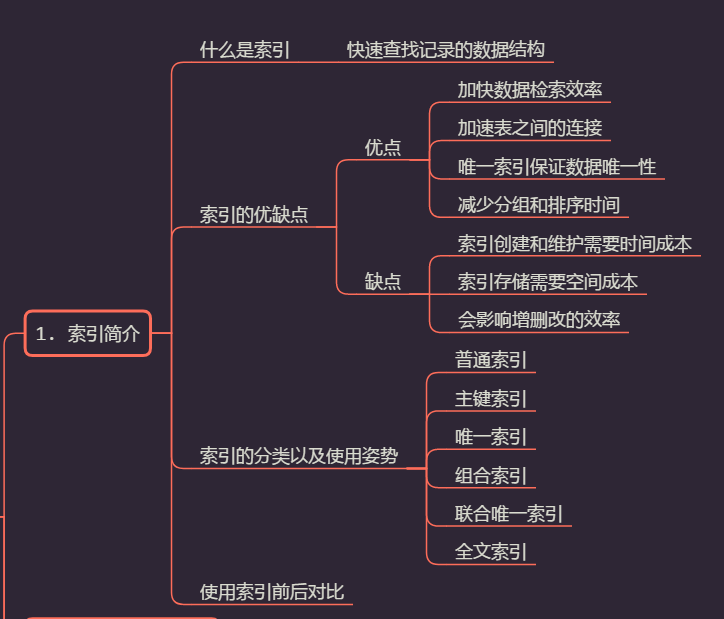
二、什麼是索引
索引是儲存引擎用於快速查詢記錄的一種資料結構。
emm,用人話說,如果把Mysql比作一本書的話,索引就是書的目錄,根據目錄便能很快找到需要的資訊所在的頁面,如果沒有目錄的話,想要查詢想要的資訊就只能一頁一頁翻了。
比如下面這樣一條簡單的sql:
SELECT id,name,course,grade FROM t_grade WHERE name = 'Frank';如果沒有新增索引的話,只能從最小記錄開始依次遍歷mysql中的記錄,然後對比每條記錄是否符合搜尋條件。如果表中的資料量不大(十萬級別以下),耗時其實也還好,畢竟目前來說,CPU效率已經很高了。但這樣其實是對CPU的一種浪費,就好比開著跑車在泥濘的鄉村小路上駕駛,完全無法發揮它應有的效能。而索引便是這樣一條康莊大道,有了索引,才能充分發揮mysql引擎的效能,讓你的sql跑車風馳電掣。
三、索引的優缺點
對於大部分事物而言,通常存在其對立面的,有好的一面,就會有壞的一面,就像質量好的東西通常價格高,便宜的東西通常質量差,索引也是如此。
使用索引的優點顯而易見:
- 可以大大加快資料檢索效率。
- 可以加速表與表之間的連線。
- 可以通過唯一索引的建立,保證資料的唯一性。
- 可以顯著減少分組與排序的時間。
總而言之,用一個字來總結,就是快。
使用索引的缺點也是需要考慮的:
- 索引的建立和維護需要時間成本。表中的資料量越大,插入或刪除資料時,調整索引所需要的時間就越長。
- 索引需要單獨儲存,佔用磁碟空間,如果設定了大量的索引,佔用的空間甚至比記錄本身更大。
- 在對資料進行增、刪、改時,需要同時更新索引中的資料,因此會影響增刪改的速度。
所以使用索引並不是百利而無一害,使用不當甚至可能造成刪庫跑路的慘劇【手動滑稽】。但當你瞭解它的原理,掌握了索引的真諦,它就會成為你的神兵利器,讓你在mysql開發中所向披靡。
四、索引的分類以及建立姿勢
索引可分為普通索引、唯一索引、主鍵索引、組合索引、全文索引。看起來好像很多很複雜,但其實並非如此,且聽我慢慢道來。
普通索引,名字中就透露出它普通的氣質,也就是最常見的索引。
如何建立一個普通索引呢?其實很簡單,如果是在DDL中建立索引,可以這樣使用:
CREATE TABLE `t_grade` (
id BIGINT(20) COMMENT '主鍵id',
name VARCHAR(30) COMMENT '姓名',
course INT COMMENT '課程,1-語文,2-數學,3-英語,4-物理',
grade DECIMAL(5,2) COMMENT '成績',
KEY idx_name(`name`)
)ENGINE=InnoDB AUTO_INCREMENT=0 DEFAULT CHARSET=utf8;這樣就為"name"列建立了一個名為"idx_name"的普通索引。通用的建立方式為:
KEY 索引名 (`列名`)如果是為一張已經建立好的表新增一個普通索引,那麼可以這樣:
ALTER TABLE `t_grade` ADD KEY idx_name(`name`);你可能會說,“不是用index關鍵字來建立索引的嗎”,別急別急,其實它們的效果是一樣的。
主鍵索引,一看就是很關鍵的角色,沒錯,每張表都會有且只有一個主鍵索引,即使沒有顯式的建立主鍵索引的話,也會自動建立一個隱藏的主鍵索引。
這麼重要的索引,用的關鍵字肯定也得不一樣才行,建立主鍵索引的關鍵字是PRIMARY KEY,在DDL中新增主鍵索引的姿勢為:
CREATE TABLE `t_grade` (
id BIGINT(20) COMMENT '主鍵id',
name VARCHAR(30) COMMENT '姓名',
course INT COMMENT '課程,1-語文,2-數學,3-英語,4-物理',
grade DECIMAL(5,2) COMMENT '成績',
PRIMARY KEY (`id`)
)ENGINE=InnoDB AUTO_INCREMENT=0 DEFAULT CHARSET=utf8;因為主鍵只能有一個,所以不需要新增主鍵名。通用的新增方式為:
PRIMARY KEY (`列名`)如果是為已建立好的表新增主鍵索引,那麼可以這樣:
ALTER TABLE `t_grade` ADD PRIMARY KEY (`id`);唯一索引,顧名思義,就是“唯一”的索引,被新增到索引中的列的值必須是唯一的,如果向資料表中插入一條已存在的唯一索引欄位記錄,就會報錯。
定義唯一索引的關鍵字為 UNIQUE KEY。在DDL中新增唯一索引的姿勢為:
CREATE TABLE `t_grade` (
id BIGINT(20) COMMENT '主鍵id',
name VARCHAR(30) COMMENT '姓名',
course INT COMMENT '課程,1-語文,2-數學,3-英語,4-物理',
grade DECIMAL(5,2) COMMENT '成績',
UNIQUE KEY uk_name (`name`)
)ENGINE=InnoDB AUTO_INCREMENT=0 DEFAULT CHARSET=utf8;唯一索引的通用新增方式為:
UNIQUE KEY 索引名 (`列名`)為已建立好的表新增唯一索引:
ALTER TABLE `t_grade` ADD UNIQUE KEY uk_name (`name`);組合索引,又叫聯合索引,便是將兩個或者多個欄位組合在一起的索引,好像跟沒說一樣= =
看一個栗子就知道了。
CREATE TABLE `t_grade` (
id BIGINT(20) COMMENT '主鍵id',
name VARCHAR(30) COMMENT '姓名',
course INT COMMENT '課程,1-語文,2-數學,3-英語,4-物理',
grade DECIMAL(5,2) COMMENT '成績',
KEY idx_name_corse (`name`,`course`)
)ENGINE=InnoDB AUTO_INCREMENT=0 DEFAULT CHARSET=utf8;同樣是使用key關鍵字,在索引名後新增多個欄位名即可。這裡有一點需要注意的是,欄位排列是有順序的。舉例說明,下面這兩個索引是不一樣的:
ALTER TABLE `t_grade` ADD KEY idx_name_course (`name`,`course`);
ALTER TABLE `t_grade` ADD KEY idx_name_course (`course`,`name`);索引的匹配遵循“左綴匹配原則”,舉個栗子說明,如果建立的組合索引是
ALTER TABLE `t_grade` ADD KEY idx_name_course (`name`,`course`);那麼下面語句將能命中這個組合索引。
SELECT * FROM `t_grade` WHERE name = 'Frank'; 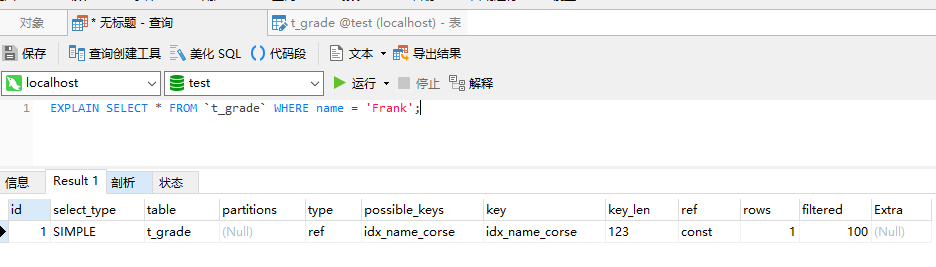
而下面這個語句將無法命中索引:
SELECT * FROM `t_grade` WHERE course = 1;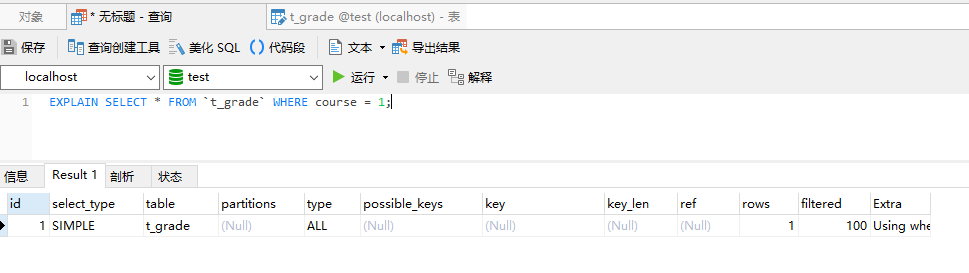
因為在組合索引中,索引中的記錄是先按照前一個欄位排序,然後再根據後一個欄位排序的,所以如果直接使用組合索引中的第二個欄位查詢時,查詢索引對索引記錄進行遍歷,遍歷完成之後還需要回溯到聚簇索引中獲取完整記錄,這樣反而更耗時間,所以sql優化器會選擇直接對記錄進行遍歷。
如果你還不清楚索引的結構以及聚簇索引是什麼,不要著急,後面的文章裡會有詳細的介紹。
聯合唯一索引,便是將多個欄位組合起來形成一個唯一鍵,舉個栗子:
先刪除所有索引,然後新增兩條記錄:
INSERT INTO `t_grade` (`id`, `name`, `course`, `grade`) VALUES(1, 'Frank', 1, 100);
INSERT INTO `t_grade` (`id`, `name`, `course`, `grade`) VALUES(2, 'Frank', 1, 95);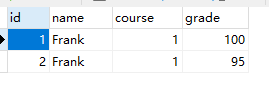
這樣就能插入兩條記錄了。
然後刪掉這兩條記錄,建立一個聯合唯一索引:
ALTER TABLE `t_grade` ADD UNIQUE KEY idx_name_course (`name`,`course`);然後再來執行一下上面的sql:
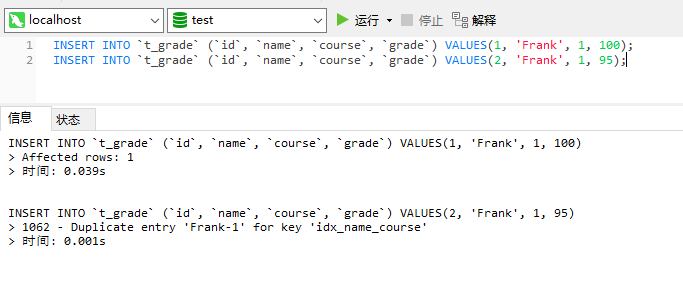
這時候,就會得到一個錯誤提示,因為將欄位name和course建立了聯合唯一索引,所以這兩個欄位的組合值必須是唯一的,如果要插入的記錄的這兩個欄位組合值已經存在,那麼就會丟擲異常。
最後一個是比較複雜的索引:全文索引,由於其複雜性,這裡只簡單的介紹它的建立姿勢。
CREATE TABLE `t_article`(
id BIGINT COMMENT '文章id',
title VARCHAR(200) COMMENT '文章標題',
content TEXT COMMENT '文章內容',
FULLTEXT (title, content)
)ENGINE=InnoDB AUTO_INCREMENT=0 DEFAULT CHARSET=utf8;或者給現有表新增全文索引:
ALTER TABLE `t_article` ADD FULLTEXT KEY fidx_title_content (title,content) WITH PARSER ngram;想要使用全文索引查詢,則需要使用MATCH關鍵字。
SELECT * FROM `t_article` WHERE MATCH(title, content) AGAINST('查詢字串');當然,如果想要使用全文索引,需要確認mysql的版本號在5.7以上,否則無法在innodb引擎上使用全文索引的中文檢索外掛ngram。
五、索引使用前後對比
為了更直觀的看出索引的優缺點,我們可以來對資料表新增索引前後執行相同sql的耗時來看出對比,這裡僅進行簡單的比較,沒有使用效能測試。
先來建立一個數據表:
CREATE TABLE `t_grade` (
id BIGINT(20) COMMENT '主鍵id',
name VARCHAR(30) COMMENT '姓名',
course INT COMMENT '課程,0-化學,1-語文,2-數學,3-英語,4-物理',
grade DECIMAL(5,2) COMMENT '成績'
)ENGINE=InnoDB AUTO_INCREMENT=0 DEFAULT CHARSET=utf8;然後插入一百萬條資料:
public void batchInsert(){
long timeMillis = System.currentTimeMillis();
System.out.println("開始插入資料");
for (int i = 1; i < 1000000; i++) {
GradeDO gradeDO = new GradeDO((long) i, randomName(), random.nextInt(5), BigDecimal.valueOf(random.nextDouble() * 100));
gradeMapper.insert(gradeDO);
}
System.out.println("插入一百萬條記錄耗時:" + ( System.currentTimeMillis() - timeMillis) / 1000.0 );
}輸出如下:
開始插入資料
插入一百萬條記錄耗時:1507.102現在是沒有索引的狀態,開始進行插入測試:
public void batchInsert(){
long timeMillis = System.currentTimeMillis();
System.out.println("開始插入資料");
for (int i = 1000000; i < 1010000; i++) {
GradeDO gradeDO = new GradeDO((long) i, randomName(), random.nextInt(5), BigDecimal.valueOf(random.nextDouble() * 100));
gradeMapper.insert(gradeDO);
}
System.out.println("插入一萬條記錄耗時:" + ( System.currentTimeMillis() - timeMillis) / 1000.0 );
}輸出如下:
開始插入資料
插入一萬條記錄耗時:15.681然後進行查詢測試。
@Test
void testQuery() {
long timeMillis = System.currentTimeMillis();
System.out.println("開始查詢");
for (int i = 0; i < 100; i++) {
Integer id = random.nextInt(1000000);
GradeDO gradeDO = gradeMapper.selectById(id);
}
System.out.println("一百次查詢耗時:" + ( System.currentTimeMillis() - timeMillis) / 1000.0 );
}輸出如下:
開始查詢
一百次查詢耗時:51.658接下來,為id列建立一個主鍵,併為name欄位建立一個普通索引。
再插入一萬條記錄:
開始插入資料
插入一萬條記錄耗時:17.465然後進行查詢測試。
開始查詢
一百次查詢耗時:0.191可以看出,在有單個索引的情況下,建立記錄耗時略長於無索引的情況,當欄位數量和索引數量增加時,這種差距將會增大。查詢效率可以清晰的看出,這裡添加了索引之後,大大的縮減了查詢的耗時,當然,這裡主要是聚簇索引的功勞。
六、總結
索引是mysql中十分重要的一個特性,使用好它就能讓你的sql如虎添翼。簡單來說,索引一方面可以大大提升查詢效能,另一方面也會佔用時間和空間成本,因此索引的選擇也是一門學問。索引有很多種型別,不同型別的索引有著不同的特性,因此只有瞭解了它們各自的特性才能正確使用它們。
關於索引的簡介就先介紹到這裡了,後面會對索引的原理進行進一步深入的介紹,讓你不僅知道怎麼使用索引,而且還能知道為什麼要這樣使用索引